November 23, 2019
HTTPS reaches 80% - mission accomplished after 14 years
A post on Matthew Green's blog highlights that Snowden revelations helped the push for HTTPS everywhere.
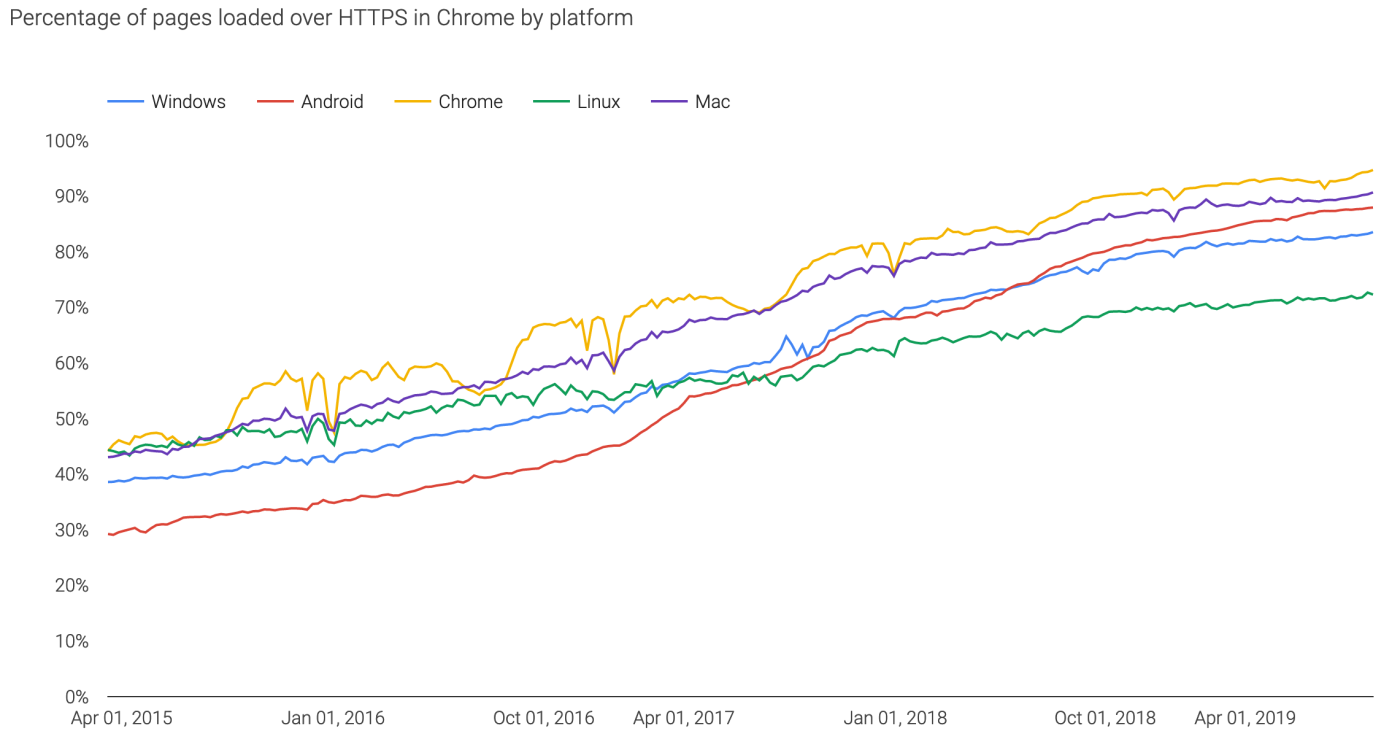
Firefox also has a similar result, indicating a web-wide world result of 80%.
(It should be noted that google's decision to reward HTTPS users by prioritising it in search results probably helped more than anything, but before you jump for joy at this new-found love for security socialism, note that it isn't working too well in the fake news department.)
The significance of this is that back in around 2005 some of us first worked out that we had to move the entire web to HTTPS. Logic at the time was:
Why is this important? Why do we care about a small group of sites are still running SSL v2. Here's why - it feeds into phishing:1. In order for browsers to talk to these sites, they still perform the SSL v2 Hello. 2. Which means they cannot talk the TLS hello. 3. Which means that servers like Apache cannot implement TLS features to operate multiple web sites securely through multiple certificates. 4. Which further means that the spread of TLS (a.k.a. SSL) is slowed down dramatically (only one protected site per IP number - schlock!), and 5, this finally means that anti-phishing efforts at the browser level haven't a leg to stand on when it comes to protecting 99% of the web.Until *all* sites stop talking SSL v2, browsers will continue to talk SSL v2. Which means the anti-phishing features we have been building and promoting are somewhat held back because they don't so easily protect everything.
For the tl;dr: we can't protect the web when HTTP is possible. Having both HTTP and HTTPS as alternatives broke the rule: there is only one mode, and it is secure, and allowed attackers like phishers to just use HTTP and *pretend* it was secure.
The significance of this for me is that, from that point of time until now, we can show that a typical turn around the OODA loop (observe, orient, decide, act) of Information Security Combat took about 14 years. Albeit in the Internet protocol world, but that happens to be a big part of it.
During that time, a new bogeyman turned up - the NSA listening to everything - but that's ok. Decent security models should cover multiple threats, and we don't so much care which threat gets us to a comfortable position.
October 19, 2018
AES was worth $250 billion dollars
So says NIST...
10 years ago I annoyed the entire crypto-supply industry:
Hypothesis #1 -- The One True Cipher Suite In cryptoplumbing, the gravest choices are apparently on the nature of the cipher suite. To include latest fad algo or not? Instead, I offer you a simple solution. Don't.
There is one cipher suite, and it is numbered Number 1.
Cypersuite #1 is always negotiated as Number 1 in the very first message. It is your choice, your ultimate choice, and your destiny. Pick well.
The One True Cipher Suite was born of watching projects and groups wallow in the mire of complexity, as doubt caused teams to add multiple algorithms- a complexity that easily doubled the cost of the protocol with consequent knock-on effects & costs & divorces & breaches & wars.
It - The One True Cipher Suite as an aphorism - was widely ridiculed in crypto and standards circles. Developers and standards groups like the IETF just could not let go of crypto agility, the term that was born to champion the alternate. This sacred cow led the TLS group to field something like 200 standard suites in SSL and radically reduce them to 30 or 40 over time.
Now, NIST has announced that AES as a single standard algorithm is worth $250 billion economic benefit over 20 years of its project lifetime - from 1998 to now.
h/t to Bruce Schneier, who also said:
"I have no idea how to even begin to assess the quality of the study and its conclusions -- it's all in the 150-page report, though -- but I do like the pretty block diagram of AES on the report's cover."
One good suite based on AES allows agility within the protocol to be dropped. Entirely. Instead, upgrade the entire protocol to an entirely new suite, every 7 years. I said, if anyone was asking. No good algorithm lasts less than 7 years.
Crypto-agility was a sacred cow that should have been slaughtered years ago, but maybe it took this report from NIST to lay it down: $250 billion of benefit.
In another footnote, we of the Cryptix team supported the AES project because we knew it was the way forward. Raif built the Java test suite and others in our team wrote and deployed contender algorithms.
June 29, 2017
SegWit and the dispersal of the transaction
 Jimmy Nguyen criticises SegWit on the basis that it breaks the signature of a contract according to US law. This is a reasonable argument to make but it is also not a particularly relevant one. In practice, this only matters in the context of a particularly vicious and time-wasting case. You could argue that all of them are, and lawyers will argue on your dime that you have to get this right. But actually, for the most part, in court, lawyers dont like to argue things that they know they are going to lose. The contract is signed, its just not signed in a particularly helpful fashion. For the most part, real courts and real judges know how to distinguish intent from technical signatures, so it would only be relevant where the law states that a particular contract must be signed in a particular way, and then weve got other problems. Yes, I know, UCC and all that, but lets get back to the real world.
Jimmy Nguyen criticises SegWit on the basis that it breaks the signature of a contract according to US law. This is a reasonable argument to make but it is also not a particularly relevant one. In practice, this only matters in the context of a particularly vicious and time-wasting case. You could argue that all of them are, and lawyers will argue on your dime that you have to get this right. But actually, for the most part, in court, lawyers dont like to argue things that they know they are going to lose. The contract is signed, its just not signed in a particularly helpful fashion. For the most part, real courts and real judges know how to distinguish intent from technical signatures, so it would only be relevant where the law states that a particular contract must be signed in a particular way, and then weve got other problems. Yes, I know, UCC and all that, but lets get back to the real world.
But there is another problem, and Nguyens post has triggered my thinking on it. Lets examine this from the perspective of triple entry. When we (by this I mean to include Todd and Gary) were thinking of the problem, we isolated each transaction as being essentially one atomic element. Think of an entry in accounting terms. Or think of a record in database terms. However you think about it, its a list of horizontal elements that are standalone.
When we sign it using a private key, we take the signature and append it to the entry. By this means, the entry becomes stronger - it carries its authorisation - but it still retains its standalone property.
So, with the triple entry design in that old paper, we dont actually cut anything out of the entry, we just make it stronger with an appended signature. You can think of it as is a strict superset of the old double entry and even the older single entry if you wanted to go that far. Which makes it compatible which is a nice property, we can extract double entry from triple entry and still use all the old software weve built over the last 500 years.
And, standalone means that Alice can talk to Bob about her transactions, and Bob can talk to Carol about his transaction without sharing any irrelevant or private information.
Now, Satoshis design for triple entry broke the atomicity of transactions for consensus purposes. But it is still possible to extract out the entries out of the UTXO, and they remain standalone because they carry their signature. This is especially important for say an SPV client, but its also important for any external application.
 Like this: Im flying to Shanghai next week on Blockchain Airlines, and Ive got to submit expenses. I hand the expenses department my Bitcoin entries, sans signatures, and the clerk looks at them and realises they are not signed. See where this is going? Because, compliance, etc, the expenses department must now be a full node. Not SPV. It must now hold the entire blockchain and go searching for that transaction to make sure its in there - its real, it was expended. Because, compliance, because audit, because tax, because thats what they do - check things.
Like this: Im flying to Shanghai next week on Blockchain Airlines, and Ive got to submit expenses. I hand the expenses department my Bitcoin entries, sans signatures, and the clerk looks at them and realises they are not signed. See where this is going? Because, compliance, etc, the expenses department must now be a full node. Not SPV. It must now hold the entire blockchain and go searching for that transaction to make sure its in there - its real, it was expended. Because, compliance, because audit, because tax, because thats what they do - check things.
If Bitcoin is triple entry, this is making it a more expensive form of triple entry. We dont need those costs, bearing in mind that these costs are replicated across the world - every user, every transaction, every expenses report, every accountant. For the cost of including a signature, an EC signature at that, the extra bytes gain us a LOT of strength, flexibility and cost savings.
(You could argue that we have to provide external data in the form of the public key. So whoevers got the public key could also keep the sigs. This is theoretically true but is starting to get messy and I dont want to analyse right now what that means for resource, privacy, efficiency.)
Some might argue that this causes more spread of Bitcoin, more fullnodes and more good - but thats the broken window fallacy. We dont go around breaking things to cause the economy to boom. A broken window is always a dead loss to society, although we need to constantly remind the government to stop breaking things to fix them. Likewise, we do not improve things by loading up the accounting departments of the world with additional costs. Were trying to remove those costs, not load them up, honestly!
Then, but malleability! Yeah, thats a nuisance. But the goal isnt to fix malleability. The goal is to make the transactions more certain. Segwit hasnt made transactions more certain if it has replaced one uncertainty with another uncertainty.
Today, Im not going to compare one against the other - perhaps I dont know enough, and perhaps others can do it better. Perhaps it is relatively better if all things are considered, but its not absolutely better, and for accounting, it looks worse.
Which does rather put the point on ones worldview. SegWit seems to retain the certainty but only as outlined above: when ones worldview is full nodes, Bitcoin is your hammer and your horizon. E.g., if youre only thinking about validation, then signatures are only needed for validation. Nailed it.
But for everyone else? Everyone else, everyone outside the Bitcoin world is just as likely to simply decline as they are to add a full node capability. We do not accept Bitcoin receipts, thanks very much.
Or, if you insist on Bitcoin, you have to go over to this authority and get a signed attestation by them that the receipt data is indeed valid. Theyve got a full node. Authenticity as a service. Some will think business opportunity! whereas others will think huh? Wasnt avoiding a central authority the sort of thing we were trying to avoid?
 I dont know what the size of the market for interop is, although I do know quite a few people who obsess about it and write long unpublished papers (daily reminder - come on guys, publish the damn things!). Personally I would not make that tradeoff. Im probably biased tho, in the same way that Bitcoiners are biased: I like the idea of triple entries, in the same way that Bitcoiners like UTXO. I like the idea that we can rely on data, in the same way that Bitcoiners like the idea that they can rely on a bunch of miners.
I dont know what the size of the market for interop is, although I do know quite a few people who obsess about it and write long unpublished papers (daily reminder - come on guys, publish the damn things!). Personally I would not make that tradeoff. Im probably biased tho, in the same way that Bitcoiners are biased: I like the idea of triple entries, in the same way that Bitcoiners like UTXO. I like the idea that we can rely on data, in the same way that Bitcoiners like the idea that they can rely on a bunch of miners.
Now, one last caveat. I know that SegWit in all its forms is a political food fight. Or a war, depending your use of the language. Im not into that - I keep away from it because to my mind war and food fights are a dead loss to society. I have no position one way or the other. The above is an accounting and contractual argument, albeit with political consequences. Im interested to hear arguments that address the accounting issues here, and not at all interested in arguments based on omg youre a bad person and youre taking money from my portfolio.
Ive little hope of that, but I thought Id ask :-)
February 27, 2017
Today Im trying to solve my messaging problem...
Financial cryptography is that space between crypto and finance which by nature of its inclusiveness of all economic activities, is pretty close to most of life as we know it. We bring human needs together with the net marketplace in a secure fashion. Its all interconnected, and Im not talking about IP.
Today Im trying to solve my messaging problem. In short, tweak my messaging design to better supports the use case or community I have in mind, from the old client-server days into a p2p world. But to solve this I need to solve the institutional concept of persons, i.e. those who send messages. To solve that I need an identity framework. To solve the identity question, I need to understand how to hold assets, as an asset not held by an identity is not an asset, and an identity without an asset is not an identity. To resolve that, I need an authorising mechanism by which one identity accepts another for asset holding, that which banks would call "onboarding" but it needs to work for people not numbers, and to solve that I need a voting solution. To create a voting solution I need a resolution to the smart contracts problem, which needs consensus over data into facts, and to handle that I need to solve the messaging problem.
Bugger.
A solution cannot therefore be described in objective terms - it is circular, like life, recursive, dependent on itself. Which then leads me to thinking of an evolutionary argument, which, assuming an argument based on a higher power is not really on the table, makes the whole thing rather probabilistic. Hopefully, the solution is more probabilistically likely than human evolution, because I need a solution faster than 100,000 years.
This could take a while. Bugger.
February 23, 2017
SHA1 collision attack - FINALLY after TWELVE years
Timeline on a hash collision attack:
| 1993 | SHA0 published |
| 1995 | SHA1 published due to weaknesses found |
| 2001 | SHA2 published due to expectations of weakness in SHA1 |
| 2005 | Shandong team MD5 attacked, SHA1 worried |
| 2009? | RocketSSL breached for using MD5 |
| 2014 | Chrome responds and starts phasing out SHA1 |
| 2017 | CWI & Google announce collision attack on SHA1 |
The point I wish to make here is that SHA1 was effectively deprecated in 2001 with the publication of SHA2. If you are vulnerable to a collision attack, then you had your moment of warning sixteen years ago.
On the other hand, think about this for a moment - in 2005 the Shandong shot was heard around the cryptographic world. Everyone knew! But we now see that SHA1 lasted an additional 12 years before it crumbled to a collision attack. That shows outstanding strength, an incredible run.
On the third hand, let's consider your protocol. If your protocol is /not/ vulnerable to a collision attack then SHA1 is still good. As is SHA0 and MD5. And, as an aside, no protocol should be vulnerable to a collision attack - such weakness is probably a bug.
So SHA1 is technically only a problem if you have another weakness in your protocol. And if you have that weakness, well, it's a pretty big one, and you should be worried for everything, not just SHA1.
On the fourth hand, however, institutions are too scared to understand the difference, and too bureaucratic to suggest better practices like eliminating collision vulnerabilities. Hence, all software suppliers have been working to deprecate SHA1 from consideration. To show you how asinine this gets, some software suppliers are removing older hash functions so, presumably you can't use them - to either make new ones or check old ones. (Doh!)
Security moves as a herd not as a science. Staying within the herd provides sociability in numbers, but social happiness shouldn't be mistaken for security, as the turkey well knows.
Finally, on the fifth hand, I still use SHA1 in Ricardo for naming Ricardian Contracts. Try for the life of me, and I still can't see how to attack it with collisions. As, after all, the issuer signs his own contract, and if he collides, he's up for both contracts, and there are copies of both distributed...
There is no cause for panic, if you've done your homework.
November 30, 2016
Corda Day - a new force
 Today is the day that Corda goes open source. Which will be commented far and wide, so not a lot of point in duplicating that effort. But perhaps a few comments on where this will lead us, as a distributed ledger sector.
Today is the day that Corda goes open source. Which will be commented far and wide, so not a lot of point in duplicating that effort. But perhaps a few comments on where this will lead us, as a distributed ledger sector.
For a long time, since 2009, Bitcoin dominated the scene. Ethereum successfully broke that monopoly on attention, not without a lot of pain, but it is safe to say that for a while now, there have been two broad churches in town.
As Corda comes out, it will create a third force. From today, the world moves to three centers of gravity. As with the the fabled three-body-gravity problem of astrophysics, it's a little difficult to predict how this will pan out but some things can be said.
This post is to predict that third force. First, a recap of features, and shortfalls. Then, direction, and finally interest.
Featurism. It has to be said again and again (and over and over) that Corda is a system that was built for what the finance world wanted. It wasn't ever a better blockchain, indeed, it's not even a blockchain - that was considered optional and in the event, discarded. It also wasn't ever a smarter contract, as seen against say Ethereum.
Corda was what made sense to corporates wanting to trade financial instruments - a focus which remains noticeably lacking in 'the incumbent chains' and the loud startups.
Sharing. In particular, as is well hashed in the introductory paper: Corda does not share the data except with those who are participants to the contract. This is not just a good idea, it's the law - there are lots and lots of regulations in place that make sharing data a non-starter if you are in the regulated world. Selling a public, publishing blockchain to a bank is like selling a prime beef steak to a vegetarian - the feedgrain isn't going to improve your chances of a sale.
Toasting. Corda also dispenses with the planet-warming proof of work thing. While an extraordinary innovation, it just will not fly in a regulated world. Sorry about that, guys. But, luckily, it turns out we don't need it in the so-called private chain business - because we are dealing with a semi-trusted world in financial institutions, they can agree on a notary to sign off on some critical transactions; And -- innovation alert here -- as it happens, the notary is an interface or API. It can be a single server, or if you feel like going maximal, you can hook up a blockchain at that point. In theory at least, Corda can happily use Bitcoin to do its coordination, if you write the appropriate notary interface. If that's your thing. And for a few use cases, a blockchain works for the consensus part.
These are deviations. Then there are similarities.
Full language capability. Corda took one lead from Ethereum which was the full Turing-complete VM - although we use Java's JVM as it's got 20 years of history, and Java is the #1 language in finance. Which we can do without the DAO syndrome because our contracts will be user-driven, not on an unstoppable computer - if there's a problem, we just stop and resolve it. No problem.
UTXO. Corda also took the UTXO transaction model from Bitcoin - for gains in scaleability and flexibility.
There's a lot more, but in brash summary - Corda is a lot closer to what the FIs might want to use.
Minuses. I'm not saying it's perfect, so let me say some bad things: Corda is not ready for production, has zero users, zero value on-ledger. It has not been reviewed for security, nor does that make sense until it's built out. It's missing some key things (which you can see in the docs or the new technical paper). It hasn't been tested at scale, neither with a regulator nor with a real user base.
Direction. Corda has a long long way to go, but the way it is going is ever closer to that same direction - what financial institutions want. The Ethereum people and the Bitcoin people have not really cottoned on to user-driven engineering, and remain bemused as to who the users of their system are.
Which brings us to the next point - interest. Notwithstanding all the above, or perhaps because of it - Corda already has the attention of the financial world:
- Regulators are increasingly calling R3 for expertise in the field.
- 75 or so members, each of which is probably larger than the entire blockchain field put together, have signed up. OK, so there is some expected give and take as R3 goes through its round process (which I don't really follow so don't ask) but even with a few pulling out, members are still adding and growth is still firmly positive.
- Here's a finger in the air guess: I could be wrong, but I think that as of today we already have about the same order of magnitude of programming talent working on Corda as Bitcoin or Ethereum, provided to us by various banks working a score or more projects. Today, we'll start the process of adding a zero. OK, adding that zero might take a month or two. But thereafter we're going to be looking at the next zero.
- Internally, members have been clamouring to get into it for 6 months now - but capacity has been too tight because of the dev team bottleneck. That changes today.
All of which is to say: I predict that Corda will shoot to pole position. That's because it is powered by its members, and it is focussed to their needs. A clear feedback loop which is totally absence in the blockchain world.
The Game. Today, Corda becomes the third force in distributed ledger technologies. But I also predict it's not only the game changer, it's the entire game.
The reason I say that is because it is the only game that has asked the users what they want. In contrast, Bitcoin told the users it wanted an unstoppable currency - sure, works for a small group but not for the mass market. Ethereum told their users they need an unstoppable machine - which worked how spectacularly with the DAO? Not. What. We. Wanted.
Corda is the only game in town because it's the only one that asked the users. It's that simple.
June 12, 2016
Where is the Contract? - a short history of the contract in Financial Cryptography systems
(Editor's note: Dates are approximate. Written in May of 2014 as an educational presentation to lawyers, notes forgotten until now. Freshened 2016.09.11.)
Where is the contract? This is a question that has bemused the legal fraternity, bewitched the regulator, and sent the tech community down the proverbial garden path. Let's track it down.
Within the financial cryptography community, we have seen the discussion of contracts in approximately these ways:
- Smart Contracts, as performance machines with money ,
- Ricardian Contract which captures the writings of an agreement ,
- Compositions: of elements such as the "offer and acceptance" agreement into a Russian Doll Contracts pattern, or of clause-code pairs, or of split contract constructions.
Let's look at each in turn.
a. Performance
a(i) Nick Szabo theorised the notion of smart contracts as far back as 1994. His design postulated the ability of our emerging financial cryptography technology to automate the performance of human agreements within computer programs that also handled money. That is, they are computer programs that manage performance of a contract with little or less human intervention.
At an analogous level at least, smart contracts are all around. So much of the performance of contracts is now built into the online services of corporations that we can't even count them anymore. Yet these corporate engines of performance were written once then left running forever, whereas Szabo's notion went a step further: he suggested smart contracts as more of a general service to everyone: your contractual-programmer wrote the smart contract and then plugged it into the stack, or the service or the cloud. Users would then come along and interact with this machine, to get services.
a(ii). Bitcoin. In 2009 Bitcoin deployed a limited form of Smart Contracts in an open service or cloud setting called the blockchain. This capability was almost a side-effect of a versatile payments transaction of smart contracts. After author Satoshi Nakamoto left, the power of smart contracts was reduced in scope somewhat due to security concerns.
To date, success has been limited to simple uses such as Multisig which provides a separation of concerns governance pattern by allowing multiple signers to release funds.
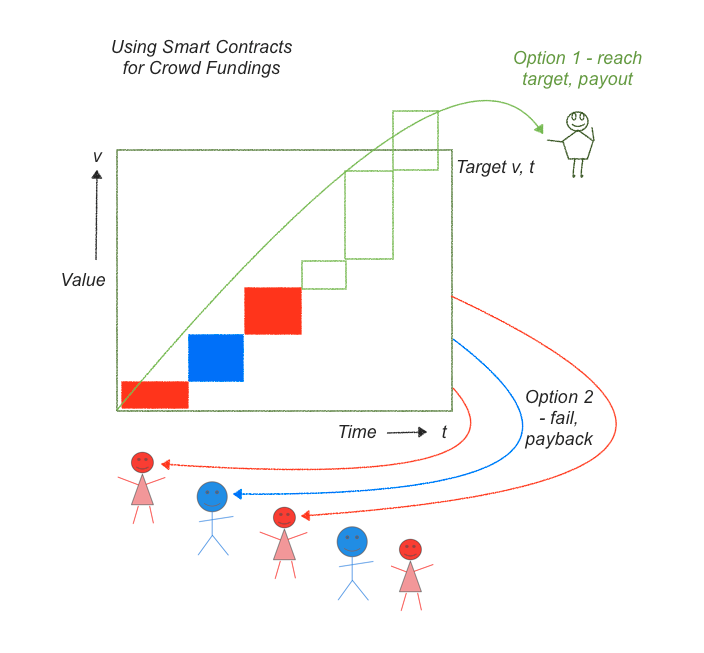
If we look at the above graphic we can see a fairly complicated story that we can now reduce into one smart contract. In a crowd funding, a person will propose a project. Many people will contribute to a pot of money for that project until a particular date. At that date, we have to decide whether the pot of money is enough to properly fund the project and if so, send over the funds. If not, return the funds.
To code this up, the smart contract has to do these steps:
- describe the project, including an target value v and a strike date t.
- collect and protect contributions (red, blue, green boxes)
- on the strike date /t/, count the total, and decide on option 1 or 2:
- if the contributions reach the amount, pay all over to owner (green arc), else
- if the contributions do not exceed the target v, pay them all back to funders (red and blue arcs).
A new service called Lighthouse now offers crowdfunding but keep your eyes open for crowdfunding in Ethereum as their smart contracts are more powerful.
b. Writings of the Contract
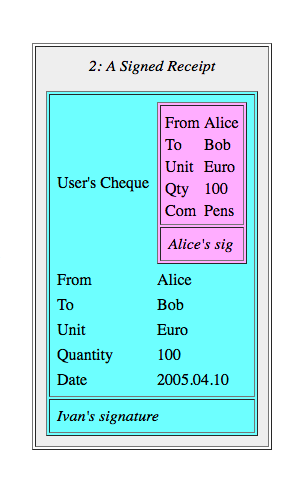
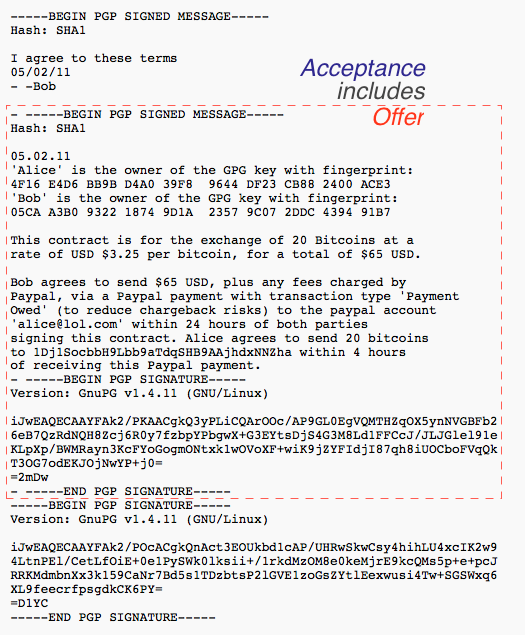
Back in 1996, as part of a startup doing bond trading on the net, I created a method to bring a classical 'paper' contract into touch with a digital accounting system such as cryptocurrencies. The form, which became known as the Ricardian Contract, was readily usable for anything that you could put into a written contract, beyond its original notion of bonds.
In short: write a standard contract such as a bond. Insert some machine-readable tags that would include parties, amounts, dates, etc that the program also needed to display. Then sign the document using a cleartext digital signature, one that preserves the essence as a human-readable contract. OpenPGP works well for that. This document can be seen on the left of this bow-tie diagram.
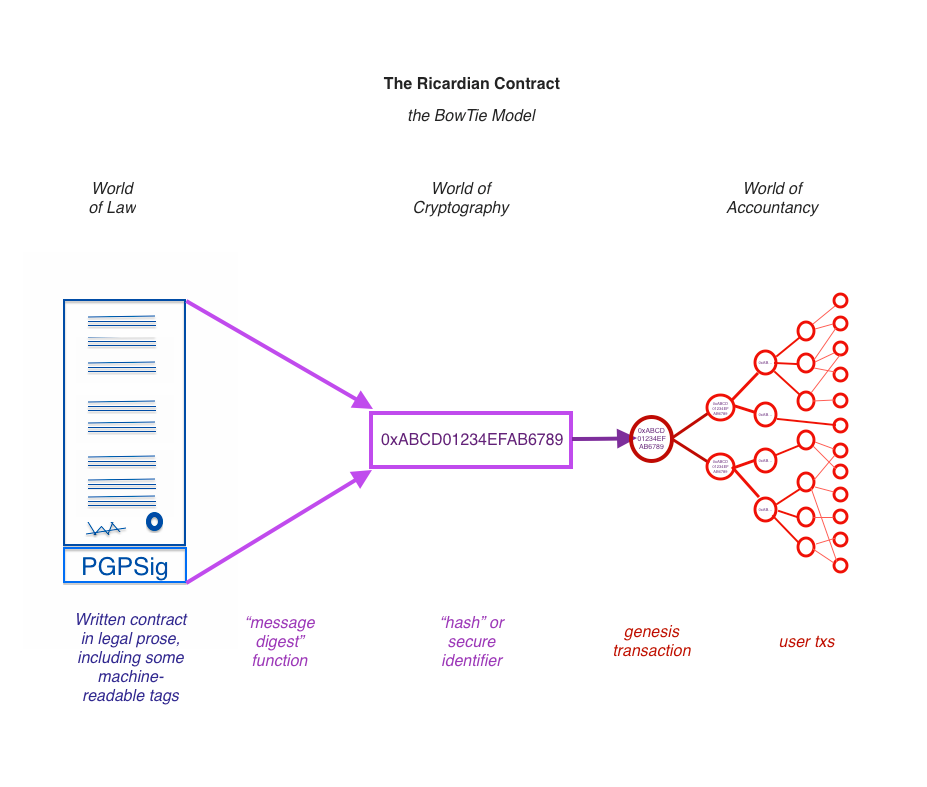
Then - hash the document using a cryptographic message digest function that creates a one-for-one identifier for the contract, as seen in the middle. Put this identifier into every transaction to lock in which instrument we're paying back and forth. As the transactions start from one genesis transaction and then fan out to many transactions, all of them including the Ricardian hash, with many users, this is shown in the right hand part of the bow-tie.
See 2004 paper and wikipedia page on the Ricardian contract. We have then a contract form that is readable by person and machine, and can be locked into every transaction - from the genesis transaction, value trickles out to all others.
The Ricardian Contract is now emerging in the Bitcoin world. Enough businesses are looking at the possibilities of doing settlement and are discovering what I found in 1996 - we need a secure way to lock tangible writings of a contract on to the blockchain. A highlight might be NASDAQ's recent announcements, and Coinprism's recent work with OpenAssets project [1, 2, 3], and some of the 2nd generation projects have incorporated it without much fuss.
c. Composition
c(i). Around 2006 Chris Odom built OpenTransactions, a cryptocurrency system that extended Ricardian Contract beyond issuance. The author found:
"While these contracts are simply signed-XML files, they can be nested like russian dolls, and they have turned out to become the critical building block of the entire Open Transactions library. Most objects in the library are derived, somehow, from OTContract. The messages are contracts. The datafiles are contracts. The ledgers are contracts. The payment plans are contracts. The markets and trades are all contracts. Etc.I originally implemented contracts solely for the issuing, but they have really turned out to have become central to everything else in the library."
In effect Chris Odom built an agent-based system using the Ricardian Contract to communicate all its parameters and messages within and between its agents. He also experimented with Smart Contracts, but I think they were a server-upload model.
c(ii). CommonAccord construct small units containing matching smart code and prose clauses, and then compose these into full contracts using the browser. Once composed, the result can be read, verified and hashed a la Ricardian Contracts, and performed a la smart contracts.
c(iii) Let's consider person to person trading. With face-to-face trades, the contract is easy. With mail order it is harder, as we have to identify each components, follow a journey, and keep the paper work. With the Internet it is even worse because there is no paperwork, it's all pieces of digital data that might be displayed, might be changed, might be lost.
Shifting forward to 2014 and OpenBazaar decided to create a version of eBay or Amazon and put it onto the Bitcoin blockchain. To handle the formation of the contract between people distant and anonymous, they make each component into a Ricardian Contract, and place each one inside the succeeding component until we get to the end.
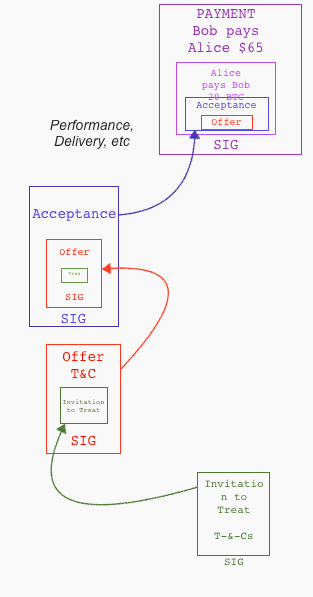 Let's review the elements of a contract in a cycle:
Let's review the elements of a contract in a cycle:
✓ Invitation to treat is found on blockchain similar to web page.
✓ offer by buyer
✓ acceptance by merchant
✓ (performance...)
✓ payment (multisig partner controls the money)
The Ricardian Contract finds itself as individual elements in the formation of the wider contract formation around a purchase. In each step, the prior step is included within the current contractual document. Like the lego blocks above, we can create a bigger contract by building on top of smaller components, thus implementing the trade cycle into Chris Odom's vision of Russian Dolls.
Conclusion
In conclusion, the question of the moment was:
Where is the contract?
So far, as far as the technology field sees it, in three areas:
- as performance - the Smart Contract
- as writing - the Ricardian Contract
- as composition - elements packaged into Russian Dolls, clause-code pairs and convergance as split contracts.
I see the future as convergence of these primary ideas: the parts or views we call smart & legal contracts will complement each other and grow together, being combined as elements into fuller agreements between people.
For those who think nothing much has changed in the world of contracts for a century or more, I say this: We live in interesting times!
(Editor's reminder: Written in May of 2014, and the convergence notion fed straight into "The Sum of all Chains".)
June 28, 2015
The Nakamoto Signature
The Nakamoto Signature might be a thing. In 2014, the Sidechains whitepaper by Back et al introduced the term Dynamic Membership Multiple-party Signature or DMMS -- because we love complicated terms and long impassable acronyms.
Or maybe we don't. I can never recall DMMS nor even get it right without thinking through the words; in response to my cognitive poverty, Adam Back suggested we call it a Nakamoto signature.
That's actually about right in cryptology terms. When a new form of cryptography turns up and it lacks an easy name, it's very often called after its inventor. Famous companions to this tradition include RSA for Rivest, Shamir, Adleman; Schnorr for the name of the signature that Bitcoin wants to move to. Rijndael is our most popular secret key algorithm, from the inventors names, although you might know it these days as AES. In the old days of blinded formulas to do untraceable cash, the frontrunners were signatures named after Chaum, Brands and Wagner.
On to the Nakamoto signature. Why is it useful to label it so?
Because, with this literary device, it is now much easier to talk about the blockchain. Watch this:
The blockchain is a shared ledger where each new block of transactions - the 10 minutes thing - is signed with a Nakamoto signature.
Less than 25 words! Outstanding! We can now separate this discussion into two things to understand: firstly: what's a shared ledger, and second: what's the Nakamoto signature?
Each can be covered as a separate topic. For example:
the shared ledger can be seen as a series of blocks, each of which is a single document presented for signature. Each block consists of a set of transactions built on the previous set. Each succeeding block changes the state of the accounts by moving money around; so given any particular state we can create the next block by filling it with transactions that do those money moves, and signing it with a Nakamoto signature.
Having described the the shared ledger, we can now attack the Nakamoto signature:
A Nakamoto signature is a device to allow a group to agree on a shared document. To eliminate the potential for inconsistencies aka disagreement, the group engages in a lottery to pick one person's version as the one true document. That lottery is effected by all members of the group racing to create the longest hash over their copy of the document. The longest hash wins the prize and also becomes a verifiable 'token' of the one true document for members of the group: the Nakamoto signature.
That's it, in a nutshell. That's good enough for most people. Others however will want to open that nutshell up and go deeper into the hows, whys and whethers of it all. You'll note I left plenty of room for argument above; Economists will look at the incentive structure in the lottery, and ask if a prize in exchange for proof-of-work is enough to encourage an efficient agreement, even in the presence of attackers? Computer scientists will ask 'what happens if...' and search for ways to make it not so. Entrepreneurs might be more interested in what other documents can be signed this way. Cryptographers will pounce on that longest hash thing.
But for most of us we can now move on to the real work. We haven't got time for minutia. The real joy of the Nakamoto signature is that it breaks what was one monolithic incomprehensible problem into two more understandable ones. Divide and conquer!
The Nakamoto signature needs to be a thing. Let it be so!
NB: This article was kindly commented on by Ada Lovelace and Adam Back.
February 16, 2015
Google's bebapay to close down, Safaricom shows them how to do it
In news today, BebaPay, the google transit payment system in Nairobi, is shutting down. As predicted in this blog, the payment system was a disaster from the start, primarily because it did not understand the governance (aka corruption) flow of funds in the industry. This resulted in the erstwhile operators of the system conspiring to make sure it would not work.

How do I know this? I was in Nairobi when it first started up, and we were analysing a lot of market sectors for payments technology at the time. It was obvious to anyone who had actually taken a ride on a Matatu (the little buses that move millions of Kenyans to work) that automating their fares was a really tough sell. And, once we figured out how the flow of funds for the Matatu business worked, from inside sources, we knew a digital payments scheme was dead on arrival.
As an aside there is a play that could have been done there, in a nearby sector, which is the tuk-tuks or motorbike operators that are clustered at every corner. But that's a case-study for another day. The real point to take away here is that you have to understand the real flows of money, and when in Africa, understand that what we westerners call corruption means that our models are basically worthless.
Or in shorter terms, take a ride on the bus before you decide to improve it.
Meanwhile, in other news, Safaricom are now making a big push into the retail POS world. This was also in the wings at the time, and when I was there, we got the inside look into this field due to a friend who was running a plucky little mPesa facilitation business for retails. He was doing great stuff, but the elephant in the room was always Safaricom, and it was no polite toilet-trained beast. Its reputation for stealing other company's business ideas was a legend; in the payment systems world, you're better off modelling Safaricom as a bank.
Ah, that makes more sense... You'll note that Safaricom didn't press over-hard to enter the transit world.
The other great takeway here is that westerners should not enter into the business of Africa lightly if at all. Westerners' biggest problem is that they don't understand the conditions there, and consequently they will be trapped in a self-fulfilling cycle of western psuedo-economic drivel. Perhaps even more surprising, they also can't turn to their reliable local NGOs or government partners or consultancies because these people are trained & paid by the westerners to feed back the same academic models.
 How to break out of that trap economically is a problem I've yet to figure out. I've now spent a year outside the place, and I can report that I have met maybe 4 or 5 people amongst say 100 who actually understand the difference? Not a one of these is employed by an NGO, aid department, consultant, etc. And, these impressive organisations around the world that specialise in Africa are in this situation -- totally misinformed and often dangerously wrong.
How to break out of that trap economically is a problem I've yet to figure out. I've now spent a year outside the place, and I can report that I have met maybe 4 or 5 people amongst say 100 who actually understand the difference? Not a one of these is employed by an NGO, aid department, consultant, etc. And, these impressive organisations around the world that specialise in Africa are in this situation -- totally misinformed and often dangerously wrong.
I feel very badly for the poor of the world, they are being given the worst possible help, with the biggest smile and a wad of cash to help it along its way to failure.
Which leads me to a pretty big economic problem - solving this requires teaching what I learnt in a few years over a single coffee - can't be done. I suspect you have to go there, but even that isn't saying what's what.
Luckily however the developing world -- at least the parts I saw in Nairobi -- is now emerging with its own digital skills to address their own issues. Startup labs abound! And, from what I've seen, they are doing a much better job at it than the outsiders.
So, maybe this is a problem that will solve itself? Growth doesn't happen at more than 10% pa, so patience is perhaps the answer, not anger. We can live and hope, and if an NGO does want to take a shot at the title, I'm in for the 101th coffee.
November 19, 2014
Bitcoin and the Byzantine Generals Problem -- a Crusade is needed? A Revolution?
It is commonly touted that Bitcoin solves the Byzantine Generals Problem because it deals with coordination between geographically separated points, and there is an element of attack on the communications. But I am somewhat suspicious that this is not quite the right statement.
To review "the Byzantine Generals Problem," let's take some snippets from Lamport, Shostack and Pease's seminal paper of that name:
We imagine that several divisions of the Byzantine army are camped outside an enemy city, each division commanded by its own general. The generals can communicate with one another only by messenger. After observing the enemy, they must decide upon a common plan of action. However, some of the generals may be traitors, trying to prevent the loyal generals from reaching agreement. The generals must have an algorithm to guarantee thatA. All loyal generals decide upon the same plan of action.
The loyal generals will all do what the algorithm says they should, but the traitors may do anything they wish. The algorithm must guarantee condition A regardless of what the traitors do.
The loyal generals should not only reach agreement, but should agree upon a reasonable plan. We therefore also want to insure thatB. A small number of traitors cannot cause the loyal generals to adopt a bad plan.
Lamport, Shostack and Pease, "the Byzantine Generals Problem", ACM Transactions on Programming Languages and Systems,Vol.4, No. 3, July 1982, Pages 382-401.
My criticism is one of strict weakening. Lamport et al addressed the problem of Generals communicating, but there are no Generals in the Bitcoin design. If we read Lamport, although it doesn't say it explicitly, there are N Generals, exactly, and they are all identified, being loyal or disloyal as it is stated. Which means that the Generals Problem only describes a fixed set in which everyone can authenticate each other.
While still a relevant problem, the Internet world of p2p solutions has another issue -- the sybil attack. Consider "Exposing Computationally-Challenged Byzantine Impostors" from 2005 by Aspnes, Jackson and Krishnamurthy:
Peer-to-peer systems that allow arbitrary machines to connect to them are known to be vulnerable to pseudospoofing or Sybil attacks, first described in a paper by Douceur [7], in which Byzantine nodes adopt multiple identities to break fault-tolerant distributed algorithms that require that the adversary control no more than a fixed fraction of the nodes. Douceur argues in particular that no practical system can prevent such attacks, even using techniques such as pricing via processing [9], without either using external validation (e.g., by relying on the scarceness of DNS domain names or Social Security numbers), or by making assumptions about the system that are unlikely to hold in practice. While he describes the possibility of using a system similar to Hashcash [3] for validating identities under certain very strong cryptographic assumptions, he suggests that this approach can only work if (a) all the nodes in the system have nearly identical resource constraints; (b) all identities are validated simultaneously by all participants; and (c) for "indirect validations," in which an identity is validated by being vouched for by some number of other validated identities, the number of such witnesses must exceed the maximum number of bad identities. This result has been abbreviated by many subsequent researchers [8, 11, 19-21] as a blanket statement that preventing Sybil attacks without external validation is impossible.J. Aspnes, C. Jackson, and A. Krishnamurthy, "Exposing computationally-challenged byzantine impostors," Tech. Report YALEU/DCS/TR-1332, Yale University, 2005, http://www.cs.yale.edu/homes/aspnes/papers/tr1332.pdf
Prescient, or what? The paper then goes on to argue that the solution to the sybil attack is precisely in weakening the restriction over identity: *The good guys can also duplicate*.
We argue that this impossibility result is much more narrow than it appears, because it gives the attacking nodes a significant advantage in that it restricts legitimate nodes to one identity each. By removing this restriction...
This is clearly not what Lamport et al's Generals were puzzling over in 1982, but it is as clearly an important problem, related, and one that is perhaps more relevant to Internet times.
It's also the one solved according to the Bitcoin model. If Bitcoin solved the Byzantine Generals Problem, it did it by shifting the goal posts. Where then did Satoshi move the problem to? What is his problem?
With p2p in general and Bitcoin in particular, we're talking more formally about a dynamic membership set, where the set comes together once to demand strong consensus and that set is then migrated to a distinct set for the next round, albeit with approximately the same participants.
What's that? It's more like a herd, or a school of fish. As it moves forward, sudden changes in direction cause some to fall off, others to join.
The challenge then might be to come up with a name. Scratching my head to come up with an analogue in human military affairs, it occurs that the Crusades were something like this: A large group of powerful knights, accompanied by their individual retainers, with a forward goal in mind. The group was not formed on state lines typical of warfare but religious lines, and it would for circumstances change as it moved. Some joined, while some crusaders never made it to the front; others made it and died in the fighting, and indeed some entire crusades never made it out of Europe.
Crusaders were typically volunteers, often motivated by greed, force or threat of reputation damage. There were plenty of non-aligned interests in a crusade, and for added historical bonus, they typically travelled through Byzantium or Constantinople as it was then known. And, as often bogged down there, literally falling to the Byzantine attacks of the day.
Perhaps p2p faces the Byzantine Crusaders Problem, and perhaps this is what Bitcoin has solved?
In the alternate, I've seen elsewhere that the problem is referred to as the Revolutionaries' Problem. This term also works in that it speaks to the democracy of the moment. As a group of very interested parties come together they strike out at the old ways and form a new consensus over financial and other affairs.
History will be the judge of this, but it does seem that for the sake of pedagogy and accuracy, we need a new title. Bysantium Crusaders' problem? Democratic Revolutionaries' problem? Consensus needed!
September 03, 2014
Proof of Work made useful -- auctioning off the calculation capacity is just another smart contract
 Just got tipped to Andrew Poelstra's faq on ASICs, where he says of Adam Back's Proof of Work system in Bitcoin:
Just got tipped to Andrew Poelstra's faq on ASICs, where he says of Adam Back's Proof of Work system in Bitcoin:
In places where the waste heat is directly useful, the cost of mining is merely the difference between electric heat production and ordinary heat production (here in BC, this would be natural gas). Then electricity is effectively cheap even if not actually cheap.
Which is an interesting remark. If true -- assume we're in Iceland where there is a need for lots of heat -- then Bitcoin mining can be free at the margin. Capital costs remain, but we shouldn't look a gift horse in the mouth?
My view remains, and was from the beginning of BTC when Satoshi proposed his design, that mining is a dead-weight loss to the economy because it turns good electricity into bad waste, heat. And, the capital race adds to that, in that SHA2 mining gear is solely useful for ... Bitcoin mining. Such a design cannot survive in the long run, which is a reflection of Gresham's law, sometimes expressed as the simplistic aphorism of "bad money drives out good."
Now, the good thing about predicting collapse in the long run is that we are never proven wrong, we just have to wait another day ... but as Ben Laurie pointed out somewhere or other, the current incentives encourage the blockchain mining to consume the planet, and that's not another day we want to wait for.
Not a good thing. But if we switch production to some more socially aligned pattern /such as heating/, then likely we could at least shift some of the mining to a cost-neutrality.
Why can't we go further? Why can't we make the information calculated socially useful, and benefit twice? E.g., we can search for SETI, fold some DNA, crack some RSA keys. Andrew has commented on that too, so this is no new idea:
7. What about "useful" proofs-of-work?These are typically bad ideas for all the same reasons that Primecoin is, and also bad for a new reason: from the network's perspective, the purpose of mining is to secure the currency, but from the miner's perspective, the purpose of mining is to gain the block reward. These two motivations complement each other, since a block reward is worth more in a secure currency than in a sham one, so the miner is incentivized to secure the network rather than attacking it.
However, if the miner is motivated not by the block reward, but by some social or scientific purpose related to the proof-of-work evaluation, then these incentives are no longer aligned (and may in fact be opposed, if the miner wants to discourage others from encroaching on his work), weakening the security of the network.
I buy the general gist of the alignments of incentives, but I'm not sure that we've necessarily unaligned things just by specifying some other purpose than calculating a SHA2 to get an answer close to what we already know.
Let's postulate a program that calculates some desirable property. Because that property is of individual benefit only, then some individual can pay for it. Then, the missing link would be to create a program that takes in a certain amount of money, and distributes that to nodes that run it according to some fair algorithm.
What's a program that takes in and holds money, gets calculated by many nodes, and distributes it according to an algorithm? It's Nick Szabo's smart contract distributed over the blockchain. We already know how to do that, in principle, and in practice there are many efforts out there to improve the art. Especially, see Ethereum.
 So let's assume a smart contract. Then, the question arises how to get your smart contract accepted as the block calculation for 17:20 on this coming Friday evening? That's a consensus problem. Again, we already know how to do consensus problems. But let's postulate one method: hold a donation auction and simply order these things according to the amount donated. Close the block a day in advance and leave that entire day to work out which is the consensus pick on what happens at 17:20.
So let's assume a smart contract. Then, the question arises how to get your smart contract accepted as the block calculation for 17:20 on this coming Friday evening? That's a consensus problem. Again, we already know how to do consensus problems. But let's postulate one method: hold a donation auction and simply order these things according to the amount donated. Close the block a day in advance and leave that entire day to work out which is the consensus pick on what happens at 17:20.
Didn't get a hit? If your smart contract doesn't participate, then at 17:30 it expires and sends back the money. Try again, put in more money? Or we can imagine a variation where it has a climbing ramp of value. It starts at 10,000 at 17:20 and then adds 100 for each of the next 100 blocks then expires. This then allows an auction crossing, which can be efficient.
An interesting attack here might be that I could code up a smartcontract-block-PoW that has a backdoor, similar to the infamous DUAL_EC random number generator from NIST. But, even if I succeed in coding it up without my obfuscated clause being spotted, the best I can do is pay for it to reach the top of the rankings, then win my own payment back as it runs at 17:20.
With such an attack, I get my cake calculated and I get to eat it too. As far as incentives go to the miner, I'd be better off going to the pub. The result is still at least as good as Andrew's comment, "from the network's perspective, the purpose of mining is to secure the currency."
What about the 'difficulty' factor? Well, this is easy enough to specify, it can be part of the program. The Ethereum people are working on the basis of setting enough 'gas' to pay for the program, so the notion of 'difficulty' is already on the table.
I'm sure there is something I haven't thought of as yet. But it does seem that there is more of a benefit to wring from the mining idea. We have electricity, we have capital, and we have information. Each of those is a potential for a bounty, so as to claw some sense of value back instead of just heating the planet to keep a bunch of libertarians with coins in their pockets. Comments?
April 20, 2014
Code as if everyone is the thief.
This is what financial cryptography is about (h/t to Jeroen). Copied from Qi of the TheCodelessCode:
 I have some sympathy for the developer: this bug is so epic they gave it a website and ITS OWN LOGO. Even 'goto-fail' doesn't have a logo.")
A novice asked of master Bawan: Say something about the Heartbleed Bug.
Said Bawan: Chiuyin, the Governors treasurer, is blind as an earthworm. A thief may give him a coin of tin, claim that it is silver and receive change. When the treasury is empty, which man is the villain? Speak right and I will spare you all blows for one week. Speak wrong and my staff will fly!
The novice thought: if I say the thief, Bawan will surely strike me, for it is the treasurer who doles out the coins. But if I say the treasurer he will also strike me, for it is the thief who takes advantage of the situation.
When the pause grew too long, Bawan raised his staff high. Suddenly enlightened, the novice cried out: The Governor! For who else made this blind man his treasurer?
Bawan lowered his staff. And who is the Governor?
Said the novice: All who might have cried out this man is blind! but failed to notice, or even to examine him.
Bawan nodded. This is the first lesson. Too easily we praise Open Source, saying smugly to each other, under ten thousand eyeballs, every bug is laid bare. Yet when the ten thousand avert their gaze, they are no more useful than the blind man. And now that I have spared you all blows for one week, stand at ease and tell me: what is the second lesson?
Said the novice: Surely, I have no idea.
Bawan promptly struck the novices skull with his staff. The boy fell to the floor, unconscious.
As he stepped over the prone body, Bawan remarked: Code as if everyone is the thief.
April 06, 2014
The evil of cryptographic choice (2) -- how your Ps and Qs were mined by the NSA
One of the excuses touted for the Dual_EC debacle was that the magical P & Q numbers that were chosen by secret process were supposed to be defaults. Anyone was at liberty to change them.

Epic fail! It turns out that this might have been just that, a liberty, a hope, a dream. From last week's paper on attacking Dual_EC:
"We implemented each of the attacks against TLS libraries described above to validate that they work as described. Since we do not know the relationship between the NIST- specified points P and Q, we generated our own point Q′ by first generating a random value e ←R {0,1,...,n−1} where n is the order of P, and set Q′ = eP. This gives our trapdoor value d ≡ e−1 (mod n) such that dQ′ = P. (Our random e and its corresponding d are given in the Appendix.) We then modified each of the libraries to use our point Q′ and captured network traces using the libraries. We ran our attacks against these traces to simulate a passive network attacker.
In the new paper that measures how hard it was to crack open TLS when corrupted by Dual_EC, the authors changed the Qs to match the P delivered, so as to attack the code. Each of the four libraries they had was in binary form, and it appears that each had to be hard-modified in binary in order to mind their own Ps and Qs.
So did (a) the library implementors forget that issue? or (b) NIST/FIPS in its approval process fail to stress the need for users to mind their Ps and Qs? or (c) the NSA knew all along that this would be a fixed quantity in every library, derived from the standard, which was pre-derived from their exhaustive internal search for a special friendly pair? In other words:
"We would like to stress that anybody who knows the back door for the NIST-specified points can run the same attack on the fielded BSAFE and SChannel implementations without reverse engineering.
Defaults, options, choice of any form has always been known as bad for users, great for attackers and a downright nuisance for developers. Here, the libraries did the right thing by eliminating the chance for users to change those numbers. Unfortunately, they, NIST and all points thereafter, took the originals without question. Doh!
April 01, 2014
The IETF's Security Area post-NSA - what is the systemic problem?
In the light of yesterday's newly revealed attack by the NSA on Internet standards, what are the systemic problems here, if any?
I think we can question the way the IETF is approaching security. It has taken a lot of thinking on my part to identify the flaw(s), and not a few rants, with many and aggressive defences and counterattacks from defenders of the faith. Where I am thinking today is this:
First the good news. The IETF's Working Group concept is far better at developing general standards than anything we've seen so far (by this I mean ISO, national committees, industry cartels and whathaveyou). However, it still suffers from two shortfalls.
1. the Working Group system is more or less easily captured by the players with the largest budget. If one views standards as the property of the largest players, then this is not a problem. If OTOH one views the Internet as a shared resource of billions, designed to serve those billions back for their efforts, the WG method is a recipe for disenfranchisement. Perhaps apropos, spotted on the TLS list by Peter Gutmann:
Documenting use cases is an unnecessary distraction from doing actual work. You'll note that our charter does not say "enumerate applications that want to use TLS".
I think reasonable people can debate and disagree on the question of whether the WG model disenfranchises the users, because even though a a company can out-manouver the open Internet through sheer persistence and money, we can still see it happen. In this, IETF stands in violent sunlight compared to that travesty of mouldy dark closets, CABForum, which shut users out while industry insiders prepared the base documents in secrecy.
I'll take the IETF any day, except when...
2. the Working Group system is less able to defend itself from a byzantine attack. By this I mean the security concept of an attack from someone who doesn't follow the rules, and breaks them in ways meant to break your model and assumptions. We can suspect byzantium disclosures in the fingered ID:
The United States Department of Defense has requested a TLS mode which allows the use of longer public randomness values for use with high security level cipher suites like those specified in Suite B [I-D.rescorla-tls-suiteb]. The rationale for this as stated by DoD is that the public randomness for each side should be at least twice as long as the security level for cryptographic parity, which makes the 224 bits of randomness provided by the current TLS random values insufficient.
Assuming the story as told so far, the US DoD should have added "and our friends at the NSA asked us to do this so they could crack your infected TLS wide open in real time."
Such byzantine behaviour maybe isn't a problem when the industry players are for example subject to open observation, as best behaviour can be forced, and honesty at some level is necessary for long term reputation. But it likely is a problem where the attacker is accustomed to that other world: lies, deception, fraud, extortion or any of a number of other tricks which are the tools of trade of the spies.
Which points directly at the NSA. Spooks being spooks, every spy novel you've ever read will attest to the deception and rule breaking. So where is this a problem? Well, only in the one area where they are interested in: security.
Which is irony itself as security is the field where byzantine behaviour is our meat and drink. Would the Working Group concept past muster in an IETF security WG? Whether it does or no depends on whether you think it can defend against the byzantine attack. Likely it will pass-by-fiat because of the loyalty of those involved, I have been one of those WG stalwarts for a period, so I do see the dilemma. But in the cold hard light of sunlight, who is comfortable supporting a WG that is assisted by NSA employees who will apply all available SIGINT and HUMINT capabilities?
Can we agree or disagree on this? Is there room for reasonable debate amongst peers? I refer you now to these words:

On September 5, 2013, the New York Times [18], the Guardian [2] and ProPublica [12] reported the existence of a secret National Security Agency SIGINT Enabling Project with the mission to actively [engage] the US and foreign IT industries to covertly influence and/or overtly leverage their commercial products designs. The revealed source documents describe a US $250 million/year program designed to make [systems] exploitable through SIGINT collection by inserting vulnerabilities, collecting target network data, and influencing policies, standards and specifications for commercial public key technologies. Named targets include protocols for TLS/SSL, https (e.g. webmail), SSH, encrypted chat, VPNs and encrypted VOIP.
The documents also make specific reference to a set of pseudorandom number generator (PRNG) algorithms adopted as part of the National Institute of Standards and Technology (NIST) Special Publication 800-90 [17] in 2006, and also standardized as part of ISO 18031 [11]. These standards include an algorithm called the Dual Elliptic Curve Deterministic Random Bit Generator (Dual EC). As a result of these revelations, NIST reopened the public comment period for SP 800-90.
And as previously written here. The NSA has conducted a long term programme to breach the standards-based crypto of the net.
As evidence of this claim, we now have *two attacks*, being clear attempts to trash the security of TLS and freinds, and we have their own admission of intent to breach. In their own words. There is no shortage of circumstantial evidence that NSA people have pushed, steered, nudged the WGs to make bad decisions.
I therefore suggest we have the evidence to take to a jury. Obviously we won't be allowed to do that, so we have to do the next best thing: use our collective wisdom and make the call in the public court of Internet opinion.
My vote is -- guilty.
One single piece of evidence wasn't enough. Two was enough to believe, but alternate explanations sounded plausible to some. But we now have three solid bodies of evidence. Redundancy. Triangulation. Conclusion. Guilty.
Where it leaves us is in difficulties. We can try and avoid all this stuff by e.g., avoiding American crypto, but it is a bit broader that that. Yes, they attacked and broke some elements of American crypto (and you know what I'm expecting to fall next.). But they also broke the standards process, and that had even more effect on the world.
It has to be said that the IETF security area is now under a cloud. Not only do they need to analyse things back in time to see where it went wrong, but they also need some concept to stop it happening in the future.
The first step however is to actually see the clouds, and admit that rain might be coming soon. May the security AD live in interesting times, borrow my umbrella?
March 31, 2014
NSA caught again -- deliberate weakening of TLS revealed!?
In a scandal that is now entertaining that legal term of art "slam-dunk" there is news of a new weakness introduced into the TLS suite by the NSA:
We also discovered evidence of the implementation in the RSA BSAFE products of a non-standard TLS extension called "Extended Random." This extension, co-written at the request of the National Security Agency, allows a client to request longer TLS random nonces from the server, a feature that, if it enabled, would speed up the Dual EC attack by a factor of up to 65,000. In addition, the use of this extension allows for for attacks on Dual EC instances configured with P-384 and P-521 elliptic curves, something that is not apparently possible in standard TLS.
This extension to TLS was introduced 3 distinct times through an open IETF Internet Draft process, twice by an NSA employee and a well known TLS specialist, and once by another. The way the extension works is that it increases the quantity of random numbers fed into the cleartext negotiation phase of the protocol. If the attacker has a heads up to those random numbers, that makes his task of divining the state of the PRNG a lot easier. Indeed, the extension definition states more or less that:
4.1. Threats to TLS
When this extension is in use it increases the amount of data that an attacker can inject into the PRF. This potentially would allow an attacker who had partially compromised the PRF greater scope for influencing the output.
The use of Dual_EC, the previously fingered dodgy standard, makes this possible. Which gives us 2 compromises of the standards process that when combined magically work together.
Our analysis strongly suggests that, from an attacker's perspective, backdooring a PRNG should be combined not merely with influencing implementations to use the PRNG but also with influencing other details that secretly improve the exploitability of the PRNG.
Red faces all round.
March 06, 2014
Eat this, Bitcoin -- Ricardo now has cloud!
Ricardo is now cloud-enabled.
Which I hasten to add, is not the same thing as cloud-based, if your head is that lofty. Not the same thing, at all, no sir, feet firmly placed on planet earth!
Here's the story. Apologies in advance for this self-indulgent rant, but if you are not a financial cryptographer, the following will appear to be just a lot of mumbo jumbo and your time is probably better spent elsewhere... With that warning, let's get our head up in the clouds for a while.
As a client-server construction, much like a web arrangement, and like Bitcoin in that the client is in charge, the client is of course vulnerable to loss/theft. So a backup of some form is required. Much analysis revealed that backup had to be complete, it had to be off-client, and also system provided.
That work has now taken shape and is delivering backups in bench-conditions. The client can backup its entire database into a server's database using the same point-to-point security protocol and the same mechanics as the rest of the model. The client also now has a complete encrypted object database using ChaCha20 as the stream cipher and Poly1305 as the object-level authentication layer. This gets arranged into a single secured stream which is then uploaded dynamically to the server. Which latter offers a service that allows a stream to be built up over time.
Consider how a client works: Do a task? Make a payment? Generate a transaction!
Remembering always it's only a transaction when it is indeed transacted, this means that the transaction has to be recorded into the database. Our little-database-that-could now streams that transaction onto the end of its log, which is now stream-encrypted, and a separate thread follows the appends and uploads additions to the server. (Just for those who are trying to see how this works in a SQL context, it doesn't. It's not a SQL database, it follows the transaction-log-is-the-database paradigm, and in that sense, it is already stream oriented.)
In order to prove this client-to-server and beginning to end, there is a hash confirmation over the local stream and over the server's file. When they match, we're golden. It is not a perfect backup because the backup trails by some amount of seconds; it is not therefore /transactional/. People following the latency debate over Bitcoin will find that amusing, but I think this is possibly a step too far in our current development; a backup that is latent to a minute or so is probably OK for now, and I'm not sure if we want to try transactional replication on phone users.
This is a big deal for many reasons. One is that it was a quite massive project, and it brought our tiny startup to a complete standstill on the technical front. I've done nothing but hack for about 3 months now, which makes it a more difficult project than say rewriting the entire crypto suite.
Second is the reasoning behind it. Our client side asset management software is now going to be using in a quite contrary fashion to our earlier design anticipations. It is going to manage the entire asset base of what is in effect a financial institution (FI), or thousands of them. Yet, it's going to live on a bog-standard Android phone, probably in the handbag of the Treasurer as she roves around the city from home to work and other places.
Can you see where this is going? Loss, theft, software failure, etc. We live in one of the most crime ridden cities on the planet, and therefore we have to consider that the FI's entire book of business can be stolen at any time. And we need to get the Treasurer up and going with a new phone in short order, because her customers demand it.
Add in some discussions about complexity, and transactions, and social networking in the app, etc etc and we can also see pretty easily that just saving the private keys will not cut the mustard. We need the entire state of phone to be saved, and recovered, on demand.
But wait, you say! Of course the solution is cloud, why ever not?
No, because, cloud is insecure. Totally. Any FI that stores their customer transactions in the cloud is in a state of sin, and indeed it is in some countries illegal to even consider it. Further, even if the cloud is locally run by the institution, internally, this exposes the FI and the poor long suffering customer to fantastic opportunities for insider fraud. What I failed to mention earlier is that my user base considers corruption to be a daily event, and is exposed to frauds continually, including from their FIs. Which is why Ricardo fills the gap.
When it comes to insider fraud, cloud is the same as fog. Add in corruption and it's now smog. So, cloud is totally out, or, cloud just means you're being robbed blind like you always were, so there is no new offering here. Following the sense of Digicash from 2 decades earlier, and perhaps Bitcoin these days, we set the requirement: The server or center should not be able to forge transactions, which, as a long-standing requirement (insert digression here into end-to-end evidence and authentication designs leading to triple entry and the Ricardian Contract, and/or recent cases backing FIs doing the wrong thing).
To bring these two contradictions together however was tricky. To resolve, I needed to use a now time-honoured technique theorised by the capabilities school, and popularised by amongst others Pelle's original document service called wideword.net and Zooko's Tahoe-LAFS: the data that is uploaded over UDP is encrypted to keys only known to the clients.
And that is what happens. As my client software database spits out data in an append-only stream (that's how all safe databases work, right??) it stream-encrypts this and then sends the stream up to the server. So the server simply has to offer something similar to the Unix file metaphor: create, read, write, delete *and append*. Add in a hash feature to confirm, and we're set. (It's similar enough to REST/CRUD that it's worth a mention, but different enough to warrant a disclaimer.)
A third reason this is a big deal is because the rules of the game have changed. In the 1990s we were assuming a technical savvy audience, ones who could manage public keys and backups. The PGP generation, if you like. Now, we're assuming none of that. The thing has to work, and it has to keep working, regardless of user foibles. This is the Apple-Facebook generation.
This benchmark also shines adverse light on Bitcoin. That community struggles to deal with theft, lurching from hack to bug to bankruptcy. As a result of their obsession over The Number One Criminal (aka the government) and with avoiding control at the center, they are blinded to the costly reality of criminals 2 through 100. If Bitcoin hypothetically were to establish the user-friendly goal that they can keep going in the face of normal 2010s user demands and failure modes, it'd be game over. They basically have to handwave stuff away as 'user responsibility' but that doesn't work any more. The rules of the game have changed, we're not in the 1990s anymore, and a comprehensive solution is required.
Finally, once you can do things like cloud, it opens up the possibilities for whole new features and endeavours. That of course is what makes cloud so exciting for big corporates -- to be able to deliver great service and features to customers. I've already got a list of enhancements we can now start to put in, and the only limitation I have now is capital to pay the hackers. We really are at the cusp of a new generation of payment systems; crypto-plumbing is fun again!
January 30, 2014
Hard Truths about the Hard Business of finding Hard Random Numbers
Editorial note: this rant was originally posted here but has now moved to a permanent home where it will be updated with new thoughts.
As many have noticed, there is now a permathread (Paul's term) on how to do random numbers. It's always been warm. Now the arguments are on solid simmer, raging on half a dozen cryptogroups, all thanks to the NSA and their infamous breach of NIST, American industry, mom's apple pie and the privacy of all things from Sunday school to Angry Birds.
Why is the topic of random numbers so bubbling, effervescent, unsatisfying? In short, because generators of same (RNGs), are *hard*. They are in practical experience trickier than most of the other modules we deal with: ciphers, HMACs, public key, protocols, etc.
Yet, we have come a long way. We now have a working theory. When Ada put together her RNG this last summer, it wasn't that hard. Out of our experience, herein is a collection of things we figured out; with the normal caveat that, even as RNs require stirring, the recipe for 'knowing' is also evolving.
- Use what your platform provides. Random numbers are hard, which is the first thing you have to remember, and always come back to. Random numbers are so hard, that you have to care a lot before you get involved. A hell of a lot. Which leads us to the following rules of thumb for RNG production.
- Use what your platform provides.
- Unless you really really care a lot, in which case, you have to write your own RNG.
- There isn't a lot of middle ground.
- So much so that for almost all purposes, and almost all users, Rule #1 is this: Use what your platform provides.
- When deciding to breach Rule #1, you need a compelling argument that your RNG delivers better results than the platform's. Without that compelling argument, your results are likely to be more random than the platform's system in every sense except the quality of the numbers.
- Software is our domain.
- Software is unreliable. It can be made reliable under bench conditions, but out in the field, any software of more than 1 component (always) has opportunities for failure. In practice, we're usually talking dozens or hundreds, so failure of another component is a solid possibility; a real threat.
- What about hardware RNGs? Eventually they have to go through some software, to be of any use. Although there are some narrow environments where there might be a pure hardware delivery, this is so exotic, and so alien to the reader here, that there is no point in considering it. Hardware serves software. Get used to it.
- As a practical reliability approach, we typically model every component as failing, and try and organise our design to carry on.
- Security is also our domain, which is to say we have real live attackers.
- Many of the sciences rest on a statistical model, which they can do in absence of any attackers. According to Bernoulli's law of big numbers, models of data will even out over time and quantity. In essence, we then can use statistics to derive strong predictions. If random numbers followed the law of big numbers, then measuring 1000 of them would tell us with near certainty that the machine was good for another 1000.
- In security, we live in a byzantine world, which means we have real live attackers who will turn our assumptions upside down, out of spite. When an attacker is trying to aggressively futz with your business, he will also futz with any assumptions and with any tests or protections you have that are based on those assumptions. Once attackers start getting their claws and bits in there, the assumption behind Bernoulli's law falls apart. In essence this rules out lazy reliance on statistics.
- No Test. There is no objective test of random numbers, because it is impossible to test for unpredictability. Which in practical terms means that you cannot easily write a test for it, nor can any test you write do the job you want it to do. This is the key unfortunate truth that separates RNs out from ciphers, etc (which latter are amenable to test vectors, and with vectors in hand, they become tractable).
- Entropy. Everyone talks about entropy so we must too, else your future RNG will exhibit the wrong sort of unpredictability. Sadly, entropy is not precisely the answer, enough such that talking about is likely missing the point. If we could collect it reliably, RNs would be easy. We can't so it isn't.
- Entropy is manifest physical energy, causing events which cannot be predicted using any known physical processes, by the laws of science. Here, we're typically talking about quantum energy, such as the unknown state of electrons, which can collapse either way into some measurable state, but it can only be known by measurement, and not predicted earlier. It's worth noting that quantum energy abounds inside chips and computers, but chips are designed to reduce the noise, not increase it, so turning chip entropy into RNs is not as easy as talking about it.
- There are objective statements we can make about entropy. The objective way to approach the collection of entropy is to carefully analyse the properties of the system and apply science to estimate the amount of (e.g.) quantum uncertainty one can derive from it. This is possible and instructive, and for a nice (deep) example of this, see John Denker's Turbid.
- At the level of implementation, objective statements about entropy fail for 2 reasons. Let's look at those, as understanding these limitations on objectivity is key to understanding why entropy does not serve us so willingly.
- Entropy can be objectively analysed as long as we do not have an attacker. An attacker can deliver a faulty device, can change the device, and can change the way the software deals with the device at the device driver level. And much more...
- This approach is complete if we have control of our environment. Of course, it is very easy to say Buy the XYZ RNG and plug it in. But many environments do not have that capability, often enough we don't know our environment, and the environment can break or be changed. Examples: rack servers lacking sound cards; phones; VMs; routers/firewalls; early startup on embedded hardware.
- In conclusion, entropy is too high a target to reach. We can reach it briefly, in controlled environments, but not enough to make it work for us. Not enough, given our limitations.
- CSRNs. The practical standard to reach therefore is what we call Cryptographically Secure Random Numbers.
- Cryptographically secure random numbers (or CSRNs) are numbers that are not predictable /to an attacker/. In contrast to entropy, we might be able to predict our CSRNs, but our enemies cannot. This is a strictly broader and easier definition than entropy, which is needed because collecting entropy is too hard, as above.
- Note our one big assumption here: that we can determine who is our attacker and keep him out, and determine who is friendly and let them in. This is a big flaw! But it happens to be a very basic and ever-present one in security, so while it exists, it is one we can readily work with.
- Design. Many experiments and research seem to have settled on the following design pattern, which we call a Trident Design Pattern:
Entropy collector ----\
In short, many collectors of entropy feed their small contributions in to a Mixer, which uses the melded result to seed an Expander. The high level caller (application) uses this Expander to request her random numbers.
\ _____ _________ / \ / \
Entropy collector ---->( mixer )----->( expansion )-----> RNs
\_____/ \_________/
/
Entropy collector ----/ - Collectors. After all the above bad news, what is left in the software toolkit is: redundancy .
- A redundant approach tells us to draw our RNs from different places. The component that collects RNs from one place is called a Collector. Therefore we want many Collectors.
- Each of the many places should be uncorrelated with each other. If one of these were to fail, it would be unlikely that others also would fail, as they are uncorrelated. Typical studies of fault-tolerant systems often suggest the number 3 as the target.
-
 Some common collector ideas are:
Some common collector ideas are:- the platform's own RNG, as a Collector into your RNG
- any CPU RNG such as Intel's RDRAND,
- measuring the difference between two uncorrelated clocks,
- timings and other measurands from events (e.g., mouse clicks and locations),
- available sensors (movement on phones),
- differences seen in incoming new business packets,
- a roughly protected external source such as a business feed,
- An attacker is assumed to be able to take a poke at one or two of these sources, but not all. If the attacker can futz with all our sources, this implies that he has more or less unlimited control over our entire machine. In which case, it's his machine, and not ours. We have bigger problems than RNs.
- We tend to want more numbers than fault-tolerant reliability suggests because we want to make it harder for the attacker. E.g., 6 would be a good target.
- Remember, we want maximum uncorrelation. Adding correlated collectors doesn't improve the numbers.
- Because we have redundancy, on a large scale, we are not that fussed about the quality of each Collector. Better to add another collector than improve the quality of one of them by 10%. This is an important benefit of redundancy, we don't have to be paranoid about the quality of this code.
- Mixer. Because we want the best and simplest result delivered to the caller, we have to take the output of all those above Collectors, mix them together, and deliver downstream.
- The Mixer is the trickiest part of it all. Here, you make or break. Here, you need to be paranoid. Careful. Seek more review.
- The Mixer has to provide some seed numbers of say 128-512 bits to the Expander (see below for rationale). It has to provide this on demand, quickly, without waiting around.
- There appear to be two favourite designs here: Push or Pull. In Push the collectors send their data directly into Mixer, forcing it to mix it in as it's pushed in. In contrast, a Pull design will have the Mixer asking the Collectors to provide what they have right now. This in short suggests that in a Push design the Mixer has to have a cache, while in Pull mode, the Collectors might be well served in having caches within themselves.
- Push or Mixer-Cache designs are probably more popular. See Yarrow and Fortuna as perhaps the best documented efforts.
- We wrote our recent Trident effort (AdazPRING) using Pull. The benefits include: simplified API as it is direct pull all the way through; no cache or thread in mixer; and as the Collectors better understand their own flow, so they better understand the need for caching and threading.
- Expander. Out of the Mixer comes some nice RNs, but not a lot. That's because good collectors are typically not firehoses but rather dribbles, and the Mixer can't improve on that, as, according to the law of thermodynamics, it is impossible to create entropy.
- The caller often wants a lot of RNs and doesn't want to wait around.
- To solve the mismatch between the Mixer output and the caller's needs, we create an expansion function or Expander. This function is pretty simple: (a) it takes a small seed and (b) turns that into a hugely long stream. It could be called the Firehose...
- Recalling our truth above of (c) CSRNs being the goal, not entropy, we now have a really easy solution to this problem: Use a cryptographic stream cipher. This black box takes a small seed (a-check!) and provides a near-infinite series of bytes (b-check!) that are cryptographically secure (c-check!). We don't care about the plaintext, but by the security claims behind the cipher, the stream is cryptographically unpredictable without access to the seed.
- Super easy: Any decent, modern, highly secure stream cipher is probably good for this application. Our current favourite is ChaCha20 but any of the NESSIE set would be fine.
- In summary, the Expander is simply this: when the application asks for a PRNG, we ask the Mixer for a seed, initialise a stream cipher with the seed, and return it back to the user. The caller sucks on the output of the stream cipher until she's had her fill!
- Subtleties.
- When a system first starts up there is often a shortage of easy entropy to collect. This can lead to catastrophic results if your app decides that it needs to generate high-value keys as soon as it starts up. This is a real problem -- scans of keys on the net have found significant numbers that are the same, which is generally traced to the restart problem. To solve this, either change the app (hard) ... or store some entropy for next time. How you do this is beyond scope.
- Then, assuming the above, the problem is that your attacker can do a halt, read off your RNG's state in some fashion, and then use it for nefarious purposes. This is especially a problem with VMs. We therefore set the goal that the current state of the RNG cannot be rolled forward nor backwards to predict prior or future uses. To deal with this, a good RNG will typically:
- stir fresh entropy into its cache(s) even if not required by the callers. This can be done (e.g.) by feeding ones own Expander's output in, or by setting a timer to poll the Collectors.
- Use hash whiteners between elements. Typically, a SHA digest or similar will be used to protect the state of a caching element as it passes its input to the next stage.
- As a technical design argument, the only objective way that you can show that your design is at least as good as or better than the platform-provided RNG is the following:
- Very careful review and testing of the software and design, and especially the Mixer; and
- including the platform's RNG as a Collector.
- Business Justifications.
As you can see, doing RNGs is hard! Rule #1 -- use what the platform provides. You shouldn't be doing this. About the only rationales for doing your own RNG are the following.
- Your application has something to do with money or journalism or anti-government protest or is a CVP. By money, we mean Bitcoin or other forms of hard digital cash, not online banking. The most common CVP or centralised vulnerability party (aka TTP or trusted third party) is the Certification Authority.
- Your operating platform is likely to be attacked by a persistent and aggressive attacker. This might be true if the platform is one of the following: any big American or government controlled software, Microsoft Windows, Java (code, not applets), any mobile phone OS, COTS routers/firewalls, virtual machines (VMs).
- You write your own application software, your own libraries *and* your own crypto!
- You can show objectively that you can do a better job.

That all said, good luck! Comments to the normal place, please, and Ed's note: this will improve in time.
January 20, 2014
Digital Currencies get their mojo back: the Ripple protocol
 I was pointed to Ripple and found it was actually a protocol (I thought it was a business, that's the trap with slick marketing). Worth a quick look. To my surprise, it was actually quite neat. However, tricks and traps abound, so this is a list of criticisms. I am hereby going to trash certain features of the protocol, but I'm trying to do it in the spirit of, please! Fix these things before it is too late. Been there, got the back-ache from the t-shirt made of chain mail. The cross you are building for yourself will be yours forever!
I was pointed to Ripple and found it was actually a protocol (I thought it was a business, that's the trap with slick marketing). Worth a quick look. To my surprise, it was actually quite neat. However, tricks and traps abound, so this is a list of criticisms. I am hereby going to trash certain features of the protocol, but I'm trying to do it in the spirit of, please! Fix these things before it is too late. Been there, got the back-ache from the t-shirt made of chain mail. The cross you are building for yourself will be yours forever!
Ripple's low level protocol layout is about what Gary Howland's SOX1 tried to look like, with more bells and whistles. Ripple is a protocol that tries to do the best of today's ideas that are around (with a nod towards Bitcoin), and this is one of its failings: It tries to stuff *everything* into it. Big mistake. Let's look at this with some choice elements.
Numbers: Here are the numbers it handles:

1: 16-bit unsigned integer
2: 32-bit unsigned integer
3: 64-bit unsigned integer
6: Currency Amount
16: 8-bit unsigned integer
17: 160-bit unsigned integer
Positive. One thing has been spotted and spotted well: in computing and networking we typically do not need negative numbers, and in the rare occasions we do, we can handle it with flags. Same with accounting. Good!
Now, the negatives.
First bad: Too many formats! It may not be clear to anyone doing this work de novo, but it is entirely clear to me now that I am in SOX3 - that is, the third generation of not only the basic formats but the suite of business objects - that the above is way too complicated.
x.509 and PGP formats had the same problem: too many encodings. Thinking about this, I've decided the core problem is historical and philosophical. The engineers doing the encodings are often highly adept at hardware, and often are seduced by the layouts in hardware. And they are often keen on saving every darn bit, which requires optimising the layout up the wazoo! Recall the old joke, sung to the Monty Python tune:
Every bit is great,
If a bit gets wasted,
God gets quite irate!
But this has all changed. Now we deal in software, and scripting languages have generally pointed the way here. In programming and especially in network layouts, we want *one number*, and that number has to cope with all we throw at it. So what we really want is a number that goes from 0 to infinity. Luckily we have that, from the old x.509/telco school. Here's a description taken from SDP1:
Compact Integer A Compact Integer is one that expands according to the size of the unsigned integer it carries. ...
A Compact Integer is formed from one to five bytes in sequence. If the leading (sign) bit in each byte is set, then additional bytes follow. If a byte has the sign bit reset (0) then this is the last byte. The unsigned integer is constructed by concatenating the lower order 7 bits in each byte.
A one byte Compact Integer holds an integer of 0 to 127 in the 7 lower order bits, with the sign bit reset to zero. A two byte Compact Integer can describe from 128 to 16383 (XXXX check). The leading byte has the sign bit set (1) and the trailing byte has the sign bit reset (0).
That's it (actually, it can be of infinite length, unlike the description above). Surprisingly, everything can be described in this. In the evolution of SOX, we started out with all the above fields listed by Ripple, and they all fell by the wayside. Now, all business objects use CompactInts, all the way through, for everything. Why? Hold onto that question, we'll come back to it...
Second bad: Let's look at Ripple's concept of currencies:
Native CurrencyNative amounts are indicated by the most-significant bit (0x8000000000000000) being clear. The remaining 63 bits represent a sign-and-magnitude integer. Positive amounts are encoded with the second highest bit (0x4000000000000000) set. The lower 62 bits denote the absolute value.
Ripple/IOU Currencies
Amounts of non-native currencies are indicated by the most-significant bit (0x8000000000000000) being set. They are encoded as a 64-bit raw amount followed by a 160-bit currency identifier followed by a 160-bit issuer. The issuer is always present, even if zero to indicate any issuer is acceptable.
The 64-bit raw amount is encoded with the most-significant bit set and the second most significant bit set if the raw amount is greater than zero. If the raw amount is zero, the remaining bits are zero. Otherwise, the remaining bits encode the mantissa (between 10^15 and 10^16-1) and exponent.
Boom! *Ripple puts semantics into low level syntax*. Of course, the result is a mess. Trying to pack too much business information into the layout has caused an explosion of edge cases.
What is going on here is that the architects of ripple protocol have not understood the power of OO. The notion of a currency is a business concept, not a layout. The packets that do things like transactions are best left to the business layer, and those packets will define what a currency amount means. And, they'll do it in the place where limits can be dealt with:
RationaleThe Ripple code uses a specialized internal and wire format to represent amounts of currency. Because the server code does not rely on a central authority, it can have no idea what ranges are sensible with currencies. In addition, it's handy to be able to use the same code both to handle currencies that have inflated to the point that you need billions of units to buy a loaf of bread and to handle currencies that have become extremely valuable and so extremely small amounts need to be tracked.
The design goals are:
Accuracy - 15 decimal digits
Wide representation range - 10^80 units of currency to 10^-80 units
Deterministic - no vague rounding by unspecified rules.
Fast - Integer math only.
(my emphasis) They have recognised the problems well. Now come back to that question: why does SOX3 use CompactInts everywhere? Because of the above Rationale. In the business object (recall, the power of OO) we can know things like "billions of units to buy a loaf of bread" and also get the high value ones into the same format.
Next bad: Contractual form. This team has spotted the conundrum of currency explosion, because that's the space they chose: everyone-an-issuer (as I termed it). Close:

Custom CurrenciesCurrency 160-bit identifier is the hash of the currency definition block, which is also its storage index. Contains: Domain of issuer. Issuer's account. Auditor's account (if any). Client display information. Hash of policy document.
So, using the hash leads to an infinite currency space, which is the way to handle it. Nice! Frequent readers know where I'm going with this: their currency definition block is a variation of the Ricardian Contract, in that it contains, amongst other things, a "Hash of the policy document."
It's very close, it's almost a good! But it's not close enough. One of the subtleties of the Ricardian Contract is that because it put that information into the contract, *and not in some easily cached record*, it forced the following legal truth on the entire system: the user has the contract. Only with the presence of the contract can we now get access to data above, only with the presence of the contract can we even display to the user simple things like decimalisation. This statement -- the user has the contract -- is a deal changer for the legal stability of the business. This is your get out of jail free card in any dispute, and this subtle power should not be forgone for the mere technical benefit of data optimisation of cached blocks.
Next bad:
There are three types of currencies on ripple: ripple's native currency, also known as Ripples or XRP, fiat currencies and custom currencies. The later two are used to denominate IOUs on the ripple network.Native currency is handled by the absence of a currency indicator. If there is ever a case where a currency ID is needed, native currency will use all zero bits.
Custom currencies will use the 160-bit hash of their currency definition node as their ID. (The details have not been worked out yet.)
National currencies will be handled by a naming convention that species the three-letter currency code, a version (in case the currency is fundamentally changed), and a scaling factor. Currencies that differ only by a scaling factor can automatically be converted as transactions are processed. (So whole dollars and millionths of a penny can both be traded and inter-converted automatically.)
What's that about? I can understand the decision to impose one microcurrency into the protocol, but why a separate format? Why four separate formats? This is a millstone that the software will have to carry, a cost that will drag and drag.
There is no reason to believe that XRP or Natives or Nationals can be handled any differently from Customs. Indeed, the quality of the software demands that they be handled equivalently, the last thing you want is exceptions and multiple paths and easy optimisations. indeed, the concept of contracts demands it, and the false siren of the Nationals is just the journey you need to go on to understand what a contract is. A USD is not a greenback is not a self-issued dollar is not an petrodollar, and this:
Ripple has no particular support for any of the 3 letter currencies. Ripple requires its users to agree on meaning of these codes. In particular, the person trusting or accepting a balance of a particular currency from an issuer, must agree to the issuer's meaning.
is a cop-out. Luckily the solution is simple, scrap all the variations and just stick with the Custom.
Next: canonical layouts. Because this is a cryptographic payment system, in the way that only financial cryptographers understand, it is required that there be for every element and every object and every packet a single reliable canonical layout. (Yeah, so that rules out XML, JSON, PB, Java serialization etc. Sorry guys, it's that word: security!)
The short way to see this is signing packets. If you need to attach a digital signature, the recovery at the other end has to be bit-wise perfect because otherwise the digital signature fails.
We call this a canonical layout, because it is agreed and fixed between all. Now, it turns out that Ripple has a canonical layout: binary formats. This is Good. Especially, binary works far better with code, quality, networking, and canonicalisation.
But Ripple also has a non-canonical format: JSON. This is a waste of energy. It adds little benefit because you need the serialisation methods for both anyway, and the binary will always be of higher quality because of those more demanding needs mentioned above. I'd say this is a bad, although as I'm not aware of what they benefit they get from the JSON, I'll reserve judgement on that one.
Field Name Encodings -- good. This list recognises the tension for security coding. There needs to be a single place where all the tags are defined. I don't like it, but I haven't seen a better way to do this, and I think what we are seeing here in the Field Name Encodings' long list of business network objects is just that: the centralised definition of what format to expect to follow each tag.
Another quibble -- I don't see much mention of versions. In practice, business objects need them.
Penultimate point, if you're still with us. Let's talk layering. As is mooted above, the overall architecture of the Ripple protocol bundles the business information in with the low level packet stuff. In the same place as numbers, we also have currencies defined, digital signing and ledger items! That's just crazy. Small example, hashes:
4: 128-bit hash
5: 256-bit hash
And then there is the Currency hash of the contract information, which is a 160-bit encoding... Now, this is an unavoidable tension. The hash world won't stay still -- we started out with MACs of 32 bytes, then MD5 of 128 bits, SHA1 of 160 bits, and, important to realise, that SHA1 is deprecated, we now are faced with SHA2 in 4 different lengths, Keccak with variable length sponge function hashes, and emerging Polys of 64 bits.
Hashes won't sit still. I've also got in my work hash truncations of 48 bits or so, and pretend-hashes of 144 bits! Those latter are for internal float accounts for things like Chaumian blinded money (c.f., these days ZeroCoin).
So, Hashes are as much a business object decision as anything else. Hashes therefore need to be treated as locally designated but standardised units. Just setting hashes into the low layer protocol isn't the answer, you need a suite of higher level objects. The old principle of the one true cipher suite just doesn't work when it comes to hashes.
One final point. In general, it has to be stressed: in order to do network programming *efficiently* one has to move up the philosophical stack and utilise the power of Object Oriented Programming (used to be called OOP). Too many network protocols fall into a mess because they think OOP is an application choice, and they are at a lower place in the world. Not so; if there is anywhere that OOP makes a huge difference it is in network programming. If you're not doing it, you're probably costing yourself around 5 times the effort *and reducing your security and reliability*. That's at least according to some informal experiments I've run.
Ripple's not doing it, and this will strongly show in the altLang family.
(Note to self, must publish that Ouroboros paper which lays this out in more detail.)
December 29, 2013
The Ka-Ping challenge -- so you think you can spot a bug?
It being Christmas and we're all looking for a little fun, David Wagner has posted a challenge that was part of a serious study conducted by Ka-Ping Yee and himself:
Are you up to it? Are you a hacker-hero or a manager-mouse? David writes:
I believe I've managed to faithfully reconstruct the version of Ping's code that contains the deliberately inserted bug. If you would like to try your hand at finding the bug, you can look at it yourself:
http://www.cs.berkeley.edu/~daw/tmp/pvote-backdoored.zip
I'm copying Ping, in case he wants to comment or add to this.
Some grounds rules that I'd request, if you want to try this on your own:
- Please don't post spoilers to the list. If you think you've found a bug, email Ping and David privately (off-list), and I'll be happy to confirm your find, but please don't post it to the list (just in case others want to take a look too).
- To help yourself avoid inadvertently coming across spoilers, please don't look at anything else on the web. Resist the temptation to Google for Pvote, check out the Pvote web site, or check out the links in the code. You should have everything you need in this email. We've made no attempt to conceal the details of the bug, so if you look at other resources on the web, you may come across other stuff that spoils the exercise.
- I hope you'll think of this as something for your own own personal entertainment and edification. We can't provide a controlled environment and we can't fully mimic the circumstances of the review over the Internet.
Here's some additional information that may help you.
We told reviewers that there exists at least one bug, in Navigator.py, in a region that contains 100 lines of code. I've marked the region using comments. So, you are free to focus on only that part of the code (I promise you that we did not deliberately insert any bug anywhere else outside that region). Of course, I'm providing all the code, because you may need to understand how it all interacts. The original Pvote code was written to be as secure and verifiable as we could make it; I'm giving you a modified version that was modified to add a bug after the fact. So, this is not some "obfuscated Python" contest where the entire thing was designed to conceal a malicious backdoor: it was designed to be secure, and we added a backdoor only as an afterthought, as a way to better understand the effectiveness of code review.
To help you conduct your code review, it might help to start by understanding the Pvote design. You can read about the theory, design, and principles behind Pvote in our published papers:
- An early version of Pvote, with many of the main ideas: paper: http://pvote.org/docs/evt2006/index.html Ping's slides: http://pvote.org/docs/evt2006/talk.pdf
- Many improvements to the initial idea, and the final Pvote: paper: http://pvote.org/docs/evt2007/index.html slides: http://pvote.org/docs/evt2007/talk.pdf
The Pvote code probably won't make sense without understanding some aspects of its design and how it is intended to be used, so this background material might be helpful to you.
We also gave reviewers an assurance document, which outlines the "assurance case" (a detailed argument describing why we believe Pvote is secure and fit for purpose and free of bugs). Here's most of it:
http://www.cs.berkeley.edu/~daw/tmp/pvad-excerpts.pdf
Why not all of it? Because I'm lazy. The full assurance document contains the actual, unmodified Pvote code. We wrote the assurance document for the unmodified version of Pvote (without the deliberately inserted bug), and the full assurance document includes the code of the unmodified Pvote. If you were to look at that and compare it to the code I gave you above, you could quickly identify the bug by just doing a diff -- but that would completely defeat the purpose of the exercise. If I had copious free time, I'd modify the assurance document to give you a modified document that matches the modified code -- but I don't have time to do that. So, instead, I've just removed the part of the assurance document that contained the region of the code where we inserted our bug (namely, Navigator.py), and I'm giving you the rest of the assurance document.
In the actual review, we provided reviewers with additional resources that won't be available to you. For instance, we outlined for them the overall design principles of Pvote. We also were available to interactively answer questions, which helped them quickly get up to speed on the code. During the part where we had them review the modified Pvote with a bug inserted, we also answered their questions -- here's what Ping wrote about how we handled that part:
Since insider attacks are a major unaddressed threat in existing systems, we specifically wanted to experiment with this scenario. Therefore, we warned the reviewers to treat us as untrusted adversaries, and that we might not always tell the truth. However, since it was in everyones interest to use our limited time efficiently, we settled on a time-saving convention. We promised to truthfully answer any question about a factual matter that the reviewers could conceivably verify mechanically or by checking an independent source for example, questions about the Python language, about static properties of the code, about its runtime behaviour, and so on.
Of course, since this is something you're doing on your own, you won't get the benefit of interacting with us and having us answer questions for you (to save you time). I realize this does make code review harder. My apologies.
You can assume that someone else has done some runtime testing of the code. We deliberately chose a bug that would survive "Logic & Accuracy Testing" (a common technique in elections, where election officials conduct a test in advance where they cast some ballots, typically chosen so that at least one vote has been cast for each candidate, and then check that the system accurately recorded and tallied those votes). Focus on code review.
-- David
December 04, 2013
DJB on 'algorithm agility' -- it sucks
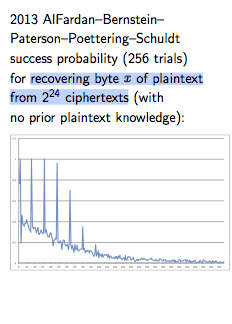
Dan Bernstein discussed various attempts to resolve bugs in ciphersuites in his keynote "Failures of secret-key cryptography" at the March Fast Sofware Encryption event. Then (fast-forwarding to pages 35-38) he says:
Cryptographic algorithm agility:
(1) the pretense that bad crypto is okay if theres a backup plan +
(2) the pretense that there is in fact a backup plan.SSL has a crypto switch that in theory allows switching to AES-GCM.
But most SSL software doesnt support AES-GCM.The software does support one non-CBC option: RC4.
Now widely recommended, used for 50% of SSL traffic.
 after which, DJB then proceeds to roundly trash RC4 as a favoured algorithm... Which is entirely fair, as RC4 has been under a cloud and deprecated since the late 1990s. In the slides, he reportst results from AlFardanBernstein PatersonPoetteringSchuldt that somewhere between 2^24 and 2^32 ciphertexts is what it takes to recover a plaintext byte. Ouch!
after which, DJB then proceeds to roundly trash RC4 as a favoured algorithm... Which is entirely fair, as RC4 has been under a cloud and deprecated since the late 1990s. In the slides, he reportst results from AlFardanBernstein PatersonPoetteringSchuldt that somewhere between 2^24 and 2^32 ciphertexts is what it takes to recover a plaintext byte. Ouch!
This attack on algorithm agility is strongly reminiscent of the One True Cipher Suite, which hypothesis also takes as a foundational assumption that algorithm agility doesn't work. So, abandon algorithm agility if you value your users.
(For further amusement, in slide 2-3, he takes aim at what I and Gutmann pronounced in 2011 and Adi's Shamir's statement that crypto is bypassed, which I'll post on later.)
DJB on 'algorithm agility' -- it sucks
Dan Bernstein discussed various attempts to resolve bugs in ciphersuites in his keynote "Failures of secret-key cryptography" at the March Fast Sofware Encryption event. Then (fast-forwarding to pages 35-38) he says:
Cryptographic algorithm agility:
(1) the pretense that bad crypto is okay if theres a backup plan +
(2) the pretense that there is in fact a backup plan.SSL has a crypto switch that in theory allows switching to AES-GCM.
But most SSL software doesnt support AES-GCM.The software does support one non-CBC option: RC4.
Now widely recommended, used for 50% of SSL traffic.
after which, DJB then proceeds to roundly trash RC4 as a favoured algorithm... Which is entirely fair, as RC4 has been under a cloud and deprecated since the late 1990s. In the slides, he reportst results from AlFardanBernstein PatersonPoetteringSchuldt that somewhere between 2^24 and 2^32 ciphertexts is what it takes to recover a plaintext byte. Ouch!
This attack on algorithm agility is strongly reminiscent of the One True Cipher Suite, which hypothesis also takes as a foundational assumption that algorithm agility doesn't work. So, abandon algorithm agility if you value your users.
(For further amusement, in slide 2-3, he takes aim at what I and Gutmann pronounced in 2011 and Adi's Shamir's statement that crypto is bypassed, which I'll post on later.)
May 06, 2013
What makes financial cryptography the absolutely most fun field to be in?
Quotes that struck me as on-point: Chris Skinner says of SEPA or the Single-European-Payment-Area:
One of the key issues is that when SEPA was envisaged and designed, counterparty credit risk was not top of the agenda; post-Lehman Brothers crash and it is.
What a delight! Oh, to design a payment system without counterparty risk ... Next thing they'll be suggesting payments without theft!
Meanwhile Dan Kaminsky says in delicious counterpoint, commenting on Bitcoin:
But the core technology actually works, and has continued to work, to a degree not everyone predicted. Time to enjoy being wrong. What the heck is going on here?First of all, yes. Money changes things.
A lot of the slop that permeates most software is much less likely to be present when the developer is aware that, yes, a single misplaced character really could End The World. The reality of most software development is that the consequences of failure are simply nonexistent. Software tends not to kill people and so we accept incredibly fast innovation loops because the consequences are tolerable and the results are astonishing.
BitCoin was simply developed under a different reality.
The stakes werent obscured, and the problem wasnt someone elses.
They didnt ignore the engineering reality, they absorbed it and innovated ridiculously
Welcome to financial cryptography -- that domain where things matter. It is this specialness, that ones code actually matters, that makes it worth while.
Meanwhile, from the department of lolz, comes Apple with a new patent -- filed at least.
The basic idea, described in a patent application Ad-hoc cash dispensing network is pretty simple. Create a cash dispensing server at Apples datacenter, to which iPhones, iPads and Macs can connect via a specialized app. Need some quick cash right now and theres no ATM around? Launch the Cash app, and tell it how much do you need. The app picks up your location, and sends the request for cash to nearby iPhone users. When someone agrees to front you $20, his location is shown to you on the map. You go to that person, pick up the bill and confirm the transaction on your iPhone. $20 plus a small service fee is deducted from your iTunes account and deposited to the guy who gave you the cash.
The good thing about being an FCer is that you can design that one over beers, and have a good belly laugh for the same price. I don't know how to put it gently, but hey guys, don't do that for real, ok?!
All by way of saying, financial cryptography is where it's at!
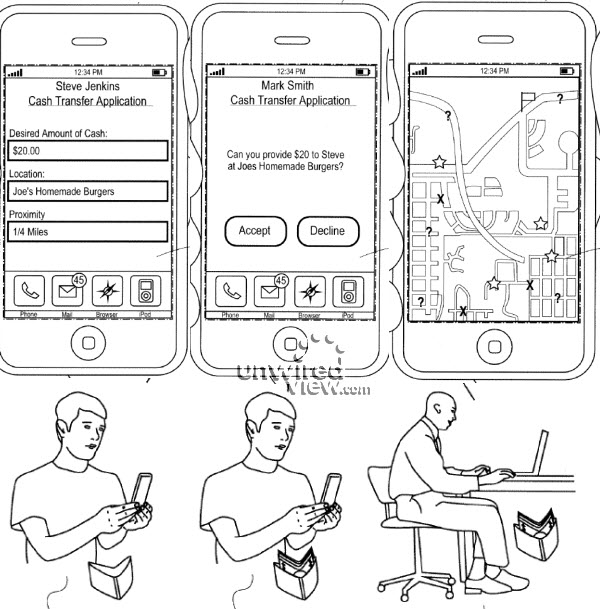
February 22, 2013
H4.4 - No Committees! (sorry, too late for OAuth)
 Coming across this retreat from the wonders of OAuth 2.0 in the daily Lynnogram reminded me of my own Hypotheses, little seeds of experience that can sometimes defend the diligent designer from the wayward path to hell:
Coming across this retreat from the wonders of OAuth 2.0 in the daily Lynnogram reminded me of my own Hypotheses, little seeds of experience that can sometimes defend the diligent designer from the wayward path to hell:
OAuth 2.0 and the Road to HellBy Eran Hammer Thursday July 26, 2012
They say the road to hell is paved with good intentions. Well, thats OAuth 2.0.
Last month I reached the painful conclusion that I can no longer be associated with the OAuth 2.0 standard. I resigned my role as lead author and editor, withdraw my name from the specification, and left the working group. Removing my name from a document I have painstakingly labored over for three years and over two dozen drafts was not easy. Deciding to move on from an effort I have led for over five years was agonizing.
There wasnt a single problem or incident I can point to in order to explain such an extreme move. This is a case of death by a thousand cuts, and as the work was winding down, Ive found myself reflecting more and more on what we actually accomplished. At the end, I reached the conclusion that OAuth 2.0 is a bad protocol. WS-* bad. It is bad enough that I no longer want to be associated with it. It is the biggest professional disappointment of my career.
Eran Hammer was instrumental in OAuth 1.0. He then moved the efforts into an IETF working group so as to "improve" it to Enterprise grade. He didn't survive the transition.
Which reminded me of what I'd written in "Hypothesis 4 - The First Requirement of Security is Usability." Sadly, until today it seems, I had neglected to publish the relevant seed! Hardly a usable Hypothesis, indeed, and apologies to all. Here it is:
#4.4 No Committees!It should be clear by now that committees are totally out of the question. They are like whirlpools, great spiralling sinks of talent, so paddle as fast as possible in the other direction.
On the other hand, if you are having trouble shrinking your team or agreeing with them, a committee over yonder can be useful as a face saving idea. Point them in that direction of the whirlpool, give them a nudge, and then get back to work.
And, for my sins, I have also packed in H4.5-7, and the entirety of Hypothesis 4 is now published.
January 09, 2013
The Great Data Privacy Battle of the 2010s
As the Internet wars of the 21st Century roll on, it's worth thinking about how to build systems in the new context. My ruminations follow.
The map has changed substantially from that of the 1990s, or the 20th century. In the last decade, 3 groups became paramount and are now battling it out: Apple, google and Facebook. That war isn't settled yet, which keeps the media hacks writing something vaguely wise and exciting, keeps our headlines breathless and tempting (as above :) .
Although no winner is declared, the protagonists have changed the privacy map. Before, it was about keeping ones data carefully partitioned, giving corporations only what they needed to know, leaning on them to at least try to protect it, and preserve some sense of privacy policy. And keep away from those who were just scarfing it up for sales.
Privacy used to be relatively simple, although we didn't know it then, nor appreciate it.
What we have now is cloud - all your data are being collected in one place by one person. To stress the positive, this works. At least, the sum total of apps and services offered by each of the behemoths seems to be better for us if we follow without question, and we carry the risk unknowingly. And, far better than previous models even dreamed of (here, I'm thinking of Microsoft's 1990s worldview).
But there are many negatives. Privacy is a total nightmare -- all our eggs are in their baskets.
Reliability seems to suffer too. The great migrations we have witnessed from client tools to cloud apps have seen many failures. We see reversals, costly absences, and drop-outs too. I personally no longer trust my Calendar - one of the earliest and simplest apps of all - because Apple's migration to cloud failed and I could not recover the data nor usability of same without just signing on completely and utterly. Most of you will have your own stories (I see them every day on the lists).
Worse, most users will not realise that it wasn't their fault, that they are victims of the slow suffocation of a vaporous white fluffy juggernaut. It isn't just Apple; there are so many insistent "offerings" in google's products that just by clicking NO so many times, by mistake you will end up in cloud 9 without intending, knowing, or any chance of redemption. I hear similar things about Facebook.
This is all by way of reaching the following question: what is a poor app designer supposed to do? My choice is to use google apps everywhere, or not. Or Apple, or Facebook.
I think I have to design my own version of a privacy model. And, I have to do it in such a fashion that it is both implementable without the resources of a major slice of the stock market, and in a fashion that delivers most of the benefits in a controllable way. OK, and it has to run seemlessly across platforms, not chew up bandwidth on the android, and make tea on demand.
I would rather trust Apple with my privacy, and the privacy of my customers. Honestly, they do a good job at most things. But somehow, the switch to cloud has stripped that very trust away. Google & Facebook the same - whatever one thought in the past, things have changed.
(For those hoping for the solution, sorry. I'm still thinking. :) Today's rambling is just about why I can't see how to place my customer's data in their hands.)
June 20, 2012
Another "official" result: USA+Israel unilaterally launched cyberwar against Iran
The question of the moment has been answered by WaPo - Flame was from the same USA/Israeli campaign that used Stuxnet to destroy 1000 centrifuges:
The United States and Israel jointly developed a sophisticated computer virus nicknamed Flame that collected intelligence in preparation for cyber-sabotage aimed at slowing Irans ability to develop a nuclear weapon, according to Western officials with knowledge of the effort.
USA and Israel have launched a campaign of cyber attacks against Iran. Unilateral, undeclared, surprise attacks.
Last year the Pentagon concluded that computer sabotage coming from another country can constitute an act of war according to the Wall Street Journal. Back in 2010, Secretary of State Hillary Clinton declared countries or individuals that engage in cyber attacks should face consequences and international condemnation.
Given the evidentiary nature of tracking a nation's actions in war, a newspaper expose is generally about as good as it gets. For non-USA readers, the Washington Post is one of the top handful papers, and they won't be making mistakes on this one. In this case, we get one better - the FBI are investigating leaks into the Stuxnet disclosures, and have thus confirmed the basic accuracy of the WaPo revelations.
Targetting and destroying centrifuges is about as clear and directed an attack as it gets in warfare. By way of analogue, it's little different to the classical bombing attacks of WWII directed against ball-bearing factories in the Ruhr. Like the city/factory bombing campaign of those days, this campaign also appears to be flexible in target scope:
Flame came to light last month after Iran detected a series of cyberattacks on its oil industry. The disruption was directed by Israel in a unilateral operation that apparently caught its American partners off guard, according to several U.S. and Western officials who spoke on the condition of anonymity.
OK, let's take down their oil industry. Who the heck cares?
Well, perhaps there are some responses possible. We'll leave with just this one thought from Bruce Schneier:
There's a common belief within the U.S. military that cyberweapons [mitigation] are not in our best interest: that we currently have a military advantage in cyberspace that we should not squander. That's not true. We might have an offensive advantage -- although that's debatable -- but we certainly don't have a defensive advantage. More importantly, as a heavily networked country, we are inherently vulnerable in cyberspace.
(I edited one word out for context. In his discussion he is talking about cyberweapon treaties, but the wider point remainst true.)
Ye reap what ye sew, and all that. For the USA, it's gonna get biblical - the new question for Washington DC is whether DHS is prepared for Iranian counterstrikes in cyberspace.
April 16, 2012
Emerging subtle requirements: pretending to be Skype
Bruce Schneier points at SkypeMorph:
To prevent the Tor traffic from being recognized by anyone analyzing the network flow, SkypeMorph uses what's known as traffic shaping to convert Tor packets into User Datagram Protocol packets, as used by Skype. The traffic shaping also mimics the sizes and timings of packets produced by normal Skype video conversations. As a result, outsiders observing the traffic between the end user and the bridge see data that looks identical to a Skype video conversation.The SkypeMorph developers chose Skype because the software is widely used throughout the world, making it hard for governments to block it without arousing widespread criticism. The developers picked the VoIP client's video functions because its flow of packets more closely resembles Tor traffic. Voice communications, by contrast, show long pauses in transmissions, as one party speaks and the other listens.
Yup, it is a time honoured tradition in firewall hopping to pretend to be someone else who gets an easier ride. Typically, we have webapps because applications needed to be let through the firewall. To respond to firewalls getting pernickety, everyone started layering their simple traffic over HTTP. It worked, but annoyed the firewall people who realised they'd been bypassed.
But, if HTTP wants to do this, it can't. Or Skype - how does it pretend to be Skype?
There is an answer. If we scale up this approach - copying the best over time - then the best will try to be better. Better, in this case, means removing any and all information that can be analysed.
In other words, Indistinguishable from Random.
In the past we would have said that defeating traffic analysis is too hard. But that's what is going at the coal face, regardless of the theoretical view. So let's take it to its logical conclusion - the end game is not to copy someone else, but to be indistinguishable from random.
When everyone is doing that, we all win. Skype is already a long way there, it seems. Can your protocol do better?
April 15, 2012
DSD launches Cyber Warfare - on my machine...
 I'm sitting here minding my own business in early hours of Sunday morning - OK, completing a risks analysis - and my machine starts churning away. Now, if you're an old time guy like me, you'll probably recall when cycles were expensive, kilobytes had deep emotional meaning, and noise delta was trauma. Either way, even though I have the late-gen Mac Air and it has very nice heat management, as well as more sex-appeal than any 10 shares in Facebook, I remain ... sensitive!
I'm sitting here minding my own business in early hours of Sunday morning - OK, completing a risks analysis - and my machine starts churning away. Now, if you're an old time guy like me, you'll probably recall when cycles were expensive, kilobytes had deep emotional meaning, and noise delta was trauma. Either way, even though I have the late-gen Mac Air and it has very nice heat management, as well as more sex-appeal than any 10 shares in Facebook, I remain ... sensitive!
Hunting around, I find that the culprit: google's Chrome. Ok, so what page? Well, none and all of them - Google's algorithm seems to have decided to cover my surfin sites with adverts for the DSD - Defence Signals Directorate - which is Australia's spook agency copy of the fabled NSA. Indeed 2 adverts to a page, all in impeccable Flash with zany cool graphics.
Blech. DSD is inviting me - and anyone, seems they're not that fussy - to join their great cyber-warfare jihad against the anonymous planet (us? they ain't saying).
 And they've started the campaign by stealing my cycles. No fair!
And they've started the campaign by stealing my cycles. No fair!
Not to mention, even Blind Freddy could tell what was wrong with their lame HR campaign. OK, maybe not, but here it is anyway: Firstly, people who are great defenders need great attack skills. Where do these budding ueber-cyber-guerillas get their skills from?
Attacking, is what. Hacking, to use the street parlance.
So we already have an issue - if you've led an exciting life of packet crime, you'll be knocked out in the security process. I know this at first hand - among the hundred-odd interesting factoids of my international life of mystery, the only time alarm bells went off : a mildly amusing moment a few dog-lives ago doing some crypto-manipulation and social-engineering for private pleasure.
Where are we then? Anyone we want working at DSD simply won't be allowed, and anyone who is allowed is suspicious for the same reason!

Which brings us to point 2: the security process. To work at DSD you require TOP SECRET. That's if you're the janitor, and even he's not allowed to know it. And, while it sounds sexy, security clearances are a drag of immense proportions. One year's delay *minimum* (some guy was telling me it took him 13 months to get his TS back again because it lapsed for 12 months ...).
It doesn't take a PhD in Economics to realise this is as dead a duck can be, and that's before we look at public service pay scales.
But wait, there's more! While you're waiting on that coveted TS to come through (and filling in reams of data concerning the mating habits of your first 10 pets) you can't work in the field. They can't offer you a job. They can't even offer you another job.
Bottom line: DSD are conducting a massive poaching campaign against .. themselves. They are advertising for people working in /other government departments/ who already have TS ... so they can steal them. Can you say beggar thy neighbour? DSD can. And when they do manage to steal the hard-won cyber-slave of some poor other schmuck department, they won't pay anywhere near enough to cover the anguish of TS.
Wake up guys!
Save your money! You've been doing this for 2 years now. The pool is fished out. Try another strategy. Sack your PR guy and hire some hackers. And, further, I've shut down Chrome... Cop that!
March 17, 2012
Fans of Threat Modelling reach for their guns ... but can they afford the bullets?
Over on New School, my threat-modelling-is-for-birds rant last month went down like a lead balloon.
Now, I'm gonna take the rap for this one. I was so happy to have finally found the nexus between threat modelling and security failure that has been bugging me for a decade, that I thought everyone else would get it in a blog post. No such luck, schmuck. Have another go!
Closest pin to the donkey tail went to David, who said:
Threat modeling is yet another input into an over all risk analysis.
Right. And that's the point. Threat modelling by itself is incomplete. What's the missing bit? The business. Look at this gfx, risk'd off some site. This is the emerging 31000 risk management typology (?) in slightly cut down form.
The business is the 'context' as shown by the red arrow. When you get into "the biz" you discover it's a place of its own, a life, a space, an entire world. More pointedly, the biz provides you with (a) the requirements and (b) a list of validated threats. E.g., history, as we already deal with them.
The biz provides the foundation and context for all we do - we protect the business, without which we have no business meddling.
(Modelling distraction: As with the graphic, the source of requirements is often painted at the top of the diagram, and requirements-driven architecture is typically called top-down. Alternatively and depending on your contextual model, we can draw it as a structural model: our art or science can sit on top of the business. We are not lifting ourselves up by our bootstraps; we are lifting the business to greater capabilities and margins. So it may be rational and accurate to call the business a bottom-up input.)
Either way, business is a mess, and one we can't avoid. We have to dive in and absorb, and in our art we filter out the essence of the problem from the business into a language we call 'requirements'.
Then, the "old model" of threat modelling is somewhere in that middle box. For sake of this post, turn the word risk into threat. Follow the blue arrow, it's somewhere in there.
The point then of threat modelling is that it is precisely the opposite of expected: it's perfect. In more particular words, it lives without a context. Threat modelling proceeds happily without requirements that are grounded in a business problem or a customer base, without a connection to the real world.
Threat modelling is perfect by definition, which we achieve by cutting the scope off at the knees.
 Bring in the business and we get real messy. Human, tragic. And out of the primordial swamp of our neighbors crawls the living, breathing, propogating requirements that make a real demand on us - survival, economy, sex, war, whatever it is that real people ask us for.
Bring in the business and we get real messy. Human, tragic. And out of the primordial swamp of our neighbors crawls the living, breathing, propogating requirements that make a real demand on us - survival, economy, sex, war, whatever it is that real people ask us for.
Adam talks about Spoofing, Tampering, Repudiation, Information Disclosure, Denial of Service and Elevation of Privilege... which sounds perfect. And I'd love to play the game :)
But real life is these things: insider trading, teenager versus teenager versus parent versus parent, revolutions of colour, DVD sharing, hiding in plain sight, movement tracking of jealous loved ones, don't ask, don't tell, whistleblowing, revenge,...
Which philosophy of business context first and foremost also explains a lot of other things. Just by way of one example, it gives an essential clue as to why only end-to-end security is worth anything. Application security automatically has a better chance of including the business; point-to-point designs like IPSec, SSL, DNSSec, etc have no chance. They've already handwaved anything past the relevant nodes into utter obscurity.
February 18, 2012
The Convergence of PKI
Last week's post on the jaws of Trust sparked a bit of interest, and Chris asks what I think about Convergence in comments. I listened to this talk by Moxie Marlinspike, and it is entertaining.
The 'new idea' is not difficult. The idea of Convergence is for independent operators (like CAcert or FSFE or FSF) to run servers that cache certificates from sites. Then, when a user browser comes across a new certificate, instead of accepting the fiat declaration from the CA, it gets a "second opinion" from one of these caching sites.
Convergence is best seen as conceptually extending or varying the SSH or TOFU model that has already been tried in browsers through CertPatrol, Trustbar, Petnames and the like.
In the Trust-on-first-use model, we can make a pretty good judgement call that the first time a user comes to a site, she is at low risk. It is only later on when her relationship establishes (think online banking) that her risk rises.
This risk works because likelihood of an event is inversely aligned with the cost of doing that attack. One single MITM might be cost X, two might be X+delta, so as it goes on it gets more costly. In two ways: firstly, in maintaining the MITM over time against Alice costs go up more dramatically than linear additions of a small delta. In this sense, MITMs are like DOSs, they are easier to mount for brief periods. Secondly, because we don't know of Alice's relationship before hand, we have to cast a very broad net, so a lot of MITMs are needed to find the minnow that becomes the whale.
First-use-caching or TOFU works then because it forces the attacker into an uneconomic position - the easy attacks are worthless.
Convergence then extends that model by using someone else's cache, thus further boxing the attacker in. With a fully developed Convergence network in place, we can see that the attacker has to conduct what amounts to being a perfect MITM closer to the site than any caching server (at least at the threat modelling level).
Which in effect means he owns the site at least at the router level, and if that is true, then he's probably already inside and prefers more sophisticated breaches than mucking around with MITMs.
Thus, the very model of a successful mitigation -- this is a great risk for users to accept if only they were given the chance! It's pretty much ideal on paper.
Now move from paper threat modelling to *the business*. We can ask several questions. Is this better than the fiat or authority model of CAs which is in place now? Well, maybe. Assuming a fully developed network, Convergance is probably in the ballpark. A serious attacker can mount several false nodes, something that was seen in peer2peer networks. But a serious attacker can take over a CA, something we saw in 2011.
Another question is, is it cheaper? Yes, definately. It means that the entire middle ground of "white label" HTTPS certs as Mozilla now shows them can use Convergence and get approximately the same protection. No need to muck around with CAs. High end merchants will still go for EV because of the branding effect sold to them by vendors.
A final question is whether it will work in the economics sense - is this going to take off? Well, I wish Moxie luck, and I wish it work, but I have my reservations.
Like so many other developments - and I wish I could take the time to lay out all the tall pioneers who provided the high view for each succeeding innovation - where they fall short is they do not mesh well with the current economic structure of the market.
In particular, one facet of the new market strikes me as overtaking events: the über-CA. In this concept, we re-model the world such that the vendors are the CAs, and the current crop are pushed down (or up) to become sub-CAs. E.g., imagine that Mozilla now creates a root cert and signs individually each root in their root list, and thus turns it into a sub-root list. That's easy enough, although highly offensive to some.
Without thinking of the other ramifications too much, now add Convergance to the über-CA model. If the über-CA has taken on the responsibility, and manages the process end to end, it can also do the Convergence thing in-house. That is, it can maintain its set of servers, do the crawling, do the responding. Indeed, we already know how to do the crawling part, most vendors have had a go at it, just for in-house research.
Why do I think this is relevant? One word - google. If the Convergence idea is good (and I do think it is) then google will have already looked at it, and will have already decided how to do it more efficiently. Google have already taken more steps towards ueber-CA with their decision to rewire the certificate flow. Time for a bad haiku.
Google sites are pinned now / All your 'vokes are b'long to us / Cache your certs too, soon.
And who is the world's expert at rhyming data?
Which all goes to say that Convergence may be a good idea, a great one even, but it is being overtaken by other developments. To put it pithily the market is converging on another direction. 1-2 years ago maybe, yes, as google was still working on the browser at the standards level. Now google are changing the way things are done, and this idea will fall out easily in their development.
(For what it is worth, google are just as likely to make their servers available for other browsers to use anyway, so they could just "run" the Convergance network. Who knows. The google talks to no-one, until it is done, and often not even then.)
January 29, 2012
Why Threat Modelling fails in practice
I've long realised that threat modelling isn't quite it.
There's some malignancy in the way the Internet IT Security community approached security in the 1990s that became a cancer in our protocols in the 2000s. Eventually I worked out that the problem with the aphorism What's Your Threat Model (WYTM?) was the absence of a necessary first step - the business model - which lack permitted threat modelling to be de-linked from humanity without anyone noticing.
But I still wasn't quite there, it still felt like wise old men telling me "learn these steps, swallow these pills, don't ask for wisdom."
In my recent risk management work, it has suddenly become clearer. Taking from notes and paraphrasing, let me talk about threats versus risks, before getting to modelling.
A threat is something that threatens, something that can cause harm, in the abstract sense. For example, a bomb could be a threat. So could an MITM, an eavesdropper, or a sniper.
But, separating the abstract from the particular, a bomb does not necessarily cause a problem unless there is a connection to us. Literally, it has to be capable of doing us harm, in a direct sense. For this reason, the methodologists say:
Risk = Threat * Harm
Any random bomb can't hurt me, approximately, but a bomb close to me can. With a direct possibility of harm to us, a threat becomes a risk. The methodologists also say:
Risk = Consequences * Likelihood
That connection or context of likely consequences to us suddenly makes it real, as well as hurtful.
A bomb then is a threat, but just any bomb doesn't present a risk to anyone, to a high degree of reliability. A bomb under my car is now a risk! To move from threats to risks, we need to include places, times, agents, intents, chances of success, possible failures ... *victims* ... all the rest needed to turn the abstract scariness into direct painful harm.
We need to make it personal.
To turn the threatening but abstract bomb from a threat to a risk, consider a plane, one which you might have a particular affinity to because you're on it or it is coming your way:
⇒ people dying⇒ financial damage to plane ⇒ reputational damage to airline⇒ collateral damage to other assets⇒ economic damage caused by restrictions⇒ war, military raids and other state-level responses
Lots of risks! Speaking of bombs as planes: I knew someone booked on a plane that ended up in a tower -- except she was late. She sat on the tarmac for hours in the following plane.... The lovely lady called Dolly who cleaned my house had a sister who should have been cleaning a Pentagon office block, but for some reason ... not that day. Another person I knew was destined to go for coffee at ground zero, but woke up late. Oh, and his cousin was a fireman who didn't come home that day.
Which is perhaps to say, that day, those risks got a lot more personal.
We all have our very close stories to tell, but the point here is that risks are personal, threats are just theories.
Let us now turn that around and consider *threat modelling*. By its nature, threat modelling only deals with threats and not risks and it cannot therefore reach out to its users on a direct, harmful level. Threat modelling is by definition limited to theoretical, abstract concerns. It stops before it gets practical, real, personal.
Maybe this all amounts to no more than a lot of fuss about semantics?
To see if it matters, let's look at some examples: If we look at that old saw, SSL, we see rhyme. The threat modelling done for SSL took the rather abstract notions of CIA -- confidentiality, integrity and authenticity -- and ended up inverse-pyramiding on a rather too-perfect threat of MITM -- Man-in-the-Middle.
We can also see from the lens of threat analysis versus risk analysis that the notion of creating a protocol to protect any connection, an explicit choice of the designers, led to them not being able to do any risk analysis at all; the notion of protecting certain assets such as credit cards as stated in the advertising blurb was therefore conveniently not part of the analysis (which we knew, because any risk analysis of credit cards reveals different results).
Threat modelling therefore reveals itself to be theoretically sound but not necessarily helpful. It is then no surprise that SSL performed perfectly against its chosen threats, but did little to offend the risks that users face. Indeed, arguably, as much as it might have stopped some risks, it helped other risks to proceed in natural evolution. Because SSL dealt perfectly with all its chosen threats, it ended up providing a false sense of false security against harm-incurring risks (remember SSL & Firewalls?).
OK, that's an old story, and maybe completely and boringly familiar to everyone else? What about the rest? What do we do to fix it?
The challenge might then be to take Internet protocol design from the very plastic, perfect but random tendency of threat modelling and move it forward to the more haptic, consequences-directed chaos of risk modelling.
Or, in other words, we've got to stop conflating threats with risks.
Critics can rush forth and grumble, and let me be the first: Moving to risk modelling is going to be hard, as any Internet protocol at least at the RFC level is generally designed to be deployed across an extremely broad base of applications and users.
Remember IPSec? Do you feel the beat? This might be the reason why we say that only end-to-end security cuts the mustard, because end-to-end implies an application, and this draw in the users to permit us to do real risk modelling.
It might then be impossible to do security at the level of an Internet-wide, application-free security protocol, a criticism that isn't new to the IETF. Recall the old ISO layer 5, sometimes called "the security layer" ?
But this doesn't stop the conclusion: threat modelling will always fail in practice, because by definition, threat modelling stops before practice. The place where users are being exposed and harmed can only be investigated by getting personal - including your users in your model. Threat modelling does not go that far, it does not consider the risks against any particular set of users that will be harmed by those risks in full flight. Threat modelling stops at the theoretical, and must by the law of ignorance fail in the practical.
Risks are where harm is done to users. Risk modelling therefore is the only standard of interest to users.
July 28, 2011
ZRTP and the H3 experience
Zooko writes a case study in support of H3,
there is only One Mode, and it is Secure:
When Phil Zimmermann and I were designing ZRTP, we had a complete protocol design for the secure stream and a working prototype, and then we decided, against my better judgment, to add the feature of users being able to switch back and forth between secure mode and insecure ("clear") mode. (This was before [Jon Callas] got involved in the protocol-level details of the ZRTP that eventually became [RFC 6189]. I think it was in 2006.)
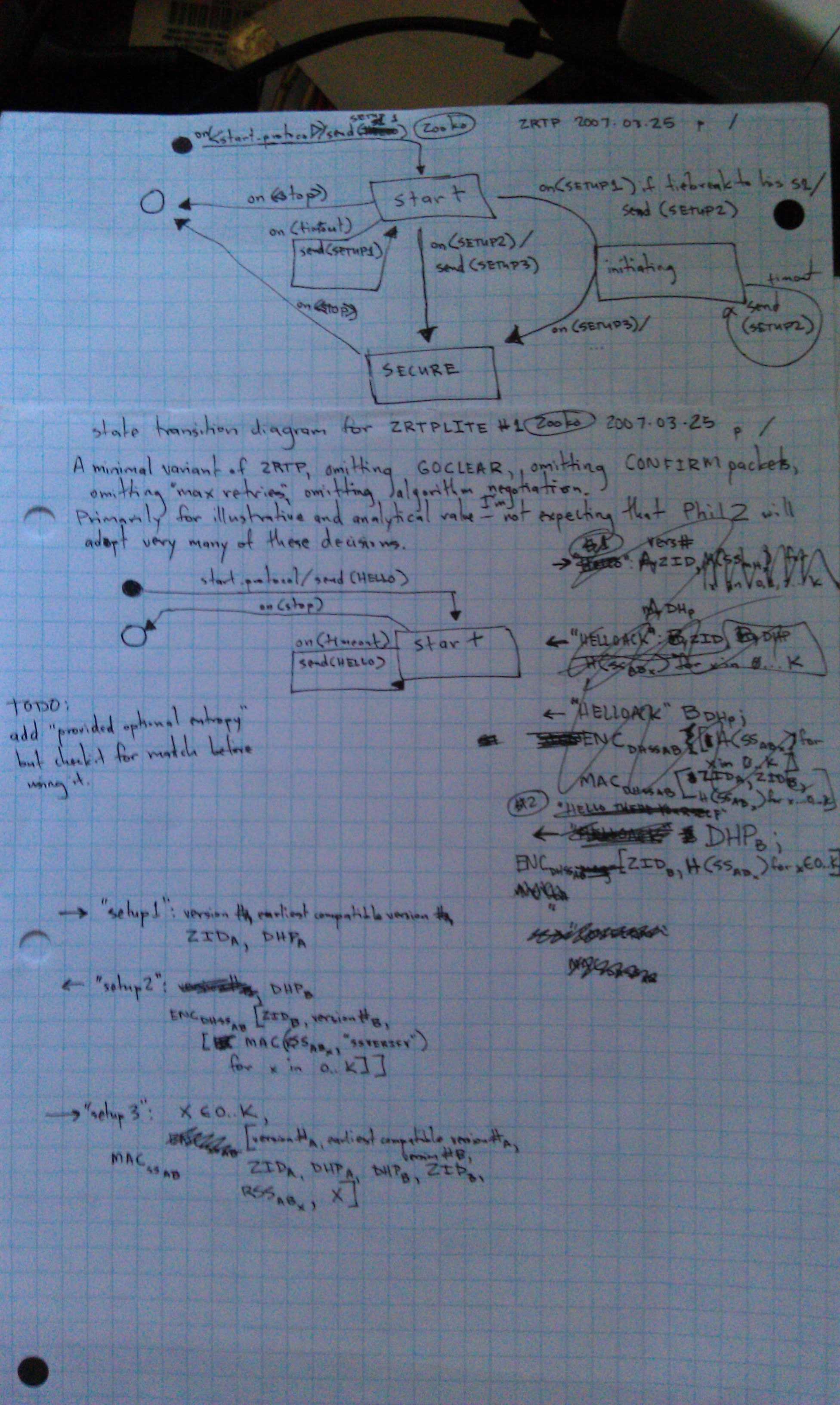
This caused the state transition diagram (which lived on a piece of 8.5x11 paper pinned to the wall above my screen) to balloon from, if I recall correctly, approximately five states with around ten transitions to approximately ten states with closer to twenty transitions. We then added and removed several successive bugs in the protocol or in the prototype implementation over the next few months, all of which were in this newly added feature of the protocol.
Phil was concerned about our schedule and frustrated by the delay. He remarked that if he had known adding "clear mode" was going to cost so much development time he wouldn't have done it.
Later, the existence of the insecure mode again added complexity when we wanted to add support for PBXes and call transfer, and instead of working out how to handle call transfer from one state (secure mode), we had to work out how to do it from several statessecure mode, clear mode, the state where you've indicated that you wish to switch from secure mode to clear mode but the other party hasn't yet ACKed, and the state where you've indicated that you wish to switch from clear mode to secure mode but the two parties haven't finished negotiating the new session. (By this time I had left the ZRTP project to begin work on what eventually became Tahoe-LAFS, and my contribution to the PBX/call-transfer issue was merely a little bit of consulting.)
I think that in retrospect ZRTP would have been better if we had followed Grigg's H3.
Hm, digging around in my keepsakes cabinet, I unfortunately do not find the original state transition diagram that I mentioned above, but I do find an artifact that I wrote a few months latera sketch of a protocol that I called "ZRTP lite" which was ZRTP as it existed at that time minus insecure mode, algorithm negotiation, the "confirm" packet, and the max-retries timeout. The resulting state transition diagram has only three states (five if you count the beginning statebefore the phone call has begunand the ending stateafter the call has ended), and only five transitions (counting start and stop).
I never showed this to anyone until now. See attachment.
My next major project after ZRTP was Tahoe-LAFS, and in that project my co-designers and I have adhered to Grigg's H3. We occasionally get requests to add an insecure mode to Tahoe-LAFS and so far we have declined to do so. I could be provoked into posting further musings on that issue. (The fact that we are refusing to accommodate repeated requests from users is certainly a warning flag in my view and deserves careful justification.)
Regards,
Zooko
[RFC 6189] http://zfone.com/docs/ietf/rfc6189.html
May 20, 2011
Hold the press! Corporates say that SSL is too slow to be used all the time?
Google researchers say they've devised a way to significantly reduce the time it takes websites to establish encrypted connections with end-user browsers, a breakthrough that could make it less painful for many services to offer the security feature. ....The finding should come as welcome news to those concerned about online privacy. With the notable exceptions of Twitter, Facebook, and a handful of Google services, many websites send the vast majority of traffic over unencrypted channels, making it easy for governments, administrators, and Wi-Fi hotspot providers to snoop or even modify potentially sensitive communications while in transit. Companies such as eBay have said it's too costly to offer always-on encryption.
The Firesheep extension introduced last year for the Firefox browser drove home just how menacing the risk of unencrypted websites can be.
Is this a case of, NIST taketh away what Google granteth?
December 09, 2010
Teaching p2p? You betcha!
I have long held an opinion that the exciting work in Computer Science has been over in the p2p area. Now, Arnaud Legout writes about his course in p2p:
Hi, I have given a course on P2P for 4 years now, and I decided to release it publicly due to the lack of such a public resource.
I believe this course can be of interest to a large audience: developers of P2P protocols that want to better understand how it works, researchers that want a comprehensive introduction to the field, students that are looking for a document on the subject, etc.
This course is focused on P2P content replication with a very comprehensive part on BitTorrent. I also address some very important notions of distributed security. I usually give this course on seven lectures of 3 hours.
I put the slides of my course online (with a Creative Commons license BY-NC-SA, which means you can reuse anything as long as you give credit and don't make money out of it).
http://cel.archives-ouvertes.fr/cel-00544132/en/
I recommend to download the PowerPoint version (PPTX), as the PDF version will not render the animations and the animated slides will look cluttered.
Of course, comments are highly welcomed.
Regards,
Arnaud Legout.
You can contact him at arnaud.legout at inria dot fr. Happy learning!
August 24, 2010
What would the auditor say to this?
Iran's Bushehr nuclear power plant in Bushehr Port:
"An error is seen on a computer screen of Bushehr nuclear power plant's map in the Bushehr Port on the Persian Gulf, 1,000 kms south of Tehran, Iran on February 25, 2009. Iranian officials said the long-awaited power plant was expected to become operational last fall but its construction was plagued by several setbacks, including difficulties in procuring its remaining equipment and the necessary uranium fuel. (UPI Photo/Mohammad Kheirkhah)"
Click onwards for full sized image:
Compliant? Minor problem? Slight discordance? Conspiracy theory?
(spotted by Steve Bellovin)
August 21, 2010
memes in infosec IV - turn off HTTP, a small step towards "only one mode"
There appears to be a wave of something going through the infosec industry. There are reports like this:
In the past month, we've had several customers at work suddenly insist that we make modifications to their firewalls and/or load balancers to redirect *all* incoming HTTP traffic to HTTPS (which of course isn't always entirely sane to do on proxying devices, but they apparently don't trust their server admins to maintain an HTTP redirect). Most of them cited requirements from their PCI-DSS auditors. One apparently was outright told that their redirects were "a security problem" because they presented an open socket on port 80, and they needed to be refusing all HTTP to their servers at the firewall. I think we gave them sufficient wording to convince their auditor that blocking access to the redirect itself wasn't going to do anyone any good.
Then, there have been long discussions circulating around the meaning of this hypothesis in security design:
there is only one Mode, and it is Secure
Which, if I can say in small defence, is an end-point, a result, an arrival that does not in the slightest hint at how or why we got there. Or by what path, which by way of example is the topic of this very blog post.
![]() The Electronic Frontier Foundation has announced and pushed a new experimental browser plugin to take browsing on that very path towards more and pervasive HTTPS:
The Electronic Frontier Foundation has announced and pushed a new experimental browser plugin to take browsing on that very path towards more and pervasive HTTPS:
HTTPS Everywhere is a Firefox extension produced as a collaboration between The Tor Project and the Electronic Frontier Foundation. It encrypts your communications with a number of major websites.Many sites on the web offer some limited support for encryption over HTTPS, but make it difficult to use. For instance, they may default to unencrypted HTTP, or fill encrypted pages with links that go back to the unencrypted site.
The HTTPS Everywhere extension fixes these problems by rewriting all requests to these sites to HTTPS.
And Jeff Hodges, Collin Jackson and Adam Barth have published an Internet Draft called Strict Transport Security based on this paper, which in essence tells anyone who connects to the insecure HTTP service to instead switch across to the secure HTTPS service.
Now, leaving aside whether these innovations will cause a few confusions in compatibility, site-redesign and access, all common ills that we would normally bow and scrape before, ... it would seem that this time there is some emphasis behind it: As well as the EFF plugin above, Paypal and NoScript have adopted STS. As Paypal was at one time the number 1 target for phishing-style attacks, this carries some weight. And as NoScript is allegedly used by practically all the security people on the planet, this could be influential.
A few words on what appears to be happening here. In the Internet security field is that the 800lb gorilla -- breaches, viruses, botnets, phishing,... -- it seems that outsiders like EFF, Paypal and PCI-DSS auditors are starting cleaning up the field. And in this case, they're looking for easy targets.
 One such target was long identified: turn off HTTP. Yup, throw another bundle of tinder on that fire that's burning around me ... but meanwhile, switch all HTTP traffic to HTTPS.
One such target was long identified: turn off HTTP. Yup, throw another bundle of tinder on that fire that's burning around me ... but meanwhile, switch all HTTP traffic to HTTPS.
In an ideal world, every web request could be defaulted to HTTPS.
It's a simple thing, and an approximate first step towards the hypothesis of there is only one mode and it is secure. Switching to HTTPS for everything does a few things, obvious and subtle.
1. the obvious thing is that the user can now be seriously expected to participate in the "watch the padlock" protocol, because she's no longer being trained to ignore the padlock by the rest of the site. The entire site is HTTPS, that's easy enough for the users to understand.
2. The second thing that the notion of pervasive HTTPS does is to strip away some (not all) of the excuses for other parties. Right now, most decision makers almost totally ignore HTTPS. Browser manufacturers, server manufacturers, CAs, cartels, included. It is all compliance thinking, all eyes are turned elsewhere. If, for any circumstance, for any user, for any decision maker, there is a failure, then there is also an easy excuse as to "why not." Why it didn't work, why I'm not to blame, why someone else should fix their problems.
Probably, there are more excuses than we can count (I once counted 99...) (the latest excuse from NIST, Mozilla and Microsoft).
However, if the PCI-DSS auditors make HTTPS the normal and only mode of operation, that act will strip away a major class of excuses. It's on, always on, only on. Waddya mean, it went off? This means the security model can actually be pinned on the suppliers and operators, more of the time. At least, the outrage can be pinned on them, when it doesn't work, and it will have some merit.
3. The third thing it does is move a lot of attention into the HTTPS sphere. This is much more important, but more subtle.
More attention, a growing market, more expectations means more certs, more traffic, more reliance on the server cert, etc. But it also means more attention to client certs, more programmers, more admins, more more more ...
Which will elevate the use of HTTPS and its entire security model overall; which will hopefully get the people who can make a difference -- here I'm thinking of Mozilla and Microsoft and the other browser security UI production teams -- to put a bit more effort and thinking into this problem.
Some would say they are working hard, and I know they are. But let me put this in context. Last I heard, Jonathan had a team of 2-3 programmers working on Firefox security UI. (And, yes, that's a set-up for a correction, thanks!)
This team is so tiny that we can even know their names.... Let me know and I'll post their names :)
Yet, this security UI is protecting the online access of probably 100 million people across the planet. And the current viewpoint of the owning organisation is that this is a backwater that isn't really important, other areas are much more important.
(Just to point out that I'm not picking on Mozilla unfairly: Microsoft is no better, albeit more clear in their economic reasoning. Google probably has one person, Opera may have one too. Konqueror? Apple won't say a thing...)
(Prove me wrong, guys! Ya know ya want to! :)
August 05, 2010
Beyond Architecture: the City Planner of today's high-density Information Business
That which I described a month back relates to an application called payments, and a variation designed to make it better. One aspect that probably rankles is that a lot of people in the so-called Architecture role do something else, and that's not it
This is what is killing Enterprise Architecture every computer programmer, systems designer, software architect, solutions architect, technology architect, computer operator, PC owner, data architect, database architect, network architect, business analyst, systems analyst, enterprise architect, service architect, object architect, project manager and CIO calls whatever they want to or maybe, whatever they are doing, Architecture. It is chaos. No wonder we dont have Enterprises that are coherent, integrated, flexible, dynamic, interoperable, reusable, aligned, lean and mean and working.
So sayeth John Zachman, who is credited with having invented a term or two in the space.
Here's one variation in the workspace of Architecture, which some call programming in the large. Consider the app from the last post, payments. It's cohesive, tight, and operates to a set of rules. It has strong boundaries. We can analogise this process to be like a building; hence it is probably fair to claim someone who designs and builds a payment system can call themselves an architect. If not fair, uncontroversial.
There are also many others applications, and each of them can be analogised to a building. They are each cohesive units, strict rules within and without, and they are generally focussed on particular purposes. For each building, we have different Architects, and for each style of building, we have different styles of Architecture.
Then, there are places where there are many applications. Larger companies, government departments, banks, etc, have dozens or hundreds of these applications. And, what's more, these applications are often connected in long, difficult transactions. A particular client's request might go wandering through from app to app, department to department, database to database until it finally pops out the other end.
This is a very different building process, it's a macroworld compared to the individual building's microworld. In order for the whole organisation to deliver on its goals, all of the apps and people must somehow play towards the same goal; which means we have to bring all these together somehow. Architects have to talk to Architects, apps to apps, people to people, and many variations.
It is tempting then to extend the application scenario and simply view an organisation as a very large application. But this runs into trouble very quickly. Firstly, all the individual apps run to their own timeline. Secondly, departments, and people, are jealous of their independence. Thirdly, the complexity is such that without very good oversight, very good understanding, and quite deft tuning and aligning, an Architect of an entire organisation will likely fail to make a mark.
In order to make all this work, and improve, we need to set some guidelines. Firstly, once delivered, applications do not change much, if at all. Just like we don't go moving buildings around just because they are now inconveniently placed. Secondly, the interconnections between the apps are capable of changing , and being re-used for new and diverse purposes. This is the streets and walkways between the buildings, which typically become public ownership; they always seem to be being dug up and moved around for one reason or another.
Hence we start to look at how the applications can look to each other, and we also start to standardise this as a first step. From this view comes the march of webservices, XML, WSDL, and friends: if all apps deliver their output in standardised forms, then it becomes a matter of cheap scripting for other apps to tap that output. Once that is done, we can start to re-connect, inter-connect and so forth. Hypothetically...
Which leads to the next issue. Although we've tackled ways to reconfigure the I/O of the business units, just like we used to reconnect computer peripherals with cat(1), and we've created a fast & flexible form of BPR, we still haven't reduced the complexity. For that, a wave of tools and methodologies has rushed in like a tsunami to try and map out the complexity in some fashion to allow our supreme leader to be the true master of all she surveys: service discovery, service cataloguing, service levels, dependency mapping, defect discovery, transaction troubleshooting, model-driven reconfiguration, use-case mapping for large transactions, etc etc. With the flood of tools comes the flotsam of buzzwords, jetsam of key phrases, and sales calls for yet more tools. Anyone in the business will tell you this is a very costly area, as every new tool promises far more than any other tool has ever delivered, and you only find out after paying the price that there is a new must-have tool just around the corner.
All of which goes to suggest that this is a very different game to Architecture. This is really City Planning, and although it is a sub-branch of what the Architecture Professionals like to consider their domain, it is a very separate field. An application Architect is very focussed on the tech, and needs to tear himself away from it to understand enough of the business in order to build something that is wanted. But in the wider organisation domain, the reverse is more true: this person is very focussed on the business, and she needs to tear herself away from the business just enough to understand what the tech can do for her, in the way of interfaces, data formats, etc.
Just like the Architect meets the City Planner at the boundary line, driveway and other pipes, the Application Architect meets the "Company Planner" at the external I/O interfaces of the App. The desire for every building to have the same boring driveway is seen in webservices, which can be considered to be a lowest common denominator of application driveway.
What then to call this person? Because the domain Architects grew out and upwards from this field, on the supremacy of their applications, they are sometimes called Enterprise Architects. But this is a parochial, bottom-up view by technologists, who press the case for more technological tools. We can also look at the question top-down, business oriented, and there, we find a familiar thread: we are talking about Business Process Re-engineering up in the early 1990s, and the rampant charge of the MBAs at that time, and then a stampede of competing methodologies from consultancy companies with different names, variations but one common theme: interconnecting the units of business in better and more efficient ways.
In the last decade, we saw the Enterprise Architecture approach possibly succeeding and outlasting, where others have not. However, it is not easy to attribute the success to its rightness; more likely it is attributable to the rise of the computer and information within modern service business. Enterprise Architecture rose upwards on the back of tech companies' assault on the business of business, and less so on its own merits.
All of these have something of a fad in them, but something of the truth. That old dirty word BPR was essentially what we wanted, but we want it to be done every week, not every decade. Every other buzz/fad/gee-whiz word like TQM, JIT, 6 Sigma, Lean, Business Transformation etc etc that followed (or led) tried to repair some of the gaps in the previous (or following) fad, but they all suffered their blind spots and their seduction to increasing complexity. Any recipe teachable to ordinary people in ordinary business fails to understand the whole complexity of business, it seems. Leaving plenty of room for the next fad...
Meanwhile, the MBAs had the ability to talk to all the departments in their language, understand the papers and draw the lines they wanted, dominate and improve on all the various methodologies ... but they didn't have the technical credibility to make it happen in a computer-driven world. (They would have loved Agile.)
The IT-focussed Architects have the latter, but not the former; they know how to program in the small with data and functions and objects. But when it comes to programming in the large, with people and customers and processes and refunds and laws and giveaways and expediting and sickleave and and and, not only is their experience simply lacking, but the rules of programming are completely different.
Which all leads to what, exactly? Although I think some very good stuff is happening in the Enterprise Architecture world, I also sense the mismatch in viewpoints. To me, I get the feeling that this evolutionary game isn't over, there's a few more cycles before we figure out who is the real master of the high-density information city. It is like we are back in the 1970s, admiring the traffic jams and the smog in Los Angeles, thinking that all this activity means we're on the right track.
We know that Cities have City Planners, and it is a distinct discipline. We just haven't found, named and understood the City Planner for information-driven business as yet. Right now, I feel we're back in last century, 50 years ago, Los Angeles: admiring the traffic jams and pile-ups, selling traffic lights, thinking the info-smog tells us we're on the right track, and complaining that City Hall is digging up the streets. Again :-(
(Hattip to Martin Bramwell who provided much of the helicopter view for this essay!)
June 05, 2010
The Baby Back Ribbed Theory of Architecture
Somebody asked me how I do Architecture, and it wasn't a question I could easily answer. Darn! I am one, but what is one, and how do I do it?
Since then, I've been doing a bit of reading, and I think I have the answer. Here it is, by way of an anecdote called Rafi's, which was a project, and also a ribs & beer place. Crack open a beer, order in some ribs, and settle in.
 In 2000 or thereabouts, my team and I were sitting on the most sophisticated and working Internet payments system around. Having got it in place, we were then faced with the problem that bedevilled most all payment systems: people don't do payments, so much as, they do trade. This was a conundrum, one I wrote about in FC7, in where I claim that a financial cryptography system without a "financial application" is approximately worthless.
In 2000 or thereabouts, my team and I were sitting on the most sophisticated and working Internet payments system around. Having got it in place, we were then faced with the problem that bedevilled most all payment systems: people don't do payments, so much as, they do trade. This was a conundrum, one I wrote about in FC7, in where I claim that a financial cryptography system without a "financial application" is approximately worthless.
Some slight context. To answer the obvious question here, we already had our application, being the swapping of financial instruments for cash, and back again. Good as it was, I was looking for more. A wider complication is that many obvious applications have beartraps in them lurking for unwitting payment systems, so there wasn't an easy answer such as copy amazon or google or expedia or Rafi's ribs place. And, finally, luckily, no customer was demanding this, it was an internally-generated strategic demand, so I could take my time.
In trying to do more payments, then, the problem evolved into figuring out what trade people did, and trying to participate in more of that. In order to get a grounding in that, I surveyed how payments integrated into life. Initially, I thought about invoice cycles, because a payment is generated out of such a cycle. This seemed fairly tractable, but I wasn't comfortable with the variations. I went wider, and thought about trading of all form, the wider business exchange that goes on that generates an invoice cycle, and finally a payment.
In principle, as we'd already done financial trades, and it was simply a matter of substituting finance with some other business, walking the transaction, architecting it and implementing it.
Or so I initially thought, but it wasn't to be. Take a hotel check-in, an example I sometimes used to convince people *not* to get into the retail payments business. When you finally get to the hotel, and walk in the door, you start the process, something like this: "I'm after a room ..."

"We have singles, doubles, and the presidential suite ..." How much is the double? "100 per night" OK, I'd like three nights. "We only have doubles available for 2 nights, but we have the singles." OK, and do you have a room at the back, not facing the highway? "Ah, yes you'll be wanting the presidential suite then ..."
And on and on it goes. The point is that, while invoicing cycles include some variability, trade cycles are all variability, to the point of arbitrary, unpredictable chaos.
Examining such a process and trying to automate it presents rather special challenges. It is somewhat clear that we can create an ontology to capture all the probable paths of the hotel reception cycle. And indeed, this is what many projects tried to do: define the process, automate the use-cases. Consider flight booking systems. It's also possible to define an exceptions protocol, to catch those tricky "backside room," special meal requests or the more prosaic desire for a welcoming Carib.
But it's hard. And risky, as having built it, how do we know the customers will agree with the ontology? Building such things only makes sense if they work, guaranteed, and that's unlikely in this case.
But the real killer is that having done all that, ones grand structure is almost useless for the next business problem. That is, a flight booking system won't translate so easily to a hotel process, even though we want to offer both of them together (and many do). And it certainly doesn't have much relationship to a book drop-shipping business. Unless, that is, one believes that there is all-powerful super-meta-hyper methodology that can capture all interactions between all humans. An AP-SMH-UML, if you like, or perhaps the über-SAP. If you believe in that, just let me know how many decades you'll finance the building of it, and I'm willing to take your money :) if I can get to the head of the queue...
In the alternate, it is possible to understand the essence of trade, approximate, and find some benefits. And this is where my months of thinking started to pay out some small glimmers of inspiration.
The first thing I realised is that, a payment is but a tiny part. A bigger part is the invoicing process, which often involves a bill being delivered, checked, paid for, and confirmed. On both sides. This is an application in and of itself, it is probably 5 times bigger than a payment.
And we still haven't given it any semantics, any meaning for the end-user. Intuitively, we have to deliver meaning in order to make it reach a customer (or, academically, recall the FC7 hypothesis above). But as soon as I tried to add some sort of semantics around the invoicing, I ended up with the killer issue above: a mess of interactions of no real structure surrounding an already challenging invoicing protocol, with a payment or three tacked on. What started out as simple modelling revealed an intractable mess, which by size dominated the original mission. My finger-in-the-air estimate is this: 1% payment, 4% invoice, 95% the messages of chaos.
Logic therefore said to me that I if I could improve the 95% and reduce the chaos as it were, then this would likely dominate any efforts to improve the 4%, at a ratio of around 20 to 1! And, following this logic, the payment was now almost optional, almost vestigial. The less I thought about payments, the better.
My next glimmer was to treat trade as a series of requests and responses, back and forth. But, that didn't quite work out because many of the so-called requests were unanticipated, and unresponded. Think of advertising's part in trade, and the request-response model is dead, which may explain why so many billing systems layered over HTTP look so ghoulish. So eventually I was led to treating interaction as a somewhat arbitrary series of messages, showing patterns of no particular import to us.
 The inspiration was then to flip the architecture system around: trade is messages, and to improve trade, improve the messaging capability. I didn't want semantics, I wanted freedom from semantics. I wanted a messaging system, with payments tacked on, rather than a payments system based on messaging. Indeed, I wanted a messaging system that could support arbitrary messages, and payments were just a trivial example of a message, within the full set of possible messages. (Trivial, because we already had them, and trivial, to focus the mind on the full possible set. Not trivial just from being payments, as these are anything but trivial.)
The inspiration was then to flip the architecture system around: trade is messages, and to improve trade, improve the messaging capability. I didn't want semantics, I wanted freedom from semantics. I wanted a messaging system, with payments tacked on, rather than a payments system based on messaging. Indeed, I wanted a messaging system that could support arbitrary messages, and payments were just a trivial example of a message, within the full set of possible messages. (Trivial, because we already had them, and trivial, to focus the mind on the full possible set. Not trivial just from being payments, as these are anything but trivial.)
So the mission became to convert our payments-system-built-over-messaging into a messaging-system-with-payments. It seemed elegant enough, so over several nights at Rafi's, over ribs and beer, I outlined the story for my team:
- we want more transactions,
- payments business derives from trade ...
- trade is really messages, with a payment tacked on,
- we have a payment system, built on great messaging principles,
- we just need to switch the emphasis of our system architecture a little, to:
messaging-with-payments, not payments-over-messaging.
That's how Project Rafi's was born. I sold it to my team through beer & ribs, toasted the name, and commissioned a demo.
Of course, when people talk of messaging as an application, they think chat or Instant Messaging or SMS. So I seized that metaphor, and turned it into the popular expression of the mission. We were adding IM to our payment system, or so we said. Which was a subtly different subset to what I wanted, but close enough to be easy to sell, easy to discuss, and easy to tune in the detailed requirements and later implementation.
Sounds simple! Let's look back to the meat on the ribs of the original question: how did I do the architectural part? Looking at the above, the serial or static view is like this:
- define the business problem that I am trying to solve
- research the business context
- extract requirements
- build a virtual or model solution using some random classical technique or tools to hand
But this assumes too much omniscience, reality is far rougher, full of errors, omissions, unknowns. So, we need an error-correcting overlay, a feedback cycle. The dynamic view is then cyclical:
e. at each step, I test my results & conclusions against the earlier parts. E.g., test the solution against the requirements .. then test against the known business variations ... then similar business problems ... then the business statement.
e-bis. something breaks.
f. Out of which breach, identify the broken part (solution, requirements, research, problem).
f-bis. Jump back to a,b,c or d, depending. Evolve and re-state the broken input.
g. keep doing it until elegance strikes me on the forehead and I can't shake it off!
Now, this might be special, but it's not unique, Indeed, you can find this on the net if you look around. Here's one from Malan and Bredemeyer:
A 9 word summary might be set the mission, start high, go deeper, test, iterate. Or, if you want the 1 word secret, it is Iterate! Those with a sense of military history will see Boyd's OODA loop in there, with the problem being the enemy, the enemy being the problem, and the challenge to spin faster than the problem spins you :) And those with appetite will appreciate now why there are always so many ribs on the plate, and why architecture and fast food don't go well together.
What might offend some people is that it is so simple. I think the response to simplicity is that this easy model hides a lot, but that which it hides is not the essence of Architecture. Rather, the hidden part is the essence of something else, which the Architect is able to successfully integrate without spoiling the secret. And as this post is about Architecture, and is already long enough, I'll stop right there.
THE
the secretthe secret of software
the secret of software architecture
the secret of software architecture is . . .i t e r a t i o n !
Hence that age-old complaint of the frustrated architect, "there aren't enough ribs on my plate!"
May 14, 2010
SAP recovers a secret for keeping data safer than the standard relational database
Sometime in 1995 I needed a high performance database to handle transactions. Don't we all have these moments?
Like everyone, I looked at the market, which was then Oracle, Informix and so forth. But unlike most, I had one advantage. I had seen the dirty side of that business because I'd been called in several times to clean up clagged & scrunted databases for clients who really truly needed their data back up. From that repetitive work came an sad realisation that no database is safe, and the only safe design is one that records in good time a clean, unchangeable and easily repairable record of what was happening, for the inevitable rebuild. At any one time.
Recovery is the key, indeed, it is the primary principle of database design. So, for my transaction database, I knew I'd have to do that with Oracle, or the rest, and that's where the lightbulb came on. The work required to wrap a reliability layer around a commercial database is approximately as much as the work required to write a small, purpose-limited database. I gambled on that inspiration, and it proved profitable. In one month, I wrote a transaction engine that did the work for 10 years, never losing a single transaction (it came close once though!).
My design process also led me to ponder the truism that all fast stuff happens in memory, and also, that all reliance stuff happens at the point of logging the transaction request. Between these two points is the answer, which SAP seems to have stumbled on:
... As memory chips get cheaper, more and more of them are being packed into servers. This means that firms, instead of having to store their data on separate disks, can put most of them into their servers short-term memory, where they can be accessed and manipulated faster and more easily. The software SAP is releasing next week, a new version of Business ByDesign, its suite of online services for small companies, aims to capitalise on this trend, dubbed in-memory. SAP also plans to rewrite other programs along similar lines. ...
The answer is something almost akin to a taboo: the database is only in memory, and the writes to slow storage are only transaction logging, not database actions. Which leads to the conclusion that when it crashes, all startups are recoveries, from the disk-based transaction log. If this were an aphorism, it would be like this: There is only one startup, and it is a recovery.
In-memory technology is already widespread in systems that simply analyse data, but using it to help process transactions is a bigger step. SAPs software dispenses with the separate relational databases where the data behind such transactions are typically stored, and instead retains the data within the servers memory. This, says Vishal Sikka, the firms chief technologist, not only speeds up existing programsit also makes them cheaper to run and easier to upgrade, and makes possible real-time monitoring of a firms performance.
 In its space, an in-memory database will whip the standard SQL-based database in read-times, which is the majority usage, and it doesn't have to be a slouch in write times either, because a careful design can deliver writes-per-transaction on par with the classical designs. Not only in performance but in ROI, because the design concept forces it into a highly-reliable, highly-maintainable posture which reduces on-going costs.
In its space, an in-memory database will whip the standard SQL-based database in read-times, which is the majority usage, and it doesn't have to be a slouch in write times either, because a careful design can deliver writes-per-transaction on par with the classical designs. Not only in performance but in ROI, because the design concept forces it into a highly-reliable, highly-maintainable posture which reduces on-going costs.
But this inversion of classical design is seen as scary by those who are committed to the old ways. Why such a taboo? Partly because, in contrast to my claim that recovery is the primary principle of database design, it has always been seen as an admission of failure, as very slow, as fraught with danger, in essence, something to be discriminated against. And, it is this discrimination that I've seen time and time again: nobody bothers to prove their recovery, because "it never happens to them." Recovery is insurance for databases, and is not necessary except to give your bosses a good feeling.
But that's perception. Reality is different. Recovery can be very fast for all the normal reasons, the processing time for recovering each individual record is about the same as reading in the record off-disk anyway. And, if you really need your data, you really need your recovery. The failure and fall-back to recovery needs to be seen in balance: you have to prove your recovery, so you may as well make it the essence not the fallback.
That said, there are of course limitations to what SAP calls the in-memory approach. This works when you don't mind the occasional recovery, in that always-on performance isn't really possible. (Which is just another way of re-stating the principle that data never fails, because the transaction integrity takes priority over other desires like speed). Also, complexity and flexibility. It is relatively easy to create a simple database, and it is relatively easy to store a million records in the memory available to standard machines. But this only works if you can architecturally carve out that particular area out of your business and get it to stand alone. If you are more used to the monolithic silos with huge databases, datamining, data-ownership fights and so forth, this will be as irrelevant to you as a McDonalds on the Moon.
Some observers are not convinced. They have not forgotten that many of SAPs new products in the past decade have not been big successes, not least Business ByDesign. There is healthy scepticism as to whether all this will work, says Brent Thill of UBS, an investment bank. Existing customers may prefer not to risk disrupting their customised computer systems by adopting the new software.
And don't forget that 3 entire generations of programmers are going to be bemused, at sea, when they ask for the database schema and are told there isn't one. For most of them, there is no difference between SQL and database.
On a closing note, my hat's off to the Economist for picking up this issue, and recognising the rather deeper questions being asked here. It is rare for anyone in the media to question the dogma of computing architecture, let alone a tea-room full of economists. Another gem:
These efforts suggest that in-memory will proliferate, regardless of how SAP will fare. That could change the way many firms do business. Why, for example, keep a general ledger, if financial reports can be compiled on the fly?
Swoon! If they keep this up, they'll be announcing the invention of triple entry bookkeeping in a decade, as that is really what they're getting at. I agree, there are definitely many other innovations out there, waiting to be mined. But that depends on somewhat adroit decision-making, which is not necessarily in evidence. Unfortunately, this in-memory concept is too new idea to many, so SAP will need to plough the ground for a while.
Larry Ellison, the boss of Oracle, which makes most of its money from such software, has ridiculed SAPs idea of an in-memory database, calling it wacko and asking for the name of their pharmacist.
But, after they've done that, after this idea is widely adopted, we'll all be looking back at the buggy whip crowd, and voting who gets the "Ken Olsen of the 21st Century Award."
March 24, 2010
Why the browsers must change their old SSL security (?) model
In a paper Certified Lies: Detecting and Defeating Government Interception Attacks Against SSL_, by Christopher Soghoian and Sid Stammby, there is a reasonably good layout of the problem that browsers face in delivering their "one-model-suits-all" security model. It is more or less what we've understood all these years, in that by accepting an entire root list of 100s of CAs, there is no barrier to any one of them going a little rogue.
Of course, it is easy to raise the hypothetical of the rogue CA, and even to show compelling evidence of business models (they cover much the same claims with a CA that also works in the lawful intercept business that was covered here in FC many years ago). Beyond theoretical or probable evidence, it seems the authors have stumbled on some evidence that it is happening:
The companys CEO, Victor Oppelman confirmed, in a conversation with the author at the companys booth, the claims made in their marketing materials: That government customers have compelled CAs into issuing certificates for use in surveillance operations. While Mr Oppelman would not reveal which governments have purchased the 5-series device, he did confirm that it has been sold both domestically and to foreign customers.
(my emphasis.) This has been a lurking problem underlying all CAs since the beginning. The flip side of the trusted-third-party concept ("TTP") is the centralised-vulnerability-party or "CVP". That is, you may have been told you "trust" your TTP, but in reality, you are totally vulnerable to it. E.g., from the famous Blackberry "official spyware" case:
Nevertheless, hundreds of millions of people around the world, most of whom have never heard of Etisalat, unknowingly depend upon a company that has intentionally delivered spyware to its own paying customers, to protect their own communications security.
Which becomes worse when the browsers insist, not without good reason, that the root list is hidden from the consumer. The problem that occurs here is that the compelled CA problem multiplies to the square of the number of roots: if a CA in (say) Ecuador is compelled to deliver a rogue cert, then that can be used against a CA in Korea, and indeed all the other CAs. A brief examination of the ways in which CAs work, and browsers interact with CAs, leads one to the unfortunate conclusion that nobody in the CAs, and nobody in the browsers, can do a darn thing about it.
So it then falls to a question of statistics: at what point do we believe that there are so many CAs in there, that the chance of getting away with a little interception is too enticing? Square law says that the chances are say 100 CAs squared, or 10,000 times the chance of any one intercept. As we've reached that number, this indicates that the temptation to resist intercept is good for all except 0.01% of circumstances. OK, pretty scratchy maths, but it does indicate that the temptation is a small but not infinitesimal number. A risk exists, in words, and in numbers.
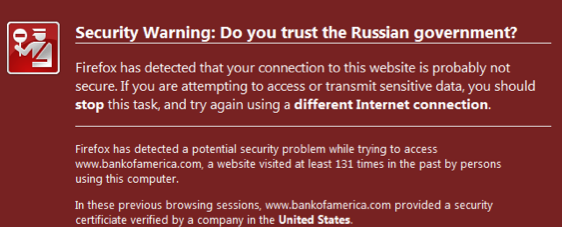
One CA can hide amongst the crowd, but there is a little bit of a fix to open up that crowd. This fix is to simply show the user the CA brand, to put faces on the crowd. Think of the above, and while it doesn't solve the underlying weakness of the CVP, it does mean that the mathematics of squared vulnerability collapses. Once a user sees their CA has changed, or has a chance of seeing it, hiding amongst the crowd of CAs is no longer as easy.
Why then do browsers resist this fix? There is one good reason, which is that consumers really don't care and don't want to care. In more particular terms, they do not want to be bothered by security models, and the security displays in the past have never worked out. Gerv puts it this way in comments:
Security UI comes at a cost - a cost in complexity of UI and of message, and in potential user confusion. We should only present users with UI which enables them to make meaningful decisions based on information they have.
They love Skype, which gives them everything they need without asking them anything. Which therefore should be reasonable enough motive to follow those lessons, but the context is different. Skype is in the chat & voice market, and the security model it has chosen is well-excessive to needs there. Browsing on the other hand is in the credit-card shopping and Internet online banking market, and the security model imposed by the mid 1990s evolution of uncontrollable forces has now broken before the onslaught of phishing & friends.
In other words, for browsing, the writing is on the wall. Why then don't they move? In a perceptive footnote, the authors also ponder this conundrum:
3. The browser vendors wield considerable theoretical power over each CA. Any CA no longer trusted by the major browsers will have an impossible time attracting or retaining clients, as visitors to those clients websites will be greeted by a scary browser warning each time they attempt to establish a secure connection. Nevertheless, the browser vendors appear loathe to actually drop CAs that engage in inappropriate be- havior a rather lengthy list of bad CA practices that have not resulted in the CAs being dropped by one browser vendor can be seen in [6].
I have observed this for a long time now, predicting phishing until it became the flood of fraud. The answer is, to my mind, a complicated one which I can only paraphrase.
For Mozilla, the reason is simple lack of security capability at the *architectural* and *governance* levels. Indeed, it should be noticed that this lack of capability is their policy, as they deliberately and explicitly outsource big security questions to others (known as the "standards groups" such as IETF's RFC committees). As they have little of the capability, they aren't in a good position to use the power, no matter whether they would want to or not. So, it only needs a mildly argumentative approach on the behalf of the others, and Mozilla is restrained from its apparent power.
What then of Microsoft? Well, they certainly have the capability, but they have other fish to fry. They aren't fussed about the power because it doesn't bring them anything of use to them. As a corporation, they are strictly interested in shareholders' profits (by law and by custom), and as nobody can show them a bottom line improvement from CA & cert business, no interest is generated. And without that interest, it is practically impossible to get the various many groups within Microsoft to move.
Unlike Mozilla, my view of Microsoft is much more "external", based on many observations that have never been confirmed internally. However it seems to fit; all of their security work has been directed to market interests. Hence for example their work in identity & authentication (.net, infocard, etc) was all directed at creating the platform for capturing the future market.
What is odd is that all CAs agree that they want their logo on their browser real estate. Big and small. So one would think that there was a unified approach to this, and it would eventually win the day; the browser wins for advancing security, the CAs win because their brand investments now make sense. The consumer wins for both reasons. Indeed, early recommendations from the CABForum, a closed group of CAs and browsers, had these fixes in there.
But these ideas keep running up against resistance, and none of the resistance makes any sense. And that is probably the best way to think of it: the browsers don't have a logical model for where to go for security, so anything leaps the bar when the level is set to zero.
Which all leads to a new group of people trying to solve the problem. The authors present their model as this:
The Firefox browser already retains history data for all visited websites. We have simply modified the browser to cause it to retain slightly more information. Thus, for each new SSL protected website that the user visits, a Certlock enabled browser also caches the following additional certificate information:
A hash of the certificate.
The country of the issuing CA.
The name of the CA.
The country of the website.
The name of the website.
The entire chain of trust up to the root CA.When a user re-visits a SSL protected website, Certlock first calculates the hash of the sites certificate and compares it to the stored hash from previous visits. If it hasnt changed, the page is loaded without warning. If the certificate has changed, the CAs that issued the old and new certificates are compared. If the CAs are the same, or from the same country, the page is loaded without any warning. If, on the other hand, the CAs countries differ, then the user will see a warning (See Figure 3).
This isn't new. The authors credit recent work, but no further back than a year or two. Which I find sad because the important work done by TrustBar and Petnames is pretty much forgotten.
But it is encouraging that the security models are battling it out, because it gets people thinking, and challenging their assumptions. Only actual produced code, and garnered market share is likely to change the security benefits of the users. So while we can criticise the country approach (it assumes a sort of magical touch of law within the countries concerned that is already assumed not to exist, by dint of us being here in the first place), the country "proxy" is much better than nothing, and it gets us closer to the real information: the CA.
From a market for security pov, it is an interesting period. The first attempts around 2004-2006 in this area failed. This time, the resurgence seems to have a little more steam, and possibly now is a better time. In 2004-2006 the threat was seen as more or less theoretical by the hoi polloi. Now however we've got governments interested, consumers sick of it, and the entire military-industrial complex obsessed with it (both in participating and fighting). So perhaps the newcomers can ride this wave of FUD in, where previous attempts drowned far from the shore.
December 07, 2009
H4.3 - Simplicity is Inversely Proportional to the Number of Designers
Which reminds me to push out yet another outrageous chapter in secure protocol design. In my hypothesis #4 on Protocol Design, I claim this:
#4.3 Simplicity is Inversely Proportional to the Number of DesignersNever doubt that a small group of thoughtful, committed citizens can change the world. Indeed, it is the only thing that ever has.
Margaret MeadSimplicity is proportional to the inverse of the number of designers. Or is it that complexity is proportional to the square of the number of designers?
Sad but true, if you look at the classic best of breed protocols like SSH and PGP, they delivered their best results when one person designed them. Even SSL was mostly secure to begin with, and it was only the introduction of PKI with its committees, world-scale identity models, digital signature laws, accountants and lawyers that sent it into orbit around Pluto. Committee-designed monsters such as IPSec and DNSSEC aren't even in the running.
Sometimes a protocol can survive a team of two, but we are taking huge risks (remember the biggest failure mode of all is failing to deliver anything). Either compromise with your co-designer quickly or kill him. Your users will thank you for either choice, they do not benefit if you are locked in a deadly embrace over the sublime but pernickety benefits of MAC-then-encrypt over encrypt-then-MAC, or CBC versus Counter-mode, or or or...
More at hypotheses on Secure Protocol Design.
December 03, 2009
Unix turns 40 -- the patience of Sun Tzu
The systems world will shortly be celebrating a major anniversary milestone. UNIX® is turning 40 years old! Most of us know the story of how UNIX was born, but what about why? Was it born strictly because its founders wanted to play a computer game on a different platform? And why does UNIX continue to thrive 15 years after an (in)famous Byte Magazine article that asked, "Is UNIX dead?"
Good questions for systems architects. You might not want to study Unix, but you should in your time study the full evolution of a few systems, and compare and contrast: why did this one succeed and others fail? Surprisingly, the reasons are generally different each time. It's almost as if the gods of the market learn and spite us if we copy the past successes, each time.
The very early story:
Ken Thompson developed a game on the GE-645 mainframe called Space Travel. Unfortunately, the game was just running too slow on the GE box, so Thompson rewrote (in assembly) the game for DEC's PDP-7, with the help of Dennis Ritchie. The porting experience led Ken to develop a new OS for the PDP-7. This included a file system as well as the new multi-tasking operating system itself. They included a command-line interpreter and some small utility programs.The project was originally named Unics, and it could eventually support two simultaneous users, which led to some financial support from Bell. In 1970, UNIX became the official name for the operating system, which ran on the PDP-11/20. It also included roff (a text formatting program) and a text editor.
The things to drag out of that is: Very Small Team. No Corporate Direction. And, they did what they needed. What did they need? Roff. Which was used for preparing papers ... which just happens to have been what all academic institutions need from their computers (above all other needs).
Ultimately, it was rewritten in C in 1973, which made it portable and changed the history of operating systems.
OK, sort of. More clearly, it made it readable. So when Computer Science departments started installing it, they found themselves with a readable, understandable and advanced operating system. What does that mean? Teaching! Unix became a favourite in the Universities because it gave a full pedagogical experience. Which lead to a generation of engineers in the early 1980s demanding it.
The portability came later, because these engineers want it. In practice, the first port off PDP-11s was done in Wollongong, as an academic exercise. But in the mid 1980s, the cost of hardware had come down, and the cost of software was rapidly rising. At the crossing point was a demand for a cheap operating system, and this meant "one you didn't have to write yourself" (curiously echoed by Bill Gates' purchase of QDOS for $50k.)
Unix took over the market for all challengers to IBM, because they couldn't beat IBM on its ability to invest in software. See _The Soul of a new Computer_ for a counterpoint, a book every architect should read. Or to be fair, Unix took over "sophisticated" end of the market, and MS-DOS took over the "basic PS" end. Between them, they destroyed IBM -- to then the greatest tech company ever -- in a single decade.
 IBM of course fought back in the 1990s, and adopted Unix as well. However, marketing games roll on. In this article, IBM adopts the "licensed" view of what Unix is, which is either polite to the licensors or deceptive depending on who butters your bread. It misses out the other two gorillas in the room: BSD on Mac and Linux. Does anyone have any figures on operating systems revenues for Mac OSX 10 and Linux family?
IBM of course fought back in the 1990s, and adopted Unix as well. However, marketing games roll on. In this article, IBM adopts the "licensed" view of what Unix is, which is either polite to the licensors or deceptive depending on who butters your bread. It misses out the other two gorillas in the room: BSD on Mac and Linux. Does anyone have any figures on operating systems revenues for Mac OSX 10 and Linux family?
Compare the chart in the IBM article to the one posted a month back.
Why does Unix live on? In part because it can do the serious things, in part because it is simply available, and in part its history was so much more oriented to the net, and it has gradually evolved to be good for it. Whereas the main competitor comes from the user-interface world, and eschewed the net in its core principles until 2002. During the 2000s, Microsoft lost a lot of ground because of security and lack of openness, ground that others were well prepared to take up. To read Sun Tzu:
The good fighters of old first put themselves beyond the possibility of defeat, and then waited for an opportunity of defeating the enemy. To secure ourselves against defeat lies in our own hands, but the opportunity of defeating the enemy is provided by the enemy himself. Thus the good fighter is able to secure himself against defeat, but cannot make certain of defeating the enemy.
Patience also is necessary. Why think about these things? Because the same battles are being fought out today. As in the charts here, but also between facebook and myspace, between blue-ray and HD-DVD, between the gold currencies, between the rebel currencies and the banks, between old media and the new. In each of these battles, the same factors emerge, as do winners and losers, and the only easy way to predict that future is to really study the examples of the past.
(Yes, there are harder and more expensive ways to learn, such as playing it yourself.)
November 17, 2009
Timeline for an SSL protocol breach -- what's the size of your OODA loop?
SSL is a protocol that gives a point-to-point connection with some protection against MITM (man-in-the-middle). Attacks against SSL as a security paradigm can be characterised in three levels:
- within the protocol,
- within the application (but outside the protocol), and
- within the business (outside the application, but inside the personal relationships).
The reason we have to see this holistically, and include all three levels, is that SSL as a tool is worthless if the wider attacks are not dealt with, SSL is only valuable to the extent that they are dealt with, and SSL gets in the way to the extent that it imposes unreasonable responsibilities or expectations on the application or user.
Classical Phishing is the latter case, in that an email is sent to a user, who then clicks on a link. The application is not attacked, the "business" is. This is the MITM that caused the explosion in phishing around 2003. MITB (man-in-the-browser) is the next level down, attacking the application directly. The perverse linkage to the MITM of phishing is that the phishing explosion financed the move into application-level attacks.
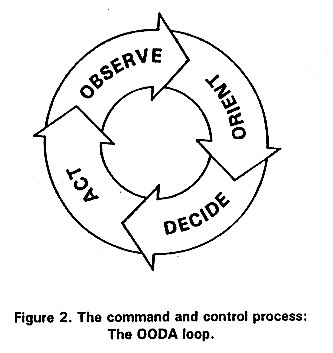 Now, all of that is security as it is delivered to users. There is then protocol security, and here SSL has generally excelled. It meets its internal protocol goals very well, and always has done so. Now news has surfaced of a rare thing: an in-protocol attack against SSL:
Now, all of that is security as it is delivered to users. There is then protocol security, and here SSL has generally excelled. It meets its internal protocol goals very well, and always has done so. Now news has surfaced of a rare thing: an in-protocol attack against SSL:
Members of an industry-wide consortium had been meeting in secret since late September to hash out a fix that will be rolled into thousands of individual pieces of hardware and software that implement the TLS protocol. The bug became public when it was disclosed by a researcher not involved in the project. So far, OpenSSL is the only provider that is close to releasing a patch, according to this status page.
How serious is this? Initial comments were that it was hard to exploit, but now news is filtering through that Anil Kurmus has written an exploit against Twitter.
It's an evolving topic. What I find interesting however is that this represents a good event to make some OODA observations. Here's what I've gathered so far:
| "late September" | bug announced to industry consortium secretly? (name?) | 0m |
| 20091104 | public disclosure by Marsh Ray and Steve Dispensa | 2m |
| 20091110 | twitter exploit announced | 2m |
The interesting conclusion to draw here is we can possibly measure the size of the OODA loop for the SSL industry, at least in this one event.
And here is what is emerging over time:
| 20091207 | fix for Mozilla's NSS crypto library announced by Nelson Bolyard | 3m |
| 20100208 | Firefox nightly builds now include partial patch announced by Daniel Veditz | 5m |
| 20130409 | SSL Pulse reports 80.3% of SSL sites patched and protected (picture shows 20130905) | 41m |
(Editor's note: Second table added and augmented after original publication.)
November 08, 2009
my War On SQL
Around three weeks ago, I had a data disaster. In a surprise attack, 2 weeks worth of my SQL DATABASE was wiped out. Right after my FIRST weekend demo of some new code. The horror!
On that Monday morning I went into shell-shock for hours as I tried to trace where the results of the demo -- the very first review of my panzer code -- had disappeared to. By 11:00 there was no answer, and finger-of-blame pointed squarely at some SQL database snafu. The decision was reached to replace the weaponry with tried and trusty blades of all wars previous: flat files, the infantry of data. By the end of the day, the code was written to rebuild the vanguard from its decimated remains, and the next day, work-outs and field exercises proved the results. Two tables entirely replaced, reliably.
That left the main body, a complex object split across many tables, and the rearguard of various sundry administrative units. It took another week to write the object saving & restoring framework, including streaming, model-objects along the lines of MVC for each element, model-view-controller conversions and unit-testing. (I need a name for this portable object pattern. It came from SOX and I didn't think much of it at the time, but it seems nobody else does it.) Then, some days of unit tests, package tests, field tests, and so forth. Finally, 4-5 days of application re-working to use object database methods, not SQL.
16 days later, up and going. The army is on the march, SQL is targetted, acquired, destroyed. Defeated, wiped off the map, no longer to blot on the territory of my application. 2 days of mop-up and I'm back to the demo.
Why go on a holy crusade against SQL? There are several motives for this war:
- Visibility. Like all databases, SQL is a black box. How exactly do you debug an application sitting on a black box?
- Visibility #2. When it goes wrong, the caller/user/owner is powerless to fix it. It's a specialist task to even see inside.
- Generalist. This database is lightweight, indeed it's called SQLite. The point isn't that it is "worse" than the rest, but that it'll have to be replaced one day. Why? All of these things are generalists and cannot cope with narrow, precise requirements. In other words, they look good on the parade ground, but when the shooting starts, the only order is "retreat!"
- Achilles heel: backups have to manually created, recovered, tested on a routine basis. Yet this never gets done, and when the data corrupts, it is too late. Making backups easy is the #1 priority of all databases. Did you know that? Funnily enough, neither did any of the database providers.
And then there's the interface. Let us not shame the mere technical _casus belli_ above, let us put the evil that is SQL in a section of abomination, all of its own:
SQL is in the top 5 of the computing world's most awful anachronisms. It's right up there with ASN1, X.509, LDAP, APL, and other embarrassments to the world of computer science. In this case, there is one reason why SQL stands out like the sideways slice of death of a shamed samurai: data! these things, SQL included, were all designed when data was king, we all had to bow before the august power of our corporate bytes, while white-suited priests inserted the holy decks and the tapes of glory into bright shining temples of the mainframe of enlightenment.
But those imperial times are over. The false data-is-god was slain, discarded and buried, in the glorious & bloody revolution of the Object, that heathen neologism that rose up and slew and enslaved data during the early 1980s. Data-only is slain, data is dead. Data is captured, enslaved, owned. It is now objects, objects, objects. Data is an immoral ghost of its former self, when let out from its rightful context of semantic control.
These are the reasons why I leapt to the field to do battle to the death with the beast that is SQL. My report from the field is as follows:
- operating from a flat files data store is slower and faster, depending on the type of action. Direct actions by my code are slower than SQL, but complicated actions are quicker. Overall, we are talking 10 - 50ms, so it is all in the "whatever" rating.
- Code overall is dramatically simpler. There is no need to emasculate the soul of ones object model. Simply store the object, and get back to the fight. The structure of the code, the design, is simplified as the inherently senseless interface of OO to SQL is gone, it is now more OO, more top-to-bottom.
- Joins have to be done in main code. This is an advantage for the coder, because the coder knows the main code, and the main language.
- debugging is much easier because the data can be read, those times that is necessary, and the data can be seen, which is necessary all the time.
- object transactions are trivial. Cross-object transactions are tricky. This forces the general in the field to be much more balanced.
- no data is ever lost. At least, in my design, it can't be lost by action of the code, as everything is append-only.
- it is uses about 5 times more space on the battlefield of your diskspace. Another "whatever..."
- The code length is about the same. What was additionally required in database code (1kloc) was taken away in awfully complicated SQL interfacing code that melted away. The "Model" code, that is, the objects to be saved is an additional 1kloc, but required anyway for clean OO design.
I continue to mop up. What's the bottom line? Control. The application controls the objects and the objects control their data.
So what went wrong with SQL? Fundamentally it was designed in a day when data was seriously different. Those days are gone, now data is integrally related to code. It's called "object oriented" and even if you don't know how to do it, it is how it is doing it to you. The object owns the data, not the database. Data seen naked is an abomination, and SQL is just rags on a beast; it's still a beast.
Sadly, the world is still a decade or two away from this. And, to be fair, hattip to Jeroen van Gelderen for the OO database he designed and built for Webfunds. Using that was a lesson in how much of a delight it was to be OO all the way down to the disk-byte.
October 19, 2009
Denial of Service is the greatest bug of most security systems
 I've had a rather troubling rash of blog comment failure recently. Not on FC, which seems to be ok ("to me"), but everywhere else. At about 4 in the last couple of days I'm starting to get annoyed. I like to think that my time in writing blog comments for other blogs is valuable, and sometimes I think for many minutes about the best way to bring a point home.
I've had a rather troubling rash of blog comment failure recently. Not on FC, which seems to be ok ("to me"), but everywhere else. At about 4 in the last couple of days I'm starting to get annoyed. I like to think that my time in writing blog comments for other blogs is valuable, and sometimes I think for many minutes about the best way to bring a point home.
But more than half the time, my comment is rejected. The problem is on the one hand overly sophisticated comment boxes that rely on exotica like javascript and SSO through some place or other ... and spam on the other hand.
These things have destroyed the credibility of the blog world. If you recall, there was a time when people used blogs for _conversations_. Now, most blogs are self-serving promotion tools. Trackbacks are dead, so the conversational reward is gone, and comments are slow. You have to be dedicated to want to follow a blog and put a comment on there, or stupid enough to think your comment matters, and you'll keep fighting the bl**dy javascript box.
The one case where I know clearly "it's not just me" is John Robb's blog. This was a *fantastic* blog where there was great conversation, until a year or two back. It went from dozens to a couple in one hit by turning on whatever flavour of the month was available in the blog system. I've not been able to comment there since, and I'm not alone.
This is denial of service. To all of us. And, this denial of service is the greatest evidence of the failure of Internet security. Yet, it is easy, theoretically easy to avoid. Here, it is avoided by the simplest of tricks, maybe one per month comes my way, but if I got spam like others get spam, I'd stop doing the blog. Again denial of service.
Over on CAcert.org's blog they recently implemented client certs. I'm not 100% convinced that this will eliminate comment spam, but I'm 99.9% convinced. And it is easy to use, and it also (more or less) eliminates that terrible thing called access control, which was delivering another denial of service: the people who could write weren't trusted to write, because the access control system said they had to be access-controlled. Gone, all gone.

According to the blog post on it:
The CAcert-Blog is now fully X509 enabled. From never visited the site before and using a named certificate you can, with one click (log in), register for the site and have author status ready to write your own contribution.
Sounds like a good idea, right? So why don't most people do this? Because they can't. Mostly they can't because they do not have a client certificate. And if they don't have one, there isn't any point in the site owner asking for it. Chicken & egg?
But actually there is another reason why people don't have a client certificate: it is because of all sorts of mumbo jumbo brought up by the SSL / PKIX people, chief amongst which is a claim that we need to know who you are before we can entrust you with a client certificate ... which I will now show to be a fallacy. The reason client certificates work is this:
If you only have a WoT unnamed certificate you can write your article and it will be spam controlled by the PR people (aka editors).If you had a contributor account and havent posted anything yet you have been downgraded to a subscriber (no comment or write a post access) with all the other spammers. The good news is once you log in with a certificate you get upgraded to the correct status just as if youd registered.
We don't actually need to know who you are. We only need to know that you are not a spammer, and you are going to write a good article for us. Both of these are more or less an equivalent thing, if you think about it; they are a logical parallel to the CAPTCHA or turing test. And we can prove this easily and economically and efficiently: write an article, and you're in.

Or, in certificate terms, we don't need to know who you are, we only need to know you are the same person as last time, when you were good.
This works. It is an undeniable benefit:
There is no password authentication any more. The time taken to make sure both behaved reliably was not possible in the time the admins had available.
That's two more pluses right there: no admin de-spamming time lost to us and general society (when there were about 290 in the wordpress click-delete queue) and we get rid of those bl**dy passwords, so another denial of service killed.
Why isn't this more available? The problem comes down to an inherent belief that the above doesn't work. Which is of course a complete nonsense. 2 weeks later, zero comment spam, and I know this will carry on being reliable because the time taken to get a zero-name client certificate (free, it's just your time involved!) is well in excess of the trick required to comment on this blog.
No matter the *results*, because of the belief that "last-time-good-time" tests are not valuable, the feature of using client certs is not effectively available in the browser. That which I speak of here is so simple to code up it can actually be tricked from any website to happen (which is how CAs get it into your browser in the first place, some simple code that causes your browser to do it all). It is basically the creation of a certificate key pair within the browser, with a no-name in it. Commonly called the self-signed certificate or SSC, these things can be put into the browser in about 5 seconds, automatically, on startup or on absence or whenever. If you recall that aphorism:
There is only one mode, and it is secure.
And contrast it to SSL, we can see what went wrong: there is an *option* of using a client cert, which is a completely insane choice. The choice of making the client certificate optional within SSL is a decision not only to allow insecurity in the mode, but also a decision to promote insecurity, by practically eliminating the use of client certs (see the chicken & egg problem).
And this is where SSL and the PKIX deliver their greatest harm. It denies simple cryptographic security to a wide audience, in order to deliver ... something else, which it turns out isn't as secure as hoped because everyone selects the wrong option. The denial of service attack is dominating, it's at the level of 99% and beyond: how many blogs do you know that have trouble with comments? How many use SSL at all?
So next time someone asks you, why these effing passwords are causing so much grief in your support department, ask them why they haven't implemented client certs? Or, why the spam problem is draining your life and destroying your social network? Client certs solve that problem.
 SSL security is like Bismarck's sausages: "making laws is like making sausages, you don't want to watch them being made." The difference is, at least Bismark got a sausage!
SSL security is like Bismarck's sausages: "making laws is like making sausages, you don't want to watch them being made." The difference is, at least Bismark got a sausage!
Footnote: you're probably going to argue that SSCs will be adopted by the spammer's brigade once there is widespread use of this trick. Think for minute before you post that comment, the answer is right there in front of your nose! Also you are probably going to mention all these other limitations of the solution. Think for another minute and consider this claim: almost all of the real limitations exist because the solution isn't much used. Again, chicken & egg, see "usage". Or maybe you'll argue that we don't need it now we have OpenID. That's specious, because we don't actually have OpenID as yet (some few do, not all) and also, the presence of one technology rarely argues against another not being needed, only marketing argues like that.
September 25, 2009
Where does anyone (young) want to go, today?
I got some good criticism on the post about accounting as a profession. Clive said this which I thought I'd share:
As an engineer who's father was an accountant I will give you three guesses as to what he told me not to do when I grew up... Oddly it is the same for engineers, we tend to tell our children to do other things. As I've said before if you want to get on in life you should learn to speak the language that the man who cuts your cheque at the end of the month does, or more correctly his boss ;)So even if you are just a humble team leader get yourself three courses,
- MBA,
- Vocal training,
- Psychology or Method acting.
And no I'm not joking about 3.
He's talking about what we do when we get to 30 and beyond, e.g., most readers of this blog. For us older folks looking back, it is depressing that the world looks so sucky; but this is a time-honoured thing. The myths have been stripped away, the rot revealed.
But the youth of today is perpetually optimistic, and the question they ask is eternal and (Spence-like) opinionated: what to study, first?
What then do we recommend for a first degree for someone near 20? It seems that nobody promotes the accountancy field, including the incumbents. Accountants don't practice accountancy, if they are any good. The only accountant I ever knew well committed suicide.
An MBA doesn't work, this is something that should be done after around 5-10 years of experience. Hence, I'm not convinced a straight business degree ("Bachelors in Business Studies" ?) makes sense either, because all that additional stuff doesn't add value until experience is there to help it click into place.
I wouldn't suggest economics. It is like law and accounting, in that it helps to provide a very valuable perspective throughout higher business planes. But it doesn't get you jobs, and it is too divorced from practical life, too hard to apply in detail. Engineering seems far too specialised these days, and a lot of it is hard to work in and subject to outsourcing. Science is like engineering but without the focus.
To my mind, the leading contenders as a first degree are (in no particular order):
⇒ law,
⇒ computer science,
⇒ biotech, and
⇒ marketing.
Firstly, they seem to get you jobs; secondly, law, compsci and marketing are easy to apply generally and broadly, and pay dividends throughout life. I'm not quiet sure about Biotech in the "broad" sense, but it is the next big thing, it is the wave to ride in.
Comp sci was the wave of the 1980s and 1990s. Now it is routine. Any technical degree these days tends to include a lot of comp sci, so if there is a tech you enjoy, do that degree and turn it into a comp sci degree on the inside.
 Law is in my list because it is the ultimate defensive strategy. Headline Law tends to offend with its aggressively self-serving guild behaviour ("a man who represents himself has a fool for a client and a fool for a lawyer") and as a direct practice (courts) the field seems made for crooks. More technically, all disputes are win-lose by definition, and therefore litigation is destructive by definition, not productive. This is offensive to most of humanity.
Law is in my list because it is the ultimate defensive strategy. Headline Law tends to offend with its aggressively self-serving guild behaviour ("a man who represents himself has a fool for a client and a fool for a lawyer") and as a direct practice (courts) the field seems made for crooks. More technically, all disputes are win-lose by definition, and therefore litigation is destructive by definition, not productive. This is offensive to most of humanity.
But litigation is only the headline, there are other areas. You can apply the practical aspects of law in any job or business, and you can much more easily defend yourself and your business against your future fall, if you have a good understanding of the weapons of mutual destruction (a.k.a. lawsuits). About half of the business failures I've seen have occurred because there was no good legal advisor on the team; this is especially true of financial cryptography which is why I've had to pick up some of it; what one person I know calls "bush lawyering."
The downside to studying law is that you can lose your soul. But actually the mythology in law is not so bad because it is grounded in fundamental rights, so keep those in mind, and don't practice afterwards. It's nowhere near as bad as the computing scene (no grounding at all, e.g., open source) or the marketing blah blah (your mission is to unground other's perceptions!).
Marketing is there because every successful business needs it, and you can only be successful with it. MBAs are full of marketing, which reflects its centrality (and also gives a good option for picking it up later). But marketing is also dangerous because it gives you the tools to fool yourself and all around you, and once you've become accustomed to the elixir, your own grounding is at risk.
I don't advise any of the arts (including Clive's points 2,3) as a primary degree for youth, because businesses hire on substance, so it is important to have some to offer. E.g., people who study psychology tend to end up doing HR ("human resources"), badly, perhaps because they lack the marketing sense to make HR the most important part of the business.
Likewise, avoid anything that is popular, soft, fun, nice and that all your touchy-feely friends want to do. When there are too many people and too little substance, the competition suppresses everyone and makes you all poor. That's the best result because at least it is honest; a very few dishonest ones become rich because they figure out the game. The notion that you can study acting, media, history, photography or any of the finer arts, and then make a living, doesn't bear talking about. It is literally gambling with lives, and has no place in advice to young people.
September 17, 2009
TOdd on Audits V: why oh why?
Editor's note: TOdd wrote this long comment to Audits V and I thought it had to be a post:
Regarding the failure of financial auditing, or statutory audits, there is probably a body of knowledge to be found in academia and business journals. There is certainly a lot of wisdom and knowledge among the accounting profession, although it is heavily suppressed, and auditors, like bankers, start out opaque and unself-aware. All three of these things grow deeper over lifelong habit (lack of honest self appraisal, lack of communication skills to talk about their business in anything but literal terms, and lack of any motive or impulse to be honest or candid even if they wanted to.) So, you'll find the best research on this problem in the business schools and press, for whom auditors are a business problem to be understood, and in the accountancy schools who still harbor a lot of great minds, with too much integrity to survive in the global audit firms. The audit profession took root in the 1930s and I would have to guess that it was captured from day one, by the publicly listed companies they were supposed to be auditing.
Accountants have had the choice to improve themselves at several historic points in time; the 1929 crash, the end of WW2, when every other economy was demolished, and the end of the Soviet threat. What they've actually done was continue fiddling with their false definitions of economic substance, called GAAP, which is really intended to modulate the lies and maintain as much opaqueness as the public would tolerate.
The greatest opportunity to improve business reporting, if that were the intention, has come from improvements in database, computing, and the internet. Internally of course, companies have built information tools to navigate and understand their customers, suppliers, financial structures and inner working. All of it conceived, developed and maintained for the benefit of senior executives. The host-centric, server-centric architecture of the dominant computing architectures (ibm, att, dec, sun, microsoft etc) reflect this.
There is nothing that reveals the intent and will of the AICPA more clearly than its design choices in XBRL. And I doubt if anybody will ever write the book about XBRL, since the people who realized what a betrayal it was, while it was being cooked up, were physically nauseated and left the standards bodies, myself included. Outside the meeting room and convention halls, there were more than a few people who saw what was happening-- and why would they pay annual dues of $thousands, plus travel costs, to attend the next XBRL conference, unless they were part of the corrupt agenda themselves?
I am reminded of the State of Washington democratic party convention I attended a few years ago-- more than 2/3s of the 1000 delegates from the precincts, statewide had never been to a convention before. And, by the end of the convention, a percentage even larger than that, was in open rebellion against the selection of candidates and railroading of the platform and agenda, by top party officials. So, 2/3s of them would never bother participating in the Democratic Party in the next election cycle either.
The people responsible for the sabotage and corruption of the AICPA's XBRL and other technologies, are Barry Melancon, working on behalf of opaque interests in the audit firms and wall street, and, the young turks they hired, Charlie Hoffman and Eric Cohen. Hoffman bubbled up in the Seattle area as an evangelist for microsoft technologies in accounting firms and probably never understood where the money and support for his magic carpet ride was coming from. Microsoft itself being a front-end for IBM and wall street. There have been a few, who try from time to time, to make these technologies honest, such as David RR Weber, Glen Gray, Bill McCarthy...
A more hopeful technology, ebXML emerged shortly after XBRL, and again the history is so vast, somebody should write a book---indeed would write a book-- if they had the stomach for it. Now, here, we ran into a different set of entrenched interests, the EDI industry and adjacent companies and interests. It was a fabulous project, with at least ten different workgroups, each with a lot of dedicated people, supported by many great companies.
To sum it all up-- there are people who want to use the power of computers and communications to reach process improvements, labor savings, AND transparency for all stakeholders. These people have developed over many years, a very complete understanding of business processes in their industries and somewhat less completely, a generalized architecture for all economic transactions. However, there are a plutocracy who own all their companies and make all of the hiring and firing decisions. Obviously, these people at the very top, have leaned hard on the tiller, since the early days.

And the accounting and auditing profession knows where its bread is buttered, see Bob Elliot's diagram of "five stage value chain."
Iang responds in the next post.
September 16, 2009
Talks I'd kill to attend....
 I'm not sure why I ended up on this link ... but it was something very strange. And then I saw this:
I'm not sure why I ended up on this link ... but it was something very strange. And then I saw this:
"Null References: The Billion Dollar Mistake"
That resonated! So what's it about? Well, some dude named Tony Hoare says:
I call it my billion-dollar mistake. It was the invention of the null reference in 1965. At that time, I was designing the first comprehensive type system for references in an object oriented language (ALGOL W). My goal was to ensure that all use of references should be absolutely safe, with checking performed automatically by the compiler. But I couldn't resist the temptation to put in a null reference, simply because it was so easy to implement. This has led to innumerable errors, vulnerabilities, and system crashes, which have probably caused a billion dollars of pain and damage in the last forty years.
I'm in for some of that. Where do I sign?
It gets better! Hidden in there was an entire track of bad ideas! I'm in awe! Look at this:
"Standards are Great, but Standardisation is a Really Bad Idea"Standards arise from consensus between competitors signaling maturity in a marketplace. A good standard can ensure interoperability and assist portability, allowing the switching of suppliers. A widely adopted standard can create new markets, and impose useful constraints which in turn foster good design and innovation. Standards are great, and as the old joke goes, that's why we have so many of them!
If standards represent peace, then formal standardisation can be war! Dark, political, expensive and exclusive games played out between large vendors often behind closed doors. There are better ways to forge consensus and build agreements and the notion of a committee taking often a number of years to writing a specification, especially in the absence of implementation experience appears archaic in today's world of Agile methods, test driven development, open source, Wikis and other Web base collaborations.
When I die and go to heaven's conferences, that's what I want hear. But there's more!
"RPC and its Offspring: Convenient, Yet Fundamentally Flawed"... A fundamental goal of these and countless other similar technologies developed over the years was to shoehorn distributed systems programming into the local programming models so customary and convenient to the average developer, thereby hiding the difficult issues associated with distribution such as partial failure, availability and location issues, and consistency and synchronization problems. ....
The old abstract-away-the-net trick... yes, that one never works, but we'll throw it in for free.
But wait, there's MORE:
"Java enterprise application standards..."In the late 90's, the J2EE standard was greeted with much enthusiasm, as a legion of Java developers were looking to escape proprietary vendor lock-in and ill-conceived technologies and embrace a standard, expert-designed specification for building enterprise applications in Java.
Unfortunately, the results were mixed, and included expensive failures like CMP/BMP entity beans. History has shown that both committee-led standards and container-managed frameworks gave way to open source driven innovation and lightweight POJO-based frameworks.
oh, POJO, Oh, OH, PO JO! (Why am I thinking about that scene in _When Harry met Sally_?)
If you're a good software engineer (and all readers of this blog are *good* at something) you'll also appreciate this one:
"Traditional Programming Models: Stone knives and bearskins in the Google age"Programming has been taught using roughly the same approach for decades, but today's systems use radically different architectures -- consider the explosion in the count of processors and cores, massively distributed environments running parallel computations, and fully virtualized operating environments.
Learn how many of yesterday's programming principles have inadvertently become today's worst practices, and how these anti-patterns continue to form the basis of modern programming languages, frameworks and infrastructure software.
...
How come these guys have all the fun?
When and where is this assembly of net angels? Unlike Dave, I am not giving away tickets. Worse, you can't even pay for it with money. It's over! March 2009, and nobody knew. Who do I kill?
September 11, 2009
40 years on, packets still echo on, and we're still dropping the auth-shuns
It's terrifically cliched to say it these days, but the net is one of the great engineering marvels of science. The Economist reports it as 40 years old:
Such contentious issues never dawned on the dozen or so engineers who gathered in the laboratory of Leonard Kleinrock (pictured below) at the University of California, Los Angeles (UCLA) on September 2nd, 1969, to watch two computers transmit data from one to the other through a 15-foot cable. The success heralded the start of ARPANET, a telecommunications network designed to link researchers around America who were working on projects for the Pentagon. ARPANET, conceived and paid for by the defence departments Advanced Research Projects Agency (nowadays called DARPA), was unquestionably the most important of the pioneering packet-switched networks that were to give birth eventually to the internet.
Right, ARPA funded a network, and out of that emerged the net we know today. Bottom-up, not top-down like the European competitor, OSI/ISO. Still, it wasn't about doing everything from the bottom:
The missing link was supplied by Robert Kahn of DARPA and Vinton Cerf at Stanford University in Palo Alto, California. Their solution for getting networks that used different ways of transmitting data to work together was simply to remove the software built into the network for checking whether packets had actually been transmittedand give that responsibility to software running on the sending and receiving computers instead. With this approach to internetworking (hence the term internet), networks of one sort or another all became simply pieces of wire for carrying data. To packets of data squirted into them, the various networks all looked and behaved the same.
I hadn't realised that this lesson is so old, but that makes sense. It is a lesson that will echo through time, doomed to be re-learnt over and over again, because it is so uncomfortable: The application is responsible for getting the message across, not the infrastructure. To the extent that you make any lower layer responsible for your packets, you reduce reliability.
This subtlety -- knowing what you could push down into the lower layers, and what you cannot -- is probably one of those things that separates the real engineers from the journeymen. The wolves from the sheep, the financial cryptographers from the Personal-Home-Pagers. If you thought TCP was reliable, you may count yourself amongst latter, the sheepish millions who believed in that myth, and partly got us to the security mess we are in today. (Related, it seems is that cloud computing has the same issue.)
Curiously, though, from the rosy eyed view of today, it is still possible to make the same layer mistake. Gunnar reported on the very same Vint Cerf saying today (more or less):
Internet Design Opportunities for ImprovementThere's a big Gov 2.0 summit going on, which I am not at but in the event apparently John Markoff asked Vint Cerf ths following question: "what would you have designed differently in building the Internet?" Cerf had one answer: "more authentication"
I don't think so. Authentication, or authorisation or any of those other shuns is again something that belongs in the application. We find it sits best at the very highest layer, because it is a claim of significant responsibility. At the intermediate layers you'll find lots of wannabe packages vying for your corporate bux:
* IP * IP Password * Kerberos * Mobile One Factor Unregistered * Mobile Two Factor Registered * Mobile One Factor Contract * Mobile Two Factor Contract * Password * Password Protected transport * Previous Session * Public Key X.509 * Public Key PGP * Public Key SPKI * Public Key XML Digital Signature * Smartcard * Smartcard PKI * Software PKI * Telephony * Telephony Nomadic * Telephony Personalized * Telephony Authenticated * Secure remote password * SSL/TLS Client Authentication * Time Sync Token * Unspecified
and that's just in SAML! "Holy protocol hodge-podge Batman! " says Gunnar, and he's not often wrong.
Indeed, as Adam pointed out, the net works in part because it deliberately shunned the auth:
The packet interconnect paper ("A Protocol for Packet Network Intercommunication," Vint Cerf and Robert Kahn) was published in 1974, and says "These associations need not involve the transmission of data prior to their formation and indeed two associates need not be able to determine that they are associates until they attempt to communicate."
So what was Vint Cerf getting at? He clarified in comments to Adam:
The point is that the current design does not have a standard way to authenticate the origin of email, the host you are talking to, the correctness of DNS responses, etc. Does this autonomous system have the authority to announce these addresses for routing purposes? Having standard tools and mechanisms for validating identity or authenticity in various contexts would have been helpful.
Right. The reason we don't have standard ways to do this is because it is too hard a problem. There is no answer to what it means:
people like me could and did give internet accounts to (1) anyone our boss said to and (2) anyone else who wanted them some of this internet stuff and wouldn't get us in too much trouble. (Hi S! Hi C!)
which therefore means, it is precisely and only whatever the application wants. Or, if your stack design goes up fully past layer 7 into the people layer, like CAcert.org, then it is what your boss wants. So, Skype has it, my digital cash has it, Lynn's X959 has it, and PGP has it. IPSec hasn't got it, SSL hasn't got it, and it looks like SAML won't be having it, in truck-loads :) Shame about that!
Digital signature technology can help here but just wasn't available at the time the TCP/IP protocol suite was being standardized in 1978.
(As Gunnar said: "Vint Cerf should let himself off the hook that he didn't solve this in 1978.") Yes, and digital signature technology is another reason why modern clients can be designed with it, built in and aligned to the application. But not "in the Internet" please! As soon as the auth stuff is standardised or turned into a building block, it has a terrible habit of turning into treacle. Messy brown sticky stuff that gets into everything, slows everyone down and gives young people an awful insecurity complex derived from pimples.
Oops, late addition of counter-evidence: "US Government to let citizens log in with OpenID and InfoCard?" You be the judge!
September 04, 2009
Numbers: CAPTCHAs and Suicide Bombers
 Two hard numbers effecting the attack model. The cost of attacking a CAPTCHA system with people in developing regions, from the Economist's report on the state of the CAPTCHA nation:
Two hard numbers effecting the attack model. The cost of attacking a CAPTCHA system with people in developing regions, from the Economist's report on the state of the CAPTCHA nation:
The biggest flaw with all CAPTCHA systems is that they are, by definition, susceptible to attack by humans who are paid to solve them. Teams of people based in developing countries can be hired online for $3 per 1,000 CAPTCHAs solved. Several forums exist both to offer such services and parcel out jobs. But not all attackers are willing to pay even this small sum; whether it is worth doing so depends on how much revenue their activities bring in. If the benefit a spammer is getting from obtaining an e-mail account is less than $3 per 1,000, then CAPTCHA is doing a perfect job, says Dr von Ahn.
And here, outside our normal programme, is news from RAH that people pay for the privilege of being a suicide bomber:
A second analysis with Palantir uncovered more details of the Syrian networks, including profiles of their top coordinators, which led analysts to conclude there wasn't one Syrian network, but many. Analysts identified key facilitators, how much they charged people who wanted to become suicide bombers, and where many of the fighters came from. Fighters from Saudi Arabia, for example, paid the most -- $1,088 -- for the opportunity to become suicide bombers.
It's important to examine security models remote to our own, because it it gives us neutral lessons on how the economics effects the result. An odd comparison there, that number $1088 is about the value required to acquire a good-but-false set of identity documents.
September 03, 2009
How to avoid Yesterday's Unknowns - Algorithm Agility in Protocols
Following yesterday's post, here's a today example of thinking about unknowns -- yesterday's, today's and tomorrow's. Currently the experts in crypto and protocol circles are championing "algorithm agility". Why? Because SHA1 is under a cloud, and MD5 is all-but-drowned. It should be replaced!
MD5 is yesterday's unknown. I vaguely recall that MD5 was "not best" in 1995, and the trick was to put in SHA1 (and not SHA0). So is SHA1: this blog has frequently reported on SHA1 running into stormy weather, since the original Wang et al papers. I even placed it into a conceptual framework of Pareto security. We've known this since mid 2004, which makes it very yesterday's news.
Unfortunately, a lot of groups did not heed the warnings, and are still running systems based either loosely or completely on SHA1, MD5 or worse. And now the researchers have the bit between their academic teeth, and are attacking the CAs and their certs.
The good news is that people are now working to replace SHA1. The bad news is that they are looking around for someone (else) to blame. And one of the easy targets is the protocol itself, which is "insufficiently agile". Developers can do something about this, they can add "algorithm agility" and then the problem will go away, so the theory goes.
But another story can be seen in the SSL and OpenPGP communities. Both of these places spent inordinate amounts of time on algorithm agility in the past: RSA, DSA, bit strength, hashes within signatures, AES, DES, Blowfish, ... these are all negotiable, replaceable, variable _within the protocol_ at some level or other. In fact, during the 1990s, a great and glorious war was fought against patents, governments, businesses, individuals and even bits&bytes. For various reasons, each of these battlegrounds became a siren call for more agility.
But it seems that both camps forgot to make the hash function fully agile and replaceable. (Disclosure: I was part of the OpenPGP group, so I have more of a view on that camp. There were occasional muted discussions on this, but in general, the issue was always deferred. There was a mild sense of urgency, knowledge of the gap, but finishing the document was always more important than changing the protocol. I still don't disagree with that sense of priotities.)
Hash replacement was forgotten because all of the efforts were spent on fighting the last war. Agility wasn't pursued in its generality, because it was messy, complex and introduced more than its share of problems; instead, only known threats from the last war were made agile. And one was forgotten, of course, being the one never in dispute.
Instead of realising the trap, and re-thinking the approach, the cries of algorithm agility are getting louder. In 2019 we'll be here again, with complete and perfect hash agility (NIST-approved no doubt) and what will happen? Something else will break, and it'll be something that we didn't make agile. The cycle will start again.
Instead, cut the gordian knot, and go with The One:
"There is one cipher suite, and it is numbered Number 1."
When you see a cloud, don't buy an umbrella; replace the climate. With #2. Completely. This way, you and your users will benefit from all of the potential for a redesign of the entire protocol, not just the headline things from the last war that catch up to you today.
Most well-designed systems will last at least 5 years. Which gives room for a general planning cycle for replacing the lot. Which -- once you understand the strategy -- is a tractable design problem, because in modern software product development, most products are replaced completely every few years. A protocol need be no different.
So, once every cycle, you might spent a year cleaning up from the yesterday's war. And then, we get back to thinking about tomorrow's war for several years.
July 15, 2009
trouble in PKI land
The CA and PKI business is busy this week. CAcert, a community Certification Authority, has a special general meeting to resolve the trauma of the collapse of their audit process. Depending on who you ask, my resignation as auditor was either the symptom or the cause.
In my opinion, the process wasn't working, so now I'm switching to the other side of the tracks. I'll work to get the audit done from the inside. Whether it will be faster or easier this way is difficult to say, we only get to run the experiment once.
Meanwhile, Mike Zusman and Alex Sotirov are claiming to have breached the EV green bar thing used by some higher end websites. No details available yet, it's the normal tease before a BlabHat style presentation by academics. Rumour has it that they've exploited weaknesses in the browsers. Some details emerging:
With control of the DNS for the access point, the attackers can establish their machines as men-in-the-middle, monitoring what victims logged into the access point are up to. They can let victims connect to EV SSL sites - turning the address bars green. Subsequently, they can redirect the connection to a DV SSL sessions under a certificates they have gotten illicitly, but the browser will still show the green bar.
Ah that old chestnut: if you slice your site down the middle and do security on the left and no or lesser security on the right, guess where the attacker comes in? Not the left or the right, but up the middle, between the two. He exploits the gap. Which is why elsewhere, we say "there is only one mode and it is secure."
Aside from that, this is an interesting data point. It might be considered that this is proof that the process is working (following the GP theory), or it might be proof that the process is broken (following the sleeping-dogs-lie model of security).
Although EV represents a good documentation of what the USA/Canada region (not Europe) would subscribe as "best practices," it fails in some disappointing ways. And in some ways it has made matters worse. Here's one: because the closed proprietary group CA/B Forum didn't really agree to fix the real problems, those real problems are still there. As Extended Validation has held itself up as a sort of gold standard, this means that attackers now have something fun to focus on. We all knew that SSL was sort of facade-ware in the real security game, and didn't bother to mention it. But now that the bigger CAs have bought into the marketing campaign, they'll get a steady stream of attention from academics and press.
I would guess less so from real attackers, because there are easier pickings elsewhere, but maybe I'm wrong:
"From May to June 2009 the total number of fraudulent website URLs using VeriSign SSL certificates represented 26% of all SSL certificate attacks, while the previous six months presented only a single occurrence," Raza wrote on the Symantec Security blogs.... MarkMonitor found more than 7,300 domains exploited four top U.S. and international bank brands with 16% of them registered since September 2008.
.... But in the latest spate of phishing attempts, the SSL certificates were legitimate because "they matched the URL of the fake pages that were mimicking the target brands," Raza wrote.VeriSign Inc., which sells SSL certificates, points out that SSL certificate fraud currently represents a tiny percentage of overall phishing attacks. Only two domains, and two VeriSign certificates were compromised in the attacks identified by Symantec, which targeted seven different brands.
"This activity falls well within the normal variability you would see on a very infrequent occurrence," said Tim Callan, a product marketing executive for VeriSign's SSL business unit. "If these were the results of a coin flip, with heads yielding 1 and tails yielding 0, we wouldn't be surprised to see this sequence at all, and certainly wouldn't conclude that there's any upward trend towards heads coming up on the coin."
Well, we hope that nobody's head is flipped in an unsurprising fashion....
It remains to be seen whether this makes any difference. I must admit, I check the green bar on my browser when online-banking, but annoyingly it makes me click to see who signed it. For real users, Firefox says that it is the website, and this is wrong and annoying, but Mozilla has not shown itself adept at understanding the legal and business side of security. I've heard Safari has been fixed up so probably time to try that again and report sometime.
Then, over to Germany, where a snafu with a HSM ("high security module") caused a root key to be lost (also in German). Over in the crypto lists, there are PKI opponents pointing out how this means it doesn't work, and there are PKI proponents pointing out how they should have employed better consultants. Both sides are right of course, so what to conclude?
Test runs with Germany's first-generation electronic health cards and doctors' "health professional cards" have suffered a serious setback. After the failure of a hardware security module (HSM) holding the private keys for the root Certificate Authority (root CA) for the first-generation cards, it emerged that the data had not been backed up. Consequently, if additional new cards are required for field testing, all of the cards previously produced for the tests will have to be replaced, because a new root CA will have to be generated. ... Besides its use in authentication, the root CA is also important for card withdrawal (the revocation service).
The first thing to realise was that this was a test rollout and not the real thing. So the test discovered a major weakness; in that sense it is successful, albeit highly embarrassing because it reached the press.
The second thing is the HSM issue. As we know, PKI is constructed as a hierarchy, or a tree. At the root of the tree is the root key of course. If this breaks, everything else collapses.
Hence there is a terrible fear of the root breaking. This feeds into the wishes of suppliers of high security modules, who make hardware that protect the root from being stolen. But, in this case, the HSM broke, and there was no backup. So a protection for one fear -- theft -- resulted in a vulnerability to another fear -- data loss.
A moment's thought and we realise that the HSM has to have a backup. Which has to be at least as good as the HSM. Which means we then have some rather cute conundrums, based on the Alice in Wonderland concept of having one single root except we need multiple single roots... In practice, how do we create the root inside the HSM (for security protection) and get it to another HSM (for recovery protection)?
Serious engineers and architects will be reaching for one word: BRITTLE! And so it is. Yes, it is possible to do this, but only by breaking the hierarchical principle of PKI itself. It is hard to break fundamental principles, and the result is that PKI will always be brittle, the implementations will always have contradictions that are swept under the carpet by the managers, auditors and salesmen. The PKI design is simply not real world engineering, and the only thing that keeps it going is the institutional deadly embrace of governments, standards committees, developers and security companies.
Not the market demand. But, not all has been bad in the PKI world. Actually, since the bottoming out of the dotcom collapse, certs have been on the uptake, and market demand is present albeit not anything beyond compliance-driven. Here comes a minor item of success:
VeriSign, Inc. [SNIP] today reported it has topped the 1 billion mark for daily Online Certificate Status Protocol (OCSP) checks.[SNIP] A key link in the online security chain, OCSP offers the most timely and efficient way for Web browsers to determine whether a Secure Sockets Layer (SSL) or user certificate is still valid or has been revoked. Generally, when a browser initiates an SSL session, OCSP servers receive a query to check to see if the certificate in use is valid. Likewise, when a user initiates actions such as smartcard logon, VPN access or Web authentication, OCSP servers check the validity of the user certificate that is presented. OSCP servers are operated by Certificate Authorities, and VeriSign is the world's leading Certificate Authority.
[SNIP] VeriSign is the EV SSL Certificate provider of choice for more than 10,000 Internet domain names, representing 74 percent of the entire EV SSL Certificate market worldwide.
(In the above, I've snipped the self-serving marketing and one blatant misrepresentation.)
Certificates are static statements. They can be revoked, but the old design of downloading complete lists of all revocations was not really workable (some CAs ship megabyte-sized lists). We now have a new thing whereby if you are in possession of a certificate, you can do an online check of its status, called OCSP.
The fundamental problem with this, and the reason why it took the industry so long to get around to making revocation a real-time thing, is that once you have that architecture in place, you no longer need certificates. If you know the website, you simply go to a trusted provider and get the public key. The problem with this approach is that it doesn't allow the CA business to sell certificates to web site owners. As it lacks any business model for CAs, the CAs will fight it tooth & nail.
Just another conundrum from the office of security Kafkaism.
Here's another one, this time from the world of code signing. The idea is that updates and plugins can be sent to you with a digital signature. This means variously that the code is good and won't hurt you, or someone knows who the attacker is, and you can't hurt him. Whatever it means, developers put great store in the apparent ability of the digital signature to protect themselves from something or other.
But it doesn't work with Blackberry users. Allegedly, a Blackberry provider sent a signed code update to all users in United Arab Emirates:
Yesterday it was reported by various media outlets that a recent BlackBerry software update from Etisalat (a UAE-based carrier) contained spyware that would intercept emails and text messages and send copies to a central Etisalat server. We decided to take a look to find out more....
Whenever a message is received on the device, the Recv class first inspects it to determine if it contains an embedded command more on this later. If not, it UTF-8 encodes the message, GZIPs it, AES encrypts it using a static key (EtisalatIsAProviderForBlackBerry), and Base64 encodes the result. It then adds this bundle to a transmit queue. The main app polls this queue every five seconds using a Timer, and when there are items in the queue to transmit, it calls this function to forward the message to a hardcoded server via HTTP (see below). The call to http.sendData() simply constructs the POST request and sends it over the wire with the proper headers.
Oops! A signed spyware from the provider that copies all your private email and sends it to a server. Sounds simple, but there's a gotcha...
The most alarming part about this whole situation is that people only noticed the malware because it was draining their batteries. The server receiving the initial registration packets (i.e. Here I am, software is installed!) got overloaded. Devices kept trying to connect every five seconds to empty the outbound message queue, thereby causing a battery drain. Some people were reporting on official BlackBerry forums that their batteries were being depleted from full charge in as little as half an hour.
So, even though the spyware provider had a way to turn it on and off:
It doesnt seem to execute arbitrary commands, just packages up device information such as IMEI, IMSI, phone number, etc. and sends it back to the central server, the same way it does for received messages. It also provides a way to remotely enable/disable the spyware itself using the commands start and stop.
There was something wrong with the design, and everyone's blackberry went mad. Two points: if you want to spy on your own customers, be careful, and test it. Get quality engineers on to that part, because you are perverting a brittle design, and that is tricky stuff.
Second point. If you want to control a large portion of the population who has these devices, the centralised hierarchy of PKI and its one root to bind them all principle would seem to be perfectly designed. Nobody can control it except the center, which puts you in charge. In this case, the center can use its powerful code-signing abilities to deliver whatever you trust to it. (You trust what it tells you to trust, of course.)
Which has led some wits to label the CAs as centralised vulnerability partners. Which is odd, because some organisations that should know better than to outsource the keys to their security continue to do so.
But who cares, as long as the work flows for the consultants, the committees, the HSM providers and the CAs?
May 25, 2009
The Inverted Pyramid of Identity
Let's talk about why we want Identity. There appear to be two popular reasons why Identity is useful. One is as a handle for the customer experience, so that our dear user can return day after day and maintain her context.
The other is as a vector of punishment. If something goes wrong, we can punish our user, no longer dear.
It's a sad indictment of security, but it does seem as if the state of the security nation is that we cannot design, build and roll-out secure and safe systems. Abuse is likely, even certain, sometimes relished: it is almost a business requirement for a system of value to prove itself by having the value stolen. Following the inevitable security disaster, the business strategy switches smoothly to seeking who to blame, dumping the liability and covering up the dirt.
Users have a very different perspective. Users are well aware of the upsides and downsides, they know well: Identity is for good and for bad.
Indeed, one of the persistent fears of users is that an identity system will be used to hurt them. Steal their soul, breach their privacy, hold them to unreasonable terms, ultimately hunt them down and hurt them, these are some of the thoughts that invasive systems bring to the mind of our dear user.
This is the bad side of identity: the individual and the system are "in dispute," it's man against the machine, Jane against Justice. Unlike the usage case of "identity-as-a-handle," which seems to be relatively well developed in theory and documentation, the "identity-as-punishment" metaphor seems woefully inadequate. It is little talked about, it is the domain of lawyers and investigators, police and journalists. It's not the domain of technologists. Outside the odd and forgettable area of law, disputes are a non-subject, and not covered at all where I believe it is required the most: marketing, design, systems building, customer relations, costs analysis.
Indeed, disputes are taboo for any business.
Yet, this is unsustainable. I like to think of good Internet (or similar) systems as an inverted pyramid. On the top, the mesa, is the place where users build their value. It needs to be flat and stable. Efficient, and able to expand horizontally without costs. Hopefully it won't shift around a lot.
 Dig slightly down, and we find the dirty business of user support. Here, the business faces the death of a 1000 tiny support cuts. Each trivial, cheap and ignorable, except in the aggregate. Below them deeper down are the 100 interesting support issues. Deeper still, the 10 or so really serious red alerts. Of which one becomes a real dispute.
Dig slightly down, and we find the dirty business of user support. Here, the business faces the death of a 1000 tiny support cuts. Each trivial, cheap and ignorable, except in the aggregate. Below them deeper down are the 100 interesting support issues. Deeper still, the 10 or so really serious red alerts. Of which one becomes a real dispute.
The robustness of the pyramid is based on the relationship between the dispute at the bottom, the support activity in the middle, and the top, as it expands horizontally for business and for profit.
Your growth potential is teetering on this one thing: the dispute at the apex of the pyramid. And, if you are interested in privacy, this is the front line, for a perverse reason: this is where it is most lost. Support and full-blown disputes are the front line of privacy and security. Events in this area are destroyers of trust, they are the bane of marketing, the nightmare of PR.
Which brings up some interesting questions. If support is such a destroyer of trust, why is it an afterthought in so many systems? If the dispute is such a business disaster, why is resolution not covered at all? Or hidden, taboo? Or, why do businesses think that their dispute resolution process starts with their customers' identity handles? And ends with the lawyers?
Here's a thought: If badly-handled support and dispute events are leaks of privacy, destroyers of trust, maybe well-handled events are builders of trust? Preservers of privacy?
If that is plausible, if it is possible that good support and good dispute handling build good trust ... maybe a business objective is to shift the process: support designed up front, disputes surfaced, all of it open? A mature and trusted provider might say: we love our disputes, we promote them. Come one, come all. That's how we show we care!
An imature and unstrusted provider will say: we have no disputes, we don't need them. We ask you the user to believe in our promise.
The principle that the business hums along on top of an inverted pyramid, that rests ultimately on a small powerful but brittle apex, is likely to cause some scratching of technophiliac heads. So let me close the circle, and bring it back to the Identity topic.
If you do this, if you design the dispute mechanism as a fully cross-discipline business process for the benefit of all, not only will trust go positive and privacy become aligned, you will get an extra bonus. A carefully constructed dispute resolution method frees up the identity system, as the latter no longer has to do double duty as the user handle *and* the facade of punishment. Your identity system can simply concentrate on the user's experience. The dark clouds of fear disappear, and the technology has a chance to work how the techies said it would.
We can pretty much de-link the entire identity-as-handles from the identity-as-punishment concept. Doing that removes the fear from the user's mind, because she can now analyse the dispute mechanism on its merits. It also means that the Identity system can be written only for its technical and usability merits, something that we always wanted to do but never could, quite.
(This is the rough transcript of a talk I gave at Identity & Privacy conference in London a couple of weeks ago. The concept was first introduced at LexCybernetoria, it was initially tried by WebMoney, partly explored in digital gold currencies, and finally was built in
CAcert's Arbitration project.)
March 21, 2009
Conficker chooses Rivest!
Dani writes: Here is an in-depth analysis of one of the (if not THE) most advanced malware currently in circulation. Please note the wide selection of defensive and offensive measures, including extensive use of strong cryptography.
we summarize the inner workings and practical implications of this latest malicious software application produced by the Conficker developers. In addition to the dual layers of packing and encryption used to protect A and B from reverse engineering, this latest variant also cloaks its newest code segments, along with its latest functionality, under a significant layer of code obfuscation to further hinder binary analysis.
Its choice of crypto suite is RSA4096, RC4, MD6 (all designed by Ron Rivest, as the authors note). A fascinating read for all interested in information security.
February 17, 2009
on H5: how to inject security into the SQL database
 In comments to yesterday's H5, "AC2" asked:
In comments to yesterday's H5, "AC2" asked:
Confused by the applicability of this particular hypothesis (and in general all of them)...Are you primarily concerned with over the wire comms, especially outside the 'boundaries' (whatever they are) of an organisation's network?
If not, then would App to DB communication fall in its remit? H5 is pretty much broken in this space afaik, as such communication IS dependent on underlying infrastructure/ protocols to a great extent.. Unless you suggest that the app encrypt everything apart from the SELECT WHERE FROM etc in the SQL...
Posted by: AC2 at February 16, 2009 03:05 AM
Good question, and here comes a sweeping, hand waving answer.
Security is all-encompassing, top-to-bottom, left-to-right, from the requirements all out. This hypothesis says that the requirement to secure covers the entire space.
"App to DB" comms and SQL fall within that. So the answer is, yes, H5 decidedly covers everything, including SELECT WHERE FROM etc in SQL. That is, there is no point in securing the rest of it if your database is an open love letter to the attacker.
How do we apply this in practice? Here are two answers. The first answer could be called "don't do that!" I personally have not followed the literature on this, because I looked at SQL databases a long time ago (I used to port them into Unix systems, and repair broken ones for desperate clients) and decided they can't be economically made secure. So I don't ever use them. Period. I use things I can secure, which means, I write my own databases. Sometimes, these are known as "flat files" in the industry; I once saw an estimate that something like 30% of databases are of this form.
The second answer could be called "kick-back." Once we decide that the need is for end-to-end security, this changes a lot of things. One of the things is that we assume that the data can become public, or should be able to be public, without any loss. For example, in my digital cash work, if all the server-side transaction databases were viewable by an attacker, it wouldn't mean that he could steal money (although there is an obvious privacy angle here). For second example, refer to any Lynn.std.rant on x9.59 and you will find the same deal, in that because of the analysis revealing miles and miles of processes and steps, it was reasoned that there was no way to keep the stuff unviewable, so the only response was to neutralise the data. C.f., "naked and vulnerable transactions" cannot be protected with encryption.
So to come back to AC2's comment, yes, something is pretty much broken in this space. Whether one thinks it is H5, or whether one thinks it is the original decision to use an unsecurable and unreliable tool is rather a political choice for you. If your job is SQL programming, and you want to keep your job, I know which way you're going to call it, and nobody can fault you for that :) OTOH, if you did set the requirements for security, ... well, how serious was that requirement?
PS: in all the above, where I use the word "secure" I really mean the superset of "reliable", including in this case, security.
February 15, 2009
H5: Security Begins at the Application and Ends at the Mind
So much of what we do today is re-inventing what others have already done, but has been lost in the noise. Today, Ian Brown said:
EIFFEL is a group of leading networking researchers funded by the European Commission to "provide a place for discussing and exchanging ideas and research trajectories on the future of the Internet architecture and governance building as a foundation of the future networked society." I'm proud they have asked me to speak on Tuesday at their second meeting, alongside such luminaries as MIT's Dr David "end-to-end principle" Clark. You can see my presentation below any comments (before or after Tuesday morning) most welcome!
What caught my eye, other than the grandiose goal, was the mention of an end-to-end principle. Lo and behold, Ian linked to this over on wikipedia:
The principle states that, whenever possible, communications protocol operations should be defined to occur at the end-points of a communications system, or as close as possible to the resource being controlled.According to the end-to-end principle, protocol features are only justified in the lower layers of a system if they are a performance optimization, hence, Transmission Control Protocol (TCP) retransmission for reliability is still justified, but efforts to improve TCP reliability should stop after peak performance has been reached.
Aha! Well, that makes sense. This is very close to what I say in this unpublished hypothesis, here:
Hypothesis #5 -- Security Begins at the Application and Ends at the Mind The application must do most of the work [1]. For really secure systems, only application security is worthwhile. That is simply because most applications are delivered into environments where they have little control or say over how the underlying system is set up.
#5.1 Security below the application layer is unreliable For security needs, there is little point in for example relying on (specifying) IPSec or the authentication capabilities or PKI or trusted rings or such devices. These things are fine under laboratory conditions, but you have no control once it leaves your door. Out there in the real world, and even within your own development process, there is just too much scope for people to forget or re-implement parts that will break your model.
If you need it, you have to do it yourself. This applies as much to retries and replay protection as to authentication and encryption; in a full secure system you will find yourself dealing with all these issues at the high layer eventually, anyway, so build them in from the start.
Try these quick quizzes. It helps if you close your eyes and think of the question at the deeper levels.
- Is your firewall switched on? How do you know? Or, how do you know when it is not switched on?
- Likewise, is your VPN switched on? How do you know?
- Does TLS provide replay protection [2]?
These questions lead to some deeper principles.
Super hint! Now out there and published ... leaving only one more to go.
As an aside, the set of 7 hypotheses covering secure design is around 60% published. As time goes on, I find new info that I try and integrate in, which slows down the process. Some of them are a little rough (or, a mess) and some of them fight for the right to incorporate a key point. One day, one day...
December 07, 2008
Security is a subset of Reliability
From the "articles I wish I'd written" department, Chandler points to an article by Daniels Geer & Conway on all the ways security is really a subset of reliability. Of course!

I think this is why the best engineers who've done great security things start from the top; from the customer, the product, the market. They know that in order to secure something, they had better know what the something is before even attempting to add a cryptosec layer over it.
Which is to say, security cannot be a separate discipline. It can be a separate theory, a bit like statics is a theory from civil engineering, or triage is a part of medicine. You might study it in University, but you don't get a job in it; every practitioner needs some basic security. If you are a specialist in security, your job is more or less to teach it to practitioners. The alternate is to ask the practitioners to teach you about the product, which doesn't seem sensible.
September 20, 2008
Builders v. Breakers
Gunnar lauds a post on why there are few architects in the security world:
Superb post by Mark on what I think is the biggest problem we have in security. One thing you learn in consulting is that no matter what anyone tells you when you start a project about what problem you are trying to solve, it is always a people problem. The single biggest problem in security is too many breakers not enough builders. Please understand I am not saying that breakers are not useful, we need them, and we need them to continue to get better so we can build more resilient systems. But the industry is about 90% breaking and 10% building and that's plain bad.
Its still predominantly made up of an army of skilled hackers focused on better ways to break systems apart and find new ways to exploit vulnerabilities than security architects who are designing secure components, protocols and ultimately secure systems.
Hear hear! And why is this? One easy answer: breaking something is a solid metric. It's either broken or not, in general. Any journo can understand it.
On the other hand, building it is too difficult a signal. There is no easy number, there is no binary result. It takes a business focus over decades to understand that one architecture delivers more profits for users and corporates alike than another, and by then, the architects have moved on, so even, then the result may not be clear.
Let's take an old example. Back around 1996, a couple of bored uni students cracked Netscape's secure browsing. The first time was by crunching the 40 bit crypto using the idle lab computers, and the second time was by predicting the less-than-random numbers injected into the protocol. These students were lauded in the press for having done something grand.
They then went on to a much harder task, and were almost never heard of again. What was that harder task? Building secure and usable systems. One of them tried to build a secure communications platform, another is trying to build a secure computing platform. So far, they have not succeeded at either task, but these are much harder tasks.
The true heroes back in the mid-1990s were the Netscape engineers who got something going and delivered it to the public, not the kids who scratched the paint off it. The breaches mentioned above were jokes, and bad ones at that, because they distracted attention on what was really being built. Case in point, is that, even today, if we had twice as much 40 bit crypto as we do 128 bit crypto, we'd probably be twice as secure, because the attack of relevance simply isn't the bored uni student, it is the patient phisher.
If you recall names in this story, recall them for what they tried to build, and not for what they broke.
July 11, 2008
wheretofore Vista? Microsoft moves to deal with the end of the Windows franchise
Since the famous Bill Gates Memo, around the same time as phishing and related frauds went institutional, Microsoft has switched around to deal with the devil within: security. In so doing, it has done what others should have done, and done it well. However, there was always going to be a problem with turning the super-tanker called Windows into a battleship.
I predicted a while back that (a) Vista would probably fail to make a difference, and (b) the next step was to start thinking of a new operating system. This wasn't the normal pique, but the cold-hearted analysis of the size of the task. If you work for 20 years making your OS easy but insecure, you don't have much chance of fixing that, even with the resources of Microsoft.
The Economist brings an update on both points. Firstly, on Vista's record after 18 months in the market:
To date, some 140m copies of Vista have been shipped compared with the 750m or more copies of XP in daily use. But the bulk of the Vista sales have been OEM copies that came pre-installed on computers when they were bought. Anyone wanting a PC without Vista had to order it specially.Meanwhile, few corporate customers have bought upgrade licences they would need to convert their existing PCs to Vista. Overwhelmingly, Windows users have stuck with XP.
Even Microsoft now seems to accept that Vista is never going to be a blockbuster like XP, and is hurrying out a slimmed-down tweak of Vista known internally as Windows 7. This Vista lite is now expected late next year instead of 2010 or 2011.
It's not as though Vista is a dud. Compared with XP, its kernelthe core component that handles all the communication between the memory, processor and input and output devicesis far better protected from malware and misuse. And, in principle, Vista has better tools for networking. All told, its design is a definite improvementalbeit an incremental oneover XP.
Microsoft tried and failed to turn it around, security+market-wise. We might now be looking at the end of the franchise known as Windows. To be clear, while we are past the peak, any ending is a long way off in the distant future.
Classical strategy thinking says that there are two possible paths here: invest in a new franchise, or go "cash-cow". The latter means that you squeeze the revenues from the old franchise as long as possible, and delay the termination of the franchise as long as possible. The longer you delay the end, the more revenues you get. The reason for doing this is simple: there is no investment strategy that makes money, so you should return the money to the shareholders. There is a simple example here: the music majors are decidedly in cash-cow, today, because they have no better strategy than delaying their death by a thousand file-shares.
Certainly, with Bill Gates easing out, it would be possible to go cash-cow, but of course, we on the outside can only cast our augeries and wonder at the signs. The Economist suggests that they may have taken the investment route:
Judging from recent rumours, that's what it is preparing to do. Even though it won't be in Windows 7, Microsoft is happy to talk about MinWina slimmed down version of the Windows core. Its even willing to discus its Singularity projecta microkernel-based operating system written strictly for research purposes. But ask about a project code-named Midori and everyone clams up.By all accounts, Midori (Japanese for green and, by inference, go) capitalises on research done for Singularity. The interesting thing about this hush-hush operating system is that its not a research project in the normal sense. It's been moved out of the lab and into incubation, and is being managed by some of the most experienced software gurus in the company.
With only 18 months before Vista is to be replaced, there's no way Midoriwhich promises nothing less than a total rethink of the whole Windows metaphorcould be ready in time to take its place. But four or five years down the road, Microsoft might just confound its critics and pleasantly surprise the rest of us.
Comment? Even though I predicted Microsoft would go for a new OS, I think this is a tall order. There are two installed bases in the world today, being Unix and Windows. It's been that way for a long time, and efforts to change those two bases have generally failed. Even Apple gave up and went Unix. (The same economics works against the repeated attempts to upgrade the CPU instruction set.)
The flip-side of this is that the two bases are incredibly old and out-of-date. Unix's security model is "ok" but decidedly pre-PC, much of what it does is simply irrelevant to the modern world. For example, all the user-to-user protection is pointless on a one-user-one-PC environment, and the major protection barrier has accidentally become a hack known as TCP/IP, legendary for its inelegant grafting onto Unix. Windows has its own issues.
So we know two things: a redesign is decades over-due. And it won't budge the incumbents; both are likely to live another decade without appreciable change to the markets. We would need a miracle, or better, a killer-app to budge the installed base.
Hence the cold-hearted analysis of cash-cow wins out.
But wait! The warm-blooded humanists won't let that happen for one and only one reason: it is simply too boring to contemplate. Microsoft has so many honest, caring, devoted techies within that if a decision were made to go cash-cow, there would be a mass-defection. So the question then arises, what sort of a hybrid will be acceptable to shareholders and workers? Taking a leaf from recent politics, which is going through a peak-energy-masquerade of its own these days, some form of "green platform" has appeal to both sides of the voting electorate.
June 22, 2008
H4.2 -- Usability Determines the Number of Users
Last week's discussion (here and here) over how there is only one mode, and it is secure, brought forth the delicious contrast with browsing and security: yes, you can do that but it doesn't work well. No, I'm not talking about the logos being cross-sited, but all of the 100 little flaws that you find when you try and do a website for secure purposes.
So why bother? Financial cryptography eats its own medicine, but it doesn't do it for breakfast, lunch and desert. Which reminds me to introduce another of the sub-hypes for critique:
#4.2 Usability Determines the Number of Users Ease of use is the most important determinant to the number of users. Ease of implementation is important, ease of incorporation is also important, and even more important is the ease of use by end-users. This reflects a natural subdivision into several classes of users: implementors, integrators and end-users, each class of which can halt the use of the protocol if they find it ... unusable. As they are laid out serially between you and the marketplace, you have to consider usability to all of them.
The protocol should be designed to be easy to code up, so as to help implementors help integrators help users. It should be designed to be easy to interface to, so as to help integrators help users. It should be designed to be easy to configure, so as to help users get security.
If there are any complex or tricky features, ask yourself whether the benefit is really worth the cost of coder's time. It is not that developers cannot do it, it is simply that they will not do it; nobody has all the time in the world, and a protocol that is twice as long to implement is twice as likely to not get done.
Same for integrators of systems. If the complexity provided by the protocol and the implementation causes X amount of work, and another protocol costs only X/2 then there is a big temptation to switch. Regardless of absolute or theoretical security.
Same for users.
June 21, 2008
Why is is this blog secure? Because there is only one mode, and it is secure!
Anon asks:
> ian: I never understood why you insist on using HTTPS for the blog... maybe you can shed light ?
Fair question, and often I ask myself whether it is worth the extra effort. As succinctly as I can put it, it is because of the fundamental principle:
This principle is not so well understood in today's Internet security business, so I'll explain. Whenever a system has two modes, there is always weakness as it switches from one mode to another. In security systems, we get security weakness as we switch from unsecured mode to secured mode.
A very basic problem with security is that attackers are intelligent and active and users are distracted and passive. Not exactly dumb, but just paying attention to other things. So attackers will search out weaknesses, and users will not notice weaknesses, and therefore attacks at the weaknesses.
Then, attackers will attack at the switch in mode, and users won't really notice. Easy to say, but how does this work in practice? Consider browsing. You go to the website of your bank by typing the name into the google bar on the top right of google (ok, *you* might not, but you have a friend who will...) and clicking on the top result [1]. Or you could do it any number of other ways. Whichever, you end up at a website. Then you click around looking for the place to type your password and username.
The session started out "insecure", and ended up "secure". Hopefully. Normal users will pay attention at the beginning, but their attention wanes with each click. So in general, they won't notice when they switched into secure model. Which also means they won't notice who they switched too, which in turn leads to an easy attack: around the time the user is not paying attention, switch somewhere else that looks like what they expect.
Hence, phishing, in all its variations.
The fundamental flaw here is that we browse insecurely and then switch to secure mode for something important. We can eliminate a whole class of attacks here by being secure always. Never having to switch. Hence the principle; in that *if* you are doing anything that requires security, you are a million times better off if you *always* do everything secure [2].
Financial Cryptography is using HTTPS to remind people doing serious security work of that principle: you should design your systems to be always secure. Every time you click on the FC website and see that it is in HTTPS, I want you to remember that the application known as secure browsing is fundamentally broken, because it breaches the 3rd hypothesis: There is only one mode, and it is secure [3].
You, and your friend, are at risk because of that. To paraphrase an old saying, you enter a state of sin when you design a system with a security switch in it. It follows that, if we want to do anything that involves security on the web, then, everything should be in HTTPS, not just this blog. All blogs, all wikis, all websites, all the REST, everything.
[1] I was looking for an example, so I googled Bank of America. The first link took me straight to a https site (via a redirect). Outstanding!
Clicking around from the second link on google, I found that it switched me (via North Carolina) across to a login box in HTTPS with this site: https://businessconnect.ebanking-services.com/nubi/signin.aspx . Firefox says (oddly) "This web site does not supply identity information." .... but the certificate says it is Metavante Corporation ... ok, so this is a bad example, even I am totally confused by what is happening here...
[2] What "secure" means and how you do that are other questions that can only be answered with reference to the specific circumstances. E.g., for browsing, secure means that you are talking to the right site, and nobody else.
[3] How we got to this state of affairs, where practically everyone on the planet believes that insecure browsing is normal, should be considered as a research question.
June 14, 2008
Hypothesis #4 -- The First Requirement of Security is Usability
Duane points to a recent debate, something about DNSSEC and its added value, which resulted in this comment by one Thierry Moreau: DNNSEC is almost worthless! The reasons appear to be based on an analysis of three usage models, and each usage model heads for the rocks for one reason or other. Thierry points out that user #1 is not interested, user #2 is small, and user #3 will be not be allowed. The analysis is worth a read, as it is nicely laid out (regardless of whether you agree or not).
What is going wrong with DNSSEC? From the outside, the results are clear: it was never used. In my terms it breaches parts of my 4th hypothesis, which is, in short, "Usability is Number One." To start off with:
#4.1 Zero Users means Zero SecurityThe most common failure mode of any security protocol is not being used by users, at all.
There have been thousands of attempts at secure protocols in recent Internet times. Many did not get completed, many were completed but were rejected as too hard to use, and many great protocols missed the boat and were swamped by bad protocols. These are therefore all failures; their delivered security is zero. Zip, zilch, nada.
Perfect security, multiplied by zero users, always equals Zero security. Try it with any variation of zero you like, and any grade of security. Count up as many security projects as you like, and look at the very strong correlation: Security perfectly reaches zero with all known forms of mathematics, if it is has zero users.
Only a delivered protocol that protects and ships packets for actual, warm, live, talkative users can deliver security. A good protocol with some gaping holes will always outperform a perfect protocol that remains undelivered, in security terms. A good protocol in widespread use will generally outperform a better protocol that is poorly used.
Again simple mathematics tells us why: a protocol that is perfect that protects one person perfectly, is still limited to that one person. The mathematics of security says that is a one. If you can reduce your protocol's theoretical security from 100% to 99%, and get ten users, that then means you can reach 9.9, in delivered security to those ten users. Approximately. If you can reduce to 98%, but gain 100 users then your security reaches 98.
Security is as delivered to users, and is summed across them. Therefore, it goes up almost perfectly with the number of users. By far the biggest determinant of security is then the number of users that you can gain. Consider that first and foremost.
This result certainly applies to DNSSEC, and the hypothesis title of Usability may hint at why. Or not.
June 06, 2008
TLS/httpd finally to be fixed for general purpose website security
Life is slowly improving with that old tired security model called secure browsing. Here's a roundup:
Firefox have their new security UI in place whereby you can click on exceptions to store the certificates as accepted and trust by you (being your most important authority). There is an annoying bug where it loses the cache from time to time, and this causes the user to have to re-do the exceptions. That is being pursued in the bug channels, and will be cracked as soon as someone figures out a way to reproduce it.
Meanwhile, this blog's certificate expired, causing much confusion because it was misdiagnosed as the above. Once I had figured the real cause, the cert was re-issued within an hour or so. Thanks to Philipp for that one! You might also note that the certificate is one of those AltServerName specials, where you can shove in many names into the one certificate. This is a kludge of the highest order, but it is what is required for the small end of the market when IP#s are not handed out like candy.
Which brings us to the ServerNameIndication news . This is the long-awaited fix in TLS that enables Apache webservers to do virtual hosting of the secured sites, something that has been missing since forever. Once we can do virtual hosting of secured sites, this means all the smaller operators using own Linux and BSD machines can move just about anything to TLS. This means people can finally start to employ security on websites as it was meant to be:
There is only one mode, and it's secure.
Unfortunately, the SSL model broke about five minutes after deployment when people separated the websites into non-SSL and SSL. Military people will quickly realise that this is a split-forces pattern, and a disaster that must and did happen. _Do not split your forces!_ is one thing that is hammered into the new recruit until the soldier mumbles it in sleep.
ServerNameIndication or SNI is the most important fix there is in secure browsing today. I argue this in the face of strong candidates, such as security UI improvements, key continuity models (a.k.a. SSH), secure password protocols, EV, CardSpace, etc. The reason this is more important is that it is a structural & market forces change, not a technical change, and market forces trumps tech every time.
<obligatory><rant>
Take EV for example, as the most popular answer to phishing. It adds around 1000 new certs to the market. The top end. And it changes little for those big companies, other than a new paint job. Green is in, this season, it seems. The industry is divided as to whether it adds nothing, or just a little. Even the EV people agree that it is not intended to solve phishing... Either way, most agree it isn't worth the bother (to resist or to implement), and it consumed significant resources which were therefore wasted.In comparison, TLS/SNI will unleash one million Linux boxes that can now start serving 10 million websites in TLS. This is no paint job, SNI is a revolution in blood; most of those new certs will trigger IE's new warning colour as well. Currently, the Linux multitudes cannot serve security, more or less, because they have only one IP# each. It's just not worth the bother for one site, see the split-forces issue. With SNI, it removes a massive barrier: the IP# limitation, and we no longer have to compromise our security between the two models.
I predict we'll add a million new TLS websites over the few years after Apache SNI is released.
Which will then have a massive, truly massive knock-on effect on all developers of all software applications: Suddenly, developers will find their insecure applications being put into security areas, because TLS secures, right? Suddenly, ordinary developers will have to start thinking about security. Because if users mount secure websites, that means they need security, right? Suddenly, developers will discover an itch to get more familiar with security programming, practices and tricks. And this will all flow into their applications and across to users.
The humble cert will be reborn. Can this massive claim be true? The good part is that even if only a small part of it is true, it's a win for everyone except phishers...
</rant></obligatory>
So, story aside, where are we at? The Apache HTTPD team are now debating the patch to put it into the next release version of 2.2.9. Here's a snippet from joe from redhat:
Changing the dirconf structure fields in-place seems ugly and may even be thread-unsafe (not sure). I still can't see how this handles half the cases it needs to, as I've said several times now - SSLVerifyClient is only one part of this. From a quick look I can't see how a reneg would be forced for any of:1) SSLCipherSuite changed since original vhost
2) SSLCACeritificate* changed since original vhost (where both
3) SSLOCSP* changed since original vhostbut it certainly should be. A lot of the mod_ssl code will need to be very carefully reviewed since some core assumptions are being broken by supporting SNI. I would go through each of the config directive which supports vhost context in turn. What about SSLCertificateChainFile? What about CRLs? etc etc.
It is also a complete cop-out to claim these issues aren't specific to SNI since we explicitly don't support any non-SNI configuration in which these paths can be triggered. And for very good reason: *they don't work properly*.
joe
Which is to say, OK, we're looking at it, but SNI is such a dramatic change to the codebase that it needs to be carefully reviewed. If you know the codebase, you could do the world a huge favour by piling in and helping the review.
My opinion? Like any manager, I've seen the demo, so ship it now :) Indeed, I encourage you to call your supplier and ask why it didn't ship 10 years ago. In fact, if your website was unencrypted and unsecured because your sysadm grumbled about TLS support, call your supplier and ask why he shouldn't be sued for a decade of breaches, angst and confusion?
More practically, SNI could be released now with a caveat that says "not for security production use yet!" Compromise on security before delivery. A caveat can be in the config files, and the use of the fix to TLS will require special configuration anyway.
This is the shear economics theory of security: we need to get it into production use with a non-production status, because we need that 1 million insecure secure singularity, as above. Do the maths: a million times 99.99% secure is way more than our current numbers.
And, if a few Linux boxen have a few security losers amongst them, they take some for the team. That's what Linux is there for, right? To carve the territory for the rest of us, and take some arrows in the back. Others agree. Some Linux distros already ship with the fix to TLS:
Oden wrote: > FYI. SNI is in Mandriva Linux 2008.1.Then you should pull it out ASAP, as noted by others the patch currently in trunk is broken in several ways, with possible security configuration implications...
Apache of course will leap forth and blame the Mandriva guys for breaching the cosy protocol. Tut, tut, look what happened to Debian! But in this case they are wrong. Security on this scale is far too important to be held back by concern over security bugs. If there is one thing we learnt in the 1990s, it is that perfect security is more of an enemy than any attacker.
June 01, 2008
Case Study 2: OpenSSL's patched-out randomness
In the aftermath of the OpenSSL failure due to a vendor patch (which bit the vendor badly...) there has been more analysis. Clearly, early attempts to describe this were flawed, and mine was no exception, as the precise failure was not well described.
I did miss out on one important thing, pointed out by Philipp Güring: when doing high-sec apps, it is necessary to mix in different sources, because we should assume that the lower layers will fail. But, while necessary, it is not sufficient. We still require to show that our mixed randoms are getting into the right place. Then, we need some form of testing strategy that shows this. I suggest:
- all sources be set to some fixed X like zero, and then run many times, to show that the result is the same each time,
- each source be singly varied, and then show that the result varies each time,
- test each result for randomness,
- read the code. (So, use simple code for this area.)
In addition to other's comments, I found this extremely useful, from David Brodbeck, posted in comments on EC:
In aviation it's common to talk about an "accident chain," the series of small mistakes that lead up to an incident. Breaking any one link in the chain would have stopped the accident from happening. That's kind of what happened here.
I suggest we incorporate the accident chain into the security lingo. We can guess that each mistake by itself was probably innocuous, otherwise we would have fixed it. Instead of the current 'best practices' of fingerpointing, it is then much better to document the chain of mistakes that led to the accident. And think about how you are going to deal with them. Ideally, be able to show that anyone component could fail completely, and disaster would not then follow.
Finally, as I mentioned, it's better to own the problem than to avoid it. I was heartened then to see that Eric Young wrote:
I just re-checked, this code was from SSLeay, so it pre-dates OpenSSL taking over from me (about 10 years ago, after I was assimilated by RSA Security).So in some ways I'm the one at fault for not being clear enough about why 'purify complains' and why it was not relevant. Purify also incorrectly companied about a construct used in the digest gathering code which functioned correctly, but purify was also correct (a byte in a read word was uninitialised, but it was later overwritten by a shifted byte).
One of the more insidious things about Purify is that once its complaints are investigated, and deemed irrelevant (but left in the library), anyone who subsequently runs purify on an application linking in the library will get the same purify warning. This leads to rather distressed application developers. Especially if their company has a policy of 'no purify warnings'.
One needs to really ship the 'warning ignore' file for purify (does valgrind have one?).
I personally do wonder why, if the original author had purify related comments, which means he was aware of the issues, but had still left the code in place, the reviewer would not consider that the code did some-thing important enough to ignore purify's complaints.
So what we saw was a timebomb that had been ticking for around 10 years. As Ben Laurie mentioned, an awful lot has changed in our knowledge and available tools since then, and as mentioned above, the original code author has long since left the scene. Definately a case for avionics accident investigation. I wonder if they write books on that sort of stuff?
May 26, 2008
Firefox 3 and the new "make a security exception" (+ 1 bug)
Firefox 3 has reworked the ability to manage your certificates. After some thought back at Mozo central, they've introduced a more clarified method for dealing with those sites that you know are good. E.g., for the people who are new to this; there are those sites that you know are good, and there are those sites where others tell you they are good. People have spent decades over deciding which of these spaces owns the term "trust" so I won't bore you with that sad and sorry tale today.
Meanwhile, I've worked my way through the process and added the FC blog as an Exception. The process is OK: The language is better than before, as it now says that the site is not trusted. Before it said "*you* don't trust this site!" which was so blatantly wrong as to be rude to me and confusing to everyone else. Now it just fudges the issue by saying the site is untrusted, but not indicating by whom. Most people will realise this is a meaningless statement, as trust comes from a person, it isn't something that you can get from an advert.
There are multiple clicks, possibly intended to indicate that you should really know what you are doing. I don't think that is so much going to help. What would help better is a colour. So far, it is white, indicating that ... well, nothing. So there is a confusion between sites you trust and those that have nothing, they are both cast into the nothing bucket.
However, this all in time. There is no doubt that KCM or Key Continuity Management is the way to go because users need to work with their sites, and when their communities install and use certs, that's it. KCM is needed to let the rest of the world outside Main Street, USA use the thing called SSL and secure browsing. So it will come in time, as the people at Firefox work out how to share the code with the two models.
One thing however: I did this around a week ago, carefully following the exception process. Now, just a moment before I started this post, Firefox suddenly lost its memory! As I was saving another blog post it decided to blow away the https site. Suddenly, we were back to the untrusted regime, and I had to do do the whole "I trust, I know I trust, I trust I know, I know I trust more than any blah blah trust blah!" thing, all over again. And then there was no post left ... luckily it was a minor change and the original was saved.
This could be an MITM. Oh, that I would be so important... oh, that someone would want to sneak into my editorial control over the influential Financial Cryptography blog and change the world-view of the thousands of faithful readers... well, fantasies aside, this isn't likely to be an MITM.
It could be a sysadm change, but the cert looks the same, although there is little info there to check (OK, this is the fault of the servers, because the only way to tell is to go to the server, and ... it doesn't give you any info worth talking about. SSH servers have the same problem.) And the sysadm would have told me.
So Occam's razor suggests this is a bug in Firefox. Well, we'll see. I cannot complain too loudly about that, as this is RC1. Release Candidates might have bugs. This is a big change to the way Firefox works, bugs are expected. One just bit me. As someone once said, the pioneers are the ones with the arrows in the back.
Information Security enters deadly embrace with Social Networking
It is often remarked that Information Security specialists are so good at their work that they lock out all threats, including the users. Meanwhile the rest of the world has moved on and done things like insecure browsing, insecure email, google datawarehousing of every of your clicks, and Facebook. These ideas are worth billions in the right hands!
What happens when Information Security people wake up and smell the future?
I recently was invited to join a social network of Information Security people and got a chance to find out. I entered some few brief details in their browser interface. Let's be clear here, just because I was invited to a social network doesn't mean I am going to expose myself to phishing, mindlessly misdirected employment advertising, and other failures of the information age. So I entered some brief words such as the stuff that you already know from reading the blog.
Unfortunately this wasn't open enough for the newly-socialised IS people:
Could you please provide a more complete biography and photo? We have been trying hard to encourage the social part of the network and that is difficult when people are reluctant to provide information. I'm sure you will appreciate there needs to be a certain amount of disclosure in order to encourage mutual trust.
Just to be clear, *I totally agree with that sentiment!* I've worked all my life in the old meatspace equivalent of social networks - teams - and building trust is something that is done with disclosure. (In an appropriate setting.) So let's just sweep away all the Internet heebie jeebies of Identity theft, win-win negotiation, rule of threes, and so forth, and let me in.
I wanna disclose, guys, I wanna do it like I saw on those Hollywood movies where we all tell our story to a circle of tearful audience! Problem is, I can't:
From: Some nice guy <mail@infosecuk.ning.com>
Reply-To: do-not-reply@infosecuk.ning.com
To: Iang <iang@i.o>
Subject: Some nice guy has sent you a message on Information Security...[big snip]
Once you have provided this information we will be pleased to grant you access and look forward to you taking an active part in contributing to, and promoting, the network.To reply to this message, click here: http://infosecuk.ning.com/profile/Some_nice_guy/?xgp=messages
--
To control which e-mails you receive on Information Security, go to:
http://infosecuk.ning.com/profiles/profile/emailSettings
I can't reply to the message, or more precisely, all replies to public email addresses are binned. Because of Information Security, as we know -- spamming, etc. OK, so I click on all the links, and it says:
Your Profile is Pending ApprovalHello, Iang (Sign Out)
Your profile details must be approved by the Administrator before you can become a member of Information Security. You will receive an e-mail once your profile is approved.
Clunk. This happened a few weeks ago and I'm now stuck with receiving a stream of well-meaning messages asking me to communicate with them, but they aren't listening. It's like being married; information security has now entered into a deadly embrace with social networking, and the result is enough to make one shave ones head and become a monk.
May 13, 2008
Monetary Ontology
Hasan reports that he has been working on an ontology for currency systems, mainly oriented at builders of local monies. Download is here, in Protege form which probably means you need to use that package to build with it.
Monetary_ontology_0.1d.zip: A zipped Protégé project of an ontology for currency creation and use. Also contains an "owl". The objective is an active description of all forms of "money" from barter to clearing systems, from precious metal coinage to debt-based fiat. It is oriented towards designers of payment systems and community currency systems. Here is a preview GIF image ! First begun 2008/05/04 and last updated 2008/05/12. v0.0 Contributed by Martin "Hasan" Bramwell
Click to load the full image.
May 07, 2008
H2.2 KISS -- Keep the Interface Stupidly Simple
Here's another in my little list of hypothesies, this one from the set known as "Divide and Conquer." The delay in publishing them is partly the cost of preparing the HTML and partly that some of them really need a good editorial whipping. Today's is sparked by this comment made by Dan, at least as attributed by Jon:
... you can make a secure system either by making it so simple you know it's secure, or so complex that no one can find an exploit.
allegedly Dan Geer, as reported by Jon Callas.
#2.2 KISS
In the military, KISS stands for keep it simple, stupid because soldiers are dumb by design (it is very hard to be smart when being shot at). Crypto often borrows from the military, but we always need to change a bit. In this case, KISS stands for
Keep the Interface Stupidly Simple.
When you divide your protocol into parts, KISS tells you that even a programmer should find every part easy to understand. This is more than fortiutous, it is intentional, because the body programmer is your target audience. Remember that your hackers have to also understand all the other elements of good programming and systems building, so their attention span will be limited to around 1% of their knowledge space.
A good example of this is a block cipher. A smart programmer can take a paper definition of a secret-key cipher or a hash algorithm and code it up in a weekend, and know he has got it right.
Why is this? Three reasons:
- The interface is simple enough. There's a secret key, there's a block of input, and there's a block of output. Each is generally defined as a series of bits, 128 being common these days. What else is there to say?
- There is a set of numbers at the bottom of that paper description that provides test inputs and outputs. You can use those numbers to show basic correctness.
- The characteristic of cryptography algorithms is that they are designed to screw up fast and furiously. Wrong numbers will 'avalanche' through the internals and break everything. Which means, to your good fortune, you only need a very small amount of testing to show you got it very right.
An excellent protocol example of a simple interface is SSL. No matter what you think of the internals of the protocol or the security claims, the interface is designed to exactly mirror the interface to TCP. Hence the name, Secure Socket Layer. An inspired choice! The importance of this is primarily the easy understanding achieved by a large body of programmers who understand the metaphor of a stream.
April 09, 2008
another way to track their citizens
Passports were always meant to help track citizens. According to lore, they were invented in the 19th century to stop Frenchmen evading the draft (conscription), which is still an issue in some countries. BigMac points to a Dutch working paper "Fingerprinting Passports," that indicates that passports can now be used to discriminate against the bearer's country of issue, to a distance of maybe 25cm. Future Napoleons will be happy.
Because terrorising the reader over breakfast is currently good writing style by governments and media alike, let's highlight the dangers first. The paper speculates:
Given that we can remotely detect the presence of a passport of a particular country, how could this functionality be abused? One abuse case that has been suggested is a passport bomb, designed to go off if someone with a passport of a certain nationality comes close. One could even send such a bomb by post, say to an embassy. A less spectacular, but possibly more realistic, use of this functionality would by passport thieves, who can remotely check if someone is carrying passport and if it is of a suitable nationality, before they decide to rob them.
From the general fear department, we can also add that overseas travellers sometimes have a fear of being mugged, kidnapped, hijacked or simply shot because of their mere membership of a favourable or unfavourable country.
Now that we have the FUD off our chest, let's talk details. The trick involves sending a series of commands (up to 4) to the RFID in the passport, each of which are presumably rejected by the passport. The manner of rejection differs from country to country, so a precise fingerprint-of-country can be formed simply by examining each rejection, and then choosing a different command to further narrow the choices.
How did this happen? I would speculate that the root failure is derived from bureaucrats' never-ending appetite for complex technological solutions to simple problems. In this case, the first root cause is the use of the RFID, being by intention and design something that can be read from up to 10 cm.
It is inherently attackable, and therefore by definition a very odd choice for security. The second complexity, then, involved implementing something to stop the attackers reading off the RFIDs without permission. The solution to an active read-off attack is encryption, of course! Which leads to our third complexity, a secret key, which is written inside the passport, of course! Which immediately raises issues of brute-forcing (of course!) and, as the paper references, it turns out, brute forcing attacks work on some countries' passports because the secret key is .. poorly chosen.
All of this complexity, er, solution, means something called Basic Access Control is added to the RFID in order to ensure the use of the secret key. Which means a series of commands meant to defend the RFID. If we factor in the tendency for each country to implement passports entirely alone (because they are more scared of each other than they are of their citizens), we can see that each solution is proprietary and home-grown. To cope with this, the standard was written to be very flexible (of course!). Hence, it permits wide diversity in response to errors.
Whoops! Security error. In the world of security, we say that one should be precise in what we send, and precise in what we return.
From that point of view, this is poor security work by the governments of the world, but that's to be expected. The US State Department can now derive some satisfaction from earlier blunders; because of their failure to implement any form of encryption or access control, American passports can be read by all (terrorists and borderists alike), which apparently forced them to add aluminium foil into the passport cover to act as a Faraday cage. Likely, the other countries will now have to follow suit, and the smugness of being sophisticated and advanced in security terms ("we've got BAC!") will be replaced by a dawning realisation that they should have adopted the simpler solutions in the first place.
April 07, 2008
An idea for opportunistic public key exchange
In our ELTEcrypt research group [writes Dani Nagy], we discussed opportunistic public key exchange from a cost-benefit point of view and came up with an important improvement over the existing schemes (e.g. ssh), which, I think, must be advertised as broadly as possible. It may even merit a short paper to some conference, but for now, I would like to ask you to publish it in your blog.
Opportunistic public key exchange is when two communicating parties perform an unauthenticated key exchange before the first communication session, assume that this key is trustworthy and then only verify that the same party uses the same key every time. This lowers the costs of defense significantly by not imposing authentication on the participants, while at the same time it does not significantly lower the cost of the dominant attack (doing MITM during the first communication session is typically not the dominant attack). Therefore, it is a Pareto-improvement over an authenticated PKI.
One successful implementation of this principle is ssh. However, it has one major flaw, stemming from misplaced costs: when an ssh host is re-installed or replaced by a new one, the cost of migrating the private key of the host is imposed on the host admin, while most of the costs resulting from not doing so are imposed on the clients.
In the current arrangement, when a new system is installed, the ssh host generates itself a new key pair. Migrating the old key requires extra work on the system administrator's part. So, he probably won't do it.
If the host admin fails to migrate the key pair, clients will get a frightening error message that won't let them do their job, until they exert significant effort for removing the "offending" old public key from their key cache. This is their most straightforward solution, which both weakens their security (they lose all protection against MITM) and punishes them for the host admin's mistake.
This could be improved in the following way: if the client detects that the host's public key has changed, instead of quitting after warning the user, it allows the user to accept the new key temporarily for this one session with hitting "yes" and SENDS AN EMAIL TO THE SYSTEM ADMINISTRATOR.
Such a scheme metes out punishment where it is due. It does not penalize the client too much for the host admin's mistake, and provides the latter with all the right incentives to do his duty (until he fixes the migration problem, he will be bombarded by emails by all the clients and the most straightforward solution to his problem is to migrate the key, which also happens to be the right thing to do).
As an added benefit, in some attack scenarios, the host admin will learn about an ongoing attack.
March 12, 2008
Format Wars: XML v. JSON
They're called wars because afterwards, everyone agrees that they were senseless wastes of resources, and faithfully promises never to let it happen again. In this case (at Mozo), the absolutely-everything format of XML (that stuff where everything is surrounded by <angle> bracketed words </angle>) is up against a new comer called JSON.
Because we are software engineers in the financial cryptography world I prefer the haptic approach to decision making. That is, we have to understand at least enough in order to build it. Touch this:
Heres an example data structure, of the kind you might want to transmit from one place to another (represented as a Python dictionary; mentally replace with the syntax from your programming language of choice).
person = {
"name": "Simon Willison",
"age": 25,
"height": 1.68,
"urls": [
"http://simonwillison.net/",
"http://www.flickr.com/photos/simon/",
"http://simon.incutio.com/"
]
}
Speaking strictly from the point of view of security: the goals are to have all your own code, and to be simple. Insecurity lurks in complexity, and other people's code represents uncontrollable complexity. Not because the authors are evil but because their objectives differ from yours in ways that you cannot see and cannot control.
Generally, then, in financial cryptography you should use your own format. Because that ensures that it is your own code doing the reading, and especially, that you have the skills and assets to maintain that code, and fix it.
To get to the point, I think this rules out XML. If one were considering security as the only goal, then it's out: XML is far too complex, it drags in all sorts of unknown stuff which the average developer cannot control, and you are highly dependent on the other people's code sets. I've worked on a few large projects with XML now, and this is the ever-present situation: out of control.
What then about JSON? I'm not familiar with it, but a little googling and I found the page above that describes it ... in a page. From a strictly security pov, that gives it a hands-down win.
I already understand what JSON is about, so I can secure it. I can't and never will be able to say I can secure XML.
March 09, 2008
The Trouble with Threat Modelling
We've all heard it a hundred times: what's your threat model? But how many of us have been able to answer that question? Sadly, less than we would want, and I myself would not have a confident answer to the question. As writings on threat modelling are few and far between, it is difficult to draw a hard line under the concept. Yet more evidence of gaping holes in the security thinker's credibility.
Adam Shostack has written a series of blog posts on threat modelling in action at Microsoft (read in reverse order). It's good: readable, and a better starting point, if you need to do it, than anything else I've seen. Here are a couple of plus points (there are more) and a couple of criticisms:
Surprisingly, the approach is written to follow the practice that it is the job of the developers to do the security work:
We ask feature teams to participate in threat modeling, rather than having a central team of security experts develop threat models. Theres a large trade-off associated with this choice. The benefit is that everyone thinks about security early. The cost is that we have to be very prescriptive in how we advise people to approach the problem. Some people are great at think like an attacker, but others have trouble. Even for the people who are good at it, putting a process in place is great for coverage, assurance and reproducibility. But the experts dont expose the cracks in a process in the same way as asking everyone to participate.

What is written between the lines is that the central security team at Microsoft provides a moderator or leader for the process. This is good thinking, as it brings in the experience, but it still makes the team do the work. I wonder how viable this is for general practice? Outside the megacorps where they have made this institutional mindshift happen, would it be possible to ask a security expert to come in, swallow 2 decades of learning, and be a leader of a process, not a doer of a process?
There are many ramifications of the above discovery, and it is fascinating to watch them bounce around the process. I'll just repeat one here: simplification! Adam hit the obvious problem that if you take the mountain to Mohammad, it should be a small mountain. Developers are employed to write good code, and complex processes just slow that down, and so an aggressive simplification was needed to come up with a very concise model. A more subtle point is that the moderator wants to impart something as well as get through the process, and complexity will kill any retention. Result: one loop on one chart, and one table.
The posts are not a prescription on how to do the whole process, and indeed in some places, they are tantalisingly light (we can guess that it is internal PR done through a public channel). With that understanding, they represent a great starting point.
There are two things that I would criticise. One major error, IMHO: Repudiation. This was an invention by PKI-oriented cryptographers in the 1990s or before, seeking yet another marketing point for the so-called digital signature. It happens to be wrong. Not only is the crypto inadequate to the task, the legal and human processes implied by the Repudiation concept are wrong. Not just misinformed or misaligned, they are reversed from reality, and in direct contradiction, so it is no surprise that after a decade of trying, Non-Repudiation has never ever worked in real life.
It is easy to fix part of the error. Where you see Non-Repudiation, put Auditing (in the sense of logging) or Evidence (if looking for a more juridical flavour). What is a little bit more of a challenge is how to replace "Repudation" as the name of the attack ... which on reflection is part of the error. The attack alleged as repudiation is problematic, because, before it is proven one way or the other, it is not possible to separate a real attack from a mistake. Then, labelling it as an attack creates a climate of guilty until proven innocent, but without the benefit of evidence tuned to proving innocence. This inevitably leads to injustice which leads to mistrust and finally, (if a fair and open market is in operation) rejection of the technology.
Instead, think of it as an attack born of confusion or uncertainty. This is a minor issue when inside one administrative or trust boundary, because one person elects to carry the entire risk. But it becomes a bigger risk when crossing into different trust areas. Then, different agents are likely to call a confusing situation by different viewpoints (incentives differ!).

At this point the confusion develops into a dispute, and that is the real name for the attack. To resolve the dispute, add auditing / logging and evidence. Indeed, signatures such as hashes and digsigs make mighty fine evidence so it might be that a lot of the work can be retained with only a little tweaking.
I then would prefer to see the threat - property matrix this way:
| Threat | Security Property | |
| Spoofing | --> | Authentication |
| Tampering | --> | Integrity |
| Dispute | --> | Evidence |
| Information Disclosure | --> | Encryption |
| Denial of Service | --> | Availability |
| Elevation of Privilege | --> | Authorisation |
A minor criticism I see is in labelling. I think the whole process is not threat modelling but security modelling. It's a minor thing, which Adam neatly disposes of by saying that arguing about terms is not only pointless but distracts from getting the developers to do the job. I agree. If we end up disposing of the term 'security modelling' then I think that is a small price to pay to get the developers a few steps further forward in secure development.
March 06, 2008
Economics not repealed, just slow: Paypal blames Browsers for Phishing
Well, it had to happen one day. A major player has finally broken the code of silence and blamed the browsers. In this case, it is PayPal, and Safari.
Infoworld last week quoted Michael Barrett, PayPals CIO, saying the following:Apple, unfortunately, is lagging behind what they need to do, to protect their customers. Our recommendation at this point, to our customers, is use Internet Explorer 7 or 8 when it comes out, or Firefox 2 or Firefox 3, or indeed Opera.
The browser is the user's security tool. The browser is the only thing between you and the phisher. The browser is the point of all attack attention. The browser is it. That's why it had SSL built in -- to correctly identify the website as the one you wanted to go to.
So above, Paypal blames Safari for not doing enough about phishing. It's true, Safari does nothing (as I found out recently and had to switch back to Firefox). It likely had to be Paypal because the regulated banks won't say boo without permission, and Paypal might be supposed to be net-savvy. It had to be Safari because (a) there is that popular alternate now, and (b) Apple is still small enough not to be offended, and (c) others have done something in the phishing area.
A take-away then is not the names involved, but the fact that a large player has finally lost patience and is pointing fingers at those who are not addressing phishing:
At issue is the fact that Safari lacks a built-in phishing filter to warn users about shady Web sites. Safari also doesnt support so-called Extended Validation certificates, which turn the address bar green if a site is legit. Extended Validation certificates arent the complete answer but are a help.
OK, so those are some ideas, and Safari could do something. However there may be more to this than meets the eye:
An emerging technology, EV certificates are already supported in Internet Explorer 7, and they've been used on PayPal's Web site for more than a year now. When IE 7 visits PayPal, the browser's address bar turns green -- a sign to users that the site is legitimate. Upcoming versions of Firefox and Opera are expected to support the technology.
Aha! It's not a general complaint to Apple at all. It is a complaint that EV has not been implemented in Safari. It's a very specific complaint!
( Long term readers know that EV implements the basic steps necessary to complete the SSL security model: By naming the CA that makes the claim, it clearly encapsulates the statement. By making it more clear what was going on to the user the final step was made to the risk-bearing party. )
Paypal has purchased a green certificate. And now they want it to work. It works on IE, but not on others. (Firefox and Opera say "soon" and so are given a pass. For now.) Apple rarely comments on its plans, so it has been named and shamed for not adopting the agreed solution. More for not playing the game than anything.
The sad thing about the EV is that it is (approximately) what the browsers should have done years ago, when phishing became apparent.
But nothing could be done. I know, I tried. If there is any more elegant proof of the market for silver bullets, I'm hard pressed to find it. To break the equilibrium around SSL+cert-user-CA (that reads SSL plus cert minus user minus CA), EV had to be packaged as an industry consortium agreeing on an expensive product. Once so packaged, it was then sold to Microsoft and to some major websites. Once in the major places, influence is then brought to bear to get the rest to come into line.
The problem with this, as I lay out in silver bullets, is that shifting from one equilibrium to another is a strictly weaker strategy. Firstly, we are not that confident in our choice of equilibrium. That's by definition; we wouldn't play this game if we knew how to play the game. Secondly, and to spin a leaf from John Boyd, the attacker can turn inside our OODA loop. Which is to say, he can create and modify his attacks faster than we can change equilibrium. Or, he is better at playing his game than we are.
You can read a much more extended argument in the essay (new, improved with extra added focus!). But for now, what I find interesting is the questions we don't yet have answers to.
What would be the attacker's best strategy, knowing all we do about the market and our claim that this is equilibrium shifting? Would the attacker destroy EV? Would he protect EV? Would he milk it?
Another question is, what is Apple's best strategy? It is currently outside the consortium, but has been attacked. Should it join and implement EV? Go it alone? Ignore? Invent an own strategy?
February 27, 2008
Attack on Brit retail payments -- some takeways
Some of the people at U.Cambridge have successfully and easily attacked the card readers and cards used in retail transactions in Britain. This is good work. You should skim it for the documented attacks on the British payments systems, if only because the summary is well written.
My takeaways are these:
- the attack is a listening/recording attack in between the card readers and cards
- the communications between reader and card are not secured (they say "not encrypted"), so easy to tap,
- the attack hides inside a compromised reader (which is slightly but not significantly tamper-resistant)
- the cards themselves have "weak modes" to make the cards usable overseas,
- the card readers are available for sale on eBay!
- the certification or independent security review is done in secret.
Many others will write about the failure to use some security protocol, etc. Also note the failure of modes. So I shall add a postscript on the last point, secrecy of architecture. (I have written before about this problem, but I recall not where.)
By placing the security of the system under the wrap of secrecy, this allows a "secure-by-design" myth to emerge. Marketing people and managers cannot resist the allure of secret designs, and the internal security team has little interest in telling the truth (their job is easier if no informed scrutiny!). As the designs and processes are secret, there is no independent check on the spread of this myth of total security.
At some point the organisation (a bank or a banking sector) internalises the myth of total security and starts to lean heavily on the false belief. Other very-needed parts of the security arrangement are slowly stripped away because "the devices are secure so other parts are not needed."
The reality is that the system is not "secure" but is "economically difficult to attack". Defence in depth was employed to raise and balance the total security equation, which means other parts of the business become part of the security. By way of example, the card readers are often required to be tamper-resistant, and to be "controlled items" which means they cannot be purchased openly. These things will be written into the security architecture.
But, because all the business outside the security team cannot see the security architecture -- it's secret! -- they do not know this. So we see cost cutting and business changes indicated above. Because the business believes the system to be totally secure -- the myth! -- they don't bother to tell the security team that the cards have dual modes, readers are now made of plastic, are sold on eBay. The security team doesn't need to know this because they built a secure system.
In this way, the security-model-wrapped-in-secrecy backfires and destroys the security. I sometimes term the arisal of the myth within banks as organisational cognitive dissonance for want of a better term.
February 13, 2008
H2.1 Protocols Divide Naturally Into Two Parts
Peter Gutmann made the following comment:
Hmm, given this X-to-key-Y pattern (your DTLS-for-SRTP example, as well as OpenVPN using ESP with TLS keying), I wonder if it's worth unbundling the key exchange from the transport? At the moment there's (at least):TLS-keying --+-- TLS transport | +-- DTLS transport | +-- IPsec (ESP) transport | +-- SRTP transport | +-- Heck, SSH transport if you really wantIs the TLS handshake the universal impedance-matcher of secure-session mechanisms?
Which reminds me to bring out another hypothesis in secure protocol design, being #2: Divide and conquer. The first part is close to the above remark:
#2.1 Protocols Divide Naturally Into Two Parts
Good protocols divide into two parts, the first of which says to the second,
trust this key completely!
Frequently we see this separation between a Key Exchange phase and Wire Encryption phase within a protocol. Mingling these phases seems to result in excessive confusion of goals, whereas clean separation improves simplicity and stability.
Note that this principle is recursive. That is, your protocol might separate around the key, being part 1 for key exchange, and part 2 for encryption. The first part might then separate into two more components, one based on public keys and the other on secret keys, which we can call 1.a and 1.b. And, some protocols separate further, for example primary (or root) public keys and local public keys, and, session negotiation secret keys and payload encryption keys.
As long as the borders are clean and simple, this game is good because it allows us to conquer complexity. But when the borders are breached, we are adding complexity which adds insecurity.
A Warning. An advantage from this hypothesis might appear to be that one can swap in a different Key Exchange, or upgrade the protection protocol, or indeed repair one or other part without doing undue damage. But bear in mind the #1: just because these natural borders appear doesn't mean you should slice, dice, cook and book like software people do.
Divide and conquer is #2 because of its natural tendency to turn one big problem into two smaller problems. More later...
November 08, 2007
H1: OpenPGP becomes RFC4880. Consider Hypothesis #1: The One True Cipher Suite
Some good news: after a long hard decade, OpenPGP is now on standards track. That means that it is a standard, more or less, for the rest of us, and the IETF process will make it a "full standard" according to their own process in due course.
RFC4880 is now OpenPGP and OpenPGP is now RFC4880. Hooray!
Which finally frees up the OpenPGP community to think what to do next?
Where do we go from here? That's an important question because OpenPGP provides an important base for a lot of security work, and a lot of security thinking, most of which is good and solid. The OpenPGP web of trust is one of the seminal security ideas, and is used by many products (referenced or not).
However, it is fair to say that OpenPGP is now out of date. The knowledge was good around the early 1990s, and is ready for an update. (I should point out that this is not as embarrassing as it sounds, as one competitor, PKI/x.509, is about 30 years out of date, deriving its model from pre-Internet telco times, and there is no recognition in that community of even the concept of being out of date.)
Rising to the challenge, the OpenPGP working group are thinking in terms of remodelling the layers such that there is a core/base component, and on top of that, a major profile, or suite, of algorithms. This will be a long debate about serious software engineering, security and architecture, and it will be the most fun that a software architect can have for the next ten years. In fact, it will be so much fun that it's time to roll out my view, being hypothesis number one:
H1: The One True Cipher Suite In cryptoplumbing, the gravest choices are apparently on the nature of the cipher suite. To include latest fad algo or not? Instead, I offer you a simple solution. Don't.
There is one cipher suite, and it is numbered Number 1.Cypersuite #1 is always negotiated as Number 1 in the very first message. It is your choice, your ultimate choice, and your destiny. Pick well.
If your users are nice to you, promise them Number 2 in two years. If they are not, don't. Either way, do not deliver any more cipher suites for at least 7 years, one for each hypothesis.And then it all went to pot... We see this with PGP. Version 2 was quite simple and therefore stable -- there was RSA, IDEA, MD5, and some weird padding scheme. That was it. Compatibility arguments were few and far between. Grumbles were limited to the padding scheme and a few other quirks.
Then came Versions 3-8, and it could be said that the explosion of options and features and variants caused more incompatibility than any standards committee could have done on its own.
Avoid the Champagne Hangover Do your homework up front.
Pick a good suite of ciphers, ones that are Pareto-Secure, and do your best to make the combination strong. Document the short falls and do not worry about them after that. Cut off any idle fingers that can't keep from tweaking. Do not permit people to sell you on the marginal merits of some crazy public key variant or some experimental MAC thing that a cryptographer knocked up over a weekend or some minor foible that allows an attacker to learn your aunty's birth date after asking a million times.
Resist the temptation. Stick with The One.
September 01, 2007
How S/MIME could suck slightly less with a simple GETSMIME
I've been using S/MIME for around a year now for encrypted comms, and I can report that the overall process is easier than OpenPGP. The reasons are twofold:
- Thunderbird comes with S/MIME and not OpenPGP. Yes, I know there are plugins, but this decision by the developers is dominating.
- I work with a CA, and it is curious, to watch them work with their own product. Indeed, it's part of the job. (Actually they also do OpenPGP, but as we all know, OpenPGP works just fine without... See reason 1.)
Sadly, S/MIME sucks. I reported previously on Thunderbird's most-welcome improvements to its UI (from unworkable to woeful) and also its ability to encrypt-not-sign, which catapulted the tool into legal sensibility. Recall, we don't know what a signature means, and the lawyers say "don't sign anything you don't read" ... I'd defy you to read an S/MIME signed email.
The problem that then occurs is that the original S/MIME designers (early 1990s?) used an unfortunate trick which is now revealed as truly broken: the keys are distributable with signing.
Ooops. Worse, the keys are only distributable with signing as far as I can see, which uncovers the drastic failings of tools designed by cryptographers and not software engineers. This sort of failure derives from such claims as, you must sign everything "to be trusted" ... which we disposed of above.
So, as signing is turned off, we now need to distribute the keys. This occurs by 2 part protocol that works like this:
- "Alice, please send me a signed email so I can only get your key."
- "Bob, here is a signed email that only means you can get my key."
With various error variations built in. OK, our first communal thought was that this would be workable but it turns out not to scale.
Consider that we change email clients every 6 months or so, and there appears no way to export your key collection. Consider that we use other clients, and we go on holidays every 3 months (or vacations every 12 months), and we lose our laptops or our clients trash our repositories. Some of us even care about cryptographic sanitation, and insist on locking our private keys in our secured laptop in the home vault with guards outside. Which means we can't read a thing from our work account.
Real work is done with a conspiracy of more than 2. It turns out that with around 6 people in the ring, someone is AFK ("away from keys"), all the time. So, someone cannot read and/or write. This either means that some are tempted to write in clear text (shame!), or we are all running around Alice-Bobbing each other. All the time.
Now, of course, we could simply turn on signing. This requires (a) a definition of signing, (b) written somewhere like a CPS, (c) which is approved and sustainable in agreements, (d) advised to the users who receive different signature meanings, and (e) acceptance of all the preceeding points as meaningful. These are very tough barriers, so don't hold your breath, if we are talking about emails that actually mean something (kid sister, knock yourself out...).
Turning on the signing also doesn't solve the core problem of key management, it just smothers it somewhat by distributing the keys every chance we get. It still doesn't solve the problem of how to get the keys when you lose your repository, as you are then locked out of posting out until you have everyone's keys. In every conspiracy, there's always one important person who's notoriously shy of being called Alice.
This exposes the core weakness of key management. Public Key cryptography is an engineering concept of 2 people, and beyond that it scales badly. S/MIME's digsig-distro is just a hack, and something like OpenPGP's key server mechanism would be far more sensible, far more scaleable. However, I wonder if we can improve on even OpenPGP, as the mere appearance of a centralised server reduces robustness by definition (TTPs, CVP, central points of attack, etc).
If an email can be used to send the key (signed), then why can't an email be used to request a key? Imagine that we added an email convention, a little like those old maillist conventions, that did this:
Subject: GETSMIME fc@example.com
and send it off. A mailclient like Thunderbird could simply reply by forwarding the key. (How this is done is an exercise for the reader. If you can't think of 3 ways in the next 3 minutes, you need more exercise.)
Now, the interesting thing about that is that if Tbird could respond to the GETSMIME, we wouldn't need key servers. That is, Alice would simply mail Bob with "GETSMIME Carol@example.com" and Bob's client could respond, perhaps even without asking because Bob already knows Alice. Swarm key distro, in other words. Or, Dave could be a key server that just sits there waiting for the requests, so we've got a key server with no change to the code base.
In closing, I'll just remind that the opinion of this blog is that the real solution to the almost infinite suckiness of S/MIME is that the clients should generate the keys opportunistically, and enable use of crypto as and when possible.
This solution will never be ideal, and that's because we have to deal with email's legacy. But the goal with email is to get to some crypto, some of the time, for some of the users. Our current showing is almost no crypto, almost none of the time, for almost none of the users. Pretty dire results, and nothing a software engineer would ever admit to.
August 16, 2007
Skype on the test of a utility
So how do you know if you are a utility? Crash the system, and see how far the ripples spread.
Skype is down. Their blog reports some sort of network issue that blocks logins.
It's worth tracking to see how the world responds, how dependent the users have become on their Skype feed.
If you really want to be reliable, you need to let the accidents happen. Even, inject some unreliability. I like failure. I for one get perverse enjoyment from bugs. Once I see bugs in software, I like to leave them in there to shake out other bugs. Problems beget more problems, and once I've shaken a system for all its worth, I like to work from the furtherest and easiest, inwards, testing as I go.
It's always a moment of sadness when the last, deepest most convoluted prize bug gets fixed, and the system bursts back into stable, reliable life. Boring, and sad. No more art in life.
Skype to date has been far too reliable for my liking, which may mean it's heading for some reliability problems. You just can't buy the sort of entertainment that the Skype engineers are enjoying today :)
August 07, 2007
Security can only be message-based?
Reading this post from Robert Watson:
I presented, Exploiting Concurrency Vulnerabilities in System Call Wrappers, a paper on the topic of compromising system call interposition-based protection systems, such as COTS virus scanners, OpenBSD and NetBSDs Systrace, the TIS Generic Software Wrappers Toolkit (GSWTK), and CerbNG. The key insight here is that the historic assumption of atomicity of system calls is falacious, and that on both uniprocessor and multiprocessing systems, it is trivial to construct a race between system call wrappers and malicious user processes to bypass protections. ...The moral, for those unwilling to read the paper, is that system call wrappers are a bad idea, unless of course, youre willing to rewrite the OS to be message-passing.
And it sparked a thought that systems can only be secure if message-based. Maybe it's a principle, maybe it's a hypothesis, or maybe it's a law.
(My underlining.) To put this in context, if a system was built using TCP/IP, it's not built with security as its number one, overriding goal. That might be surprising to some, as pretty much all systems are built that way; which is the point, such an aggressive statement partly explains where we are, and partly explains how tricky this stuff is.
(To name names: SSH is built that way. Sorry, guys. Skype is a hybrid, with both message-passing and connections. Whether it is internally message-passing or connection-oriented I don't know, but I can speculate from my experiences with Ricardo. That latter started out message-passing over connection-oriented, and required complete client-side rewrites to remove the poison. AADS talks as if it is message-passing, and that might be because it is from the payments world, where there is much better understanding of these things.)
Back to theory. We know from the coordination problem, or the Two Generals problem, that protocols cannot be reliable about what they have sent to the other side. We also know from cryptography that we can create a reliable message on the receive-side (by means of an integrated digsig). We know that reliabile connections are not.
Also, above, read that last underlined sentence again. Operating systems guys have known for the longest time that the cleanest OS design was message passing (which they didn't push because of the speed issues):
Concurrency issues have been discussed before in computer security, especially relating to races between applications when accessing /tmp, unexpected signal interruption of socket operations, and distributed systems races, but this paper starts to explore the far more sordid area of OS kernel concurrency and security. Given that even notebook computers are multiprocessor these days, emphasizing the importance of correct synchronization and reasoning about high concurrency is critical to thinking about security correctly. As someone with strong interests in both OS parallelism and security, the parallels (no pun intended) seem obvious: in both cases, the details really matter, and it requires thinking about a proverbial Cartesian Evil Genius. Anyone whos done serious work with concurrent systems knows that they are actively malicious, so a good alignment for the infamous malicious attacker in security research!
But none of that says what I asserted above: that if security is your goal, you must choose message-passing.
Is this intuition? Is there a theory out there? Where are we on the doh!-to-gosh scale?
July 05, 2007
Breaching a telco, completely -- an exercise in breaches
Chris points to an indepth article on the Greek phone breach. Most will be looking for the whodunnit, but the article doesn't do more than stir the waters there. It is however a nice explanation of the technical breach. To summarise,
- Vodaphone installed an unpurchased option in the Greek telco switches to do wiretapping, but did not install the management software to monitor that capability.
- intruders used the automatic software install facility to install special patches into 29 separate modules (out of a total of 1760) making for around 6500 lines of code.
- these patches intercepted calls to standard functions, redirecting them to special areas set aside for patching.
- the patches also took lots to detailed steps to hide themselves from logs and checks -- checksum modification, process output filtering, modified shells that permitted unlogged commands to be run, etc.
- the patches ran addressbooks of people to wiretap (around 100).
This ran for about a year, creating invisible wiretaps to some unknown cellphones for external reporting. Why then discovered? The normal story, something went wrong. Apparently a perpetrator upgrade on 24th January 2005 didn't quite work, broke text message forwarding, and started generating log messages. Ericsson investigators had to dig deep and discovered unauthorised patches....
Whoops. As I say, this is the normal story, and the authors say "It's impossible to overstate the importance of logging."
So, what can we say? This involved someone who had substantial knowledge of the system (hard-core programmers), access to the source code, access to a test system, and a substantial budget. E.g., a quasi-insider attack, and the bone is pointed at Ericsson, Vodaphone, or a Greek contractor, Intracom Telecom. And (not or) some spook friends of the aforementioned.
 | Costas Tsalikidis, telco engineer responsible for networks planning, found hanged, an apparent suicide, just before the Athens affair became public. |
Some people have that as their enemy, their threat, and given the target (politicians in Greece in the time of the Olympics) this is not exactly a national security issue (wot, protecting over-steroided atheletes is now spook business?) but it's almost certainly a state actor, and probably one run amok. So it moves the threat model closer to the domain of normal business, if in a mysterious fashion.
How to protect against that? The French offer one answer, tell their pollies to stop using foreign controlled services...
June 28, 2007
"Trusted-Hardcopy" -- more experiments with digitising paper and signatures
RAH points to WSJ on security and paper from HP:
H-P Designs 'Digital Signature' Against ForgeriesBANGALORE, India -- As anyone who does business in India knows, you can't get very far without the right piece of paper. That makes forgery a big problem and one of the most common types of fraud. ... In a research and development laboratory here in Bangalore, India's tech hub, Hewlett-Packard Co. is researching a way of marking new paper documents with a bar code that helps prevent forgeries....
With Trusted Hardcopy, which is just one of the tailored efforts, rather than requiring holograms or watermarked paper, the system uses equipment no more complicated than some software, a scanner and a computer. The bar code is designed to act like a digital signature, "thus bringing network level security to the world of paper," says H-P in a company document. H-P envisages government entities, public offices and companies as potential users, such as for the registration of land ownership.
... Yet India also is famously bureaucratic and forms-ridden. So the company has focused some of its efforts on trying to bridge the gap between tech and paper.... "We sort of assume that paper's not going to go away," said Mr. Kuchibhotla. "And we say that if paper's not going to go away, what technology do you need to bridge what's happening in the paper world with what's happening in the IT world?"
H-P's goal was to make a product that allowed paper to be read by a machine and secure against forgery. An early version of Trusted Hardcopy puts a bar code on paper that is similar to the bar codes on groceries. It contains the data that are also printed on the document and can be read by a scanner. It also encodes the data in the bar code to prevent tampering.
Because the bar code contains the authentic data, any changes to the document should be identifiable. The bar codes can't be easily copied. The bar code is printed at the bottom of a page of regular size copier paper....
May 21, 2007
When to bolt on the security afterwards...
For some obscure reason, this morning I ploughed through the rather excellent but rather deep tome of Peter Gutmann's Cryptographic Security Architecture - Design and Verification (or at least an older version of chapter 2, taken from his thesis).
He starts out by saying:
Security-related functions which handle sensitive data pervade the architecture, which implies that security needs to be considered in every aspect of the design, and must be designed in from the start (its very difficult to bolt on security afterwards).
And then spends much of the chapter showing why it is very difficult to design it in from the start.
When, then, to design security in at the beginning and when to bolt it on afterwards? In my Hypotheses and in the GP essays I suggest it is impractical to design the security in up-front.
But there still seems to be a space where you do exactly that: design the security in up-front. If Peter G can write a book about it, if security consultants take it as unquestionable mantra, and if I have done it myself, then we need to bring these warring viewpoints closer to defined borders, if not actual peace.
Musing on this, it occurs to me that we design security up front when the mission is security . And, not, if not. What this means is open to question, but we can tease out some clues.
A mission is that which when you have achieved it, you have succeeded, and if you have not, you have failed. It sounds fairly simple when put in those terms, and perhaps an example from today's world of complicated product will help.
For example a car. Marketing demands back-seat DVD players, online Internet, hands-free phones, integrated interior decorative speakers, two-tone metallised paint and go-faster tail trim. This is really easy to do, unless you are trying to build a compact metal box that also has to get 4 passengers from A to B. That is, the mission is transporting the passengers, not their entertainment or social values.
This hypothesis would have it that we simply have to divide the world's applications into those where security is the mission, and those where some other mission pertains.
E.g., with payment systems, we can safely assume that security is the mission. A payment system without security is an accounting system, not a payment system. Similar logic with an Internet server control tool.
With a wireless TCP/IP device, we cannot be so dismissive; an 802.11 wireless internet interface is still good for something if there is no security in it at all. A wireless net without security is still a wireless net. Similar logic with a VoIP product.
(For example, our favourite crypto tools, SSH and Skype, fall on opposing sides of the border. Or see the BSD's choice.)
So this speaks to requirements; a hypothesis might be that in the phase of requirements, first establish your mission. If your mission speaks to security, first, then design security up front. If your mission speaks to other things, then bolt on the security afterwards.
Is it that simple?
May 15, 2007
K6 again, again and again. Therefore, H6.4 -- Compromise on Security before Delivery
Bruce Schneier's popular cryptogram is out with the essay that I challenged earlier. Here's another point that I missed early on:
I see this kind of thing happening over and over in computer security. In the late 1980s and early 1990s, there were more than a hundred competing firewall products. The few that "won" weren't the most secure firewalls; they were the ones that were easy to set up, easy to use and didn't annoy users too much. Because buyers couldn't base their buying decision on the relative security merits, they based them on these other criteria. The intrusion detection system, or IDS, market evolved the same way, and before that the antivirus market. The few products that succeeded weren't the most secure, because buyers couldn't tell the difference.
This is simply the dominance of Kherchoffs' 6th principle. The most important ("as I've said many times before") although cryptographers still believe the 2nd is more important. One could validly ask how many product and industry evolutions do we have to watch before we work this out? Will this happen, again and again?
For those who do not recall, K6 is simply that the tool has to be usable:
6. Finally, it is necessary, given the circumstances that command its application, that the system be easy to use, requiring neither mental strain nor the knowledge of a long series of rules to observe.
By users. It's almost as if, as suggested above, that buyers cannot base their buying decision on the security metrics, so they cast around and decide on usability.
But not quite. The truth is far more fundamental than mere ignorance and random behaviour by users. It is that a tool that is used delivers security, and a tool that is not used cannot deliver any security at all. So an easy-to-use tool will generally win over a hard-to-use tool, and this will dominate the security equation.
Or to put it in other terms (another hypothesis!) the most common security failure of all is to not be used. The security business is more about business rules than security rules, which leads me into today's hypothesis:
#6.4 Compromise on Security before DeliverySecurity experts will tell you that if you don't build in security at the beginning, then you'll have trouble building it in later. This is true, but it hides a far worse evil: if you spend too much effort on security up front, you'll either lose time and lose the market, or you'll create a security drag on the application side before it has shown its true business model.
The security-first argument speaks to security convenience, the business-first argument speaks to survival. Make sure you understand your businesss need for survival, and pray that they understand the inconveniences you put up with to ensure that goal.
This will be unpopular. But, read the snippet above, again. Kerckhoffs wrote K6 in 1883, so we've got plenty of time. Again and again.
May 11, 2007
H6.3 and the clash of worlds -- IESG v. iPods --- Security for the throwaway generation
Thoughts from the modern world:
My incompetence with electronics and computers has always been offset by help from friends in the software industry. The lesson I learned from trying to work with an older-generation iPod is different. Technologies of different generations don't totally understand each other -- just like humans of different generations. However, in the case of electronics, generations pass in a matter of months, if not weeks.
He suggests that iPods don't talk to cars unless they are both up to date. Gadgets now work in generations!
Meanwhile, the IESG -- Internet Engineering Something Group -- is resisting the OpenPGP community from standardising its protocol because the document isn't good enough to be implemented from the document itself. (As discussed in their open maillist, I'll spare you the details....)
Who's right in this clash of worldviews? The market is always right. Although the IESG has a noble endeavour and a mission derived from the long history of lock-out by major corporations, the market moves too fast for such things.
We as a marketplace simply accept that some consumers, some developers, some standards will lose out. Because they weren't fast enough. OpenPGP faces that battle, and in the end, the long delay from 1997 or so until now has caused a fair cost on its adoption. (Yes, that was our fault, we didn't write it fast enough.)
Or, in contrast, those that did implement OpenPGP and PGP (Cryptix did both at insistence of myself, for example) didn't wait for the standard. PGP itself has migrated seriously, with losses at each step; we are now on protocol version 4 and this is distinctly different to protocol version 1!
This then means we have to be flexible. Today's hypothesis then is directly towards the security protocol industry entering the throwaway world:
H6.4: Design One to Throwaway. You Will Anyway.Carefully partition your protocol to be replaced. Not some portion of it (see Hypothesis #1 -- the One True Cipher Suite) but the whole sodding thing. If you like, get blatant about it and slot in ROT13 with a checksum made from your cat's ink dippings and a key exchange from putty and pigeon post.
Likely your application will not need real security for the first 1000 users or so (pick you own number here, or read up on GP). Once you've proven the business model, then it's time to secure, and start the tortuous and expensive process of rolling out a new protocol.
Here however note carefully: you are taking on a risk on behalf of the business, and the cryptoguild will massacre you! Make sure that you tell your boss and his boss and her boss too, but do it quietly.
... and we need to replace Dodgy Crypto Protocol #1 when the heat startsDon't just tell them, write it down, email it to the auditors, tattoo it on their daughters' foreheads in a secret code that only they know.
Meanwhile, design Well Needed Protocol #2 over your private weekends. Tell your spouse you need to save the world, or better yet, make him do it. Just make sure you are ready with a replacement in advanced form.
May 09, 2007
Solution to phishing -- an idea who's time has come?
Over on EC and other places they are talking about the .bank TLD as a possibility for solving phishing. Alex says it's an idea who's time has come.
No chance: Adam correctly undermines it:
- Crooks are already investing in their attacks. If that money will have a high return, by convincing more people that the URL is safe, then crooks will invest it.
- Some banks, such as credit unions, can't really afford $50,000 for a domain name, and so won't have one. (Thanks to Alex at RiskAnalys.is, " .bank TLD, An Idea Whose Time Has Come?"
- Finally, and most importantly, it won't work. People don't understand URLs, and banks create increasingly complex URLs. The phishers will make foo.bar.cn/.bank/ and people won't understand that's bad.
It's useful to throw these ideas around ... if even as an exercise of what doesn't work. .bank won't work, or, if it did, why did all the URL based stuff fail in the past?
Human names aren't secure. Check out zooko's triangle. Something more is needed. Adam goes on to say:
The easy solution to preserving the internet channel against phishers is to use bookmarks.
The secure bookmark may be it. Adam is right. If there is such a thing as a time for a solution, the bookmark's time may have come.
The reason is that we as a security community (I mean here the one that took phishing seriously as a threat) have done a *lot* of work that has pushed in that direction. In excrutiatingly brief form:
- ZT is the theory,
- Trustbar was the first experiment,
- Petname Toolbar simplified it down to the essentials of petnames *and* discovered the bookmark,
- the caps community re-thought out all their theory (!) and said "it's a secure bookmark!"
- the human security UI people like Ping mixed in different flavours and different ideas.
Etc, etc. The bookmark was the core result. It's time has come, in that many of the people looking at phishing have now clicked into alignment on the bookmark.
But Adam also raises a good point in that it is hard to compete with sold security:
But that's too simple for anyone to make money at it. Certainly, no one's gonna make $50,000 a bank. That money is better spent on other things. .Bank is a bad idea.
I think that is a truism in general, but also the converse is as much a truism: many security developments were done for free in the 1st instance. SSH, Skype, firewalls, SSLeay, etc were all marked by strong not-for-profit contributions, and these things changed the world.
May 08, 2007
H6.2 Most Standardised Security Protocols are Too Heavy
Being #6.2 in a series of hypotheses.
It's OK to design your own protocol. If there is nothing out there that seems to fit, after really thrashing #6.1 for all she is worth, design one that will do the job -- your job.
Consider the big weakness of SSL - its a connection protocol!
The mantra of "you should use SSL" is just plain stupid. For a start, most applications are naturally message-oriented and not connection-oriented. Even ones that are naturally stream-based -- like voip -- are often done as message protocols because they are not stream-based enough to make it worthwhile. Another example is HTTP which is famously a request/response protocol, so it is by definition a messaging protocol layered over a connection protocol. The only real connection-oriented need I can think of is for the secure terminal work done by SSH; that is because the underlying requirement (#6.1) is for a terminal session for Unix ttys that is so solidly connection based that there is no way to avoid it. Yet, even this slavish adoption of connection-oriented terminal work is not so clearcut: If you are old enough to remember, it does not apply to terminals that did not know about character echo but instead sent lines or even entire pages in batch mode.
What this principle means is that you have to get into the soul of your application and decide what it needs (requirements! #6.1 ! again!) before you decide on the tool. Building security systems using a bottom-up toolbox approach is fraught with danger, because the limitations imposed by the popular tools cramp the flexibility needed for security. Later on, you will re-discover those tools as shackles around your limbs; they will slow you down and require lots of fumbling and shuffling and logical gymnastics to camouflage your innocent journey into security.
May 05, 2007
H6.1: Designing (Security) Without Requirements is like Building a Road Without a Route Map to a Destination You've Never Seen.
Number 6.1 in a series of Hypotheses, as sparked by the earlier post that suggests that S/MIME and its critics alike lack foundation.
Lay down your requirements before you start.
I find it takes longer to lay down the security requirements of the application than to actually design the protocol to meet the needs. And, it takes longer to design than it does to code up the first version. The hard work is in knowing what to build, not in building it.
During later phases, you will find challenges that bounce you back to your original requirements.
Let that happen. Bounce things back and forward for as long as it takes to prove your requirements are really what is needed for the application. Don't be surprised if you get half-way through and discover a real doozy.
The alternative is to pick up someone else's requirements out of a textbook or off a cypherpunks list and assume they make sense. If that happens you'll be into a perpetual battle that will eventually end up in a dog's breakfast when some real canine attacker works out the joke. If you're in that game, use a psuedonym when designing, and change jobs before it gets serious.
To come: 6.2 through 6.6, to complete Hypothesis #6: It's your job. Do it!
survey of RFC S/MIME signature handling
As inspired by this paper on S/MIME signing, I (quickly) surveyed what the RFCs say about S/MIME signature semantics. In brief, RFCs suggest that the signature is for the purpose of:
- integrity of content or message
- authenticity of the sender / originator, and/or
- non-repudiation of origin
- (advanced usages such as) preservation of signing labels
In increasing order of sophistication. What the RFCs do not say is that a digital signature used in an S/MIME packet should be for a particular purpose, and should be construed to a particular meaning.
That is, they do not say that the signature means precisely some set of the above, and excluding others. Is it one? Is it all? Is one more important than another?
RFC2459 sheds more light on where this is defined:
A certificate user should review the certificate policy generated by the certification authority (CA) before relying on the authentication or non-repudiation services associated with the public key in a particular certificate. To this end, this standard does not prescribe legally binding rules or duties.
There, we can probably make a guess that the RFC uses the term "non-repudiation" when it means all of the legal semantics that might apply to a human act of signing. (Non-repudiation, as we know, is a fundamentally broken concept and should not be used.) So we can guess that any human semantics are deferred to the CA's documents.
Indeed, RFC2459 goes even further by suggesting that the user refer to the CP before relying on the authentication services. This is a direct recognition that all CAs are different, and therefore the semantics of identity must also differ from CA to CA. In this sense, RFC2459 is correct, as we know that many certificates are issued according to domain-control, others are issued according to web-of-trust, and yet others are issued to the EV draft.
So when the paper mentioned above refers to weaknesses, it seems to be drifting into semantics that are not backed up by its references. Although the commentary raises interesting problems, it is not easy to ascribe the problem to any particular area. Indeed, few of the documents specified have a definition of security, as indicated by (lack of) requirements, and neither does the paper supply one. Hence the complaint that "naïve sign & encrypt is vulnerable" is itself vulnerable to definitions assumed but not clearly stated by the author.
Where did these confused semantics come from? This is a common trap that most of the net and much of the cryptographic community has fallen into; The wider problem is simply not doing the requirements, something that serious software engineers know is paramount.
A narrower problem is that the digital signature can be confused with a human signature, perhaps by using the same word for very different concepts. Many people have then thought it has something to do with a human signature, or human identification, confusing its real utility and complicating architectures built on such confusion.
MOSS:
As long as the private keys are protected from disclosure, i.e., the private keys are accessible only to the user to whom they have been assigned, the recipient of a digitally signed message will know from whom the message was sent and the originator of an encrypted message will know that only the intended recipient is able to read it.
ESS:
Some of the features of each service use the concept of a "triple wrapped" message. A triple wrapped message is one that has been signed, then encrypted, then signed again. The signers of the inner and outer signatures may be different entities or the same entity....1.1.1 Purpose of Triple Wrapping
Not all messages need to be triple wrapped. Triple wrapping is used when a message must be signed, then encrypted, and then have signed attributes bound to the encrypted body. Outer attributes may be added or removed by the message originator or intermediate agents, and may be signed by intermediate agents or the final recipient.
The inside signature is used for content integrity, non-repudiation with proof of origin, and binding attributes (such as a security label) to the original content. These attributes go from the originator to the recipient, regardless of the number of intermediate entities such as mail list agents that process the message. The signed attributes can be used for access control to the inner body. Requests for signed receipts by the originator are carried in the inside signature as well.....
The outside signature provides authentication and integrity for information that is processed hop-by-hop, where each hop is an intermediate entity such as a mail list agent. The outer signature binds attributes (such as a security label) to the encrypted body. These attributes can be used for access control and routing decisions.
S/MIME Version 3 Certificate Handling:
2.3 ... Agents MAY send CA certificates, that is, certificates that are self-signed and can be considered the "root" of other chains. Note that receiving agents SHOULD NOT simply trust any self-signed certificates as valid CAs, but SHOULD use some other mechanism to determine if this is a CA that should be trusted. Also note that in the case of DSA certificates the parameters may be located in the root certificate. This would require that the recipient possess the root certificate in order to perform a signature verification, and is a valid example of a case where transmitting the root certificate may be required.
S/MIME Version 3 Message Specification
1. IntroductionS/MIME (Secure/Multipurpose Internet Mail Extensions) provides a consistent way to send and receive secure MIME data. Based on the popular Internet MIME standard, S/MIME provides the following cryptographic security services for electronic messaging applications: authentication, message integrity and non-repudiation of origin (using digital signatures) and privacy and data security (using encryption).
Internet X.509 Public Key Infrastructure Certificate and CRL Profile
This specification profiles the format and semantics of certificates and certificate revocation lists for the Internet PKI. ...In order to relieve some of the obstacles to using X.509 certificates, this document defines a profile to promote the development of certificate management systems; development of application tools; and interoperability determined by policy.
Some communities will need to supplement, or possibly replace, this profile in order to meet the requirements of specialized application domains or environments with additional authorization, assurance, or operational requirements. However, for basic applications, common representations of frequently used attributes are defined so that application developers can obtain necessary information without regard to the issuer of a particular certificate or certificate revocation list (CRL).
A certificate user should review the certificate policy generated by the certification authority (CA) before relying on the authentication or non-repudiation services associated with the public key in a particular certificate. To this end, this standard does not prescribe legally binding rules or duties.
May 02, 2007
Message is the Center
This is getting boring. Yet another post from Gunnar Peterson where the only thing I can do is copy it verbatim:
Tim Bray on REST:Messages All The Way Down · HTTP is a decent and under-appreciated protocol, but in the end maybe the most important thing is that it forces you to think about the messages and how you exchange them. Theres no pretense that Remote Procedures are being called, or Object Models are being shared; I send you some bits and some metadata about them, and you respond with the same. It turns out that in the HTTP universe, at that point our conversation is over, and that turns out to be a good basis for building applications, but the key thing is putting the messages, rather than what they allegedly stand for, at the centerThat's great - the message is the center - now REST just needs message level security model and mechanisms like WS-Security. SSL is what is usually bandied about as a security model by Restafarians, but we know from Deutsch, Gosling, and Joy that "the network is secure" is the fourth fallacy of distributed computing.
Ok, I admit to being highly skeptical about WS-anything, but that's his area :) The concept however is right: REST is great but totally insecure, and there isn't any way to help that right now, SSL being a famously connection-oriented design that doesn't meet a message-oriented requirement.
( For the record, SOX was more or less a basic form of REST, done in 1995 by Gary Howland. Not because he was some sort of seer or genius, but because that was the only serious way to engineer it. Well, that's what we thought at the time. Maybe he was a genius. )
April 08, 2007
H3 - there is only one mode, and it is secure
Some time ago, I used Thunderbird as a foil for introducing a hypothesis of mine:
There is only one mode, and it is secure.
Thunderbird, although long suffering and unfairly maligned, is a perfect example of how a security application fails to deliver security, because it believes there are "modes" and a user must "enable modes" in order to get security. It is, in the case of Thunderbird, and practically all S/MIME products, a disaster, because it reduces takeup to the numbers that don't permit any valuable market feedback to develop.
Here, then is Hypothesis #3 all written out in simple, direct form.
#3 There is only one Mode, and it is Secure.Good Protocols bootstrap into secure mode, immediately. On first time starting up, the protocol goes into secure mode. From there on, it only gets better.
There is no insecure mode. No button to turn off, no feature to forget, no way to trick the application.
There should be no necessary setup by the user. If a public key is needed, make it. If the other side needs a secret key, send it. If you need a password, invent it and suggest the user replaces it, don't ask for it and block the action.
It should take an Act of God to start up in anything but the best possible security you can manage. A Presidential Order doesn't cut it. Make your protocol immorally promiscuous and your users will thank you, even if your reputation will take a dive for about 5 years. Don't worry, your users will outlive their users.
In practice, a perfect start-up is impossible, and we do not let a perfect theory be the enemy of a good protocol. Your protocol should leap into life with joy and abandon, and reward your users with instantly secure communication. Let an expert add some extra features if they want to get that warm gooey feeling of no-risk security, but never let him tell you that near enough isn't good enough. Instead, send him paddling over to a committee.
The above says what to do, but it doesn't say why. Let's talk about why.
It's all about take-up: In the building and especially the deployment of a secure protocol, every time we present a choice to the user, we face the binary destruction of our market share. To our poor, overloaded and easily distracted user, if there are two modes, and if everything is equal, she has a 50% chance of turning off the security.
Actually, things aren't equal, and it is much worse than 50%. Some brief examples:
- In crypto mode, we have to talk to someone, and they have to select crypto as well. Divide by 2 for Alice, and 2 for Bob (draw it in a 2 X 2 table, if you like). Keep dividing for everyone else we want to talk to, of course...
- In S/MIME, you can only deliver the keys if you sign the email. How do you sign? Oh, you have to turn that on (divide by 2). Hmmm, and what does that mean, to sign? (Divide by 2.) Well, it's undefined, or it's the same as a human signature, or it's not the same, or .... (divide by 2). And anyway, don't lawyers say "don't sign anything you aren't fully sure of?" (Divide by 2.)
(Thunderbird now permits encryption *without signing* so it is possible to do a simple "signed nonsense message" to send your key, and avoid the trauma of the above paragraph. This is a big win, as before it was unprofessional and potentially dangerous to recommend S/MIME.)
- But people still have to add certificates .... and they still have to get the certs from somewhere ... else. The number of steps involved is more than the digits on our hands, so divide by 2, until you run out of fingers.
- If they have two email addresses, guess what? The certs won't work as the other side rejects them. (Divide by 2.). It isn't possible to use one cert for two email addresses. Why? I have no idea, but divide by two, as everyone has more than one email address.
I could go on. All these problems have solutions, of course, if you are serious about that sort of thing. Or you could take another tack and sweep all the problems away, by simply employing H3:
There is only one mode, and it is secure.
H3 says "be kind to your users," and don't ask them to turn off your software. H3 suggests "be kind to your shareholders," and don't ask them to apply the maths of binary destruction to the predicted user base in your business plan.
March 02, 2007
Random stats on instant messaging (IM/chat) ...
(cleaning up old stats from the Times ... there must be money here, as otherwise, why didn't I publish these months ago?)
ONLINE, ON THE PHONE, ON THE UP50 billion the number of e-mails dispatched every day wordwide; in 2001 the traffic was less than 12 billion 88 per cent of e-mails are junk including about 1 per cent which are virus-infected 32 The average number of e-mail messages received per person per day. This is rising by 84 per cent each year 440 million the number of electronic mailboxes in use, including 170 million corporate ones, growing by 32 per cent per year 1,035 million the total number of mobile phone text messages sent each month in Britain 37 The average number of texts a user sends per month compared with 21 in 2001 1 million the number of children aged under 10 in Britain - one in three - who own a phone 8 The average age at which a child gets a mobile phone in Britain Copyright 2006 Times Newspapers Ltd.
February 26, 2007
Crypto Revisionism -- Hypothesis #6 -- It's your Job. Do it.
Paul Crowley rants in anguish over the status of current day cryptoplumbing, and attacks the usual suspects (SSL, SSH, *pgp*, IPSec). They are easy targets so I'll let you read them there. (Where Paul goes further is that he actually attacks SSH, which takes it beyond the norm. I like.)
Leaving aside that, what is it that Paul really interested in? He needs a protocol.
I'm now in the position of wanting to make crypto recommendations for the next generation of the Monotone revision control system. I wish I had a better idea what to tell them. They need transport-level crypto for server-to-server connections, but I hesitate to recommend SSL because the poison that is X.509 is hard to remove and it makes all the libraries for using SSL ugly and hard to use. They need to sign things, but I don't want to recommend OpenPGP: it's hard to talk to and the Web of Trust is a truly terrible fit for their problem; on top of which, OpenPGP has no systematic way to assert the type of what you're signing. They need a way for one key to make assertions about another, and we're going to invent all that from scratch because nothing out there is even remotely suitable.
After long hard thought ... Paul says he has problems with what is offered. Here's what I think, and in my scratch pad of Hypotheses, I call this
Hypothesis #6: It's your job. Do it.
(It's your job to click. Click on ... thanks to Zooko for the pointer! Oh, and the editor reminds that Hypothesis #3 was introduced earlier.)
November 24, 2006
What is the point of encrypting information that is publicly visible?
The Grnch asks, in all honesty:
> What is the point of encrypting information that is publicly visible?
To which the answer is:
To remove the security weakness of the decision.
This weakness is the decision required to determine what is "publicly visible" or not. Or, more generally, what is sensitive or not.
Unfortunately, there is no algorithm to determine those two sets. Software can't make that decision, so it falls to humans. Unfortunately, humans have no good algorithm either -- they can make quick value judgements, they can make bad value judgements, or they can turn the whole thing off. Worse, even, it often falls to software engineers to make the decision (e.g., HTTPS) and not only are engineers poor at making such judgements, they don't even have local contextual information to inform them. That is, they have no clue what the user wants protected.
The only strategy then is to encrypt everything, all the time. This feeds into my third hypothesis:
There is only one mode, and it is secure.
I'm being very loose here in the use of the word "secure" but suffice to say, we include encryption in the definition. But it also leads feeds into another hypothesis of mine:
Only end-to-end security is secure.
For the same reasons ... if we introduce a lower layer security mechanism, we again introduce a decision problem. Following on from the above, we can't trust the software to decide whether to encrypt or not, because it has no semantic wisdom with which to decide. And we can't trust the user...
Which brings rise to the knowledge problem. Imagine a piece of software that has a binary configuration for own-security versus rely-on-lower-layers. A button that says "encrypt / no-encrypt" which you set if the lower layer has its own security or not, for example. There is, so the theory goes, no point in encrypting if the lower layer does it.
But, how does it know? What can the software do to reliably determine whether the lower layer has encryption? Consider IPSec ... how do we know whether it is there? Consider your firewall sysadmin ... who came in on the weekend and tweaked the rules ... how do we know he didn't accidentally open something critical up? Consider online account access through a browser ... how do we know that the user has secured their operating system and browser before opening Internet Explorer or Firefox?
You can't. We can't, I can't, nobody can rely on these things. Security models built on "just use SSL" or similar are somewhere between fatally flawed and nonsense for these reasons; for real security, security models that outsource the security to some other layer just don't cut the mustard.
But, the infrastructure is in place, which counts for something. So are there some tweaks that we can put in place to at least make it reasonably secure, whatever that means? Yes, they include these fairly minor tweaks:
- put the CA's name on the chrome of the browser
- implement SNI (in everywhere but Opera :)
- encrypt -- HTTPS -- everything all the time
- utilise naming theory (add petnames to certs)
Spread the word! This won't stop phishing, but it will make it harder. And, it gets us closer to doing the hard re-engineering ... such as securing against MITB.
Appendix: Alaric Daily posts this great example:

October 06, 2006
Why security training is really important (and it ain't anything to do with security!)
Lynn mentioned in comments yesterday:
I guess I have to admit to being on a roll.
:-) Lynn grasped the nexus between the tea-room and the systems room yesterday:
One of the big issues is inadequate design and/or assumptions ... in part, failing to assume that the operating environment is an extremely hostile environment with an enormous number of bad things that can happen.
What I didn't stress was the reasons behind why security training was so important -- more important than your average CSO knows about. Lynn spots it above: reliability.
The reason we benefit from teaching security (think Fight Club here not the American Football) is that it clearly teaches how to build reliable systems. The problem addressed here is that unreliable systems fall foul of statistical enemies, and they are weak, few and far between. But when you get to big systems and lots of transactions, they become significant, and systems without reliability die the death of a thousand cuts.
Security training solves this because it takes the statistical enemy up several notches and makes it apparent and dangerous even in small environments. And, once a mind is tuned to thinking of the attack of the aggressor, dealing with the statistical failure is easy, it's just an accidental case of what an aggressor could do.
I would even assert that the enormous amounts of money spent attempting to patch an inadequate implementation can be orders of magnitude larger than the cost of doing it right in the first place.
This is the conventional wisdom of the security industry -- and I disagree. Not because it doesn't make sense, and because it isn't true (it makes sense! and it's true!) but because time and time again, we've tried it and it has failed.
The security industry is full of examples where we've spent huge amounts of money on up-front "adequate security," and it's been wasted. It is not full of examples where we've spent huge amounts of money up front, and it's paid off...
Partly, the conventional security industry wisdom fails because it is far too easy for us to hang it all out in the tea-room and make like we actually know what we are talking about in security. It's simply too easy to blather such received wisdom. In the market for silver bullets, we simply don't know, and we share that absence of knowledge with phrases and images that lose meaning for their repitition. In such a market, we end up selling the wrong product for a big price -- payment up front, please!
We are better off -- I assert -- saving our money until the wrong product shows itself to be wrong. Sell the wrong product by all means, but sell it cheaply. Live life a little dangerously, and let a few frauds happen. Ride the GP curve up and learn from your attackers.
But of course, we don't really disagree, as Lynn immediately goes on to say:
Some of this is security proportional to risk ... where it is also fundamental that what may be at risk is correctly identified.
Right.
To close with reference to yesterday's post: Security talk also easily impresses the managerial class, and this is another reason why we need "hackers" to "hack", to use today's unfortunate lingo. A breach of security, rendered before our very servers, speaks for itself, in terms that cut through the sales talk of the silver bullet sellers. A breach of security is a hard fact that can be fed into the above risk analysis, in a world where Spencarian signals abound.
October 05, 2006
How the Classical Scholars dropped security from the canon of Computer Science
Once upon a time we all went to CompSci school and had lots of fun.
Then it all stopped. It stopped at different times at different places, of course, but it was always for the same reason. "You can't have fun," wiggled the finger of some professor talking a lot of Greek.
Well, it wasn't quite like that, but there is a germ of truth in the story. Have a look over at this post (spotted on EC) where the poster declares -- after a long-winded description of the benefits of a classical education -- that the computer science schools should add security to their canons, or core curricula. (Did I get the plurals right? If you know the answer you will have trouble following the rest of this post...)
Teaching someone to validate input is easy. Teaching someone why they need to be rabid about doing it every single time - so that they internalize the importance of security - is hard. It's the ethics and values part of secure coding I really hate having to retrofit, not the technical bit. As it says in Proverbs 22:6, "Train a child in the way he should go, and when he is old he will not turn from it."
This poster has it wrong, and I sense years in the classroom, under the ruler, doing verbs, adverbs and whatnots. No fun at all.
Of course, the reason security is hard is because they -- the un-fun classical scholars -- don't provide any particular view as to why it is necessary, and modern programmers might not be able to eloquently fill in the gap, but they do make very economic decisions. Economics trumps ethics in all known competitions, so talking about "ethics and values of secure coding" is just more Greek.
So what happened to the fun of it all? I speak of those age-old core skills now gone, the skills now bemoaned in the board rooms of just-hacked corporations the world around, as they frown over their SB1386s. To find out happened to them, we have to go back a long time, to a time where titles mattered.
Time was, a junior programmer didn't have a title, and his first skills were listening, coding and frothing.

He listened, he coded and frothed, all under close supervision, and perchance entered the world's notice as a journeyman, being an unsupervised listener, coder and frother.
In those days, the journeyman was called a hacker, because he was capable of hacking some bits and pieces together, of literally making a hack of something. It was a bit of a joke, really, but our hacker could get the job done, and it was better to be known as one than not being known at all. (One day he would aspire to become a guru or a wizard, but that's another story.)
There was another lesser meaning to hacker, which derived from one of the journeyman's core classes in the canon -- breaching security. He was required to attack others' work. Not so as to break it but so as to understand it. To learn, and to appreciate why certain odd things were done in very certain but very odd ways.
Breaching security was not only fun, it was a normal and necessary part of computer science. If you haven't done it, you aren't well rounded, and this is partly why I muck around in such non-PC areas such as poking holes in SSL. If I can poke holes in SSL, so the theory of secure protocols goes, then I'm ready -- perhaps -- to design my own.
Indeed breaching security or its analogue is normal and essential in many disciplines; cryptology for example teaches that you should spend a decade or so attacking others' designs -- cryptanalysis -- before you ever should dare to make your own -- cryptography. Can you imagine doing a civil engineering course without bending some beams?
(Back to the story.) And in due course, when a security system was breached, it became known as being hacked. Not because the verb was so intended, but by process of elimination some hacker had done it, pursuant to his studies. (Gurus did not need to practice, only discuss over cappuccinos. Juniors listened and didn't do anything unless told, mostly cleaning out the Atomic for another brew.)

You can see where we are going now, so I'll hit fast-forward. More time passed ... more learning a.k.a. hacking ... The press grasped the sexy term and reversed the senses of the meaning.
Some company had its security breached. Hacking became annoying. The fun diminishes... Then the viruses, then the trojans, the DDOS, the phishing, the ....
And it all got lumped together under one bad name and made bad. Rustication for some, "Resigned" for others, Jail for some unfortunates.
That's how computer science lost the security skills from the canon. It was dropped from the University curricula by people who didn't understand that it was there for a reason. Bureaucrats, lawmakers, police, and especially corporates who didn't want to do security and preferred to blame others, etc etc, the list of naysayers is very long.
Having stripped it from computer science, we are now in a world where security is not taught, and need to ask: what they suggest in its place:
There are some bright security spots in the academic environs. For example, one professor I talked to at Stanford in the CS department - in a non-security class, no less - had his students "red team" and blue team" their homework, to stress that any and all homework had to be unhackable. Go, Stanford! Part of your grade was your homework, but your grade was reduced if a classmate could hack it. As it should be.
Right, pretend hacking exercises. Also, security conferences. Nice in spirit, but the implementation is a rather poor copy of the original. Indeed, if you think about the dynamics of hacking games and security conferences ("Nobody ever got hacked going to Blue Hat??") we aren't likely to sigh with relief.

And then:
One of my colleagues in industry has an even more draconian (but necessary) suggestion for enforcing change upon universities. ... He decided that one way to get people's attention was to ask Congress to tie research funds to universities to changing the computer science curriculum. I dare say if universities' research grants were held up, they might find the extra time or muster the will to change their curricula!
Heaven help us! Are we to believe that the solution to the security training quandary is to ask the government to tell us how to do security training? Tell me this is a joke, and the Hello Kitty People haven't taken over our future:
The Hello Kitty people are those teenagers who put their personal lives on MySpace and then complain that their privacy is being violated. They are the TV viewers who think that the Hurricane Katrina rescue or the Iraq war were screwed up only because we don't, they belatedly discover, have actual Hello Kitties in political power. When inevitably some of world's Kitties, unknown beyond their cute image, turn out to be less than fully trustworthy, the chorus of yowling Kitty People becomes unbearable cacophony.
(We've written before about how perhaps the greatest direct enemy of Internet security is the government, so we won't repeat today.)
Here is a test. A corporation such as Oracle could do this, instead of blaming the government or the hackers or other corporations for its security woes. Or Microsoft could do it, or anyone, really.
Simply instruct all your people to breach security. Fill in the missing element in the canon. Breach something, today, and learn.
Obviously, the Greeks will complain about the errant irresponsibility of such support for crime ... but just as obviously, if they were to do that, their security knowledge would go up by leaps and bounds.
Sadly, if this were taken seriously, modern corporations such as Oracle would collapse in a heap. It's far cheaper to drop the training, blame "the hackers" and ask the government for a subsidy.
Even more sadly, we just don't have a better version of training than "weapons free." But let's at least realise that this is the issue: you classicals, you bureaucrats, you Sonys and Oracles and Suns, you scared insecure corporations have brought us to where we are now, so don't blame the Universities, blame yourselves.
And, in the name of all that is sacred, *don't ask the government for help!*
September 13, 2006
NFC - telco operators get another chance at innovation
Dave Birch posts on telco operators in Britain and NFC -- near field communications. You should read the lot, but here's most of it as it's mostly FC:
I think they are alluding to a tussle between service providers (eg, banks) and mobile operators over NFC. The mobile operators want everything to go through the SIM, generally speaking, including NFC applications. This frames NFC applications in the kind of portal strategy that was so successful for the operators when they introduced WAP. Naturally, the service providers want NFC applications to be directly addressable without going through the SIM, so that anyone can load any NFC application into their phone.I have to say that my sympathies are with the service providers here. We've been having fun building and loading NFC applications for a variety of clients using -- for instance -- the Nokia NFC phone (see diagram below) and it would be crazy to have get permission from (or, indeed, pay) an operator to load a new application: it would kill creativity.
In fact, I'm sure it would it be bad (even for the operators) to have NFC locked down by the operators. For one thing, contactless payments are only one potential use of NFC phones and the operators should not let this one application (and the ideaof charging banks a transaction fee) to dominate their roadmap. There is a much bigger picture, which is around the integration of mobile phones into their local environments. Look at smart posters, as an obvious example: we've been playing with these for a while now. Incidentally, one of the demonstrations that we will be presenting at the Intelligent Transport Systems World Congress in London next month allows someone to find out a bus timetable by holding their phone up to a poster at a bus stop and then subsequently buy a ticket by waving their phone over a "purchase ticket" label (we'll also be demonstrating phone-to-phone transfer of tickets, which is pretty interesting). Anyway, the point is that no-one accesses these kinds of services by typing URLs into WAP screens: no smart posters means no servicediscovery and therefore no data usage.
We saw this same process with WAP. Some people tried and were constrained (notably, e-gold did WAP based payments from 1999 onwards). Other people didn't bother, as it was clear from the outside that the control structure was too tight to innovate.
So telco operators get another chance with NFC. Will they try (and fail) to control NFC or destroy it in the attempt? As Dave indicates, getting "Internet" thinking to telcos is no easy sale.
I think the answer is they will fail to control it. The reason for this is that there are enough rebel handset manufacturers out there now; there are even, I am told, handsets that can route calls through bluetooth and VoIP (the shame! the horror!). An open market will counter-balance control attempts, and NFC will just become another option independent of the network.
September 07, 2006
The one secure mode; Thunderbird would meet Kerckhoffs' 6th; and how easy it is to make it secure...
While on the conjunction of Mozo tools and security, woeful or otherwise ... a month or so back I used Thunderbird as a foil to introduce a hypothesis (which you can call a law when I'm dead):
* There is only one mode, and it's secure. *
Predictably, most people thought I was grumbling "about Thunderbird", when in fact I was grumbling about the brain-dead insecurity known as PKI.
Unfortunately, Thunderbird has a great name, but the security thing it follows does not. The absolutely dire architecture loosely and variously known as S/MIME or x.509 identity certificates, as applied to email, provides a textbook case of how a system breaches Kerckhoffs' 6th law -- that the system should be usable -- and therefore is bypassed by the users. As this is his most important law by far (by simple economic proof, if you wish to demur) the system is insecure, and the 5 lesser Kerckhoffs do not enter into the discussion.
I also pointed out that I had two newbies up and going in 3 minutes flat with Skype - both with next to no help (over some other chat thing like ICQ). So let's call that the benchmark for a superlative security solution that meets Kerckhoffs' 6th law.
Which leads me to last night's observation - Jimbo, a moderately experienced computer person, downloaded, installed and was sending and receiving email with Thunderbird within 10 minutes. "Less probably," he says, which was welcome relief after debugging what turned out to be an Microsoft Outlook failure brought on by a re-install of Microsoft Office. About an hour, times two, wasted, but at least we got another Tbird flying in <10mins.
From which we can conclude that Thunderbird is in the ballpark, that's actually a good result, albeit with no security. We could suggest that Thunderbird would potentially meet Kerckhoffs' 6th if it could boot up in some sort of quasi-secure mode (even though it and every other mailer won't meet my hypothesis and probably never will, due to the tired and aged infrastructure of email).
So, why is this important? Well, it's important because there are some relatively simple fixes to put in that would bring an x.509 identity based mail agent closer to being in line with modern security thinking (if we can stretch the point with the late19th century).
Here they are:
- The client creates a self-signed key/cert for every account.
- Automatically, no questions asked, user not told.
- The self-singed cert is marked "mail encryption only" to distinguish it from "person signing."
- All mails are sent out signed&cert attached, by default.
- Mails incoming are scanned for clues - certs - as to whether encryption can be used.
- Those recipients for whom we have certs are sent encrypted email.
- If an encrypted email is sent or received, colour it pretty. Reward the user. Not that funny little icon, but something much better.
The key is to be opportunistic, pun intended. By creating and adding the missing key, we bootstrap from nothing -- insecure comms -- to a security level which is good-enough-for-most-folks.
Let's step back and put this in context. The above simple crypto mechanism is better than the alternate as it encrypts when it can. The alternate is nothing, recall. Yet, some might say that it is worse than the PKI alternate, to which I say: comparing real world user comms -- email in flight -- to some paper ideal is an irrelevant comparison.
Keep in mind that the alternate is no crypto email, due to the immutable K6. If however you are one of those unfortunate souls locked in the world of PKI, and/or to die in the attempt, this method comes with an added bonus:
- It's ok to point out that the opportunistic key is a self-signed, non-identified cert.
- Allow easy replacement of the opportunistic key!
- It would be ok to provide a link there to *upgrade* the cert to something better.
I don't want to stress the last point, above. Perhaps that's because I audit a CA in my spare time (can you say conflict of interest?), or perhaps because I have a fairly pessimistic view of the ability of the players to deliver something the market wants. Or perhaps I don't want to encourage software suppliers to do yet more secret deals with yet more opaque partners which users can't control or even have reasonable security expectations about? Who knows...
But, notwithstanding all the above, points 1 thru 5 will approximately deliver a startup that gets a Thunderbird client into something like secure comms some of the time. And once something like that is done, there are plenty of ways to *improve* that to get more crypto, more of the time, more securely.
I wonder if it could be done with a plugin?
September 06, 2006
Introducing the new HavenCo location...
After SeaLand burnt up a month or so back ...

... we've been on the lookout for a new site for an ultra-cool offshore datahaven. And now we're proud to announce we've found it:
US missile defence radar hits stormy seas - $815m behemoth flounders - By Lester HainesThe Sea-Based X-Band Radar. Photo: BoeingThe future of the US's much-hyped, $815m Sea-Based X-Band Radar (SBX) platform is in serious doubt after a raft of sceptics expressed doubts that the sea monster could ever effectively operate in its intended final mooring off Alaska's Aleutian Islands.
Check it out ...

Is that the mother of all radomes, or what?
July 30, 2006
smart cards with displays - at last!
Jane Adams reports over on the Digital Money blog:
Now Visa International is working with InCard Technologies, an American company that has come up with something called Power Inlay Technology. The result is a smart card with a screen (or a smart card with a built in light or one that plays annoying jingles - isn't technology wonderful?) and a random number generator. That means the card is capable of generating a dynamic cvv2 for example.
Hoping over to InCardTech, we find, right down the bottom of the page:
 | DisplayCard with Additional Information
Depending on the type of payment card in question, a wealth of information useful to the consumer can be conveyed on an easy to read display. All this at the consumers fingertips!
Offering you what you need to know, when you need to know it. |
Potentially interesting! What does this mean? Jane says:
It doesn't come with a keypad yet but Visa seems confident that it will.What does that mean? That means that the arguments about who pays for readers for token based authentication for secure sign on to online banking will become redundant. Who needs a reader if you can tap your PIN directly into the card and the card itself displays your one time passcode?
Whoa, slight confusion there. You still need a reader ... to communicate with the smart card. What you don't necessarily need, in the fullness of time, is an expensive Class 4 secured reader, with its own display, keypad and Go button.
So while this will eliminate some costs, indeed a major cost, costs will remain.
And those costs are still rather traumatic, especially in comparison to your other smart card that already comes with its secure reader, including display and keypad, and soon to include GPS and other handy dandy tracking tools. (your cell/mobile/handy.) So while this may eventually cause smart cards to be independently useful in some universe, I'd suspect it is too little, too late at this stage.
| Also from the Maginot product line, they even have a one time pad card. |  |
July 23, 2006
Case Study: Thunderbird's brittle security as proof of Iang's 3rd Hypothesis in secure design: there is only one mode, and it's secure.
In talking with Hagai, it was suggested that I try using the TLS/IMAP capabilities of Thunderbird, which I turned on (it's been a year or two since the last time I tried it). Unfortunately, nothing happened. Nothing positive, nothing negative. Cue in here a long debate about whether it was working or not, and how there should be a status display, at least, and various other remedies, at most.
A week later, the cleaning lady came in and cleaned up my desk. This process, for her, also involves unpowering the machine. Darn, normally I leave it on for ever, like a couple of months or so.
On restarting everything, Thunderbird could not connect to the mail servers. Our earlier mystery is thus resolved - the settings don't take effect until restart. Doh!
So, how then did Thunderbird handle? Not so well, but it may have got there in the end. This gives me a change to do a sort of case study in 1990s design weaknesses, a critique in (un)usability, leading to design principles updated for this decade.
To predict the punch line, the big result is that there should only be one mode, and it should be secure. To get there more slowly, here's what I observed:
Firstly, Thunderbird grumbled about the certificate being in the wrong name. I got my negative signal, and I knew that there was something working! Hooray!
But, then it turned out that Thunderbird still could not connect, because "You have chosen secure authentication, but this server does not offer it. Therefore you cannot log in..." Or somesuch. Then I had to go find that option and turn it off. This had to be done for all mail accounts, one by one.
Then it worked. Well, I *guess* it did... because funnily enough it already had the mail, and again had not evidenced any difference.
Let's break this up into point form. Further, let's also assume that all competing products to be as bad or worse. I actually *choose* Thunderbird as my preferred email client, over say Kmail. So it's not as bad as it sounds; I'm not "abandoning Thunderbird", I'm just not getting much security benefit from it, and I'm not recommending it to others for security purposes.
- No caching of certs. There is no ability to say "Yes, use that cert for ever, I do know that the ISP is not the same name as my domain name, dammit!!!!" This is an old debate; in the PKI world, they do not subscribe to the theory that the user knows more than any CA about her ISP. One demerit for flat earth fantasies.
- No display anywhere that tells me what the status of the security is. One demerit. (Keep in mind that this will only be useful for us "qualified cryptoplumbers" who know what the display means.)
- I can choose "secure authentication" and I can choose "secure connection." As a dumb user, I have no idea what that means, either of them. One demerit.
- If I choose one of those ON, and it is not available, it works. Until it doesn't -- it won't connect at some later time and it tells me to turn it off. So as a user I have a confusing choice of several options, but ramifications that do not become clear until later.
Another demerit: multiple options with no clear relationship, but unfortunate consequences.
- Once it goes wrong, I have to navigate from a popup telling me something strange, across to a a series of boxes in some other strange area, and turn off the exact setting that I was told to, if I can remember what was on the popup. Another demerit.
- All this took about 5 minutes. It took longer to do the setting up of some security options than it takes to download, install, and initiate an encrypted VoIP call over Skype with someone who has *never used Skype before*. I know that because the previous night I had two newbies going with Skype in 3 minutes each, just by talking them through it via some other chat program.
- Normal users will probably turn it all off, as they won't understand what's really happening, and "I need my mail, darnit!"
(So, we now start to see what "need" means when used by users... it means "I need my email and I'll switch the darned security rubbish off and/or move to another system / supplier / etc.)
- This system is *only useable by computer experts.* The only reason I was able to "quickly" sort this out was because I knew (as an experienced cryptoplumber) exactly what it was trying to do. I know that TLS requires a cert over the other end, *and* there is a potential client-side cert. But without that knowledge, a user would be lost. TLS security as delivered here is a system is not really up to use by ordinary people - hence "brittle."
We can conclude that this is a nightmare in terms of:
- usability.
- implementation.
- design.
- standards.
Let's put this in context: when this system was designed, we didn't have the knowledge we have now. Thunderbird's security concept is at least 3 years old, probably 8-10 years old. Since those years have passed, we've got phishing, usability studies, opportunistic crypto, successful user-level cryptoapps (two, now), and a large body of research that tells us how to do it properly.
We know way more than we did 3 years ago - which was when I started on phishing. (FTR, I suggested visit counts! How hokey!)
Having got the apologies off our chest, let's get to the serious slamming: If you look at any minor mods to the Thunderbird TLS-based security, like an extra popup, or extra info or displays, you still end up with a mess. E.g., Hagai suggested that there should be an icon to display what is going on - but that only helps *me* being an experience user who knows exactly what it is trying to tell me. I know what is meant by 'secure authentication' but if you ask grandma, she'll offer you some carrot cake and say "yes, dear. now have some of this, I grew the carrots myself!"
(And, in so doing, she'll prove herself wiser than any of us. And she grows carrots!)
Pigs cannot be improved by putting them in dresses - this security system is a pig and won't be improved by frills.
The *design* is completely backwards, and all it serves to do is frustrate the use of the system. The PKI view is that the architecture is in place for good reasons, and therefore the user should be instructed and led along that system path. Hence,
"We need to educate the users better."
That is a truly utterly disastrous recommendation. No! Firstly, the system is wrong, for reasons that we can skip today. Secondly, the technical choices being offered to the users are beyond their capabilities. This can never be "educated." Thirdly, it's a totally inefficient use of the user's time. Fourthly, the end effect is that most users will not ever get the benefit.
(That would be a mighty fine survey -- how many users get the benefit of TLS security in Thunderbird? If it is less than 10%, that's a failure.)
The system should be reversed in logic. It should automatically achieve what it can achieve and then simply display somewhere how far it got:
- Try for the best, which might be secure auth, and then click into that. Display "Secure Auth" if it got that far.
- If that fails, then, fallback to second best: try the "Secure Conn" mode, and display that on success.
- Or finally, fall back to password mode, and display "Password only. Sorry."
The buttons to turn these modes on are totally unneccessary. We have computers to figure that sort of nonsense out.
Even the above is not the best way. Fallback modes are difficult to get right. They are very expensive, brittle even. (But, they are better - far far far cheaper - than asking the user to make those choices.) There is still one way to improve on this!
Hence, after 5 demerits and a handful of higher-level critiques, we get to the punchline:
To improve, there should only be one mode. And that mode is secure. There should be only one mode, because that means you can eliminate the fallback code. Code that falls back is probably twice as large as code that does not fallback. Twice as brittle, four times as many customer complaints. I speak from experience...
The principle, which I call my 3rd Hypothesis in Secure Protocol Design, reads like this:
There is only one mode, and it is secure.
If you compare and contrast that principle with all the above, you'll find that all the above bugs magically disappear. In fact, a whole lot of your life suddenly becomes much better.
Now, again, let's drag in some wider context. It is interesting that email can never ever get away from the fact that it will always have this sucky insecure mode. Several of them, indeed. So we may never get away from fallbacks, for email at least.
That unfortunate legacy should be considered as the reality that clashes with the Hypothesis. It is email that breaches the Hypothesis, and it and all of us suffer for it.
There is no use bemoaning the historical disaster that is email. But: new designs can and will get it right. Skype has adopted this Hypothesis, and it took over - it owns VoIP space in part because it delivered security without the cost. SSH did exactly the same, before.
In time, other communication designs such as for IM/chat and emerging methods will adopt Hypothesis #3, and they will compete with Skype. Some of the mail systems (Start/TLS ?) have also adopted it, and where they do, they do very well, allegedly.
(Nobody can compete with SSH, because we only need one open source product there - the task is so well defined there isn't any room for innovation. Well, that's not exactly true - there are at least two innovations coming down the pipeline that I know of but they both embrace and extend. But that's topic drift.)
July 09, 2006
Phishing for SNI progress - tantalisingly close?
SNI is slowly coming to fruition. Quick reminder: SNI is the extension that supports multiple SSL servers on the same machine, and is one huge barrier to the routine employment of TLS as an aid against phishing and other threats.
Googling around I found that Apache 2.2.0 may be slated to support SNI. This is important -- until Apache or the Microsoft equivalent supports it as shipped, we will be blocked as browsers will be waiting, waiting, ...
Over on ThoughtTorrent, Nik says that most browsers are good already or are going to be ready to support. What's missing is Apple's Safari. Shocking! File a bug:
Title: Support for TLS Server Name Indication (RFC 3546)Summary: This is a request for server name indication (SNI) support, per RFC 3546. It's basically TLS' equivalent of the Host header, allowing the correct SSL certificate to be served when multiple domains share the same IP address.
Steps to Reproduce: Connect to a server that supports SNI.
Expected Results: A perfectly normal hello is sent.
Actual Results: An extended hello, with a server_name extension.
Regression: This occurs consistently in my tests using Safari/WebKit as frontends.
Notes: There is a test server available at https://sni.corelands.com/
Other browsers support this:
- Opera 8.0
- Internet Explorer 7, beta 2
- Firefox 2.0
- Konqueror 4.0
Granted, the last three aren't released yet, but it does show that support is widespread.
But you need an Apple user account to do this. Bummer! Has anyone got one?
Someone else is also running test servers:
https://sni.velox.ch https://alice.sni.velox.ch https://carol.sni.velox.ch https://bob.sni.velox.ch https://dave.sni.velox.ch https://mallory.sni.velox.ch https://www.sni.velox.ch https://test.sni.velox.ch
What more needs to be done? Does Apache need some help in getting this done? Given the importance of spreading more websites to TLS usage (so we can use the certs to deal with phishing on a routine basis) this is one of those projects where it is worth it to go the distance, identify the blockages and see what we can do to remove them.
(I note that Frank has posted more information on the Mofo grants project. Here's a totally random thought .... Is there merit in sponsoring a TLS/SNI compatibility meet? A bit like George's of last year...)
June 27, 2006
It's official! SSH whips HTTPS butt! (in small minor test of no import....)
Finally some figures! We've known for a decade that the SSH model consumes all in its path. What we haven't known is relative quantities. Seen somewhere on the net, this week's report shows Encrypted Traffic. In SSH form: 3.42% In HTTPS form: 1.11%, by volume. For number of packets, it is 3.51 and 1.67 respectively.
| SSH | 3.42% | 17.45T | 3.51% | 20.98% |
|---|---|---|---|---|
| HTTPS | 1.11% | 5.677T | 1.67% | 10.00G |
| IPsec ESP | 0.14% | 0.697T | 0.21% | 1.211G |
| IPsec AH | 0.01% | 0.054G | 0.01$ | 0.089G |
| IPsec IKE | 0.00% | 0.001G | 0.00% | 0.006G |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Approximately a three times domination which is our standard benchmark for a good whipping in military terms. Although this is not a pitched battle of like armies contesting the same space (like the VPN bloodletting to come) it is important to establish that SSH usage is significant, non trivial and exceeds HTTPS on all measures.
IPsec barely twitched the needle and others weren't reported. Curiously, the amount of HTTPS is way up compared to HTTP: about 7-8%. I would have expected much less, the many silent but resiliant readers of FC have more impact than previously thought.
There's one monster catch: this is "Internet 2" which is some weird funded different space, possibly as relevant to the real net as candy prices are to the economy. Also, no mention of Skype. Use of Rsync and FTP slightly exceeds that of all encrypted traffic. Hmmm.... people still use Rsync. What is wrong here? I have not come across an rsync user since ... since ... Any clues?
Still it's a number. Any number is good for an argument.
June 25, 2006
FC++3 - Dr Mark Miller - Robust Composition: Towards a Unified Approach to Access Control and Concurrency Control
Financial cryptographer Mark Miller has finished his PhD thesis, formally entitled Robust Composition: Towards a Unified Approach to Access Control and Concurrency Control.
This is a milestone! The thrust of Dr Miller's work could be termed as "E: a language for financial cryptography applications." Another way of looking at it could be "Java without the bugs" but that is probably cutting it short.
If this stuff was in widespread usage, we would probably reduce our threat surface area by 2 orders of magnitude. You probably wouldn't need to read the other two papers at all, if.
http://www.erights.org/talks/thesis/
http://www.caplet.com/
AbstractWhen separately written programs are composed so that they may cooperate, they may instead destructively interfere in unanticipated ways. These hazards limit the scale and functionality of the software systems we can successfully compose. This dissertation presents a framework for enabling those interactions between components needed for the cooperation we intend, while minimizing the hazards of destructive interference.
Great progress on the composition problem has been made within the object paradigm, chiefly in the context of sequential, single-machine programming among benign components. We show how to extend this success to support robust composition of concurrent and potentially malicious components distributed over potentially malicious machines. We present E, a distributed, persistent, secure programming language, and CapDesk, a virus-safe desktop built in E, as embodiments of the techniques we explain.
Advisor: Jonathan S. Shapiro, Ph.D.
Readers: Scott Smith, Ph.D., Yair Amir, Ph.D.
Presented here as the lead article in FC++. Mark's generous licence:
Copyright © 2006, Mark Samuel Miller. All rights reserved.
Permission is hereby granted to make and distribute verbatim copies of this document without royalty or fee. Permission is granted to quote excerpts from this documented provided the original source is properly cited.
June 10, 2006
Naked Payments I - New ISO standard for payments security - the Emperor's new clothes?
[Anne & Lynn Wheeler do a guest post to introduce a new metaphor! Editorial note: I've done some minor editorial interpretations for the not so eclectic audience.]
From the ISO, a new standard aims to ensure the security of financial transactions on the Internet:
ISO 21188:2006, 'Public Key Infrastructure for financial services - practices and policy framework', offers a set of guidelines to assist risk managers, business managers and analysts, technical designers and implementers and operational management and auditors in the financial services industry.
My two bits [writes Lynn], in light of recent British pin&chip vulnerability thread, is to consider another metaphor for viewing the session authentication paradigm: They tend to leave the transaction naked and vulnerable.
In the early 1990s, we had worked on the original payment gateway for what become to be called e-commerce 1, 2 (as a slight aside, we also assert it could be considered the first SOA implementation 3 - Token-ring vs Ethernet - 10 years later ).
To some extent part of the transaction vulnerability analysis for x9.59 transaction work done in the mid-90s was based on analysis and experience with that original payment gateway as it was implemented on the basis of the session-oriented paradigm 4.
This newer work resulted in something that very few other protocols did -- defined end-to-end transactions with strong authentication. Many of the other protocols would leave the transaction naked and vulnerable at various steps in the processing. For example, session-oriented protocols would leave the entire transaction naked and vulnerable. In other words, the bytes that represent the transaction would not have a complete end-to-end strong authentication related to exactly that transaction, and therefore leave it naked and vulnerable for at least some part of the processing.
This then implies that the complete end-to-end business process has to be heavily armored and secured, and even minor chinks in the business armoring would then result in exposing the naked transaction to the potental for attacks and fraud.
If outsider attacks aren't enough, naked transactions are also extremely vulnerable to insider attacks. Nominally, transactions will be involved in a large number of different business processes, exposing them to insider attacks at every step. End-to-end transactions including strong authentication armors the actual transaction, and thus avoids leaving the transaction naked and vulnerable as it travels along a vast array of processing steps.
The naked transaction paradigm also contributes to the observation that something like seventy percent of fraud in such environments involve insiders. End-to-end transactions with strong authentication (armoring the actual transaction) then also alleviates the need for enormous amounts of total business process armoring. As we find it necessary to protect naked and vulnerable transactions, we inevitably find that absolutely no chinks in the armor can be allowed, resulting in expensive implications in the business processing - the people and procedures employed.
The x9a10 working group (for what become the x9.59 financial standard) was given the requirement to preserve the integrity of the financial infrastructure for all retail payments. This meant not only having countermeasures to things like replay attacks (static data that could be easily skimmed and resent), but also having end-to-end transaction strong authentication (eliminating the vulnerabilities associated with having naked and vulnerable transactions at various points in the infrastructure).
The x9.59 financial standard for all retail payments then called for armoring and protecting all retail transactions. This then implied the business rule that account numbers used in x9.59 transactions could not be used in transactions that didn't have end-to-end transaction strong authentication. This eliminated the problem with knowledge leakage; if the account number leaked, it no longer represents a vulnerability. I.e. an account number revealed naked was no longer vulnerable to fraudulent transactions 5.
Part of the wider theme on security proportional to risk is that if the individual transactions are not armored then it can be extraordinarily expensive to provide absolutely perfect total infrastructure armoring to protect naked and vulnerable transactions. Session-hiding cryptography especially is not able to absolutely guarantee that naked, vulnerable transactions have 100% coverage and/or be protected from all possible attacks and exploits (including insider attacks) 6.
There was yet another issue with some of the payment-oriented protocols in the mid-90s looking at providing end-to-end strong authentication based on digital signature paradigm. This was the mistaken belief in appending digital certificates as part of the implementation. Typical payment transactions are on the order of 60-80 bytes, and the various payment protocols from the period then appended digital certificates and achieved a payload bloat of 4k to 12k bytes (or a payload bloat of one hundred times). It was difficult to justify an enormous end-to-end payload bloat of one hundred times for a redundant and superfluous digital certificate, so the protocols tended to strip the digital certificate off altogether, leaving the transaction naked and vulnerable during subsequent processing.
My response to this was to demonstrate that it is possible to compress the appended digital certificates to zero bytes, opening the way for x9.59 transactions with end-to-end strong authentication based on digital signatures. Rather than viewing x9.59 as using certificate-less digital signatures for end-to-end transaction strong authentication, it can be considered that an x9.59 transaction appends a compressed zero-byte digital certificate to address the severe payload bloat problem 7.
To return briefly to Britain's Chip&Pin woes, consider that the issue of SDA (static data authentication vulnerable to replay attacks) or DDA (countermeasure to replay attacks) is somewhat independent of using a session-oriented implementation. That is, the design still leaves transactions naked and vulnerable at various points in the infrastructure.
- Naked Payments I - New ISO standard for payments security - the Emperor's new clothes?
- Naked Payments II - uncovering alternates, merchants v. issuers, Brits bungle the risk, and just what are MBAs good for?
- Naked Payments III - the well-dressed bank
- Naked Payments IV - let's all go naked
May 24, 2006
Opera talks softly about user security
Opera talks about security features in Opera 9. The good parts - they have totally rewritten their protocol engine, and:
3. We have disabled SSL v2 and the 40 and 56 bit encryption methods supported by SSL and TLS.
The somewhat silly part, they've added more warnings for use of 40 and 56 bit ciphers, but forgotten to warn about that popular zero-bit cipher called HTTP.
The slow part - it must have been two years since we first started talking about it to get to now: SSLv2 in Opera 9 disabled, and TLS Extensions enabled. (SNI itself is not mentioned. I forget where the other suppliers are on this question.)
Why so long?
2. TLS 1.1 and TLS Extensions are now enabled by default.When we tested these features in Opera 7.60 TP in September 2004, our users found 100+ sites that would not work with either or both of these features. So why enable these features now, have we lost our minds?
The reason isn't that the problematic sites have disappeared. Unfortunately, they haven't. The reason we are activating these features now is that we have worked around the problems.
It makes me giddy, just thinking about those 100 sites ... So Opera backed off, just like the others. The reason that this is taking so long is that as far as your average browser goes, security is a second or third priority. Convenience is the priority. Opera's page, above, has lots of references to how they want to be fully standards compliant etc etc, which is good, but if you ask them about security, they'll mumble on about irrelevancies like bits in algorithms and needing to share information with other browsers before doing anything.
SSL v2, originally developed by Netscape, is more than 11 years old. It was replaced by SSL v3 (also developed by Netscape) in 1996. SSL v2 is known to have at least one major weakness. And considering the age of the servers that only supports SSL v2, one can certainly wonder how secure the servers themselves are.Some may wonder why disabling an outdated protocol is news. *Shouldn't these "features" have been removed long ago?*
I like standards as much as the next guy, and I use a browser that is proud of user experience. I even suggest that you use for its incidental security benefits - see the Top Tips on the front page!
But when it comes to protecting people's online bank accounts, something has to break. Is it really more important to connect to a hundred or a thousand old sites than it is to protect users from security attacks from a thousand phishers or a hundred thousand attacks?
The fact is, as we found out when we tried to disable these methods during the 7.60 TP and 8.0 Beta testing, that despite both the new versions of the protocol and the SSL v2 protocol's security problems, there were actually major sites using it as their single available SSL version as recently as a year ago! It is actually only a few years since a major US financial institution upgraded their servers from SSL v2 to TLS 1.0. This meant that it was not practical from a usability perspective to disable the protocol.
Come on guys, don't pussy foot around with user security! If you want to get serious, name names. Pick up the big stick and wack those sites. If you're not serious, then here's what is going to happen: government will move in and pass laws to make you liable. Your choice - get serious or get sued.
The connection between all this dancing around with TLS and end-user security is a bit too hard to see in simple terms. It is all to do with SNI - server name indication. This is a feature only available in TLS. As explained above, to use TLS, SSLv2 must die.
Once we get SNI, each Apache server can *share* TLS certificates for multiple sites over one single IP number. Right now, sharing TLS sites is clumsy and only suitable for the diehards at CAcert (like this site is set up, the certs stuff causes problems). This makes TLS a high-priced option - only for "e-commerce" not for the net masses. Putting each site over a separate IP# is just a waste of good sysadmin time and other resources, and someone has to pay for that.
(Do you think the commerciality of the equation might explain the laggardness of browser manufacturers here?)
With SNI, using TLS then has a goodly chance of becoming virtual - like virtual HTTP sites sometimes called VHosts. Once we start moving more web servers into TLS _by default_, we start to protect more and more ... and we shift the ground of phishing defence over to certificates. Which can defend against phishing but only if used properly (c.f. toolbars).
Yes, I know, there are too many steps in that strategy to make for easy reading. I know, we already lost the battle of phishing, and it has moved into the Microsoft OS as the battleground. I know, TLS is bypassed as a security system. And, I know, SSL was really only for people who could pay for it anyway.
Still, it would be nice, wouldn't it? To have many more sites using crypto by default? Because they can? Imagine if websites were like Skype - always protected? Imagine how much easier it would be to write software - never needing to worry about whether you are on the right page or not.
And if that's not convincing, consider this: what's happening in "other countries" is coming to you. Don't be the one to hold back ubiquitous, opportunistic crypto. You might be reading about RIP and massive datamining in the press today about other countries; in a decade or so you'll be reading about their unintended victims in your country, and you will know the part you played.
In other crypto news:
Microsoft buys SSL VPN vendor Whale
http://www.computerworld.com/action/article.do?command=viewArticleBasic&articleId=9000608
Government to force handover of encryption keys
http://news.zdnet.co.uk/0,39020330,39269746,00.htm
UK law will criminalise IT pros, say experts
http://news.zdnet.co.uk/business/legal/0,39020651,39270045,00.htm
May 22, 2006
It is no longer acceptable to be complex
Great things going on over at FreeBSD. Last month was the surprising news that Java was now distro'd in binary form. Heavens, we might actually see Java move from "write once, run twice" to numbers requiring more than 2 bits, in our lifetimes. (I haven't tried it yet. I've got other things to do.)

More serious is the ongoing soap opera of security. I mean over all platforms, in general. FreeBSD still screams in my rankings (sorry, unpublished, unless someone blogs the secret link again, darnit) as #2, a nose behind OpenBSD for the top dog spot in the race for hard core security. Here's the story.
Someone cunning (Colin?) noticed that a real problem existed in the FreeBSD world - nobody bothers to update, and that includes critical security patches. That's right. We all sit on our haunches and re-install or put it off for 6-12 months at a time. Why?
Welll, why's a tricky word, but I have to hand it to the FreeBSD community - if there is one place where we can find out, that's where it is. Colin Percival, security czar and general good sort, decided to punch out a survey and ask the users why? Or, Why not? We haven't seen the results of the survey, but something already happened:
Polite, professional, thoughtful debate.
No, really! It's unheard of on an Internet security forum to see such reasoned, considered discussion. At least, I've never seen it before, I'm still gobsmacked, and searching for my politeness book, long lost under the 30 volume set of Internet Flames for Champions, and Trollers Almanacs going back 6 generations.
A couple of (other) things came out. The big message was that the upgrade process was either too unknown, too complex, too dangerous, or just too scary. So there's a big project for FreeBSD sitting right there - as if they need another. Actually this project has been underway for some time, it's what Colin has been working on, so to say this is unrecognised is to short change the good work done so far.
But this one's important. Another thing that delicately poked its nose above the waterline was the contrast between the professional sysadmin and the busy other guy. A lot of people are using FreeBSD who are not professional sysadmins. These people haven't time to explore the arcania of the latest tool's options. These people are impressed by Apple's upgrade process - a window pops up and asks if it's a good time, please, pretty please? These people not only manage a FreeBSD platform or 10, but they also negotiate contracts, drive buses, organise logistics, program big apps for big iron, solve disputes with unions and run recruiting camps. A.k.a., business people. And in their lunchbreaks, they tweak the FreeBSD platforms. Standing up, mouth full.
In short, they are gifted part-timers. Or, like me, trained in another lifetime. And we haven't the time.
So it is no longer - I suggest - acceptable for the process of upgrades and installs to be seriously technical. Simplification is called for. The product is now in too many places, too many skill sets and too many critical applications to demand a tame, trained sysadmin full time, right time.
Old hands will say - that's the product. It's built for the expert. Security comes at a cost.
Well, sort of - in this case, FreeBSD is hoisted on its own petard. Security comes at a risk-management cost. FreeBSD happens to give the best compromise for the security minded practitioner. I know I can install my machine, not do a darn thing for 6 months, and still be secure. That's so valuable, I won't even bother to install Linux, let alone look up the spelling of whatever thing the Microsoft circus are pushing this month. I install FreeBSD because I get the best security bang for buck: No necessary work, and all the apps I can use.
Which brings us to another thing that popped out of the discussion - every one of the people who commented was using risk management. Seriously! Everyone was calculating their risk of compromise versus work put in. There is no way you would see that elsewhere - where the stark choice is either "you get what you're given, you lucky lucky microsoft victim" all the way across to the more colourful but unprintable "you will be **&#$&# secure if you dare *@$*@^# utter the *#&$*#& OpenBSD install disk near your (*&@*@! machine in vein."
Not so on FreeBSD. Everyone installs, and takes on their risks. Then politely turns around and suggests how it would be nice to improve the upgrade process, so we can ... upgrade more frequently than those big anniversaries.
May 20, 2006
Indistinguishable from random...
(If you are not a cryptoplumber, the following words will be indistinguishable from random... that might be a good thing!)
When I and Zooko created the SDP1 layout (for "Secure Datagram Protocol #1") one of the requirements wasn't to avoid traffic analysis. So much so that we explicitly left all that out.
But, the times, they are a-changing. SDP1 is now in use in one app full-time, and 3 other apps are being coded up. So I have more experience in how to drive this process, and not a little idea about how to inform a re-design.
And the war news is bleak, we are getting beaten up in Eurasia. Our boys over there sure could use some help.
So how to avoid traffic analysis? A fundamental way is to be indistinguishable from random, as that reveals no information. Let's revisit this and see how far we can get.
One way is to make all packets around the same size, and same frequency. That's somewhat easy. Firstly, we expand out the (internal) Pad to include more mildly random data so that short packets are boosted to the average length. There's little we can do about long packets, except break them up, which really challenges the assumptions of datagrams and packet-independence.
Also, we can statistically generate some chit chat to keep the packets ticking away ... although I'd personally hold short of the dramatically costly demands of the Freedom design, which asked you to devote 64 or 256k permanent on-traffic to its cause. (A laughable demand, until you investigate what Skype is doing, now, successfully, on your computer this very minute.)
But a harder issue is the outer packet layer as it goes over the wire. It has structure, so someone can track it and learn information from it. Can we get rid of the structure?
The consists of open network layout consists of three parts - a token, a ciphertext and a MAC.
| Token | . . . enciphered . . . text . . . | SHA1-HMAC |
Each of these is an array, which itself consists of a leading length field followed by that many bytes.
| Length Field | . . . many . . . bytes . . . length . . . long . . . |
(Also, in all extent systems, there is a leading byte 0x5D that says "this is an SDP1, and not something else." That is, the application provides a little wrapping because there are cases where non-crypto traffic has to pass.)
| 5D |
|
|
|
Those arrays were considered necessary back then - but today I'm not so sure. Here's the logic.
Firstly the token creates an identifier for a cryptographic context. The token indexes into the keys, so it can be decrypted. The reason that this may not be so necessary is that there is generally another token already available in the network layer - in particular the UDP port number. At least one application I have coded up found itself having to use a different port number (create a new socket) for every logical channel, not because of the crypto needs, but because of how NAT works to track the sender and receiver.
(This same logic applies to the 0x5D in use.)
Secondly, skip to the MAC. This is in the outer layer - primarily because there is a paper (M. Bellare and C. Namprempre, Authenticated Encryption: Relations among notions and analysis of the generic composition paradigm Asiacrypt 2000 LNCS 1976) that advises this. That is, SDP1 uses Encrypt-then-MAC mode.
But it turns out that this might have been an overly conservative choice. Earlier fears that MAC-then-Encrypt mode was insecure may have been overdone. That is, if due care is taken, then putting the MAC inside the cryptographic envelope could be strong. And thus eliminate the MAC as a hook to hang some traffic analysis on.
So let's assume that for now. We ditch the token, and we do MAC-then-encrypt. Which leaves us with the ciphertext. Now, because the datagram transport layer - again, UDP typically - will preserve the length of the content data, we do not need the array constructions that tell us how long the data is.
Now we have a clean encrypted text with no outer layer information. One furfie might have been that we would have to pass across the IV as is normally done in crypto protocols. But not in SDP1, as this is covered in the overall "context" - that session management that manages the keys structure also manages the IVs for each packet. By design, there is no IV passing needed.
Hey presto, we now have a clean encrypted datagram which is indistinguishable from random data.
Am I right? At the time, Zooko and I agreed it couldn't be done - but now I'm thinking we were overly cautious about the needs of encrypt-then-Mac, and the needs to identify each packet coming in.
(Hat tip to Todd for pushing me to put these thoughts down.)
May 07, 2006
Reliable Connections Are Not
Someone blogged a draft essay of mine on the limits of reliability in connections. As it is now wafting through the blog world, I need to take remedial action and publish it. It's more or less there, but I reserve the right to tune it some :)
When is a reliable connection not a reliable connection?The answer is - when you really truly need it to be reliable. Connections provided by standard software are reliable up to a point. If you don't care, they are reliable enough. If you do care, they aren't as reliable as you want.
In testing the reliability of the connection, we all refer to TCP/IP's contract and how it uses the theory of networking to guarantee the delivery. As we shall see, this is a fallacy of extension and for reliable applications - let's call that reliability engineering - the guarantee is not adequate.
And, it specifically is not adequate for financial cryptography. For this reason, most reliable systems are written to use datagrams, in one sense or another. Capabilities systems are generally done this way, and all cash systems are done this way, eventually. Oddly enough, HTTP was designed with datagrams, and one of the great design flaws in later implementations was the persistent mashing of the clean request-response paradigm of datagrams over connections.
To summarise the case for connections being reliable and guaranteed, recall that TCP has resends and checksums. It has a window that monitors the packet reception, orders them all and delivers a stream guaranteed to be ordered correctly, with no repeats, and what you got is what was sent.
Sounds pretty good. Unfortunately, we cannot rely on it. Let's document the reasons why the promise falls short. Whether this effects you in practice depends, as we started out, on whether you really truly need reliability.
April 21, 2006
Unique Transaction Numbers in SWIFT
Mark posts this story by Mike Williams to risks. Recorded here as a nice case study in unique transaction numbers.
I used to work on the S.W.I.F.T. payments system, and even that wasn't 100% perfect at eliminating duplicates and spotting omissions.In the many years that I worked with the system, we had one situation where everybody followed the rules, and yet a payment for ten million pounds got lost.
It all started when an operator at Bank A mistyped 10,000,000 instead of 20,000,000 on the initial payment. The error was spotted pretty quickly - banks have systems in place for double checking the total amount that gets paid in and out.
The operator could have sent a cancellation for 10,000,000 and a new payment for 20,000,000 and all would have been well, but cancellations can take days to process and someone would have to pay the overnight interest. What actually happened was that they sent a second payment for the remaining 10,000,000.
Now Bank A happened to use a system whereby the SWIFT Transaction Sequence Number is the same as the initial paperwork that caused the payment to be made, so the two payment messages were sent with the same TSN, the same amount, date, payer and payee. In fact the two payment messages were identical. (My bank didn't work like that, my programs always used a unique TSN, but that's partly because I wanted to use our TSN as a unique index on our outgoing files to make the coding simpler).
Unfortunately, at some point in its journey round the world, the initial payment hit a comms glitch. These were the days when electronic data communications were far less reliable than they are now. The relay station didn't get a confirmation ("ACK") so it sent a copy of the message with a "PDS" marker (Possibly duplicated by SWIFT network).
When the payments arrived at Bank B, they got passed to one of my programs that checks the possible duplicates. Because the payments were 100% identical, and one of them was flagged "PDS", that payment was dumped into the "real duplicate" file.
Mike Williams, Gentleman of Leisure [Forwarded to RISKS by Mark Brader]
April 02, 2006
Thank Skype for not listening
A day rarely passes in the crypto community where people do not preach that you should use standard protocols for all your crypto work. Many systems have foundered on this advice, something I tried to explain in more depth in the GP rants. Thankfully, not Skype. They wrote the whole thing from scratch, and they did it well.
Arguably the worlds' most successful crypto application (with approximately 5 million people enjoying its protection right now) it had to run the gauntlet of full industry skepticism for doing the cryptoplumbing thing on its own.
I earlier wrote that even if they bungled the crypto protocol, they still did the right thing. Philipp pointed me at some work from a few months back that claims their protocols have been audited and are relatively A-OK. Even better!
The designers of Skype did not hesitate to employ cryptography widely and well in order to establish a foundation of trust, authenticity, and confidentiality for their peer-to-peer services. The implementers of Skype implemented the cryptographic functions correctly and efficiently. As a result, the confidentiality of a Skype session is far greater than that offered by a wired or wireless telephone call or by email and email attachments.
So wrote Tom Berson in "Skype Security Evaluation," a name I've not come across. His analysis is worth reading if you are into reading up on cryptoprotocols for fun and profit. Although he doesn't reveal the full story, he reveals enough to know what they are up to at the crypto level, making up somewhat for the absence of open source. Here's some observations on his observations, spiced up with two other researches listed below.
The nymous identity creation is more or less the same as SOX, with a CA layered over the top. That is, the client creates the key and registers it with a pseudonym at the central server. The CA then signs that key, presumably making a statement that the pseudonym is unique in the Skype space.
I'm not entirely sure the addition of the CA is worth the cost. Given what we know about petnaming and so forth, and the fact that it opens up the vulnerability of the TTP MITMs, this appears to be a weakspot in the protocol - if Skype are going to be listening, then this is where they are going to do it. The weakness was identified by the Blackhat presentation (see below) and the Blackhat guys also claim that it is possible to set up a separate net and trick users into that net - not good news if true, and an indictment on the use of CAs over more modern constructs if it can't stop a darknet.
The key exchange is not entirely described. Both sides exchange their certificates and can then encrypt and sign to each other. They exchange 128 random bits each and combine this into the shared key of 256 bits - makes sense given the other assumptions. Before that, however, they do this, which I did not understand the point of:
To protect against playback, the peers challenge each other with random 64-bit nonces, and respond by returning the challenge, modified in a standard way, and signed with the responders private signing key.
How can there be a replay unless both sides have clagged PRNGs and are generating the same 128 bit inputs each time? The effect of this is, AFAICS, to duplicate the key exchange process by exchanging nonces ... but then throw that useful key entropy away! If you can explain this, please do so.
The data stream is encrypted by XORing the sound onto the output of an AES algorithm running in a stream generation mode. I'm not sure why this is done. My first guess is that any data corruption is self-correcting; a useful property in phones as you can just drop the bad data. But checksums over the packets seem to also cover that. Alternatively, it might be that it results in rather small amounts of packet expansion. (My own efforts at SDP1, with Zooko, resulted in significant expansion of packets, something I find annoying, but acceptable.) (I should note that the cryptophone.de design XORs the sound with *two* cipher streams, in case one is considered dodgy.)
Other plus points - the Skype engineers wisely chose their own key formats, a device that pays of by reducing the amount of code needed dramatically, and reduces dependencies on outside formats like x.509 and ASN1. Minus points appear to be in the complexity of the use of TCP and UDP, and a lot of duplicated packet flows. This is brought out more in the other presentations though.
In closing, Tom writes:
4. The Bottom Line
I started as a skeptic. I thought the system would be easy to defeat. However, my confidence in the Skype grows daily. The more I find out about it, the more I like.In 1998 I observed that cryptography was changing from expensive to cheap, from arcane to usual, from difficult to easy, from scarce to abundant. My colleagues and I tried to predict what difference, if any, abundant cryptography might make in the world. What new forms of engineering, business, economics, or society would be possible? We did not predict Skype. But, now that I am coming to know it well, I recognize that Skype is an early example of what abundant cryptography can yield.
I don't think it is quite that rosy, but it is on the whole good.
Juicy and more Skeptical Addendums:
- Some reverse engineering of the wider protocol shows many UDP and TCP dataflows: Philippe BIONDI Fabrice DESCLAUX, " Silver Needle in the Skype." Blackhat Europe, 2-3 March, 2006
- Some reverse engineering of the obfuscated client including 2 weaknesses in the protocol: Salman A. Baset and Henning Schulzrinne, "An Analysis of the Skype Peer-to-Peer Internet Telephony Protocol." Columbia University working paper? 2004.
February 06, 2006
A Nokia Without A Phone
The Nokia 770 has just been released ... without a phone or a camera (photo taken from an Ericsson). But it does have a full-model Linux install and can be used for all things Unix.
(And, a VoIP phone is coming soon, they say, in the "2006 Edition." I wonder if Nokia reads the news...)
Seriously though, the nexus with FC is more than reading this morning's other blog entry - we want our own pocket PC so we can stick on our secure online payments program. Either a completely secure browser environment for online banking or WebFunds for secure payments. Unfortunately, the small model Java Mobile isn't worth the bother to rewrite all the apps.

January 18, 2006
How Many Transactions?
Often people expect your transaction systems to be scaleable, and fast and capable of performing prodigous feats. Usually these claims reduce down to "if you're not using my favourite widget" then you are somehow of minimal stature. But even when exposed as a microdroid sales tactic, it is very hard to argue against someone that is convinced that a system just must use the ACME backend, or it's not worth spit.
One issue is transaction flow. How many transactions must you handle? Here's some numbers, suitable for business plans or just slapping on the table as if your plan depended on it. Please note that this is a fairly boring post - only read it when you need some numbers for your b-plan. I'll update it as new info comes in.
Earlier Wednesday, the Tokyo exchange had issued a warning it would stop trading if the system capacity limit of 4 million transactions was reached. As it reached 3.5 million about an hour before the session's close, it announced it would stop trading 20 minutes early.
According to the 2004 fourth-quarter report issued by Western Union's parent company, First Data Corp., an estimated 420 Western Union transactions occur every minute each day -- amounting to an average of seven transfers every second of the year.
Craig's stellar plotting system for e-gold's transaction flow gives us loads of 34k per day last I looked. Also Fee Income.
eBay's annual report for 2005 reported that "PayPal processed an average of approximately 929,000 transactions per day during 2004." There are contradictory numbers here and here: Total number of payments grew to 117.4 million, up 41 percent year over year and 4 percent vs. the prior quarter. This would imply 320k transactions per day, but we don't expect Paypal to be accurate in filings to the SEC.
Payment News reports:
Robin Sidel reports for the Wall St. Journal on how credit card issuers are now pursuing the market for smaller payments less than $5:....The market for transactions valued at less than $5 accounted for $1.32 trillion in consumer spending in 2003, representing more than 400 billion transactions, according to research by TowerGroup, a unit of MasterCard International Inc. By comparison, Visa processes a total of about $2 trillion of global transactions each year.
During the busiest hour on December 23 [2005], Visa processed an average of 6,363 transaction messages each second. That's a 14 percent increase over the average of 5,546 transaction messages per second Visa processed during the peak hour on December 24, 2004. Consider that Visa's payment network, VisaNet, can process more transactions over the course of a coffee break than all the stock exchanges of the world in an entire day.
Nice quip! I'll check that out next time I get my exchange running. In closing, let's let Lynn Wheeler have the last word. He reports that the old white elephant of transaction processing, SET, performed like this:
...If even a small percentage of the 2000 transactions/sec that typically go on were to make the transition to SET, the backend processing institution would have to increase their legacy computational processing capability by three orders of magnitude. The only way that SET could ever be succesful was if it totally failed, since the backend processing couldn't build out to meet the SET computational requirements. It was somewhat satisfying to see the number of people that the thot stopped them in their tracks.The best case demo of SET at a show a year later was on an emulated processing environment with totally idle dedicated boxes. The fastest that they could get was 30 seconds elapsed time, with essentially all of that being RSA crypto computational processing. Now imagine a real-world asymmetric environment that is getting 1000 of those a second. My statement was that a realistic backend processing configuration would require on the order of 30,000 dedicated machines just doing the RSA crypto processing.
There were then remarks from the workstation vendors on the prospect of selling that many machines, and somebody from RSA about selling that many licenses. From then on my description that SET was purely an academic toy demo, since nobody could ever take it as a serious proposal with operational characteristics like that.
private email, 14th December 2005. Note how he's talking about the mid 90's, using 10 year old figures for credit card processing networks like Visa.
January 07, 2006
RSA comes clean: MITM on the rise, Hardware Tokens don't cut it, Certificate Model to be Replaced!
In a 2005 document entitled Trends and Attitudes in Information Security that someone sent to me, RSA Security, perhaps the major company in the security world today, surveys users in 4 of the largest markets and finds that most know about identity theft, and most are somewhat scared of ecommerce today. (But growth continues, so it is not all doom and gloom.)

This is an important document so I'll walk through it, and I hope you can bear with me until we get to the important part. As we all know all about identity theft, we can skip to the end of that part. RSA concludes its longish discussion on identity theft with this gem:
ConclusionConsumers are, in many respects, their own worst enemies. Constantly opening new accounts and providing personal information puts them at risk. Ally this to the naturally trusting nature of people and it is easy to see why Man-in-the-middle attacks are becoming increasingly prevalent. The next section of this e-Book takes a closer look at these attacks and considers how authentication tokens can be a significant preventative.
Don't forget to blame the users! Leaving that aside, we now know that MITM is the threat of choice for discerning security companies, and it's on the rise. I thought that last sentance above was predicting a routine advertisement for RSA tokens, which famously do not cover the dynamic or live MITM. But I was wrong, as we head into what amounts to an analysis of the MITM:
9. Offline [sic] Man-in-the-Middle attackWith online phishing, the victim receives the bogus e-mail and clicks through to the falsified Web site. However, instead of merely collecting rapidly changing passwords and contact information, the attacker now inserts himself in the middle of an online transaction stream. The attacker asks for and intercepts the users short-time-window, onetime password and stealthily initiates a session with the legitimate site, posing as the victim and using the victims just-intercepted ID and OTP.
Phishing is the MITM. More importantly, the hardware tokens that are the current rage will not stop the realtime attack, that which RSA calls "online phishing." That's a significant admission, as the RSA tokens have a lot to do with their current success (read: stock price). The document does not mention the RSA product by name, but that's an understandable omission.
Maybe, your pick.... But let's get back to reading this blurb. Here comes the important part! Heads up!
 | The need for site verification |
Read it again. And again, below, so you don't think I make this shit up. RSA Security is saying we need a site verification system, and not mentioning the one that's already there!

SSL and certificates and the secure browsing system are now persona non gratis, never to be mentioned again in corporate documents. The history book of security is being rewritten to remove reference to a decade or so of Internet lore and culture. Last time such a breathtaking revision occurred was when Pope Gregory XIII deleted 10 days from the calendar and caused riots in the streets by people wanting their birthdays back. (Speaking of which, did anyone see the extra second in the new year? I missed it, darn it. What was it like?)
So, what now? I have my qualms about a company that sells a solution in one decade, makes out like bandits, and then gets stuck into the next decade selling another solution for the same problem. I wrote recently about how one can trust a security project more when it admits a mistake than when it covers it up or denies its existance.
But ones trust or otherwise of RSA Security's motives or security wisdom is not at issue, except for those stock price analysts who hadn't figured it out before now. The important issue here for the Internet community is that when RSA admits, by default or by revisionism, that the certificates in the secure browsing model need to be replaced, that's big news.
This is another blackbird moment. RSA wrote the rule book when it came to PKI and certificates. They were right in the thick of the great ecommerce wars of 1994-1995. And now, they are effectively withdrawing from that market. Why? It's had a decade to prove itself and hasn't. Simple. Some time soon, the rest of the world will actually admit it too, so better be ahead of the curve, one supposes.
Get the message out - RSA has dumped the cert. We still have to live with it, though, so there is still lots of work to be done. Hundreds of companies are out there pushing certificates. Thousands of developers believe that these things work as is! A half-billion or so browsers carry the code base.
Without wishing to undermine the importance of RSA Security's switch in strategy, they do go too far. All that certificate code base can now be re-factored and re-used for newer, more effective security models. I'll leave you with this quasi-recognition that RSA is searching for that safe answer. They're looking right at it, but not seeing it, yet.
Browser plug-inWith this method, a locally resident browser plug-in cryptographically binds the one-time password (or challenge-response) to the legitimate sitei.e., the actual URL, rather than the claimed site name. This means that the password is good only for the legitimate site being visited.
This is an implicit level of site verification and is a far better approach than token-based host authentication and can prevent man-in-the-middle attacks. There are drawbacks and vulnerabilities, however. First, a browser plug-in presents all of the attendant issues of client software: it must be successfully loaded by the customer and updated, supported, and maintained by the site host. And, if the PC has been compromised through some form of co-resident malware, it remains vulnerable to subsequent exploitation.
Huh. So what they are saying is "we see good work done in plugins. But we don't see how we can help?" Well, maybe. I'd suggest RSA Security could actually do good work by picking up something like Trustbar and re-branding it. As Trustbar has already reworked the certificate model to address phishing, this provides the comfortable compromise that RSA Security needs to avoid the really hard questions. Strategically, it has everything a security company could ever want, especially one cornered by its past.
I said that was the last, but I can't resist one more snippet. Notice who else is dropped from the lexicon:
In the end, trust is a human affair and the right technology foundations can create a much stronger basis for forming that trusted relationship. As consumers and vendors continue to respond to new and emerging threats to identity theft, it will be essential for them to bear these principles in mind. For more information about any of the issues raised in this document please visit www.rsasecurity.com or contact:
If anyone can send me the URL for this document I'll gladly post it. All in all, thanks to RSA Security for coming clean. Better late than never! Now we can get to work.
Our Private Bayesian Rules Engine
The Economist has a great article on how psychologists are looking at how computer scientists are using Bayesian prediction engines for things like help wizards and spam filters. The Psychologists asked an unusual question - maybe people use Bayesian logic?
Of course! Er, well, maybe. Science needs to test the hypothesis, and that's what they set out to do:
Dr Griffiths and Dr Tenenbaum conducted their experiment by giving individual nuggets of information to each of the participants in their study (of which they had, in an ironically frequentist way of doing things, a total of 350), and asking them to draw a general conclusion. For example, many of the participants were told the amount of money that a film had supposedly earned since its release, and asked to estimate what its total gross would be, even though they were not told for how long it had been on release so far.Besides the returns on films, the participants were asked about things as diverse as the number of lines in a poem (given how far into the poem a single line is), the time it takes to bake a cake (given how long it has already been in the oven), and the total length of the term that would be served by an American congressman (given how long he has already been in the House of Representatives). All of these things have well-established probability distributions, and all of them, together with three other items on the listan individual's lifespan given his current age, the run-time of a film, and the amount of time spent on hold in a telephone queuing systemwere predicted accurately by the participants from lone pieces of data.

There were only two exceptions, and both proved the general rule, though in different ways. Some 52% of people predicted that a marriage would last forever when told how long it had already lasted. As the authors report, this accurately reflects the proportion of marriages that end in divorce, so the participants had clearly got the right idea. But they had got the detail wrong. Even the best marriages do not last forever. Somebody dies. And forever is not a mathematically tractable quantity, so Dr Griffiths and Dr Tenenbaum abandoned their analysis of this set of data.The other exception was a topic unlikely to be familiar to 21st-century Americansthe length of the reign of an Egyptian Pharaoh in the fourth millennium BC. People consistently overestimated this, but in an interesting way. The analysis showed that the prior they were applying was an Erlang distribution, which was the correct type. They just got the parameters wrong, presumably through ignorance of political and medical conditions in fourth-millennium BC Egypt. On congressmen's term-lengths, which also follow an Erlang distribution, they were spot on.
Which leaves me wondering what an Erlang distribution is... Wikipedia doesn't explain it in human terms, but it looks like a Poisson distribution:
Curious footnote - look at who they credited as the source of their graph of distributions.
December 26, 2005
Early History of SSL - guess who invented the colour bar?
There's been a bit of chat about how Microsoft picked up Firefox picked up the yellow HTTPS indicator and changed the colour. Some people have pointed out that Firefox invented it, but it turns out to have been present in the earliest versions. This 1996 document found by Frank Hecker reveals:
You can also verify the security of a document by examining the security icon in the bottom-left corner of the Netscape Navigator window and the colorbar across the top of the content area. The icon consists of a doorkey on a blue background to show secure documents and a broken doorkey on a gray background to show insecure documents. The colorbar across the top of the content area is blue for secure and gray for insecure.
(My emphasis.) I've often pointed out that the Netscape browser reputedly started out with the CA's name printed on the chrome. It must have lost the colour bar too! So perhaps we should just stop whining and download and get going the original Netscape beta and see what it does?
December 24, 2005
A VPN for the common man!
In the rumbling debate about VPNs and how they should be done, here's a new entrant as found in an interview with Damien Miller (spotted on Matasano):
The upcoming OpenSSH version 4.3 will add support for tunneling. What type of uses is this feature suited for?Damien Miller: Reyk and Markus' new tunneling support allows you to make a real VPN using OpenSSH without the need for any additional software. This goes well beyond the TCP port forwarding that we have supported for years - each end of a ssh connection that uses the new tunnel support gets a tun(4) interface which can pass packets between them. This is similar to the type of VPN supported by OpenVPN or other SSL-VPN systems, only it runs over SSH. It is therefore really easy to set up and automatically inherit the ability to use all of the authentication schemes supported by SSH (password, public key, Kerberos, etc.)
The tunnel interfaces that form the endpoints of the tunnel can be configured as either a layer-3 or a layer-2 link. In layer-3 mode you can configure the tun(4) interfaces with IP or IPv6 addresses and route packets over them like any other interface - you could even run a dynamic routing protocol like OSPF over them if you were so inclined. In layer-2 mode, you can make them part of a bridge(4) group to bridge raw ethernet frames between the two ends.A practical use of this might be securely linking back to your home network while connected to an untrusted wireless net, being able to send and receive ICMP pings and to use UDP based services like DNS.
Like any VPN system that uses a reliable transport like TCP, an OpenSSH's tunnel can alter packet delivery dynamics (e.g. a dropped transport packet will stall all tunnelled traffic), so it probably isn't so good for things like VOIP over a lossy network (use IPsec for that), but it is still very useful for most other things.
The problem with VPNs has been partly key management nightmares (a.k.a x.509) and partly install and configuration nightmares. For those reasons, VPNs only really made it into areas where corporates could pay people to get them up and going.
Adding it to SSH solves both those issues and promises to bring about VPNs for the common Unix machine (including all Macs now).
Crazy Prediction Time :- within a year of this being released and available, SSH will be the most popular VPN. Within two years, we'll even forget that VPN stood for anything other than a way in which we use SSH.
November 06, 2005
ACM Interactions - special issue on Security
Submissions Deadline: February 1st, 2006
Publications Issue: May+June 2006 Issue
PDF: here but please note that it causes lockups.
Interactions is published bi-monthly by the Association for Computer Machinery (ACM) for designers of interactive products. It is a magazine that balances articles written for professionals and researchers alike providing broad coverage of topics relevant to the HCI community.
The May+June 2006 issue of Interactions is dedicated to the user experience around security in information systems. Designing systems that are both secure and usable offers unique challenges to interaction designers. System complexity, user acceptance and compliance, and decisions about protection versus convenience all factor into the design process and resulting effectiveness of security systems in the hands of users.
Interactions invites authors to submit case studies and articles related to the security user experience. Papers should be written in a reader-friendly magazine style and tone as opposed to a conference proceedings or journal style (no abstracts, appendicies, etc).
Relevant contributions will address issues related, but not limited to, the following:
- Interaction design of systems with usable security and user trust as primary goals
- Innovative methods for conducting user experience evaluations on user trust or security systems
- Novel user interfaces or interaction methods for security systems
- Basic principles of psychology of user-security interaction
- Best practices and interaction guidelines in the design of secure and trustworthy systems
- Field research related to user-security interaction in the wild
- Social and/or philosophical issues related to security, trust, and the user experience
Interactions invites papers in the following two formats:
- Case Studies 7-9 pages. Case Studies are reports on experiences gained and lessones learned designing, using, or studying security components/systems or techniques. They take a comprehensive view of a problem from requirements analysis through design, implementation, and use.
- Articles 1-3 pages. Articles are much shorter and broader case studies and may present research findings, points of view, social or philosophical inquiries, novel interface designs, or other information relevant to the HCI community regarding security and the user experience.
Papers that appear in Interactions are archived in the ACM Digital Library and available online. The Special Issue on Security will appear in the May+June 2006 issue of Interactions and the deadline for submissions is February 1st, 2006.
For more information about submission guidelines or appropriate topics, contact ryan.west@sas.com.
October 12, 2005
The Mojo Nation Story - Part 2
[Jim McCoy himself writes in response to MN1] Hmmm..... I guess that I would agree with most of what Steve said, and would add a few more datapoints.
Contributing to the failure was a long-term vision that was too complex to be implemented in a stepwise fashion. It was a "we need these eight things to work" architecture when we were probably only capable of accomplishing three or four at any one time. Part of this was related to the fact the what became Mojo Nation was originally only supposed to be the distributed data storage layer of an anonymous email infrastructure (penet-style anonymous mailboxes using PIR combined with a form of secure distributed computation; your local POP proxy would create a retrieval ticket that would bounce around the network and collect your messages using multiple PIR calculations over the distributed storage network....yes, you can roll your eyes now at how much we underestimated the development complexity...)
As Bram has shown, stripping MN down to its core and eliminating the functionality that was required for persistent data storage turned out to create a pretty slick data distribution tool. I personally placed too much emphasis on the data persistence side of the story and the continuing complexity of maintaining this aspect was probably our achilles heel, if we had not focused on persistence as a design goal and let it develop as an emergent side-effect things might have worked but instead it became an expensive distraction.
In hindsight, it seems that a lot of our design and architecture goals were sound, since most of the remaining p2p apps are working on adding MN-like features to their systems (e.g. combine Tor with distributed-tracker-enabled BitTorrent and you are 85% of the way towards re-creating MN...) but the importance of keeping the short- term goal list small and attainable while maintaining a compelling application at each milestone was a lesson that I did not learn until it was too late.
I think that I disagree with Steve in terms of the UI issues though. Given the available choices at the time we could have either created an application for a single platform or use a web-based interface. The only cross-platform UI toolkit available to us at the time (Tk) was kinda ugly and we didn't have the resources to put a real UI team together. If we were doing this again today our options would include wxWidgets for native UI elements or AJAX for a dynamic web interface, but at the time a simple web browser interface seemed like a good choice. Of course, if we had re-focused on file-sharing instead of distributed persistent data storage we could have bailed on Linux & Mac versions and just created a native win32 UI...
The other point worth mentioning is that like most crypto wonks, we were far too concerned with security and anonymity. We cared about these features so we assumed our users would as well; while early adopters might care the vast majority of the potential user base doesn't really care as much as we might think. These features added complexity, development time, and a new source of bugs to deal with.
Jim
Back to Part 1 by Steve.
The Mojo Nation Story
[Guest post by Steve Schear] Mojo Nation was the brainchild of Jim McCoy (then formerly of Yahoo) and Doug Barnes (then formerly of C2Net). Their vision was a fully distributed peer-to-peer network with a financial mechanism that offered efficient cost recovery and discouraged the free-riding known to P2P people as leeching (a problem that continues to plague P2P).
The most radical element of MN was its method of pricing all activities in terms of network resources. It was also one of the first attempts at a P2P network using a fully distributed approach and a publishing versus a file sharing metaphor.
Unfortunately, MN was never fully operational. It never reached a point of deployment that allowed many of its novel architectural and technological assumptions, especially the mint, to be truly tested. It's not clear what economic lessons to draw from its operational vision, but here are some of the reasons behind its business failure:
- MN failed because it failed to get continued funding. It only received seed money from its founder, Jim McCoy. MN was in development before Napster but its greater complexity caused a delayed public release. Jim had the foresight to thoroughly investigate the legal aspects of P2P and architecture MN to segregate tracking and file storage and distance itself from either. Nevertheless, Napster's negative publicity closed the door on VC funding and development beyond beta testing.
- It failed because the UI never reached a point of maturity that enabled mostly automated meta-data tags (e.g., from mp3) to be generated from published content. This required users to tediously enter this data (and re-enter it when they were forced to republish, see below).
- It failed because software instabilities prevented its distributed servers from accumulating and retaining enough content and becoming stable (network effects). This instability required constant, manual, republishing of content by users who soon fatigued (user churn).
The most notable result from MN was Bram's Bit Torrent. Though, as we saw, Bram failed to heed warnings (and discussion at MN) about protecting the trackers until the MPAA/RIAA were able to shut many down. Its been reported that many of these shortcomings have been fixed but I still can't seem to get Azureus (the most popular BT client) to work as expected with the distributed tracking. Since the demise of eDonkey, et al, due to the MGM vs. Grokster BT has been given a shot at reassuming the P2P leadership mantle. I hope it succeeds. Or perhaps P2P's next growth will have to wait until enough its users discover the advantages of an anonymizing transport layers, like TOR and I2P.
Steve
Addendum: see Part 2 from Jim McCoy himself.
October 02, 2005
Extra Financial Cryptographic Engineering
Patrick announces his Loom system, which basically (AFAICS) allows slicing and dicing amounts into URLs that are distinguished by a SHA1 hash. Each piece of value can be placed into a new location with a new SHA1 hash, and as long as the SHA1 hash is kept secret, so is the dosh. (Also discussed on Venkat's blog.)
This bears comparison to epointsystem.org's ePoints which employ a similer slicing and dicing method. This system is heavily crypto-oriented but by repute employs a simple server that only offers two primitives: split, and combine.
Also, the use of SHA1 numbers as essentially big random numbers is what I use in my BRN extension to Ricardo, which is designed to do all the infrastructure behind blinded token money, without the blinding. (Serious students of FC will know that the blinding is about 2000 lines of code, and the rest is about two orders of magnitude larger, depending... so BRN creates an independent break between the precise blinding formula and the code that deals the tokens.)
What then is perhaps more interesting to the financial cryptographer is not the mechanism but the metaphor. By describing the BRN as a "location" in cyberspace, and the transfer as a placing of gold in a secret place, Patrick seems to have inspired his nearby supporters more than any description of crypto blah blah ever could.
There appears to be a new generation of hackers coming forth with money systems. I suspect this is because of the rise of p2p systems, which bring with them horrific problems in economic coordination. To my knowledge, only MojoNet (now MNET) addressed these challenges seriously with techniques known here but that story remains undocumented in FC annals (*hint*, *hint* !!!).
Meanwhile, in the Community currency field, there are now several systems offering basic accounting mechanisms (Cyclos, CCLite, MRS). These have a much lower security threshold, befitting their community heritage. Although some would argue this is mistake as community currencies often collapse at the point of success (as measured by being valuable enough to steal), I don't see it so dogmatically; like all communities, the CC world has to experiment, win a few and lose a few, in order to find out which of their assumptions were right and which wrong.
So my question is whether we now have sufficient FC activity to run another EFCE? Have the doldrums of FC passed, and is it time to make the pilgrimage to the hallowed halls of the Signet Library, or do we need another E-First City in Europe?
September 06, 2005
SSL v2 Must Die - Notice of Extinction to be issued
A Notice of Extinction for prehistoric SSL v2 web servers is being typed up as we speak. This dinosaur should have been retired net-centuries ago, and it falls to Mozilla to clean up.
In your browser, turn off SSL v2 (a two-clawed footprint in protocol evolution). Go here and follow the instructions. You may discover some web sites that can't be connected to in HTTPS mode. Let everyone know where they are and to avoid them. (Add to bug 1 or bug 2.)
Maybe they'll receive a Notices of Imminent Extinction. When I last looked at SecuritySpace there were no more than 4445 of them, about 2%. But Gerv reports it is down to 2000 or so. (Measurement of websites is not an accurate science.)
Elsewhere, Eric Rescorla published some slides on a talk he'd given on "Evidence" (apologies, URL mislaid). Eric is the person who wrote the book on SSL and TLS (literally) and also served as the editor of the IETF committee. In this talk, he presented the case for "evidence-based security" which he refers to as looking at the evidence and acting on what it tells you. Very welcome to see this approach start to take root.
Another factoid - relevent to this post - he gave was that the half-life of an OpenSSL exploit is about 50 days (see chart half way down). That's the time it takes for half of the OpenSSL servers out there to be patched with a known exploit fix. Later on, he states that the half life for windows platforms with automated patching is 21 days for external machines and 62 days for internal machines (presumably inside some corporate net). This is good news, this means there isn't really any point in delaying the extinction of SSL v2: The sooner browsers ditch it the sooner the dinosaurs will be retired - we can actually make a big difference in 50 days or so.
Why is this important? Why do we care about a small group of sites are still running SSL v2. Here's why - it feeds into phishing:
1. In order for browsers to talk to these sites, they still perform the SSL v2 Hello. 2. Which means they cannot talk the TLS hello. 3. Which means that servers like Apache cannot implement TLS features to operate multiple web sites securely through multiple certificates. 4. Which further means that the spread of TLS (a.k.a. SSL) is slowed down dramatically (only one protected site per IP number - schlock!), and 5, this finally means that anti-phishing efforts at the browser level haven't a leg to stand on when it comes to protecting 99% of the web.
Until *all* sites stop talking SSL v2, browsers will continue to talk SSL v2. Which means the anti-phishing features we have been building and promoting are somewhat held back because they don't so easily protect everything.
(There's more to it than that, but that's the general effect: one important factor in addressing phishing is more TLS. To get more TLS we have to get rid of SSL v2.)
August 28, 2005
Application mirroring - In which I strike another blow against the System Programmer's Guild
Once upon a time I was a systems programmer. I was pretty good too; not brilliant but broad and sensible enough to know my limitations, perhaps the supreme asset of all. I attribute this good fortune to having attended perhaps the best place outside Bell Labs for early Unix work - UNSW - and my own innate skepticism which saved me from the self-glorification of the "guru culture" that pervaded those places and days.
Being a systems programmer is much more technically challenging than their alter ego, the applications programmer. The technology, the concepts, the things you can do are simply at a higher intellectual plane. Yet there is a fundamental limit - the human being. Wherever and however you do systems programming, you always strike up against that immovable yet indefinable barrier of the end user. At the end of the day, your grand complex and beautiful design falls flat on its face, because the user pressed the wrong button.
A good systems programmer then reaches a point where he can master his entire world, yet never advance intellectually. So one day I entered the world of applications programming and looked back only rarely. Still, I carried the ethos and the skepticism with me...
This meandering preamble is by way of reaching here: Recently I hit a tipping point and decided to throw a Core Systems Programming Construct into the trash. RAID, mirrored drives and all that have been a good old standby of well managed systems for a decade or more. In one act, Confined and Plonk. To hell with it, and all this sodding special drivers and cards and SANs and NASes and what-not - out the window. For the last three or four years we'd been battling with mirroring technologies of one form or another, and here's the verdict: they all suck. In one way or another, and I was very glad to spy research (since lost) that claimed that something like one in eight of all mirrors system end in tears when the operator inserts the wrong drive and wipes his last backup... It restores faith to know that we weren't the only ones.
So...
I dived into our secure backend code and discovered that coding up mirroring at the application-level took all of a day. That's all! In part, that's because the data requirements are already strictly refined into one log feed and one checkpoint feed, and they both go through the same hashed interface. Also, another part is that I'd been mulling it over for months; my first attempt had ended in retreat and a renewed attack on the mirroring drivers... In those ensuing months the grey matter had been working the options as nice -n 20 task.
But, still! A day! It is a long time since I'd coded up a feature in only a day - I was somewhat shocked to have got self-testing done by the time it was dark.
OK, I thought, surely more problems will turn up in production? Well, this morning I moved a server from an unprotected machine to a new place. I turned on mirroring and then deliberately and painfully walked through starting it up without the application-defined mirror. Bang, bang, bang, it broke at each proper place, and forced me to repair. Within 30 mins or so, the migration was done, and turning on mirroring was only about 10 mins of that!
So where is all this leading? Not that I'm clever or anything; but the continuing observation that many of the systems, frameworks, methodologies, and what have you are just ... Junk. We would be better off without them, but the combined weight of marketing and journalistic wisdom scare us from bucking the trend.
Surely so many people can't be wrong? we say to ourselves, but the history seems to provide plenty of evidence that they were indeed just that: Wrong. Here's a scratch list:
SSO, PKI, RAID and mirrored drives (!), Corba, SQL, SOAP, SSL, J2EE, firewalls, .NET, ISO, Struts, provable security, AI, 4GLs, IPSec, IDS, CISPs, rich clients,
Well, ok, so I inserted a few anti-duds in there. Either way, we'd probably all agree that the landscape of technology hasn't changed that much in the last N years, but what has changed is the schlockware. Every year portends a new series of must-have technologies, and it seems that the supreme skill of all is knowing which to adopt, and which to smile sweetly at and wait until they fail under their own mass of incongrueties.
August 18, 2005
Security Systems that fall in a heap if actually challenged...
Over on EmergentChaos, there are two security systems that failed dismally when a slight attack is launched. In building real security systems, we try and analyse everyone else's attempts and especially the reasons for failure.

One is brought about by news of the London shooting of an electrician who was falsely tracked as a suicide bomber. Reading through the case (at least to the extent of the newspaper coverage there) the victim lived in an address named by past bombers, and was spotted leaving before the police were ready to take the building in a SWAT raid.
High level instructions were that he was not to enter the tube, and that the "all clear" had been given. Of course, he's in London so he's heading for the tube to go to his job. The "potential suicide bomber entering the tube" procedure is to isolate and shoot in the head, as far as I can tell, and this is carried out more or less adequately. The procedure is fatally brutal so as to not let the bomber detonate when he knows he is discovered.
The procedure as presented is "technically valid" although questionable at many reliability and ethical levels. The real underlying failure here was that the British Police just (successfully) hit their first false positive, and now they have to wrestle with the implications of the statistical unreliability of detecting bombers in advance. How many bombers and innocents do you trade for real victims of a real bomber?
The next observation is that this is what is known in the trade as an "own goal." Anti-terrorist operations have a particular strategy which is trying to force the bomber to make mistakes and thus take themselves out, a tactic that apparently came out of the Northern Ireland troubles. But it is by no means limited to the good guys; as things get more complex, more mistakes are made.
The question then is, how complex do you want to make "defence of the homeland?" It should be remembered that KISS - keep it simple, stupid - came out of the military where mistakes cost lives and lose objectives.
The third observation is that everything written about looks easy to defeat. Expect the next wave of suicide bombers to have addressed it. Which feeds into the complexity argument in both of the above directions.
Fourthly, if you are going to have a special weapons procedure for dealing with these extreme events, then do what the Brits do - make that a specially trained team, and only they get to do it. That part they got right, although the newspapers look to make it look like a schmozzle. Shoot to kill is not the sort of thing you want every policeman doing, that's the sort of thing that *has* to be handed over to the specialists, in order to preserve the integrity of ... well just about everything. But obviously handover of the task needs to be done very well, and it was botched in this case.
Fifthly and finally, there are several more victims here other than the direct victim. One is the notion of being able to catch the tube and do so with rights and so forth. And another is the policeman who followed the procedure and killed an innocent. And finally, faith in the British Police is likely to take a beating. The chilling effect alone may well be worse than a few bombs.
My prediction then is the shoot to kill policy will be drastically curtailed as it is too unreliable, and the damage it does is likely worse than the benefit it might bring.

Addendum. In a curious post, EC points to reports that a someone was apprehended trying to smuggle a bomb onto a plane in the US. Obscurely, because the authorities decided he wasn't a terrorist, nobody made a big deal. Isn't that curious evidence of a security system out of control?
In the second system, which is posting comments on the EmergentChaos blog which I can no longer do as my content is considered "questionable." It seems that the effort to stop spammers has stopped commentary, or at least mine. Some will find that amusing! This is a fairly simple case of the security being worse than no security at all, at least for this customer.
In the discussion about the apparently new epidemic of phishing, all the simple ideas have come out, such as the bank not sending out bad emails, and the users not clicking on bad emails. Also, the notion of a bank and a user sharing a special picture. Here's what I would have said if the anti-spamming protection hadn't stopped me (which entres the third security system that fell in a heap when challenged):
Sharing stuff with the bank is a dumb idea. Phishing is an MITM that allows the phisher to share his version of the website with the user ... and the bank if so desired. That is, models like Passmark and SecureId tokens fall to a simple MITM, at least in theory. We haven't seen any of these attacks as yet because the basic MITM of phishing still seems to be working (read: steals lots of money) and the rollout of the dynamic checking models isn't that far advanced, I guess.To paraphrase Lynn, "there was this little thing called SSL." It had certificates. They were supposed to stop MITMs by means of checking for spoofing against the identity of the site.
Wish to stop phishing? Stop the spoofing of the domain ... where the spoofing protection was built in the first place. (But as I mentioned, even that won't stop the rot at this stage because the attacks have jumped to the user's node.)
Asking users and banks to do the right thing is just like asking your politician to "do something." For more proactive work on fixing the technology to help the users and banks, have a look at the Anti Fraud Coffee Room.
Addendum: for those wondering what the pictures are, someone who might or might not be a nym sent me this:
Thursday morning at 7 am, the neighbor's wife called me. She wanted me to kill a cougar that their doberman had treed in the front yard. (her husband is out of town)I talked her out of it. Cat just got scared of the dog. 95% of the cougar do no harm their entire lives except to the turkeys and deer.
Took some pictures and put the dog in the kennel. Told the lady to stay indoors and not scare the cougar. It came down several hours later and left. (I wasn't there when it came down.)
I'll take that as evidence of a better security policy - think before you shoot. Thanks :-)
August 05, 2005
tracking tokens
Wired and Boston report on a new mechanism to read a fingerprint from paper. Not the fingerprint of a person touching it, but the fingerprint of the paper itself. Scanning the micro-bumps with a laser is a robust way to create this index, and it even works on plastic cards. (Note, don't be distracted about the marketing bumph about passports, it is way too early to see where this will be used as yet.)
Our recent pressed flowers adventure resulted in a new discovery along similar lines - we can now make a token like a banknote with cheap available tools that is unforgeable and uncopyable. It does this by means of the unique identifier of the flower itself; we can couple this digitally by simply scanning and hashing (a routine act in the ongoing adventure of FC). What's more, it integrates well with the pre-monetary economics that is built into our very genes, if you subscribe to the startling new theory presented in "Shelling Out," a working paper by Nick Szabo.

In other tracking information, the EFF has started tracking printers that track pages. Some manufacturers print a tiny fingerprint of the printer onto every page that gets produced. Originally "suggested" by monetary authorities so as to trace forgeries and copies of paper money, it will of course make its way into evidence in general court proceedings. Predictably the EFF finds that there is no protection whatsoever for this.
(older DRM techniques by the ECB.)
From the benches of the Montana Supreme Court, a judgement that instantiates the Orwell Society. Dramatically written by Judge Nelson and brave for its refreshing honesty, it recalls that famous line from Scott McNeally, "you have no privacy left, get used to it." It's worth reading for its clear exposition of how your garbage is abandoned and therefore open to collection by ... anyone. But it should also serve as a wakeup call to the limits of privacy. Judge Nelson writes (from Wired):
In short, I know that my personal information is recorded in databases, servers, hard drives and file cabinets all over the world. I know that these portals to the most intimate details of my life are restricted only by the degree of sophistication and goodwill or malevolence of the person, institution, corporation or government that wants access to my data.I also know that much of my life can be reconstructed from the contents of my garbage can.
I don't like living in Orwell's 1984; but I do. And, absent the next extinction event or civil libertarians taking charge of the government (the former being more likely than the latter), the best we can do is try to keep Sam and the sub-Sams on a short leash.
In such a world, we should be delivering privacy, as we cannot rely on anyone else to do it. In this sense, the recent (popularish) argument between Phil Zimmerman's new VoIP product and some PKI apologists is easily defended by Phil as such:
My secure VoIP protocol also requires almost no activation energy, so I expect it to do well.
No more need be said. Go Phil. (See the recent article on Security Usability (PDF only, sorry) for IEEE's Security & Privacy mag as well.)
July 04, 2005
Learning from Failure
When we build complex systems, we mean we build systems that are too complex for any person to understand. Any one person - it's possible for one person to understand a module completely, or an overview of all the components, but not to understand the way the whole thing works.
An inevitable result of this is that complex systems fail in strange ways. And it is as perversely inevitable that we often only really advance our understanding of complex systems in the examination of failure. It's our chance to learn how to be more complex.
Here are some notes I've picked up in the last couple of months (and an old entry):
1. Wired reports on how the people stuck in twin towers of the WTC ignored standard safety rules and also ignored what they were told. They used the elevators and stairs and scarpered.
The key lesson here is that the people on the scene often have more information than the experts, in both qualitative and quantitative terms. Wired takes this and says "Disobey Authorities" but that's going to far (Cubicle comments). What is more pertinent is that when the information is clearly better on the ground, then encourage your people to see that and work with it. Drop the rules if they see the need, knowing that if they get that judgement call wrong they will face the music later on.
2. Over in the land of military madness called the Pentagon, they have just that problem. The solution - train the corporal to fight the insurgent on his own terms - seems to be an old one as it was considered learnt at the end of the Vietnam war by the US Army. At least, that was the wisdom I recall from countless military books and articles. Read this article for why it has been forgotten.
I'm not sure what the lesson is here, and indeed, the late John Boyd had a name for the syndrome. He called it "stuck in ones own OODA loop" and said there was no solution.
3. In another episode of safety engineering (seen on TV), the design and maintenance of the cockpit window in a jetliner came under question. At cruising altitude, it popped out, sucking the captain out and trapping him half in and half out. Rather uncomfortable at 10,000 metres.
Why this happened was a series of 13 identified failures, every one of which if it hadn't have happened would have stopped the failure. Mostly, the TV program focused on the hapless maintenance engineer who openly and honestly described how he had followed 'local' procedures and ended up being an unwitting installer of the wrong bolts.
There are three lessons in this story.
Firstly, the easiest lesson is to make your designs fail safely. These days aircraft windows are designed to be fitted from the inside so they can't pop out under cabin pressure. That's a fail-safe design.
Secondly, and more subtly, design your safety features to fail obviously! 13 different failures - yet they all kept going until the last one failed? Why wasn't one of these failures noticed earier?
Finally, the subtle lesson here is that local conditions change - you can write whatever you like in the rule book, and you can set up whatever you like in the procedures, but if they are things that can be changed, ignored, bypassed, or twisted, then they will be. People optimise, and one of the things the love to optimise away is the rule book.
4. In TV documentaries and films, we've all no doubt seen the story of the O-ring engineer who was brow-beaten into silence before the shuttle went up. The safety system was overridden from on-high, because of commercial interests. We saw this same pressure a few weekends back in the farcical United States Grand Prix (Formula 1) race that dropped 14 cars because the tires were declared unsafe. All the bemoaning of damage to the sport and lack of compromise misses the key point - the safety checks are there to stop a wider Challenger-style disaster.
So money matters, and it often overrides simple and obvious safety issues, because when it doesn't, all monetary hell breaks lose. We see this all the time in security and in financial cryptography where basic flaws are left in place because it costs too much to fix them, and nobody can show the ROI.
The lesson then is to calculate the damage and make sure you aren't endangering the system with these flaws. When I design FC systems I try and calculate how much would be at risk if a worst-possible but unlikely crypto break happens, such as a server key compromise. If I can keep that cost under 1% of the entire system, by way of hypothetical example, I declare that "ok". If I can't, I start thinking of an additional defence-in-depth that will trigger and save the day.
It's by no means perfect, and some would criticise that as a declaration of defeat. But commercial pressures often rule the day, and a system that isn't fielded is one that delivers no security.
Risk analysis is the only way. But it's also expensive to do, far too expensive for most purposes, so we simplify this with metrics like "total system failure thresholds." For an FC system 1% of the float could be a trigger for that, as most business can absorb it. Or, if you can't absorb that, then maybe you have other problems.
5. One of the big lessons of failure is redundancy. All things fail, so all things need alternates. I can't say it better than this closing discussion in the engineering failure of the WTC:
Professor Eagar: I think the terrorist danger will be other things. A terrorist is not going to attack the things you expect him to attack. The real problem is pipelines, electrical transmission, dams, nuclear plants, railroads. A terrorist's job is to scare people. He or she doesn't have to harm very many people. Anthrax is a perfect example. If someone could wipe out one electrical transmission line and cause a brownout in all of New York City or Los Angeles, there would be hysteria, if people realized it was a terrorist that did it.Fortunately, we have enough redundancy -- the same type of redundancy we talk about structurally in the World Trade Center -- in our electrical distribution. We have that redundancy built in. I shouldn't say this, but this was how Enron was able to build up a business, because they could transfer their energy from wherever they were producing it into California, which was having problems, and make a fortune -- for a short period of time.
NOVA: Gas pipelines don't have redundancy built in, though.
Eagar: No, but one advantage of a gas pipeline is the damage you can do to it is relatively limited. You might be able to destroy several hundred yards of it, but that's not wiping out a whole city. The bigger problem with taking out a gas pipeline is if you do it in the middle of winter, and that gas pipeline is heating 20 percent of the homes in the Northeast. Then all of a sudden you have 20 percent less fuel, and everybody's going to have to turn the thermostat down, and you're going to terrorize 30 million people.
The lesson we have to learn about this kind of terrorism is we have to design flexible and redundant systems, so that we're not completely dependent on any one thing, whether it's a single gas pipeline bringing heat to a particular area or whatever.
Remember the energy crisis in 1973? That terrorized people. People were sitting in long lines at gas pumps. It takes five or 10 years for society to readjust to a problem like that. What happened in the energy crisis in 1973 was we had essentially all our eggs in one basket -- the oil basket. But by 1983, electric generating plants could flip a switch and change from oil to coal or gas, so no one could hold a gun to our head like they did before.
(Snippet taken from some site that tries and fails to make a conspiracy case. 1, 2 2nd page has snippet.)
Good stuff. Now try and design a system of money issuance that doesn't have a single point of failure - that's good FC engineering.
June 29, 2005
Mozilla drops Open in favour of Smoke Filled Rooms
Open is a big word these days. It started out as open source, being the progression of AT&T's distro of Unix leading to BSD and then to GPL. For computer source code, open works well, as long as you are doing the code anyway and can't figure out how to sell it. Instead of just keeping it secret, share the source and profit on the service.
Or something - the economic ramifications are quite interesting and deserve a much wider attention (especially with our new Hayekian and Misean perspectives, and the changing economics of digital property).
People have also applied open to other things: I apply it to Governance, there is a group working on words and music called Open Commons and this blog is under one of their licences. People have even prepared legal cases in Open forums. The list of experiments in Open This and Open That is quite long. I want to apply it to FC, and indeed we've published many papers and much source code without seeing much or any openness in FC at the project level to date, so it remains a big question: just how far does open go?
One of the things we have found is that open source helps security. People have often thought too much of this - that open source is necessary for security. No such applies, it certainly helps a lot, but so do many other things, and there are plenty of secure systems with closed source. Strangely, open also clashes with the process of fixing bugs. Clearly, if there is a bug in your source, and you know it, you want it fixed before the bad guys find out. Telling everyone that there is a bug might not be the smartest thing to do.
So security is more than source, it's a process. The security process involves many elements. Patching and bug fixes, of course. These are the things that non-security projects know about and the things that the press reports on (like those silly Symantec comments on how many security advisories each competitor has issued).
But there is more, much more, and these are the things that projects with a Security Goal have developed. One of these things is a relatively open process. What this means is that decisions on security are taken openly - in open forums. Even though uncomfortable and noisy, the result is better because the interests of all are heard, including the users, who normally aren't adept enough to enter these highly technical debates. Hopefully someone there will represent the users if they know this is an open process.
The problem with the alternate is "agenda capture" (or co-option?). If a project conducts secret negotiations to do some sort of security thing, then you can bet your bottom dollar that the participants want it secret because they are attempting some sort of coup. They are trying to achieve something that won't work when exposed to the disinfectant of open sunlight. It infringes the interests of one group or another, and if it didn't there wouldn't be any reason to keep it secret.
So it was with sadness that I discovered that the Mozilla Foundation had entered into the smoke filled rooms of secret negotiations for security changes. These negotiations are apparently over the security User Interface. It involves some other browser manufacturers - Microsoft was mentioned - and some of the CAs - Verisign has not been mentioned that I have heard.
There is no doubt that Mozilla has walked into an agenda capture process. It specifically excluded one CA, CACert.org, for what appears to be competitive reasons. Microsoft enters these things frequently for the purposes of a) knowing what people are up to, and b) controlling them. (Nothing wrong with that, unless you aren't Microsoft.) At least one of the participants in the process is in the throes of selling a product to others, one that just happens to leave itself in control. The membership itself is secret, as are the minutes, etc etc.
The rooms were filled with smoke a month or two back. And now, people are reportedly beavering away on the results, which are again secret. Normally, cartel theory will tell you that these sort of approaches won't work positively because of the economics of game theory (check out the Prisoner's Dilemma). But in this case, there was "A Result" and that "Result" is now being used as a justification for not addressing other initiatives in phishing. We don't know what it was but it exists and it has been accepted, secretly, without formal process or proposal, by Mozilla.
I have therefore departed the scene of Mozilla. This is a road to disaster for them, and it is blatently obvious that they haven't the business acumen to realise what they've been sucked into. As the security process is well and truly compromised at this point, there is no hope for my original objectives, which were to encourage anti-phishing solutions within Firefox.
Personally, I had thought that the notion of open source was enough to assume that an open process in security would follow, and a sterling effort by Frank Hecker seemed to support this. But I was wrong; Mozilla runs a closed security process and even Frank's openly negotiated CA ascendency protocol is stalled in closed session. The actual bug fixing process is documented as closed if there are security issues involved, and from that one small exception, the entire process has closed and to my mind stalled (1, 2). The team is a closed shop (you have to apply, they have to ignore the application), any security decisions are taken in secret forums that we haven't been able to identify, and the whole process flips mysteriously between the security team, the security group and the group sometimes known as "staff". Oh, and in their minds, security is synonymous with PKI, so anything and anyone that challenges the PKI model is rejected out of hand. Which is an issue for those that suggest PKI is at the heart of phishing...
So the security process is either closed or it's not present, which in my mind amounts to the same thing, because one becomes the other in due course. And this is another reason that security processes have to be open - in order to eliminate groupthink and keep themselves alive, the process must defend itself and regenerate itself, out in the open, on a regular basis.
My time there has still been very educational. Coming from the high security world of payments and then entering the medium security world of the browser, I've realised just how much there is yet to learn about security. I have a developing paper on what it means to be a security project, and I've identified about 19 or so factors. Comparing and contrasting Security Goal projects like the BSDs and the OpenPGPs with Mozilla has teased these factors out slowly, over a year or so. The persistence of security myths has led me on a search via Adam's security signals suggestion to Michael Spence's job market signalling theory and into a new model for Silver Bullets, another paper that is evolving (draft in the normal place).
But I have to face facts. I'm interested in security and specifically in the security of the browsing process under its validated threat of phishing. If the Mozilla Foundation cannot produce more than an alpha effort in certificate identification in 2.5 years of my being involved in what passes for their open security forum, that has to suggest that Mozilla is never going to meet new and evolving objectives in security.
June 26, 2005
Nick Szabo - Scarce Objects
Nick Szabo is one of the few people who can integrate contracts into financial cryptograpy. His work with smart contracts echoes around the net, and he last year he gave the keynote presentation at the Workshop on Electronic Contracts. In this paper he seeks to integrate scarcity and property constructs with the object oriented model of programming.
Scarce objects, a.k.a. conserved objects, provide a user and programmer friendly metaphor for distributed objects interacting across trust boundaries. (To simplify the language, I will use the present tense to describe architectures and hypothetical software). Scarce objects also give us the ability to translate user preferences into sophisticated contracts, via the market translator described below. These innovations will enable us for the first time to break through the mental transaction cost barrier to micropayments and a micromarket economy.
A scarce object is a software object (or one of its methods) which uses a finite and excludable resource -- be it disk space, network bandwidth, a costly information source such as a trade secret or a minimally delayed stock quotes, or a wide variety of other scarce resources used by online applications. Scarce objects constrain remote callers to invoke methods in ways that use only certain amounts of the resources and do not divulge the trade secrets. Furthermore, scarce object wrappers form the basis for an online economy of scarce objects that makes efficient use of the underlying scarce resources.
Scarce objects are also a new security model. No security model to date has been widely used for distributing objects across trust boundaries. This is due to their obscure consequences, their origins in single-TCB computing, or both. The security of scarce objects is much more readily understood, since it is based on duplicating in computational objects the essential security features of physical objects. This architecture is "affordable" in Donald Norman's sense, since human brains are designed to reason in much more sophisticated ways about physical objects than about computational objects. It is thus also "affordable" in terms of mental transaction costs, which are the main barrier to sophisticated small-scale commerce on the Net. Finally, it will solve for the first time denial of service attacks, at all layers above the primitive scarce object implementation.
Comments below please!
Marc Stiegler - An Introduction to Petname Systems
Petnames evolved out of hard-won experience in the Electric Communities project, and went on to become a staple within the capabilities school of rights engineering. But it wasn't until Bryce 'Zooko' Wilcox made his dramatic claims of naming that petnames really discovered their place in the financial cryptographer's armoury.
Petnames were previously undocumented in any formal sense and disseminated by word of mouth and tantalising references such as Mark Miller's Pet Names Markup Language. Marc Stiegler, visiting researcher at HP Labs, has now stepped up and collected the community knowledge into one introductory piece, "An Introduction to Petname Systems." He has done us a grand service and deserves our thanks for putting petnames onto an academically sound footing:
Zooko's Triangle argues that names cannot be global, secure, and memorable, all at the same time. Domain names are an example: they are global, and memorable, but as the rapid rise of phishing demonstrates, they are not secure.
Though no single name can have all three properties, the petname system does indeed embody all three properties. Human beings have been using petname systems since long before the advent of the computer. Informal experiments with Petname-like systems in computer-oriented contexts suggest that petnames are intuitive not only in the physical world but also in the virtual world. Proposals already exist for simple extensions to existing browsers that could alleviate (possibly dramatically) the problems with phishing. As phishers gain sophistication, it seems compelling to experiment with petname systems as part of the solution.
We seek comments below. Petnames is a very important concept in naming and if you design complicated financial cryptography systems it will be well worth your while to be at least familiar with the arguments within.
| Marc Stiegler |  |
June 16, 2005
Miller & Shapiro on Hayek's market - explaining object orientations
I was struck how the Introduction to Miller & Shapiro's new paper on concurrency control sought to integrate economics and programming. Here's the Introduction, stolen in fine Hayekian tradition for your reading pleasure. The paper is for full publication in proceedings of Trustworthy Global Computing (so it will miss out on the bona fide FC++ advantage) but I couldn't help from letting slip this teaser!
The fundamental constraint we face as programmers is complexity. It might seem that the systems we can successfully create would be limited to those we can understand. Instead, every day, massive numbers of programmers successfully contribute code towards working systems too complex for anyone to understand as a whole. Instead, we make use of mechanisms of abstraction and modularity to construct systems whose components we can understand piecemeal, and whose compositions we can again understand without fully understanding the components being composed.
To understand these twin problems, of separating components and of composing them, we draw on Friedrich Hayek's examination of how markets address the twin problems of plan coordination: bringing about the cooperative alignment of separately conceived plans, while simultaneously avoiding disruptive plan interference [Hayek45]. His explanation of the need for property rights parallels the rationale for encapsulation in object-oriented systems: to provide a domain (an object's encapsulation boundary) in which an agent (the object) can execute plans (the object's methods) that use resources (the object's private state), where the proper functioning of these plans depends on these resources not being used simultaneously by conflicting plans. By dividing up the resources of society (the state of a computational system) into separately owned chunks (private object states), we enable a massive number of plans to make use of a massive number of resources without needing to resolve a massive number of conflicting assumptions.But a single object cannot do much by itself. Instead, both objects and markets use abstraction to compose plans together into vast cooperative networks, such as subcontracting graphs, where one agent, employing only its local knowledge, will subcontract out subtasks to others, often in great ignorance of how each subtask will be carried out [Lachmann, Lavoie, Tulloh02].
"Programmers are not to be measured by their ingenuity and their logic but by the completeness of their case analysis. Alan Perlis"The problem Hayek was concerned with, how humans coordinate their plans with each other, certainly has many differences from the world of programming. For purposes of this paper, the most interesting difference is that, in the human world, the intelligence of the entity who formulates a plan is comparable to the entity who executes the plan. Therefore, the plan doesn't have to prepare for every possible contingency. If something unusual happens, you'll probably be better able to figure out what to do then anyway. By contrast, when writing a program, we must express a plan that can deal with all possible relevant contingencies. Even under sequential and benign conditions, the resulting case analysis can be quite painful. As we extend our reach into concurrency, distribution, and mutual suspicion, each of these dimensions threatens an explosion of new cases. To succeed at all three simultaneously, we must find ways to reduce the number of additional cases we need to worry about.
Mark later pointed out that he and Bill Tulloh have an entire paper on the Austrian market process, Institutions as Abstraction Boundaries.
June 14, 2005
A hand of Pennies
Adam points at the Underhanded C Contest. This is a good idea - write some C which is totally readable but does something underhanded. This year's challenge is to do some basic image processing but to conceal a fingerprint in the image you spit out.
I don't know whether this will work or not but it will be fun to see a new generation of hackers try (I'm too old for such tight elegant and intraverted code). Any bets as to whether the contest sponsors are in the DRM camp or the anti-DRM camp?
More news of techies fighting back to get some respect. Dbourse / slashdot / LA Times says the $100,000 Poker Bot Tournament is now ON! Tickle your PRNGs, tune and prune those search trees, limber up those card dealing digits.
+--------------------------------------------------------------------+ | $100,000 Poker Bot Tournament | | from the upped-my-bet-now-up-yours-robot dept. | | posted by timothy on Sunday June 12, @21:28 (Programming) | | http://games.slashdot.org/article.pl?sid=05/06/12/2326207 | +--------------------------------------------------------------------+[0]Costa Galanis writes "The LA Times is reporting that a poker tournament will be held where engineers will be able to [1]pit their automatic poker-playing programs against each other in a tournament similar to the upcoming World Series of Poker main event, with a 100,000 dollar cash prize for the winning program. The article mentions how the recent rise in popularity of poker has encouraged many to try and create the poker equivalent of chess' Big Blue, the chess playing computer program that defeated the world's top chess player in a widely publicized event, and also talks about how many engineers also are trying to make bots that are good enough to play and beat human players for money in online casinos." Discuss this story at:
http://games.slashdot.org/comments.pl?sid=05/06/12/2326207
Links:
0. mailto:cgalanis@gmail.com
1. http://www.latimes.com/news/printedition/la-fi-pokerbots12jun12,0,6050364.story?track=mostemailedlink
Bruce Schneier reports in this month's Cryptogram that "Sudanese currency is printed on plain paper with very inconsistent color and image quality, and has no security features -- not even serial numbers. How does that work? Because anyone who counterfeits will be put in front of a firing squad and shot." This link doesn't check out the story, but FC historians will recall that forgery was kept to basically zero in the scottish banking period by two rules: any forged note would be paid out in full by the bank if you cooperated with their investigation, and when they found the forger they hung him.
More links in Cryptogram point to info on the T-mobile hack - it was mostly social engineering. Also a fascinating and learned article on phishing from the Honeypot projects - I learnt some good stuff in there. Check out this corker of an observation:
"Parallel phishing operations are also indicated by the timing of the first inbound HTTP request for phishing content after the UK honeypot was compromised:2004-07-23 21:23:14.118902 XXX.XXX.XXX.XXX -> 10.2.2.120 HTTP GET /.internetBankingLogon HTTP/1.1
This inbound HTTP request to the honeypot occurred before the attackers had finished setting up the fake online banking content on the honeypot, and confirms the hypothesis that the attacker knew in advance that this server was available for use as a phishing web site. Spam messages advertising the new phishing web site were already being emailed to victims from another host, even whilst the attacker was setting up the new phishing web site."
A coordinated attack, a pincer movement! It's war out there.
June 10, 2005
Virus-safe Computing - HP Labs article
Mark Miller reports on a nice easy article from HP Labs. A must read!
Check out the current cover story on the HP Labs web page! |  |
Research on how to do safe operating systems is concentrated in the capabilities field, and this article worth reading to get the flavour. The big challenge is to how to get capabilities thought into the mainstream product area, and the way the team has chosen to concentrate on securing Microsoft Windows programs has to be admired for the chutzpah!
Allegedlly, they've done it, at least in lab conditions. Can they take the capabilities and POLA approach and put it into the production world? I don't know but the research is right up there at the top of the 'watch' list.
June 01, 2005
Software Licensing and the Know-how to Issue
Software charging for big ticket sellers is getting more complex again, as dual cores from AMD and Intel start to invade the small end. Oracle, which made billions charging on the muscle power of CPUs, will have to do something, and we've by now all seen IBM's adverts on TV suggesting "on demand" with its concommitant charging suggestion: You demand, we charge.
I've done a lot of thinking over the years about how to licence big ticket items like issuance software. In practice it is very difficult, as the only revenue model that makes sense for the supplier is for large up front licence fees to recover large up front capital and sunk costs. But for the demander (issuer and user of the software) the only model that makes sense is to pay later, when the revenues start flowing...
Issuance software has all the hallmarks of an inefficient market and I don't think there has been successful case of issuance licencing yet, as those two "sensible" options do not leave any room for agreement. This may be rational but it's very frustrating. Time and again, we see the situation of people wanting to get into the issuance market who think they can produce the software themselves for a cheaper price. And they always end up spending more and getting a lesser quality product.
In practice what we (Systemics) have been doing is this: running the software ourselves as "operator", and charging operating costs, with some future licencing or transaction flow revenues. Yet, the deal for future revenues is always based on a promise and a prayer, which is already asymmetrical given that most startups do no more than start up. (And it isn't just me bemoaning here - if you look back through history there are literally hundreds of companies that tried to build value issuance and sell it.)
Which leads to the freeware model. In the freeware world, big ticket items are given away and money is made on the consulting. This has worked relatively well in some areas, but doesn't work so well in issuance. I'm unclear of the full reason why open source software doesn't work in issuance, but I think it is mostly the complexity, the sort of complexity I wrote about in FC7. It's not that the software can't capture that complexity but that the financial cryptography business often finds itself so squeezed for management complexity that partnering with a strong software supplier are beyond capabilities.
What will potentially help is p2p issuance. That is, "everyone an issuer." We've always known this model existed even as far back as 1995, but never really considered it seriously because too many questions arose. Little things like how we teach grandma to sign a digital contract. We've now done enough experiments in-house to confirm that the corporate internal issue and the individual issue are workable, sustainable economic models but we have to get other companies and individuals to do that and for the most part they still don't do anything they don't understand.
I'm guessing the way forward here is to turn client software into issuance software. This brings up a whole host of issues in financial cryptographic architecture. For a start it can never seriously scale simply because people do silly things like turn off their laptops at night.
But, more and more, the barriers to issuance and financial cryptography in general I believe are spreading the knowledge, not the tools and tech. Every year our tools and tech get better; but every year our real barriers seem the same - how to get users and customers to make their first tentative issue of a currency of value. Oh, and how to make money so as to keep us all alive, which was the starting point on this long rant of liberal licence.
A couple of footnotes: In a similar thread over at PGP Inc, Will Price reveals how they've managed to get out of the legacy freeware version trap:
"When the 30 Day Trial version of PGP Desktop Home expires, it reverts to a set of functionality comparable to what used to be known as Freeware, and said functionality remains available indefinitely -- under the same license conditions as Freeware used to be under."
Nice one. That works for client software, not for server software.
Here's a further article on how the big companies are also working out how big ticket software isn't the way to go:
May 16, 2005
SSL for FC - not such good news
Some random notes on the adventure of securing FC with SSL. It seems that SSL still remains difficult to use. I've since found out that I was somewhat confused when I thought we could use one Apache, one IP# and share that across multiple SSL protected sites.
Quick brief of the problem: the SSL tunnel is set up and secured _before_ the HTTP headers tell the server what site is required. So there is no way to direct the SSL tunnel to be secured with a particular certificate, like the one for FC as opposed to the one for enhyper. That's a fundamental issue. That means that the cert used is fixed for IP#/port, and it contravenes Iang's 1st law 2nd hypothesis of good security protocols, to whit, "a good security protocol is divided into two halves, the first of which says to the second 'use this key.'" What arrogance!
I thought this was fixed in TLSv1 (which hereafter I'll assume as including SSLv3). Yes it is in this way: TLSv1 has a new extension in the HELO message to permit the browser to hint at what site it wants. No it is not in this way: Neither mozilla browsers nor Apache web servers implement the new extension! Worse, there is no agreement among the SSL and HTTPS sector as to how to do this.
Sheesh!
If you, like me, happen to think that more SSL will be useful in dealing with phishing (because Alice can use the cert/CA as a handle to her favourite bank) then you can vote and again for these two bugs. (You will need an account on Mozilla's bugzilla system, which I use mostly for an occasional vote).
If on the other hand you feel that phishing is ok, perhaps because the security system really wasn't meant to protect people from doing stupid things, or because money and fools should be parted, or because it hasn't happened to you yet, or for any of a myriad of other reasons, then ... don't vote (If I can figure out the same thing for Apache I'll post it.)
It seems that the desiderata to use SSL widely is shared by a brave few (other) fools over at CACert who have set up a Virtual hosts task force! Good for them, we will no longer have to worry about reaching old age in loneliness, muttering to ourselves that security wasn't meant to be this hard. CACert are experimenting on how to do this, but so far the work-around seems to be that you issue a cert that includes all the names of all the sites. Which means there is now no certificate-based independence between administrative sites - definately a kludge.
While on the topic of SSL & security, CACert's blog reports on a meeting between Comodo and Mozilla Foundation to mount a common front to phishing. "Some CAs and browser manufacturers" have been invited. More power to them, more talk is needed, spread the message. Start with:
"We have a problem with phishing."
and carry on to:
"It's our problem."
Gervase has done a white paper for the CA/browser summit called "mproving Authentication On The Internet." Good stuff.
May 08, 2005
Getting Apache to encrypt
I've been trying to figure out why Apache is presenting the wrong cert to browsers (which people then click through...) which has led me to looking at Apache's cipher suite setup as I know we need to turn off SSLv2 everywhere. It is an exercise in self-flagellation to understand SSL's approach to consumer choice and Apache does not let the side down here.
SSLCipherSuite ALL:!ADH:!EXPORT56:-SSLv2:RC4+RSA:+HIGH:+MEDIUM:+LOW:+EXP:+eNULL
As I read the string above that I inherited from gawd-knows-where, they allow for no encryption as the last acceptable suite. Huh? Yep, the cipher negotiation +eNULL allows you to authenticate yourself and then negotiate a null cipher! In other words, it is ok to broadcast your password to the world as long as we have ensured it eventually ends up at the right place. Comforting to know. On the other hand !ADH says you cannot set up an opportunistic encryption without certificates at all, so it's definately evil to use encryption unless you know who you are talking to.
So, here's how to turn off SSLv2 (something that should be done by default so we can increase the use of SSL) and set up useful encryption:
SSLProtocol all -SSLv2
SSLCipherSuite ALL:!SSLv2:!EXPORT:!NULL:!LOW:+ADH
Makes sense, ok? If you dare to suggest that you don't understand, go and stand in corner until you've learnt the correct attitude.
Jokes about inadequacy aside, I've turned off all the small key ciphers and permitted a fall back to anonymous Diffie-Hellman. Not because anyone is going to use it (as it has to be negotiated by the other side, just like the null ciphers I turned off) but because it might be nice to experiment with.
Of course, what this exercise means in the large is obvious: all sorts of rubbish is being set in the cipher suites as people copy and paste other people's mistakes around. Sysadmins don't have time to deal in this nonsense, all they want is to get some basic protection for their users as they already have enough to do just getting SSL to boot let alone tuning this cipher or that one.
What the software should do is bootstrap the crypto to the best of opportunistic ability. This time and every time. I am more firmly convinced than ever that a good crypto protocol has one and only one cipher suite, it is good and complete, and it is numbered #1. In two years, we might or might not come out with #2. In the meantime, that's what you get for free - and it's a darn site more secure than giving you a choice of hundreds of mistakes to make and charging you for the privilege.
Meanwhile, I still don't know why Apache is presenting the wrong cert ... so more on that later.
May 07, 2005
Securing with SSL - an experiment
SSL is now used to protect the FC blog. It's an experiment. You will be bothered by a CACert, so I suggest you go to this URL: http://www.cacert.org/index.php?id=3 and install the CACert root certificate into your browser. Or go here for some help notes. The CACert guys are good guys, and their verification model is face to face rather than paper.
Also, you should turn off SSL v2 in your browser otherwise you will see enhyper.com instead of FC!. This is an older version of the protocol that breaks when trying to access multiple SSL sites over the same IP#. Sorry about that, the people who ship browsers should be turning it off for you as it would enable a lot more security. (Tell them!) If you end up on a different site after clicking around, that's what has happened. And if you find any site that still uses SSL v2, let us know and we'll send them into perdition.
The reason using SSL is novel and experimental rather than routine and boring is because SSL is not set up to protect browsing, but rather to protect ... well, that's not exactly clear - but it is strongly swayed to high value installations and complex installs. What that means is that if you have sysadmins on hand and programmers who know what they are doing then protecting with SSL can be done; for the rest of the world, expect a messy compromise, which is what you will see here, or no protection at all.
A good crypto protocol protects everything all the time - it's good because it doesn't expose the user to dodgy compromises or to expensive solutions that may break down due to their complexity. Simplicity is more than a virtue in protocol design, it's a necessity, and SSL shows little of it.
Ideally, all-the-time is what browsing should do, and when it doesn't, it should be easy to upgrade. People who disagree say that server load and time delay make protecting huge graphical downloads a fruitless exercise. I think this happens to be a particularly weak case, given the vast number of servers (around 1-10 million) sitting on the Internet doing nothing. Yes, more than 99% of them would be sitting at less than 1% activity. Right now, this server is hovering between 99.7% and 100.0% of idle. Give it some work I say!
I have layered the blog so that ordinary unprotected browsing is still a starting point (so http URLs will still work) but the site itself now uses https URLs everywhere. That's not intelligent on my part, that just seems to be the only way to do it such that it doesn't suck (this is my third or fourth method). So you will be sucked into SSL as you click around. Don't be afraid!
In terms of security, this means you won't be eavesdropped. Those critical comments will now not be so easy to track, and your browsing pleasure will remain private. It isn't much, I know, but there again, it's free and it should be the standard.
And, please feel free to grumble - this blog is for its readers. I'm not religiously devoted to SSL as you all know and if it fails to work, we'll discard it.
April 19, 2005
Dave Birch - the case for RFIDs is cost
Dave Birch gave a talk at a new venue called RFIDUK, which was held in the august and ceremonial halls of the Theodore Bullfrog. One point that struck me was his comment that RFIDs are fast and reliable and they almost make their case on this alone. That is, communication is made within 100 millisecs or so, and it is done without the mechanical pain of older systems like smart cards or swipes.
Speed itself is one reason why mass transits love these things. In the queue for the mass transit, a one second delay versus a three second delay can be enough to trigger a riot when fans want in and on to get to the game. Reliability and maintenance speak for themselves; anyone who's worked big systems knows what these numbers do to your overall report card.
But when it comes to things like passports, I'm uncertain. I've not of late seen a situation where 100ms response times makes any impact on passport checks. Certainly a few years back passports (and their holders) were waved through on colour and size, no more. Then, there is reliability. And, in fact, there again I'm not so sure; if a chip is mucking up, isn't that something where you want to check up on?
RFID passports are expected to have photos, etc on them. If they are so important, then a few seconds ain't going to make any difference.
Otherwise, we could seriously talk about not even waving them, but just walking through at range. There's a thought! If we are going RFID, let's get the full benefit: 3 metre range and no wave, no pause. If the immigration watcher wants to check the photo, scan it and be quick about it, mate, coz I've got bags to collect, and the spouse is waiting!
April 16, 2005
The Twilight Zone
 Those that are deep into transactional database work, as everyone in payment systems and the like is, know there is a deep dim and ghostly place that we all fear. I've just walked that through that place, and as soon as I saw it, I know I was staring at the Twilight Zone.
Those that are deep into transactional database work, as everyone in payment systems and the like is, know there is a deep dim and ghostly place that we all fear. I've just walked that through that place, and as soon as I saw it, I know I was staring at the Twilight Zone.
The Twilight Zone is a special nightmare for database engineers. It is when your transactional set forks into two; both are correct because they are transactions, after all, but both places are wrong because of the other place. Worse, the further time passes, the more chance of more forks, more and more places, all in the same zone. It is when the time-space continuum of your data fractures and spreads out in an infinite tree of possibilities.
I've always known it existed. When you've travelled so many databases, so many scenarios, you realise that the perfect database doesn't exist. Software is meant to fail, and getting it right today just means it will really go wrong tomorrow. For nine years, tomorrow never came, until one day in Vienna, I discovered a whole issuance of newly minted gold, Euro and sterling had just ... vanished into another space. It took me over two days of isolating and isolation before I realised where I was. And where I was.
(A brief digression for the non-digerati: database software does transactions, which are like records or receipts or sales or somethings that have special characteristics: they happen once and once only, if they happen at all, and if they happen, they happen forever. We call them atomic, because they either do or they don't happen, we can't divide them into half-happens. We do this because when we move money from one place to another, we want to make darn sure it either moves or it doesn't. No halfway house. And no going back, once we got there. We actually care so much about this that we don't really care which it is - happens or not happens!)
So when my fresh gold decided it had happened and not happened, I was sucked into the Twilight Zone. The reason it exists is quite fundamental: transactional software is perfect in theory, but implementations are flawed. No matter how much care you take, changes occur, features get added, bugs need to be fixed; step by small baby step, the logical beauty of your original design flits and dances towards the forking point. With all software, everywhere, no matter the manufacturer's guarantee, there will always be the possibility of so many bugs and so many patches and so many engineers who didn't understand, all one day coming together to split your state into the twilight zone.
This is why space shuttles blow up. Why Titanics sink, dams collapse, power grids shut down, and stock exchanges melt down. It's not because of a lack in the quality of the people or the software, it's because of the complexity of the system. Fundamentally, if you got it right, someone will build a better system on yours that is 99% right, and reliant on yours 101%. And the next person will layer their opus magnum over that great work and get that 98% right... and so it goes on until the mother of all meltdowns occur.
Specifically, what happened was an event notification - a new feature added in so as to enable chat broadcasts via payments - had a dodgy forwarding address. Which would have been fine, but the change to fix that broke. Which wasn't picked up in testing, because it didn't break in quite that way, but was picked up by a recovered transaction which did look it in exactly that way, which in turn failed and then went on to block another transaction in recovery. (Long time hackers will see a chain of bugs here, one tripping another in a cascade.)
This last transaction was a minting transaction. That means, it created value, which was the sterling I mentioned earlier (or gold, or Euro, I forget). Which, by a series of other unfortunate events caused yet another whole chain of transactions to fail in weird ways and Shazam! We entered the twilight zone where half the world thought they had a bucket of dosh, and the other half did not.
Fixing the bugs is obvious, boring, and won't be discussed further. The real issues are more systemic: it is going to happen and happen again. So infrequently that its very rarity makes it much more traumatic for its lack of precedent. It is very hard to create procedures and policies to deal with something that hasn't happened in living memory, would be fixed immediately if we knew how it was going to happen, and is so not-going-to-happen that the guarantee doesn't permit it. Nor its solution, nor even the admittance of the failure.
So how do we deal with the twilight zone? Well, like quantum physics, the notion is to look at the uncertain states and attempt to collapse them into one place. With luck this is possible, simply by re-running all the transactions and hoping that it all works out. With bad luck however, there would be a clash between transactions that resulted in leaving the twilight zone the wrong way, and being splintered forever: Simply put if I had given money to you in one place, and to your sister in another place, when the two places collapsed into one then the time-space of accounting would rip asunder and swallow us all, because money can't exist in two states at once. It would be light and day together for evermore. At the least, permanent migraines.
Which leads me to our special benefit and our own fatal curse: the signed receipt. In our transactions, the evidence is a receipt, digitally signed that is distributed to all the accounts' users. This means we as issuers of contractual value are locked into each and every transaction. Even if we wanted to fiddle with the database and back out a few tranasctions to pretend your sister doesn't exist, it won't work because the software knows about the signed transactions. This trick is that which I'd suggest to other databases, and that's why we signed the receipts in the first place; We never wanted that to work, and now it doesn't. Stuck, we are.
 It does however mean that the simple tactical phase is a good starting point: re-run all the transactions, and live with the potentially broken accounts, the accounting time-space rent asunder if so discovered. How we'd deal with that is a nice little question for our final exam in post-graduate governance.
It does however mean that the simple tactical phase is a good starting point: re-run all the transactions, and live with the potentially broken accounts, the accounting time-space rent asunder if so discovered. How we'd deal with that is a nice little question for our final exam in post-graduate governance.
My walk through the twilight zone was then guided by a strategy: find all the signed receipts, and re-run them. Every one, and hope it worked out! Luck was indeed on my side this time, as it was a minting that had failed, so the two places were cleanly separated in the zone. I had to fix countless interlocking bugs, make yet more significant feature changes, and conduct days worth of testing. Even after I had done all this, and had watched the thrilling sight of 10 transactions reborn in my preferred space, I still had only the beginnings of a systemic solution to the problem of walking the twilight zone.
How to do that is definately a tricky problem. Here are my requirements so far: even though it should never happen, it must be a regular occurrence. Even though the receipts are scattered far and wide, and are unobtainable to the server, we must acquire the receipts back. And, even though we cannot collapse the states back when they have forked too far, we must re-engineer the states for collapse.
I have the essence of a solution. But it will have to remain on the drawing board, awaiting the next dim opportunity; as no-one willingly walks into the Twilight Zone.
April 13, 2005
Going Binary, half a bit at a time
The Champion of NerdHerders points to the pathological habit of nerds-gone-binary to do either all of it or nothing. It's true, that we all face this inability to create a sensible compromise and to recognise when our binary extremes are unacceptable.
But I don't think it is so black and white. It's alright to say "why not use Jakarta this/that/other" but in practice it tends to hit up against some real barriers.
Firstly, what happens if you don't spend your entire life following the esoteric and mindboggling silly arguments as to whether this tool is better than that tool? How are you to know what tool to use?
In practice, in a big enough team, there is a role for tool-meister. Or package-tamer. But for most teams, that luxury simply isn't there. My own feeling is that any tool I know about, if I can't see the fit within an hour of reading, then that's it, it's all over, and most tools aren't set up to come anywhere close to that. (So to eat my own dogfood I spend a lot of time writing executive summaries to bridge that gap, but I also recognise how few times I've succeeded!)
My general strategy is to ignore all tools, all competitors, all everything, until I've had about 3 independent comments from uncorrelated sources. The alternate is to drown. My strategy gets about a 99%hit rate, as within a year, last year's flavour is gone, replaced, forgotten. (Last year it was all Struts, this year, Spring. Do I add to last year's wasted effort with another month on Spring this year?)
Secondly, it is my overwhelming impression that most tools out there are schlock. They are quite literally junk, pasted over with some sugar coating and lots of enthusiasm. Now, that's nice and I'd fight for the right to let those people do that, because some of them aren't, but in practice, I don't want to spend a month fighting someone else's schlock when I could do the same with my own code.
Sometimes this works out: the most extreme case was the accounting engine I wrote. It took a month to do the whole thing. I estimated it would take a month just to create the _recovery strategy_ for an off-the-shelf database engine. (It will still take a month, no matter what, I think. That's because it has to work, in FC.) So for one month's effort, we've got a free engine that is totally tuned to our needs. The next best thing is Oracle, and that starts at five figures. Per unit. And climbs...
Sometimes this doesn't work out: our approach to writing a website framework for payments was a costly 2.5 year lesson in how hard it is to create good frameworks. But, even when we wanted to replace our stuff, the choice was and is shlock. I spent some months learning the J2EE frameworks, and concluded they are not going to cut down the time by so much. Plus, they're Schlock, I have no confidence in the security of J2EE and no confidence in the manageability of it. (Now, 4 years after the fact, someone wrote a J2EE framework that does the job. Even that had to be rewritten by the first programmer on the job.........)
Thirdly, when you are dealing with other people's tools, you create an admin load. The more tools the more load. The more you have to install, the more that can break. And, this not only hits you in the cost-of-server shorts, it can blow you away legally, as some tools come with poison pills that just aren't predictable (and, I'm not just speaking of licences here, but needs for support, costs in programmers, etc etc). The same with languages; Java is a cost, because there is so little support for non-preferred platforms, Perl is a cost because it isn't 64bit compatible in all senses yet, PHP is a cost because every time they up the revision, the language shifts on you ... on and on it goes, always trouble, and it grows with at least proportional to the number of tools.
It's tough. I think there is a desperate desire in the programming world to churn out a solution so damn quickly it's as if it came out of a recipe book, and anything else is unacceptable. That's not a real picture of the world, especially if you are building software that has to be relied upon.
On the other hand, what is easy is when someone says "oh, you should use XYZ" and really mean it. It's extraordinarily rare that they know what they are talking about, and it's a great differentiator between some junior nerd who's still in slashdot space, and someone who's actually been stabbed by tools and knows stuff.
April 12, 2005
GeoTrust says existing PKI practices are worthless
GeoTrust published a three part attack on the current certification practices that leave users unprotected and wide open to phishing (Exec Summary, shots of Opera being spoofed, and a white paper). In essence, they say that current vetting procedures (which they call first generation) are easy to foil. In particular, Opera's display of the company name on the chrome is flawed, and will actually make matters worse, as that information is not and has never been reliable.
Simply because, they say, it's never been relied upon! So all sorts of garbage gets in there, something I discovered today when my newly installed TrustBar said that the name for www.DnsMadeEasy.com was Tiggee ! Where did that come from?
GeoTrust's solution is that the browser should display both the domain name, being:
"the only piece of data in a digital certificate that's confirmed, guaranteed to be unique, and is registered with an official public domain registry,"
and also:
"The name and logo of the CA who issued the certificate. Consumers will soon learn from news reports which CAs to trust and which CAs use sloppy procedures and should not be trusted."
Hallelujah to that! OK, so now a well known CA has broken ranks and revealed the awful dirty truth behind the PKI. It sucks. It's useless. What are we going to do about it? Or more importantly, what are the browser manufacturers going to do about it?
What this space...

April 05, 2005
Amit Yoran - biggest fubar is 'certification'
Amit Yoran has a certain sort of positive, honest enemy reputation, perhaps reinforced because he actually left the job of DHS cybersecurity head after a year. He was asked by Todd Datz:
What were your biggest frustrations during your tenure at DHS?
"Perhaps a lack of effectiveness in much of the government's security practices, a lack of practicality. There's a phenomenal amount of paperwork around certification and accreditation. There's a significantly sized industry around Washington, D.C., running paperwork exercises on cybersecurity, as opposed to investing in improved operations and implementing security technologies."Take, for example, NIAP [National Information Assurance Partnership]. The Department of Defense says it won't procure any products that haven't been through this certification process. It takes several quarters, if not years, and costs millions of dollars. And what comes out at the end is an approved product for that specific platform, for that version of technology. So you can't apply patches and fixes because it violates your certification. It's a paradigm, an academic exercise. The practical implementation of it-the practical improvement on cybersecurity-is zero. In fact, most people don't even understand what the NIAP certification gets you; it doesn't say your product is secure or doesn't have flaws.
-----
-Todd Datz
April 02, 2005
Old tech never dies - fax machines
The fax machine refuses to die. Check the below and notice how many clues there are in the use of signatures and paper records; you can see these clues in the Ricardian contract, where we insist it is printable and we go to extraordinary lengths to entangle it in lieu of a visual signature. The big message: tech needs to meld with old ways, not demand to replace it.
The fax machine refuses to die
By Robert Johnson The New York Times Tuesday, March 29, 2005
Older technology still not obsolete
In an office world that has gone largely digital, hand-held and wireless, the fax machine is ancient technology that just will not go away. No one shows off their fax machine the way they might, say, a BlackBerry. Yet the fax persists as a mockery of the much-predicted paperless society.
Ask Rodney Eddins. If any of his accounting clients want his undivided attention at work first thing in the morning, they should shun e-mail or his telephone answering machine. Instead, they should send him a fax.
"The first thing I look at when I arrive is the incoming tray of my fax machine," said Eddins, a certified public accountant in Orlando, Florida. "If there's paper there, I feel like I have to look at it." Only after he sorts through the faxes of the morning - though most on a recent day were ads - does Eddins log on to his computer and listen to his phone messages.
Still, like many other people, Eddins readily acknowledges a tortured relationship with his fax machine. Finding it essential for transmitting sensitive accounting documents and forms that require signatures, like tax returns, he grudgingly tolerates the noise and mess, not to mention the deluge of junk faxes.
"I actually hate my fax machine," he said. "But I need it."
Jonathan Bees, a former product manager for office machines at Konica, who is now editor in chief of Better Buys for Business magazine, said, "Back in the mid-1990s, when e-mail was really coming into its own, we had high-priced consultants telling us that the fax was going the way of the horse and buggy." Among the products he reviews for consumers these days are fax machines.
"They're better than ever - quieter, faster and with clearer reproduction," he said. "They haven't been passed by, after all."
Some 1.5 million fax machines were sold in the United States last year for use at both businesses and homes, according to the Consumer Electronics Association. Manufacturers estimate that they sold 500,000 more machines that combined a fax function with other functions, like copying and scanning.
Although sales of stand-alone fax machines are well below their peak of 3.6 million in 1997, some manufacturers say that if the multiuse machines are included, demand has been rising of late. "We have been seeing an increase in fax sales for the last four or five years," said Paul Fountain, marketing product manager at Hewlett-Packard in San Diego.
In 1994, Hewlett-Packard left the fax market, believing the predictions of impending obsolescence. "We came back in 1998," Fountain said, "because we realized the fax was not going away."
While fax machines are not as prevalent as computers in the workplace or home offices, Bill Young, a communications coach at Strickland Group in New York City, said, "The fax has important functions that e-mail simply hasn't been able to take over." Those would include reproducing signatures on documents like contracts, business proposals and medical prescriptions.
CVS, a 5,300-store chain, relies on fax machines as the most common means of receiving prescriptions, said a company spokesman, Todd Andrews. "The fax gives the pharmacist a written record of what the doctor ordered," he said. Faxing avoids misunderstandings that can occur when prescriptions are phoned in.
http://www.iht.com/bin/print_ipub.php?file=/articles/2005/03/28/business/fax.html
March 24, 2005
VCs Suck, but you can still store your data on FreeBSD
Adam points to an essay by Paul Graham on A Unified Theory of VC Suckage. Sure, I guess, and if you like learning how and why, read it and also Adam's comments. Meanwhile, I'll just leave you with this amusing footnote:
[2] Since most VCs aren't tech guys, the technology side of their due diligence tends to be like a body cavity search by someone with a faulty knowledge of human anatomy. After a while we were quite sore from VCs attempting to probe our nonexistent database orifice.No, we don't use Oracle. We just store the data in files. Our secret is to use an OS that doesn't lose our data. Which OS? FreeBSD. Why do you use that instead of Windows NT? Because it's better and it doesn't cost anything. What, you're using a freeware OS?
How many times that conversation was repeated. Then when we got to Yahoo, we found they used FreeBSD and stored their data in files too.
Flat files rule.
(It turns out that the term of art for "we just use files on FreeBSD" is flat files. They are much more common than people would admit, especially among old timers who've got that "been there, done that" experience of seeing their entire database puff into smoke because someone plugged in a hair dryer or the latest security patch just blew away access to that new cryptographic filesystem with journalling mirrored across 2 continents, a cruise liner and a nuclear bunker. Flat files really do rule OK. Anyway, back to debugging my flat file database ...)
February 26, 2005
Software by the Bootcamp method
Twan points at an article on software teams boot camp that takes a highly military process. Worth reading if you touch software. There are a number of insights in there.
Another article he points at is also worth reading. It's the Shuttle Team. Although this might sound inspiring, it's not as relevant to the real world of software as all that; we don't have a single unchanging machine, we don't have the understanding required to create a 2,500 page spec for a 6,366 line change, we don't care if it crashes, and don't have the money to pay for any of that. Still, some of the things in the article resonate, so it is good to read and isolate what it is that is applicable to your world and what's not.
February 18, 2005
The Goal of Security
Jeroen van Gelderen once made the remark that FreeBSD has a security goal, but OpenBSD has *the* security goal.
Coming from a goals oriented background - more about that later - I immediately understood and thought no more of it. Now I want to find out more, and ... it seems this is not a formal position of the open source operating systems, but more an informal shared understanding. Hence Jeroen's remark was even more perceptive, and I have no easy guidelines to copy from.
The Goal of Security is quite significant. As part of this both OSs have security officers. A security officer is often someone with quite significant power; to coordinate patches, but he or she can also hold back releases and effect inclusion or exclusion of packages. (Now, that might not sound all that significant in normal project management terms, but in the Internet world of open source, where rough consensus rules and most of the work is done by people who are unpaid, it's a big deal. It's recognition that when it comes to security, rough consensus might not be the only way to do things. And it's about the only override to that rough and ready world.)
As well as the security officer, there are also policy statements on how exploits are handled, and disclosure methods. Generally, in a Security Goal oriented project, anyone can report a security bug, and there are often easy ways to do it. If one has ever tried to report a bug through formal channels, one knows that having informal methods to report a bug is worth a lot.
There are also security subprojects within, such as code audits, module rewrites, and cross-divisional re-alignments. The importance of the security term underscores to all the disparate subprojects that this particular one might be directing requirements their way. This is another big change in the Open Source world - the database people don't listen to the GUI people, and the networks stack people don't listen to the email people ... but they all listen to the security people in a Security Goal project.
Expressing a goal is then an extraordinarily useful thing. It brings torturous mail list arguments back to a ground context. It identifies what we are all striving to achieve, and if we can't demonstrate how our argument moves towards the goal, then we aren't helping.
Yet, goals are almost a dirty word. It was great management speak back in the 80s and 90s, along with various other "must do" things like vision statements. They came, and they went, I haven't heard of anyone talking about a goal for years. One could say this means they didn't work, but I'd say that's unfair - goals are just hard to understand until you've lived them.
Rather than debug the failure of management-speak, let's go back to where they came from: the military, which is where I get my goal-oriented perspective from. There, for fighting soldiers, they are called objectives, and these things are taught to soldiers anywhere from corporal and above. Why the military? I guess because in the heat of the battle, it's easy to forget why you are there, and stressing something solid and basic has real value when the bullets are whizzing overhead.
The military has its own set of verbs. Soldiers redefine "to capture, to destroy, to kill..." so they can stress the objectively measurable event using their own language. When orders are given to troops, the mission - another word for today's goal - is the most important statement, and the leader reads it out twice. The leader reads the mission out twice! After the plans, soldiers are asked, "what's the mission?"
If they didn't do these things, soldiers would go out and do the wrong thing. Trust me on this, it's hard enough to direct soldiers with the help of solid goals, it is impossible without, and many a military campaign has founded through poor goals. Which leads us to their definition of the objective:
The objective is the one thing that if you have achieved it, you have done what you should have, and if you have not done it, then anything else that you might have done was in vain.
It's a tricky thing to define, and I'm going to skip that for now. But at some point, it settles into the mind, and one can be quite incisive. As long as the objective is set it is possible to measure any proposal against it, and thus we ground everything in the reality of our goal.
But to do this, the goal has to be stated. It has to be taught to soldiers who didn't finish grade school but can be taught to fire a rifle, and equally, it has to be stressed to people in complex projects built from opposing perspectives. When people from the crypto, legal, governance, computer science, finance, accounting, retail, charity, economics, government and who knows what other disciplines crowd into one contentious applications sphere such as the Internet, it feels to me like I didn't finish grade school, and the bullets are whizzing overhead.
But I know how to fire a rifle. I know how to do my bit, so ... what's the goal? What on this hellish earth is going to convince me to lift my head up and risk those bullets?
When it comes to security, I think it suffices for an OpenBSD-like project to state that Security is the Goal. Or, in the case of a more general purposes OS like FreeBSD, Security is a Goal, and others also are Goals, that we deliberately and explicitly need to juggle - with the important caveat that Security is the only Goal that can override the others.
It needs to be stated and it needs to be shared. Also needed are what we call Limitations on the Goal. These are important secondary statements that qualify the Goal. By way of example, here are some good ones:
Before you cry foul at those limitations, ponder them for a bit. I picked those because they happen to be the unstated Limitations on an unstated security goal for a particular project (Mozilla). Your project might reverse those limitations or pick others. But also note how they had a defining quality that locked your mind into a conflict.
When you feel that you are in conflict with the goal, and its limitations, that's when the goal is doing its job. Face the conflict - either bring your thoughts into alignment with the goal, or ask why the goal is as it is!
To summarise this long rant, I'd encourage anyone who has an interest in a security project to start thinking about explicitly setting the goal or goals. Making that work means stating it, initially. But it is in the follow through that the reward is found:
- state your limitations
- appoint your security officer or security director
- design the exploit procedure
- work out the disclosure policy
- get used to thinking in terms of "how does this help us meet the goal?"
- start the background projects needed to meet the goal in the future
- develop an open understanding of where you fall short of the goal!
And above all, share and document this process. When you've done this, you'll be able to establish the credibility of the project and the people in a very simple, objective and measurable statement:
Our Goal is Security.
February 15, 2005
Plans for Scams
Gervase Markham has written "a plan for scams," a series of steps for different module owners to start defending. First up, the browser, and the list will be fairly agreeable to FCers: Make everything SSL, create a history of access by SSL, notify when on a new site! I like the addition of a heuristics bar (note that Thunderbird already does this).
Meanwhile, Mozilla Foundation has decided to pull IDNs - the international domain names that were victimised by the Shmoo exploit. How they reached this decision wasn't clear, as it was taken on insider's lists, and minutes aren't released (I was informed). But Gervase announced the decision on his blog and the security group, and the responses ran hot.
I don't care about IDNs - that's just me - but apparently some do. Axel points to Paul Hoffman, an author of IDN, who pointed out how he had IDN spoofing solutions with balance. Like him, I'm more interested in the process, and I'm also thinking of the big security risks to come and also the meta-risks. IDN is a storm in a teacup, as it is no real risk beyond what we already have (and no, the digits 0,1 in domains have not been turned off).
Referring this back to Frank Hecker's essay on the foundation of a disclosure policy does not help, because the disclosure was already done in this case. But at the end he talks about how disclosure arguments fell into three classes:
Literacy: What are the words? Numeracy: What are the numbers? Ecolacy: And then what?
"To that end [Frank suggests] to those studying the economics of disclosure that we also have to study the politics of disclosure and the ecology of disclosure as well."
Food for thought! On a final note, a new development has occurred in certs: a CA in Europe has issued certs with the critical bit set. What this means is that without the code (nominally) to deal with the cert, it is meant to be rejected. And Mozilla's crypto module follows the letter of the RFC in this.
IE and Opera do not it seems (see #17 in bugzilla), and I'd have to say, they have good arguments for rejecting the RFC and not the cert. Too long to go into tonight, but think of the crit ("critical bit") as an option on a future attack. Also, think of the game play that can go on. We shall see, and coincidentally, this leads straight back into phishing because it is asking the browser to ... display stuff about the cert to the user!
What stuff? In this case, the value of the liability in Euros. Now, you can't get more FC than that - it drags in about 6 layers of our stack, which leaves me with a real problem allocating a category to this post!
February 13, 2005
Skype challenges Open Source Security
Skype's success has caused people to start looking at the security angle. One easy claim is that because it is not open source, then it's not secure. Well, maybe. What one can say is that the open source advantage to security is absent, and there is no countervailing factor to balance that lack. We have trust, anecdotal snippets, and a little analysis, but how much is that worth? And how long will it last?
fm spotted these comments and attributed them to Sean D. Sollé:
Shame Skype's not open source really. Actually, it's pretty worrying that Skype's *not* open source.Given that you're happily letting a random app send and receive whatever it
likes over an encrypted link to random machines all over the interweb, the
best place for it is on a dedicated machine in a DMZ.Trouble is, you'd then have to VNC into it, or split the UI from the
telephony bits, but then you're back to needing the source again.Say what you like about Plain Old Telephones, but at least you know they're
not going to run through your house emptying the contents of your bookcases
through the letterbox out onto the pavement.Sean.
February 11, 2005
US approves National Identity Card
Yesterday, the US house of Representatives approved the National Identity card.
This was first created in December 2004's Intelligence bill, loosely called the Patriot II act because it snuck in provisions like this without the Representatives knowing it. The deal is basically a no-option offer to the states: either you issue all your state citizens with nationally approved cards, or all federal employees are instructed to reject access. As 'public' transport (including flying) falls under federal rules now, that means ... no travel, so it's a pretty big stick.
If this doesn't collapse, then America has a national identity card. That means that Australia, Canada and the UK will follow suit. Other OECD countries - those in the Napoleonic code areas - already have them, and poorer countries will follow if and when they can afford them.
This means that financial cryptography applications need to start assuming the existence of these things. How this changes the makeup of financial cryptography and financial applications is quite complex, especially in the Rights and Governance layers. Some good, some bad, but it all requires thought.
http://tinyurl.com/4futv
Social re-engineering
Over on the mozilla-crypto group, discussions circulated as to how to fix the Shmoo bug. And phishing, of course. My suggestion has been to show the CA's logo, as that has to change if a false cert is used (and what CA wants to be caught having themselves issue the false cert?). I've convinced very few of this, although TrustBar does include this alongside it's own great idea, and it looks great! Then comes this stunning revelation from Bob Relyea:
"These same arguments played around and around at Netscape (back when it mattered to Verisign) about whether or not to include the signer's brand. In the end it was UI realestate (or the lack thereof given to security) argument that won the day. In the arena where realestate was less of an issue, but security was, the signer's logo and name *WERE* included (remember the 'Grant' dialogs for signed apps). They still contain those logos today."
Putting the CA logo on the web page was *always* part of the security model. So, that's why it always felt so right and so obvious. But why then have so many people argued against it? Is it the real estate - that never-ending battle to get as much on the screen as possible? Is it the status quo? Is it the triviality of pictures? The dread of marketing?
Which brings to mind experiences I've had chatting with people.
Not something I normally do, and to be honest, not something many of the readers of FC do, it seems. Techies have a very limited view of what people are and do, which is why the technical world has not yet grasped the importance of IM. It's still considered a sort of adjunct cousin to email. And even the whole p2p thing is considered fashionable for its technical interest, not for its social ramifications.
Here's what I've discovered in talking to people. Text is boring. Smileys are interesting. PIctures that move are better, and ones that talk and jump and say silly things are best of all! Out in userland, they love to have wonderful fun jumping little conversations with lots of silly smileys. Think of it as ring tones in a smiley ...
(Oh, and one other thing. It seems that users don't care much for real estate. They are quite happy to load up all these plugins and use them all ... to the point where the actual web page might be left with a third of the screen! This would drive me nuts, I'm one of those that turns off all the tool bars so I can get extreme vertical distance.)
Which leaves me somewhat confused. I know nothing about this world - I recognise that. But I know enough to recognise that here is one more very good idea. Think back to TrustBar. It allows the user to select their own logo to be associated with a secure site. Great idea - it dominated all the ideas I and others had thought of (visit counts, pet names, fingerprints) because of how it reaches out to that world - the world that is being hit by phishing. But over on the cap-talk list, Marc Stiegler goes one further:
"While I agree that an icon-only system might be unsatisfactory, there's more than one way to skin this cat. One of the ideas I have been inspired to think about (Ken Kahn got me started thinking about this, I don't remember how), was to assign faces to the identities. You could start with faces like pirates, scientists, bankers, priests, etc., and edit them with mustaches, freckles, sunglasses. For creating representations of trust relationships, it would be really entertaining, and perhaps instructive, to experiment with such mechanisms to allow users to create such icons, which could be very expressive."
Fantastic idea. If that doesn't kill phishing, it deserves to! If you aren't confused enough by now, you should re-examine your techie roots... and read this closing piece on how we can use a computer to deliver mental abuse. That's something I've always wanted!
Rude software causes emotional traumaBy Will Knight Published Monday 7th February 2005 13:03 GMT
Scientists at California University in Los Angeles (UCLA) have discovered computers can cause heartache simply by ignoring the user. When simulating a game of playground catch with an unsuspecting student, boffins showed that if the software fails to throw the ball to the poor student, he is left reeling from a psychological blow as painful as any punch from a break-time bully.
Matthew Lieberman, one of the experiment's authors and an assistant professor of psychology at UCLA explains that the subject thinks he is playing with two other students sitting at screens in another room, but really the other figures are computer generated. "It's really the most boring game you can imagine, except at one point one of the two computer people stop throwing the ball to the real player," he said.
The scientists used functional magnetic resonance imaging (fMRI) to monitor brain activity during a ball-tossing game designed to provoke feelings of social exclusion. Initially the virtual ball is thrown to the participating student but after a short while the computer players lob the ball only between themselves. When ignored, the area of the brain associated with pain lights up as if the student had been physically hurt. Being the class pariah is psychologically damaging and has roots deep in our evolutionary past. "Going back 50,000 years, social distance from a group could lead to death and it still does for most infant mammals," Lieberman said.
The fact that this pain was caused by computers ignoring the user suggests interface designers and software vendors must work especially hard to keep their customers happy, and it's not surprising that failing and buggy software is so frustrating. If software can cause the same emotional disturbance as physical pain, it won't be long before law suits are flying through the courts for abuse sustained at the hands of shoddy programming. R
¿ Copyright 2005 The Register
http://go.theregister.com/news/2005/02/07/rude_software/
February 07, 2005
The secret list of ID theft victims
Another case of the One True Number syndrome: If you are one of those mystified as to why phishing is so talked about, read this article. Or, if confused as to why computer scientists get angry when governments talk about identity project, read this article. Or, if you are a big consulting firm, looking for future earnings in a never ending torrent of public monies, here's where it's at.
The article itself may be innacurate or exaggerated in parts, and let's hope so for for the sake of those in the mess. But, beyond the stories themselves, the layout of competing interests and the resultant data nightmare is the stuff of Kafkaesque nightmares. The only problem being that this is not literature, but the daily news from 21st century USA.
The secret list of ID theft victims
Consumers could be warned, but U.S government isn't talking
By Bob Sullivan Technology correspondent MSNBC Updated: 12:22 p.m. ET Jan. 29, 2005
Linda Trevino, who lives in a Chicago suburb, applied for a job last year at a local Target department store, and was denied. The reason? She already worked there -- or rather, her Social Security number already worked there.
Follow-up investigation revealed the same Social Security number had been used to obtain work at 37 other employers, mostly by illegal immigrants trying to satisfy government requirements to get a job.
Trevino is hardly alone. MSNBC.com research and government reports suggest hundreds of thousands of American citizens are in the same spot -- unknowingly lending their identity to illegal immigrants so they can work. And while several government agencies and private corporations sometimes know whose Social Security numbers are being ripped off, they won't notify the victims. That is, until they come after the victims for back taxes or unpaid loans owed by the imposter.
It's a thorny problem that cuts to the heart of America's undocumented worker issue. Immigration opponents say it's another reason to shut the borders tight; immigrant rights groups point out that identity theft is an inevitable outcome of unfair labor laws that push foreign visitors deeper into the shadows.
Either way, immigrant imposters with the least nefarious of intentions -- simply a desire to work -- often unknowingly victimize the rightful Social Security number holders. The problem is compounded by how often ripped-off numbers are used. James Lee, chief marketing officer for private data collection firm ChoicePoint, said the average victim of immigrant-based identity theft sees their Social Security number shared about 30 times.
"The numbers get passed around a family, and around neighborhoods," he said.
"People need to wake up to this problem," said Richard Hamp, an assistant attorney general for the state of Utah who has prosecuted several cases involving stolen IDs and illegal immigrants. "They are destroying people's credit, Social Security benefits, and everything else. This problem has been ignored by the federal government, and it's enormous."
But could Trevino, and all the other victims, be warned by the government? After all, several agencies and corporations found her when they wanted her money. Until then, not a single one had bothered to warn her that someone else was using her Social Security number.
Melody Millet's husband Steve was the victim of immigrant identity theft. None of the agencies involved are trying to tackle the problem because they all benefit from it, as does corporate America, she said. The IRS and Social Security collect extra taxes, lenders sell more loans and employers get inexpensive workers. Fixing the problem and telling all the victimized consumers would upset the delicate apple cart that is America's immigration policy, she said.
"The government is forcing people to share identities because they want to provide cheap labor to corporate America," Melody Millet said.
An undocumented immigrant worker managed to use Steve Millet's Social Security number for more than 10 years before the incident was discovered. Millet said the imposter managed to obtain a dozen credit cards, buy a car, and even a house using the stolen number and his own name. All the while, that imposter paid taxes, paid into Social Security, and took out loans using the stolen Social Security Number. All of those agencies had a record of the abused SSN; none bothered to tell Steve Millet.
"You can't find out except by accident," Melody Millet said. "They are not required to notify us. No one is required to notify you. The way it sits now, our lives were ruined. We will never have again a normal financial life."
$420 billion in accounting limbo
Quantifying the problem of immigrant imposters is a challenge; neither the IRS nor the Social Security Administration has tried. But there are some solid hints suggesting hundreds of thousands of people are currently at risk, right now lending their identity to an undocumented worker.
With every paycheck, U.S. workers pay FICA taxes, destined for Social Security funds. But each year, millions of payments are made to the agency with mismatched names and numbers. The Social Security Administration has no idea who deserves credit for the taxes paid by those wage earnings -- so no one gets it. The amount of uncredited Social Security wages is now an enormous $420 billion, an amount that sits in what's called the Earnings Suspense File, an accounting limbo.
During 2002, the year with the most recent figures available, 9 million people paid taxes with mismatched names and Social Security Numbers. Some were women who had failed to notify the agency that their name changed after marriage. Some were the result of typographical errors.
But most -- between 50 and 80 percent depending on whom you talk to -- represent illegal immigrants using a stolen or manufactured Social Security number at the workplace.
The amount of money headed for the Earnings Suspense File began to skyrocket after 1986, when a new federal law required workers to produce Social Security cards to get employment.
In 2001, Social Security reports indicated 35 percent of the wages in the fund were earned by workers in California. In 2002, about 46 percent of the wages that ended up in the fund come from immigrant-heavy industries like agriculture, restaurants and other services, according to Social Security's Office of Inspector General. Both facts suggest to analysts that much of the fund is the result of payments made by undocumented immigrant workers.
What's unclear is how many of those millions of payments made by undocumented workers are made using someone else's Social Security numbers. Audits show that many are made with manufactured numbers, such as 000-00-0000. But people familiar with the data say the list would point to hundreds of thousands of identity theft victims.
Still, James Huse Jr., former inspector general of the Social Security Administration, said it is unlikely the agency will ever inform potential victims.
(The list) would be a terrific source of leads for the identity remediation effort, but there are so many other compelling workloads in front of (SSA) I don't know what can they do with that today," he said. "Also, the politics of immigration get involved in this.
A spokesman for the Social Security Administration said the agency simply couldn't disclose the information to consumers because doing so would run afoul of federal law.
"That information is considered to be tax return information, and it's governed under the Internal Revenue code," said Social Security's Mark Lassiter. "There are strict limitations on disclosure. Can someone see if anyone else has reported earnings under their Social Security number? The answer would be no."
The IRS also receives payments from mismatched names and numbers, and has access to the same no-match list created by Social Security. But according to IRS spokesman Anthony Burke, the agency doesn't check for number-name mismatches until it processes tax returns. And it does not have a mechanism for informing the rightful Social Security number holder that someone else has filed a return using that number.
When tax returns are filed with wrong Social Security numbers -- some 500,000 were filed last year -- the agency simply notifies the filer in writing. The rightful number holder isn't told, because there is no way to know why the wrong number was used, Burke said.
Credit reports don't help
How can a consumer unravel the secret life of their Social Security number? In fact, since neither the government nor private industry is speaking out, there is no way. Asking the Social Security Administration or IRS won't help.
Most consumers only discover the situation when their imposters take the next step up the economic ladder, securing credit using the stolen number. And even then, the victims may not be told unless the imposter misses a loan payment or otherwise sends creditors hunting for their money. That's because thanks to a quirk in the credit system, credit obtained by imposters using their real name but a stolen Social Security number doesn't appear on the victim's credit report.
This so-called "SSN-only" identity theft poses a unique set of problems for consumers and the nation's credit bureaus. If credit is granted by a lender, an entry is made in credit bureau files -- but not disclosed to the consumer who properly owns that number. Even when a consumer gets a copy of her credit report, such fraudulent accounts don't appear on the report. Instead, the bureaus create what are sometimes called "subfiles," which act like separate identities in their databases.
In fact, consumer credit reports obtained from the credit bureaus expressly leave off this kind of fraud. If an imposter is using a consumer's Social Security number but his own name and address to open up fraudulent accounts, a consumer-disclosed credit report won't include that information. The rightful number holder will never know.
A lender, however, might find out -- even see all the accounts an imposter has opened using a victim's Social Security number.
Millet, who has sued the credit bureaus, said her husband was denied a credit card even though his credit report was spotless, and he had a superb credit score of 700.
Businesses interested in giving credit to a consumer can pay to see any activity connected to a particular Social Security Number; consumers cannot. All three credit bureaus sell specialized services with names like "Social Search," that track the entire history of a Social Security number. The services are not available to consumers.
Privacy concerns prevent consumers from seeing a Social Security number-only report, said Equifax's David Rubinger.
"Companies that have signed agreements with us can access data like that. But we can't let every consumer see it," he said. It would be difficult for the firm to establish definitively who the rightful Social Security number holder is, he said. And there would still be potentially sticky privacy issues related to revealing the imposter's information.
Don Girard, a spokesman for Experian, acknowledged his firm had seen the problem, but said it was extremely rare.
"I can tell you we have quite a few people looking into this," he said.
Trans Union did not respond to requests for interview for this report.
'Total purgatory' for taxpayers
Frustration can mount for victims of this kind of fraud. Eventually, the government agencies involved do catch up with the legitimate consumers; but often, not until they are looking for money. Victims can have trouble getting disability or unemployment benefits, Utah's Hamp said.
Others find the Internal Revenue Service on their backs, looking for payment of back taxes for wages earned by their imposters. Some see refunds held up by the confusion; others see their wages garnished.
Trevino found herself in a financial nightmare. All those imitators made a mess out of her work history, her Social Security benefits records and her credit report. She was haunted by bills and creditors. She received threatening letters from the IRS, asking her to pay taxes on money earned by her imposters. She was told to re-pay unemployment benefits she had received, after the government discovered she was "working" while drawing benefits.
"At the time I'm thinking, 'I'm unemployed. I wish I could have at least one job, let alone all these different jobs," she said.
"This is total purgatory that this puts U.S. citizen taxpayers into," said Marti Dinerstein, president of Immigration Matters, a public-policy analysis firm in New York. "It's a nightmare to get it stopped. And when they do get it stopped, it is only for that particular year. The whole mess could begin anew next tax season."
But neither the Social Security Administration nor the IRS tells consumers that something unusual is happening with their Social Security numbers. It seems consumers are the last ones in on the joke.
This is the schizophrenia of the federal government," Huse, the former Social Security inspector general said. "The Homeland Security people are screaming about the accuracy of records, and you have the IRS taking money from wherever it comes."
Mismatches go unchecked
Since the Immigration Reform and Control Act of 1986, workers must produce a Social Security card or similar identity verification when obtaining employment. Employers are supposed to verify that the card is legitimate, but many don't.
By creating a black market for counterfeit Social Security cards, the law may have inadvertently kicked off the identity theft crisis, experts say.
"It's truly an unintended consequences of the 1986 immigration law," said Marilanne Hincapie of the National Immigration Law Center. "Thats why there is this need for comprehensive immigration reform."
For now, with the tacit approval from all involved, undocumented workers buy counterfeit cards from suppliers who steal or simply manufacture Social Security numbers.
About 90 percent of the time in cases he's investigated, Utah's Hamp said, the numbers used belong to a real person. But even in the other cases, there's still harm done: the number may be issued in the future, meaning a baby may be born with a surprising financial past.
"You could end up at birth with a bad credit history and a work record," Hamp said.
The Social Security Administration has made some efforts to straighten out its records, sending letters to hundreds of thousands of businesses, asking that they follow-up on name/number mismatches.
In 2002, the agency sent 900,000 letters to companies that had workers using erroneous names or numbers. The letters confused employers and employees alike: some workers fled immediately, other employers fired workers on the spot.
Immigration rights groups objected, pointing out that inclusion in a no-match list was not an automatic indicator of illegal status. The effort did little to reduce the Earnings Suspense File or fix Social Security accounting, so the agency backed off.
Meanwhile, the IRS, which is charged with enforcing the requirement that employers collect accurate Social Security number data, has never once levied a fine against a corporation for failing to do so.
Change tied up with key policy shifts
The issue of Social Security number abuse is getting some attention as the Bush administration presses ahead on two related issues: Social Security reform and undocumented worker legalization.
The single best way to reduce the amount of entries into the Earnings Suspense File -- and remove the need for immigrant identity theft -- would be to provide a path to legal status for undocumented workers.
On the other hand, removing items from that file would actually increase future liabilities for Social Security, since more wage earners would have a claim on future Social Security payments, adding a bit of fuel for those who warn about Social Security deficits looming in the future.
As things stand, payments made by workers that land in the Earnings Suspense File -- for 2002, Social Security taxes paid on wages of $56 billion -- represent essentially free money to the system, since they come with no future payout liabilities.
In the meantime, neither the Social Security Administration nor the IRS has any public plans to attempt to notify consumers who might be sharing their identity with an undocumented worker -- or 30.
Telling the number's rightful holder that someone else is using it might create more panic then necessary, some Social Security investigators said -- and there's not a lot of good advice the agency could offer, anyway. There's little a victim could do at that point. Uncovering just who is the rightful owner of the Social Security number -- and who is the imposter -- could also pose a challenge. So would finding correct contact information for victims.
Betsy Broder, the attorney in charge of the Federal Trade Commission's efforts to combat identity theft, said more government coordination is surely needed, but she sympathized with the challenge facing the IRS and SSA.
"Of course consumers are always better off if they know how their information is being misused. But having said that, it's really complex with federal agencies," she said. "There are restrictions under the Privacy Act. You can't release to one person another person's information. And the agencies are often not in a position to know with any certainty who was the right person and who was the imposter, leading to possible problems with unauthorized disclosure of information."
The credit bureaus cite much the same concerns, indicating they simply couldn't sell Social Security number-search tools to any consumer who wants them. Even data aggregators like ChoicePoint don't sell such a product to consumers.
Millet thinks there's another motivation for agencies to not deal with the problem. Everyone except the consumer is profiting from the situation, she said. Notifying every consumer whose number is being misused by someone else would be disruptive to the American workforce, and would force government agencies to face the sticky undocumented worker problem.
"If there was no issue, the government would issue work visas to all of them," she said. "But if we gave them all their own Social Security numbers, they'd be able to compete for real wages. That's why no one is dealing with this."
Bob Sullivan is author of Your Evil Twin: Behind the Identity Theft Epidemic.
© 2005 MSNBC Interactive
URL: http://www.msnbc.msn.com/id/6814673/
January 30, 2005
RFID attacked - to impact Passport Debate
The cryptography in RFIDs used as keys into cars has been successfully attacked by a team of cryptographers and security specialists. The system, known as the Texas Instruments DST (digital signature transponder) does a challenge-response based on a proprietary algorithm and a 40 bit key.

The team cracked open the secret algorithm by probing the device and gradually isolating it from the responses; this is called an 'oracle' attack. Then, with the algorithm bare, they were able to build a brute force 16-way key space searcher (with some optimisation) and figure out keys. Allied with a device they constructed to simulate the challenge-response, the team were then able to unlock the vehicle.
It was their own vehicle, but they also used the same techniques on SpeedPass tokens to create a device to purchase fuel at gas stations.
How plausible is this attack? Reasonable. With optimisation, car owners could be at risk. But, consider this: they are still at less risk than all the others who don't have this technology. And, it's not a 100% breach, in that there are quite severe costs left over to turn this into a real live attack. Don't expect any serious news for another year, I'd say, and it is likely that SpeedPass is the more risky area, but even then, it is not an easy attack (considering that in order to steal a tank of petrol, you have to drive past the cameras ...).
Some will say this is evidence that "things should have been done properly!" To that I say Balderdash! When this system was conceived, it is likely that it couldn't have been much stronger. More, it's done its job, for that we should thank the designers. Even better, by all reasonable analysies, it is going to continue to do its job, albeit with higher risks.

Further, we now have something of inestimable value: a data point. The system was invented, deployed and attacked. On this day, in its history, it was attacked. Up until then it was a theoretical unknown, but now we have a fairly good idea of how much it costs to attack it.
That information will be of inestimable value in designing the replacement systems. The systems people now have a baseline and can happily assess what they need for the next ten years. Without this attack, that would not have been possible, as everything would have been based on theoretical projections, which have proven to be rather shy of useful in some cases.
What will be more important is how this crack shakes up the debate on Passports with RFIDs. Already under challenge, this will cause the heads over at DHS to duck down from the rampants faster than you can say challenge-response. It will be interesting to see how that primarily political project evolves!
January 27, 2005
The Green Shoots of Opportunistic Cryptography
In a New Scientist article, mainstream popular press is starting to take notice that the big Wi-Fi standards have awful crypto. But there are some signs that the remedy is being pondered - I'll go out on a limb and predict that within a year, opportunistic cryptography will be all the rage. (links: 1, 2, 3,4 5)
(Quick explanation - opportunistic cryptography is where you generate what you need to talk to the other party on the fly, and don't accept any assumptions that it isn't good enough. That is, you take on a small risk of a theoretical attack up front, in order to reach cryptographic security quickly and cheaply. The alternate, no-risk cryptography, has failed as a model because its expense means people don't deploy it. Hence, it may be no-risk, but it also doesn't deliver security.)
Here's what has been seen in the article:
Security experts say that the solution lies in educating people about the risks involved in going wireless, and making the software to protect them easier to use. "Blaming the consumer is wrong. Computers are too complex for the average person to secure. It's the fault of the network, the operating system and the software vendors," says California-based cryptographer Bruce Schneier in the US. "Products need to be secure out of the box," he says.
Skipping the contradiction between "educating people" and "blaming the consumer", it is encouraging to see security people pushing for "secure out of the box." Keys should be generated opportunistically and on install, the SSH model (an SSH blog?). If more is wanted, then the expert can arrange that, but there is little point in asking an average user to go through that process. They won't.
Schneier is pessimistic. "When convenience and features are in opposition to security, security generally loses. As wireless networks become more common, security will get worse."
Schneier is unduly pessimistic. The mistake in the above logic is to consider the opposition between convenience and security as an invioble assumption. The devil is in those assumptions, and as Modadugu and Rescorla said recently:
"Considering the complexity of modern security protocols and the current state of proof techniques, it is rarely possible to completely prove the security of a protocol without making at least some unrealistic assumptions about the attack model."
(Apologies, but it's buried in a PDF. Post.) That's a green shoot, right there! Adi Shamir says that absolutely secure systems do not exist, so as soon as we get over that false assumption that we can arrange things perfectly, we can start to work out what benefits us most, in an imperfect world.
There's no reason why security and convenience can't walk hand in hand. In the 90s, security was miscast as needing to be perfect regardless of convenience. This simply resulted in lost sales and thus much less security. Better to think of security as what we can offer in alignment with convenience - how much security can we deliver for our convenience dollar? A lot, as it turns out.
January 22, 2005
The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software
From the curious source of NTK comes news of the end of Moore's Law and life as we know it. This time there's evidence: If you are more than 20 years old and have actually factored in Moore's Law into your brain, as any good software engineer has done, you will have noticed a funny thing happen in the last couple of years.
In brief, your CPU isn't getting any faster - clock speeds have hit a wall! The Penny Littles that cheeped before about the end of Moore's Law were all plucked and fried in garlic and olive oil, so for the details, I defy you to read this article, The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software by Herb Sutter which lays out the case. If you can't face the awful awful future now, wait until March when it appears in Dr. Dobbs.
No, it's not that we're confined to ever slower paperclip torture in our office software. The future is concurrency, and that means ... higher development costs and lower reliability. It even goes a bit beyond that, but I've spent my controversy budget for this week, so I'll leave you with NTK's doom and gloom:
>> TRACKING <<
sufficiently advanced technology : the gatheringCPUs aren't getting faster! Multi-core is the future! Which
means we'll all need to learn concurrent, multi-threaded
programming, or else our software is never going to get
faster again! That's what Herb Sutter's future shock article
in Dr. Dobbs says (below). But before you start re-learning
APL, here's a daring thought: maybe programmers are just too
*stupid* to write multi-threaded software (not you of
course: that guy behind you). And maybe instead we'll see
more *background* processes springing up - filling our spare
CPUs with their own weird, low i/o calculations. Guessing
wildly, we think background - or remote - processes are
going to be the new foreground. Oh yeah, and increasingly
we're going to need some consistent way to display quiet,
passive user notifications from these processes that won't
interfere with the main flow of our single-threaded human
masters. What we're trying to say here is that, primitive
though they may be now, apps like GROWL (on the Mac) and
XOSD on Linux are going to be the new squishy UI innovation
area, and you should check them out, futz with them, and
work out your own solutions. You're already curious about
your background tasks, and soon the whole world will be.
CRISWELL PREDICTS!
http://www.gotw.ca/publications/concurrency-ddj.htm
- lock your daughter threads! here comes multiple futures!
http://growl.info/
- more interesting than the website implies
http://the.taoofmac.com/space/blog/2004-09-26
- more interesting python, rendezvous and remote unix hacking
http://www.ignavus.net/software.html
- xosd for your tail-piping pleasure
NEED TO KNOW
THEY STOLE OUR REVOLUTION. NOW WE'RE STEALING IT BACK.
Archive - http://www.ntk.net/
Unsubscribe or subscribe at http://lists.ntk.net/
NTK now is supported by UNFORTU.NET, and by you: http://www.ntkmart.com/(K) 2005 Special Projects.
Copying is fine, but include URL: http://www.ntk.net/
Full license at: http://creativecommons.org/licenses/by/1.0
Eudora overcomes stupidity to tackle phishing
(JPM reports) here is a simple example from Eudora (a popular email client) for OSX.
You'll get the idea. Note that "anti phishing technology!" is stunning, stupidly simple. It's just Not That Complex.
"You need a big warning in email clients when a link is fake."
Oh.
So over at MIT people are making robots that can have intercourse with sound effects, but over in the Email Client Corner, a concept as stunningly simple as this...
"You need a big warning in email clients when a link is fake."
Is just Too Hard.
Note that anti phishing technology is far, far simpler than say "spell checking"
When you use the Eudora email client, and you make a spleliling mistake, it brings up a HUGE, CATACLYSMIC warning - the entire operating system is taken over, massive alerts 50% the size of the screen appear, if you have a printer connected, massive "SPELLING ERROR!" banners immediately shoot out of the printer. The Mac's excellent voice synthesis is employed and suddenly - before you can type the next space key - Steven Hawking's voice is telling you "YOU HAVE -- MADE A SPELLING - ERROR - ALERT!!!"
That's for a spelling error.
In contrast when an email contains a "phishing" link, the miserable alert attached flashes up for a second -- but only if you mouse over the link:
The bottom line here, as always, is that not so much software engineers, but software designers, are stunningly, hopelessly, pathetically, uselessly, staggeringly, mind-blowingly stupid.
Note that the same piece of consumer software put a HUGE amount of effort in to enable REAL TIME SMILEYS .... if you happen to type a smiley :) it notices that in real time as you type, and animates a yellow and black smiley there for you. Wow!
(thanks JPM!)
December 30, 2004
The Guru Code - a great technique for something that never happens!
A hand-me-down copy of ACM Queue has an article in it about "the Guru Code" which lambasts this allegedly poor behaviour by programmers. The author was a bit flustered by seeing
Fatal System Error
Guru Code: #0002000436; #0001000258
on his TV screen.
Certainly, it's bad for a member of the user public to be exposed to this stuff. But, consider the lot of the poor programmer: no confidence in design, no patience in re-work, desperation to get the demo out, the impending doom of managerial dictat to distribute the demo, the creep of featurism, tuning into the flood of complexity ...
Huge amounts of code gets written in a rush to trial it and then either sent out as finished work, or thrown away. There's no middle ground, many times. To respond, the embattled programmer evolves. Learning, hacking, proving, grand construction, re-construction, managerialism, revisionism, and hacking all over again.
As we travel this path from initiate to guru and back to code monkey, we develop techniques of survival. One of the most efficacious is what the article refers to as the Guru Code. This is an indecipherable number that is only interpretable by the person who wrote it. What this means is that a particular path of code that should never have happened has indeed happened.
Of course, the outsider can say, well, you should write better code. Nope, see above; the boss wouldn't let that happen. Or, at least, you should write better error messages. Which is what the article states.
Think about it for a bit. If the code should never have happened, that means that it wasn't going to be dealt with in code! What would the error message say? "Write me?" Or, perhaps, "tell my boss I told you so?"
In practice there are lots and lots - we are talking in the thousands here for any serious shipped product - of error conditions where there is nothing to say. Other than it happened right here, and that's something that should never have happened.
What I tend to do is put in a "numberplate" error code. This little innovation is a group of three letters and three digits: ABC123, chosen randomly by typing blind. Then, if it *ever* pops up in a user complaint or a log, it is recognisable as such. The only solution is to run a massive search of all source code looking for it, and go looking at the code (there is no support database for these things, because they never happen).
Of course, such a non-occurrance happens only once a year or so. Like the front cover of the magazine says, "System Errors Happen. Deal with it." When it does happen, it's really useful to see the code stick out like a sore thumb. From there, inspection of the code makes it clear, and we can make some minor fixes to get back to the normal state of affairs, which is that it will never ever happen (again). Promise.
December 22, 2004
SkunkWorks that works - The Graphing Calculator Story
Steve pointed out this engaging story about a skunkworks team that pulled it off. A couple of guys working for nothing created a graphic calculator that shipped out on 20 million PowerMacs ... all without permission. Anyone with kids and a maths teacher will know what this means (I don't!).
Some of the world's best products have been created this way, by developers who had the guts to stick it out when the support was pulled from them. Conviction is a powerful thing, and it's even better when it's right.
Still, conviction's just as flakey as any other powerful thing, like salaries, office space, clients and a management structure. I've participated in skunworks, seen them done on corporations, and even had them performed on me. For the most part, in my experience, they are hit and miss. Most skunkworks fail, lose the boss's money, and the programmers dust themselves off and walk away without realising the damage they've done.
But sometimes there is a spark of brilliance lurking in there. The trick is in allowing the spark to light, but reducing the burn out when the spark catches other things alight. Generally, when I come across a skunkworks, I start out with "let's discuss this over a pint..." as a way to detune the politics and up-tune the entrepreneurial spirit.
December 19, 2004
Security Coding Best Practices - Java adds yet another little check, and boom...
Over on Adam's blog he has a developing theme on 'security signalling.' He asks whether a code-checking program like RATS would signal to the world that a product is a good secure product? It's an important question, and if you need a reason, consider this: when/if Microsoft gets done rewriting its current poisoned chalice of an operating system, how is it going to tell the world that it's done the job?
Last night I had occasion to feel the wrath of such a check, so can now respond with at least one sample point. The story starts earlier in the week, when I reinstalled my laptop with FreeBSD 5.3. This was quite a massive change for me, up from 4.9 which had slowly been dying under the imposition of too many forward-compatible ports. It also of course retriggered a reinstall of languages, but this should have been no trouble as I already had jdk1.4.2 installed, and that was still the current. (Well, I say no trouble ... as Java is "unsupported" on FreeBSD, mostly because of Sun's control freak policies creating a "write once, run twice" environment.)
Anyway, my code went crazy (*). A minor change in the compiler checking brought out a squillion errors. Four hours later, and I'd edited about 100 files and changed about 500 lines of code. My eyes were glazed, my brain frizzled and the only cognitive capability I had left was to open beers and dispose of them.
Now, this morning, I can look at the effect, hopefully in the cold hard light of a northern winter's sunny day. At least for another hour.
It's security code (hard crypto payments) so am I more secure? No. Probably actually less secure, because the changes were so many and so trivial that the robot masquerading as me made them without thinking; just trying to get the darn thing to compile so I could get back to my life.
So one answer to whether the RATS proposal could make any difference is that it could make things worse: If thrown at a project, the rush to get the RATS thing to come out clean could cause more harm than good.
Which is a once-off effect or a singularity. But what if you didn't have a singularity, and you instead just had "good coding checks" all the time?
Well. This is just like the old days of C where some shops used Lint and others didn't. (Lint was an old tool for cleaning out "fluff" from your C code.) Unfortunately there wasn't enough of a real discernable difference that I ever saw to be able to conclude that a Lint-using shop was more secure.
What one could tell is that the Lint-using shop had some coding practices in place. Were they good practices? Sometimes, yes. Maybe. On the whole Lint did good stuff, but it also did some stupid things, and the net result was that either you used Lint or you were careful, and not using Lint was either a signal that you were careful and knew more, or you weren't careful, and knew less; whereas using Lint was a signal that you didn't know enough to be careful, but at least you knew that!
We could debate for years on which is better.
As an example of this, at a tender age, I rewrote the infamous strcpy(3) set of routines to eliminate buffer overflows. Doing so cost me a day or two of coding. But from there on in, I never had a buffer overflow, and my code was easy to audit. Massive benefit, and I preferred that to using Lint, simply because *I* knew what I was doing was much safer.
But how to convince the world of that? I don't know ... still an open question. But, I'm glad Adam has brought up the question, and I have the chance to say "that won't work," because the answer is probably worth an extra percentage point on Microsoft's market cap, in a couple of years, maybe.
* The code is WebFunds which is about 100kloc (kilo-lines-of-code) chock full of hard crypto, RTGS payments and various other financial cryptography applications like secure net storage and secure chat.
December 15, 2004
The One True Number: "9210: the zip code of another IT-soap"
What could be called the "one true number" syndrome has been spotted by Simon Lelieveldt over on his blog. He points to this paper 9210: the zip code of another IT-soap:
"Nine-to-ten (9210) refers to the problem that the Dutch banks are running out of 9-digit bank account numbers and need to convert to 10-digit numbers. At the same time, the Dutch government wants bank account numbers to be portable to encourage competition; this may become European policy. A recent European standard for cross-border money transfers proposes totally nonportable bank account numbers. These orthogonal policies have such a high IT-soap caliber that we sometimes refer to it as 9210 Policy Nils. Whatever the plot of ``nine-two-one-o'', major challenges are at stake for European banks and other ``number crunchers'' like tax authorities, mail-order firms, etc. This paper gives insight in cost aspects, the possibilities, and impossibilities of 9210 and related problems."
Unless you really enjoy chortling at comparisons between the business of banking and the game of twister, I wouldn't suggest you read the rest of the paper. Poor guys, is all I can say.
The notion of the one true number - for a bank account, for a person, for anything - does sort of make life difficult. So much so that many software systems when freely written tend to ditch the very notion, allocate numbers on demand, and retire them when not demanded [1]. Peer to peer systems especially have revelled in the freedom of discardable accounts and resources. The alternate to the "one true number" might be called "use many numbers, they're free! [2]"
But, the world is moving more to the one true number. Over in the US rumour has it that hey have recently slipped into Patriot 2 (passed last week) enough clauses to jump-start the US citizen identity program. Future US citizens will acquire their numbers from birth on a more or less compulsory basis, have these marked on their papers, and use their government-issued papers to purchase goods. If the administration succeeds in making Patriot 2 stick then the rest of the world will follow suit.
Which leaves the formal bank-built payment systems heading for a permanent season of IT-soaps, as it tries to deal with the explosion of incompatibilities and inadequacies of the many one true numbers.
[1] My own favourite case is that of Ricardian Contracts: the classification system is a hash (or cryptographic message digest) over the text of the contract. One unique number for the contract, but no allocation policies, no central party and no incompatibility headaches. It's simple, it's scaleable, and it matches the real world of "anyone can write a contract."
[2] I need a better aphorism!
December 11, 2004
Google Labs Aptitude Test: The Cats are Firmly in Charge
One of the most vexatious tasks and probably the most important is the construction of the team. Google is on a big hiring binge at the moment, and as the only 'cool' company in town, and the only one flush with IPO dollars, they are having it all their own way in scouring for top software developers. I went to a recruiting session loosely camouflaged as a 2 hour talk on search engine technology recently, and got turned away at the door! Dozens were milling around wondering whether to stay for the 'reception' and chance their luck.
In another human resources effort, Google are running online quizes and brain teasers, trying to attract those that think. LIke they do, presumably. A flyer slipped into the ACM's Communications and other prestigious mags is called the GLAT - Google Labs Aptitude Test, as a sort of play on the series of standardised tests that the Americans run for their graduate schools. You can find the whole thing written out on various blogs like Relax and Amit's.
It's inspired human resources thinking, and well worth reverse engineering (a fun pastime). The GLAT includes these gems: "You are in a maze of twisty little passages..." and also "What's broken with Unix? How would you fix it?" Those with a sense of history will tag the archtype as the West Coast / guru / long hair long beard crowd. My first lesson in HR as a teenager with way too much confidence (arrogance?) was when I bounced into these people, decided they were even more arrogant than me, which was sobering, and also singularly unproductive for their salaries, which was confusing. So what do you do with people that are smarter than yourself? That latter challenge has bugged me all my working life.
There are lots of multiple choice questions which can only be described as leading and presumably designed to tell you how to act when you get to the next stage. See above link for why this is. And of course the "you already work for us for free" questions like the griller on "What will be the next great improvement in search technology?"
The GLAT is a Great Laugh for All Triers, but a pile of bad news for shareholders. Lots and lots of "problem solving questions" means that Google is intent on stuffing the company to the gunwales with a) problem solvers and b) problem solvers like ourselves. So we can take the monoculture thing as a given, but also, we can observe that it's a feline monoculture. The cats are will go forth and multiply. Even "What's the coolest hack you've ever written?" whilst an opportunity to really express, has a powerful conflicting force deep in the guts of those of us who have spent years herding the cats.
(The explanation for the "cats" metaphor is that someone once said that managing programmers is like herding cats.) So how many actual non-feline questions are there? One:
What is the optimal size of a project team, above which additional members do not contribute productivity equivalent to the percentage increase in the staff size?A) 1
B) 3
C) 5
D) 11
E) 24
[The answer is below.]
Now that's a good question! In fact, it's a great HR question. One could have a lot of great followup discussion on that. Issues like just why would google be better off employing even one more cat when they already have more than gomorrah spring gracefully to mind.
Shareholders watch out! This is one stock where the ceiling is firmly in view. I'll leave you with one more question:
"Which of the following expresses Google's over-arching philosophy?A) "I'm feeling lucky"
B) "Don't be evil"
C) "Oh, I already fixed that"
D) "You should never be more than 50 feet from food"
E) All of the above
The answer is of course all of the above as right now, google can afford to have as many over-arching philosophies as it desires. Live well, live young!
The answer to the above question: 1. Anything larger incurs the costs of external coordination.
December 07, 2004
Engineering for Failure
An interview with Bruce Lindsay, one of the core designers of relational technologies, claims it is all about errors. A lot of good observations about the practical side of software engineering; if you've travelled that path, you'll recognise the "shady" practices that might be better off called "best" practices.
Yes, that's about the sum of it. Reliable code is code that deals with errors. If there were no errors, my gut feeling is that we could do this whole thing without about 10% of the code we currently use.
November 27, 2004
SDP1 - Secure Datagram Protocol #1
After years of thought and days of hacking, Zooko and I have put together a new crypto protocol: Secure Datagram Protocol #1 or SDP1 . It provides for encrypting and MACing a single datagram, within a previously established secret key context.
The sexy details: The inner layer of plaintext is a Pad and a Payload, where the Pad expands to block, as well as incorporating nonce, time and random elements in order to make a good IV. The plaintext is then encrypted with AES128 in CBC mode. A token is prepended to the ciphertext so that receivers can determine where to find the keys, and the whole lot is MACed with HMAC-SHA1. The token, the ciphertext and the MAC then form the on-the-wire datagram.
I have implemented SDP1 in Java and am in the process of using it to create secure back-channels from server-to-client comms within SOX (this is a major mod to the basic paradigm of public key nymous cryptosystems which are normally all client-to-server oriented). Secret sharing was a breeze, and is already done, but usage in a full cryptosuite is much more work!
As SDP1 is intended to be used for financial applications, and is thus datagram oriented, we can't really make use of the many other protocols that have been developed, such as SSL and SSH. In fact, it seems as if there is a bit of a hole in the market for datagram products; I found ESP which has too much of a relationship to IP, and is also a little old, but little else in this area. Architecturally, SDP1 relates quite closely to ESP, but in detail it is different.
Any comments are welcome! The SDP1 docs are reasonably fullsome, but still need some touching up. The entire layout is subject to change, at least until we get to the point of deploying too many nodes to change. At that point, we'll freeze SDP1 in whatever state and plan on a redesign called SDP2.
November 24, 2004
eBay's Spanish rebellion - have they hit the transactional Brick Wall?
Over on the Register they are reporting on a rebellion - they called it a strike - by eBay's users in Spain. Initially, this just seemed to be a bunch of grumbling spaniards, but the rebellion quickly spread to other countries. What seems striking to me is that Spaniards are not the grumbling kind, so things must be pretty bad out there.
It's fun reading! Reading between those lines, it all comes down to the business model goal of pandering to features. Back in the early days of building systems, the architect is faced with a very heavy choice: features or cost. It's generally an either/or, and for the most part features wins in the market place and features wins in the mind space.
A brief explanation of the problem space. When you build a feature that is transactional in intent, there are three standards it must meet, one after the other. Demonstrable, which means you can demo it to your boss, and to analysts, to the extent that they get what it is you are trying to say, and immediately order it into production. Or, if they are analysts, they immediately stock up on options, and then write their Buy recommendations.
Wisely, the developer ignores all that, and then moves the feature to the next standard, which is Usable. This means that under most users and most circumstances the feature actually works. People can bash and bang at it, and any series of 10 user tests makes everyone smile. At this point, even the developer can only smile with joy as his new feature goes into production.
But there is a further standard: Transactional. This means that the feature returns a complete result in every case. It doesn't mean that it always works - that's beyond the ken of mere mortals and most developers. Transactional means that the result that is returned is completely reliable, and can be used to instruct further actions. It is this focus on errors that allows us to get to the real prize for Transactional software: the ability to build other software systems on top.
A few examples: an email is transactional, as you don't ever receive half an email. A bank payment is not, as people are required to find out what happened. A web request can be transactional but a web session is not. That's why there are warnings on some sites "don't push this button twice when buying..."
Most features never make the Transactional standard. Most users don't know it even exists, until they discover their favourite feature doesn't have it. And even then, the mystery just deepens, because nobody says those magic words "oh, the software never made it to Transactional status."
Here's how the progression works:
Firstly, the feature comes into use and it has a lot of bugs. The users are happy enough that they ignore the errors. But then the euphoria dies and the tide of malcontent rises ... then there is a mad push to fix bugs and the easy ones get fixed. But then the bugs get more complex, and each failure involves more and more costs. But by now, also, there are some serious numbers of users involved, and serious numbers of support people, and serious numbers of revenue bux pouring in, and it is no longer clear to the company that there are remaining problems and remaining costs...
So the company institutionalises a system of high support costs, pushing errors back onto compliant users who can be convinced by some convenient reason, and the developers start moving onto other projects. These are all the wrong things to do, but as the user base keeps growing, insiders assume that they are doing something right, not wrong.
As one CEO infamously said, "People keep sending me money." Until they stopped, that is.
To get a full appreciation of what happens next, you have to read Senge's _The Fifth Discipline. His book uses feedback notions to describe how the machine seems to run so well, and then all of a sudden runs full speed into a brick wall. The reason is partly that which worked at user base X won't work at user base 2X, but it's more than that. It's all the factors above, and it can be summed up in one sentance: the failure to move from Usable to Transactional.
You can see this in many successful companies: Microsoft's current security woes are a result of this, they hit the brick wall about 2001, 2002 when the rising tide of virues overtook the falling star of Internet/PC growth. e-gold, a payment system, hit this very problem in 2000 when they went from 10 times annual growth to zilch in a quarter.
On the strength of one article (!) I'd hazard a guess that eBay and Paypal are now entering the phase of running fast and achieving no traction. I.e., the transactional Brick Wall. To be fair, it's a bit more than one article; Paypal have never ever had a transactional approach to their payment system, so it is really been a bit of a mystery to me as to why it has taken so long for their quite horrific hidden cost structure to bite.
November 11, 2004
Opportunistic Cryptography is now Acceptable
Adam reports that Eric reports that the IETF has run its first meeting on opportunistic cryptography. Called "Better Than Nothing Security" the Internet protocol people are starting to get antsy about the number of attacks on unprotected sessions on the net.
And why aren't these sessions being protected by crypto? Because the original protocols called for a full-scale certificate authority signed key infrastructure. Nobody can be bothered with that, so they leave the links unprotected. Hence the notion that IPSec gives nothing because it isn't being utilised, and they may as well start accepting that crypto that is deployed is more useful than crypto that isn't deployed.
It is now some time past since we've had to argue the case. Crypto protocol people now seem to be comfortable that opportunistic cryptography - the glorified conceptual name for "wot SSH does" - is a valuable service.
There's still a little bit of loose naming to clear out. Adam points out that labelling opportunistic cryptography as "leaps of faith" is hardly helpful. Worse, it's just going to point more attention at the flaws in the certificate authority model.
For SSH and similar designs, we have one small step of faith at the beginning, In that if we don't check the certificate of the other node, *and* there is one of those vanishingly rare MITM attacks, then there exists a vulnerability. In contrast, we've pretty much established that certificate authority models call for two huge leaps of faith: firstly, that all CAs are the same, which isn't supported by any theory known to me, and secondly, that you can trust your CA because he is a trusted third party.
That last is now a highly questionable act of faith, in the light of Verisign's conflict of interest. Given that, the old label for self-signed certificates as "snake oil certs" is laughable, especially when phishing is considered. Self-signed certificates can make a huge difference to phishing, if the certificates were indexes into user-controlled information on the special sites. In contrast, certificate authority ones make no difference until we actually do something like adding branding to web browsers. Which then should we be calling snake oil?
http://www.financialcryptography.com/mt/archives/000206.html
http://www.ietf.org/ietf/04nov/btns.txt
http://www.rtfm.com/movabletype/archives/2004_11.html#001174
http://www.emergentchaos.com/archives/000583.html
October 28, 2004
Encrypt everything...
AlertBox, the soapbox of one Jakob Nielsen, has had enough with nonsense security prescriptions. Its 25th October entry says:
"Internet scams cannot be thwarted by placing the burden on users to defend themselves at all times. Beleaguered users need protection, and the technology must change to provide this."
Sacrilege! Infamy! How can this rebel break ranks to suggest anything other than selling more crypto and certs and solutions to the users?
Yet, others agree. Cory Doctorow says Nielsen is cranky, but educating the users is not going to solve security issues, and "our tools conspire against us to make us less secure...." Mitch Wagner agrees, saying that "much security is also too complicated for most users to understand."
And they all three agree on Nielsen's first recommendation:
"Encrypt all information at all times, except when it's displayed on the screen. In particular, never send plaintext email or other information across the Internet: anything that leaves your machine should be encrypted."
Welcome to the movement.
October 15, 2004
The Coordination Problem
Canny financial cryptographers know that connection-oriented protcools like TCP are not up to scratch if you really care about your packets. They are reliable, but that doesn't mean you can rely on them! TCP is only a reliable protocol until it stops, and then it becomes unreliable - there is no way for you to tell whether a dropped connection delivered the data or not. Or, indeed, how many times.
This problem is underwritten by what amounts to a law of computer science called the Coordination Problem. In trying to recall what this was called, I asked Twan van der Schoot, and predictably, he gave me the fullest answer. Here it is, somewhat edited:
The "Law" you are refering to [writes Twan] is the result of the attempt to solve the "Coordination Problem" or "Coordinated Attack Problem", failing in the attempt, and then proving that it cannot be solved. People generally say it is a "folk" problem in the distributed systems community. Paul Syverson attributes the original problem statement to Gray (1978).
Here's the proof. It is very simple and of a rare beauty. The only thing wrong with it is that it needs an indirect method using a reductio ad absurdum argument.
The problem setup:We have two perfect processes (i.e. which do not fail), say Alice and Bob. Alice and Bob communicate bidirectionally over a channel with transient errors (i.e. an imperfect channel). Can you devise a protocol that guarantees that Alice and Bob both choose the same action a or b?
The proof:
1. Assume there is such a protocol. And, without loss of generality, assume that it is the shortest one (i.e. the one with the least communication exchanges in either direction).
2a. Assume that Alice just has sent its last message m in the last step of the protocol. At this point in the protocol, Alice's choice of action a or b must be independent of the message m. Alice will not receive any message thereafter. In other words, prior to sending m, Alice already committed to either action a or b independent of message m.
2b. The choice by Bob for either action a or b must be the same as the choice by Alice after receiving message m from Alice, whether Bob received message m or not (message loss). So Bob's commitment to action a or b is also independent of the received message m.
2c. But then sending message m in the last step of the protocol is redundant, and can be dropped. But then we have a protocol which is one step shorter;
4. But then we have a contradiction, because the protocol was the shortest (1). Hence there is no such protocol.
Conclusion: So there is no protocol which solves the coordination problem.
There are more formal proofs, but they require a lot of formal theory. This one I grabbed from "Distributed Systems, 2nd Edition. Sape Mullender ed. Addison-Wesley 1993".
Note, however, that the "coordination attack" fails in an "absolute" sense. If we allow for some probablity thinking, we can at least approximate a solution. And that is why, say, the Internet works :)
Paul Syverson wrote a little monopgraph in 2003 "Logic, Convention, and Common Knowledge; A Conventionalist Account of Logic". Syverson claims that the Coordination Attack can be solved using a combination of logic and game theoretical ideas. I've started reading the book recently and it is laden with philosophy, (epistemic) logic and game theory. So it will take a little time before I'll grasp the basic tennet of the underlying concepts.
gr
Twan
September 28, 2004
The DDOS dilemma - change the mantra
The DDOS (distributed denial of service) attack is now a mainstream threat. It's always been a threat, but in some sense or other, it's been possible to pass it off. Either it happens to "those guys" and we aren't effected. Or, the nuisance factor of some hacker launching a DOS on our ISP is dealt with by waiting.
Or we do what the security folks do, which is to say we can't do anything about it, so we won't. Ignoring it is the security standard. I've been guilty of it myself, on both sides of the argument: Do X because it would help with DOS, to which the response is, forget it, it won't stop the DOS.
But DOS has changed. First to DDOS - distributed denial of service. And now, the application of DDOS has become over the last year or two so well institutionalised that it is a frequent extortion tool.
Authorize.com, a processor of credit cards, suffered a sustained extortion attack last week. The company has taken a blow as merchants have deserted in droves. Of course, they need to, because they need their payments to keep their own businesses alive. This signals a shift in Internet attacks to a systemic phase - an attack on a payment processor is an attack on all its customers as well.
Hunting around for some experience, Gordon of KatzGlobal.com gave this list of motives for DDOS:
- #1. Revenge Attack. A site may have ripped off someone and in revenge they ddos the site or hire it out. You can actually hire this service like a website hitman. $50 to kill your site sort of thing from most eastern block countries. Did I just coin something? The Webhit.
- #2. Field Reduction: Say I no longer like Robert and he no longer likes me and we get into a pissing match and we ddos each other... Or say we were jerks and didn't want any competition at all. We could ddos all of our competitiors into oblivion. This type of thing happens more than you might think.
- #3. Enacting God's Will: These are the DDOSERS from GOD. They are rightous and they ddos sites that do not align with their views on the world.
- #4. HYIPer Dossers: If anything looks scammy about a HYIP (high yield investment programme) site there is a particular DDOS team running around out there who ddosses HYIPs damn near on a daily basis. This falls into category 3 and 5 below:
- #5. Extortioners: Hackers or wannabees usually from Eastern European countries (usually) trying to make a living becasue their governemnt could gve a crap what they do to us citizens in general.
Great list, Gordon! He reports that extortion attacks are 1 in 100 of the normal, and I'm not sure whether to be happier or more worried.
So what to do about DDOS? Well, the first thing that has to be addressed is the security mantra of "we can't do anything about it, so we'll ignore it." I think there are a few things to do.
Firstly, change the objective of security efforts from "stop it" to "not make it worse." That is, a security protocol, when employed, should work as well as the insecure alternative when under DOS conditions. And thus, the user of the security protocol should not feel the need to drop the security and go for the insecure alternative.
Perhaps better put as: a security protocol should be DOS-neutral.
Connection oriented security protocols have this drawback - SSL and SSH both add delay to the opening of their secure connection from client to server. Packet-oriented or request-response protocols should not, if they are capable of launching with all the crypto included in one packet. For example, OpenPGP mail sends one mail message, which is exactly the same as if it was a cleartext mail. (It's not even necessarily bigger, as OpenPGP mails are compressed.) OpenPGP is thus DOS-neutral.
This makes sense, as connection-oriented protocols are bad for security and reliability. About the best thing you can do if you are stuck with a connection-oriented architecture is to turn it immediately into a message-based architecture, so as to minimise the cost. And, from a DOS pov, it seems that this would bring about a more level playing field.
A second thing to look at is to be DNS neutral. This means not being slavishly dependent on DNS to convert ones domain names (like www.financialcryptography.com) into the IP number (like 62.49.250.18). Old timers will point out that this still leaves one open to an IP-number-based attack, but that's just the escapism we are trying to avoid. Let's close up the holes and look at what's left.
Finally, I suspect there is merit in make-work strategies in order to further level the playing field. Think of hashcash. Here, a client does some terribly boring and long calculation to calculate a valid hash that collides with another. Because secure message digests are generally random in their appearance, finding one that is not is lots of work.
So how do we use this? Well, one way to flood a service is to send in lots of bogus requests. Each of these requests has to be processed fully, and if you are familiar with the way servers are moving, you'll understand the power needed for each request. More crypto, more database requests, that sort of thing. It's easy to flood them by generating junk requests, which is far easier to do than to generate a real request.
The solution then may be to put guards further out, and insist the client matches the server load, or exceeds it. Under DOS conditions, the guards far out on the net look at packets and return errors if the work factor is not sufficient. The error returned can include the current to-the-minute standard. A valid client with one honest request can spend a minute calculating. A DDOS attack will then have to do much the same - each minute, using the new work factor paramaters.
Will it work? Who knows - until we try it. The reason I think of this is that it is the way many of our systems are already structured - a busy tight center, and a lot of smaller lazy guards out front. Think Akamai, think smart firewalls, think SSL boxes.
The essence though is to start thinking about it. It's time to change the mantra - DOS should be considered in the security equation, if only at the standards of neutrality. Just because we can't stop DOS, it is no longer acceptable to say we ignore it.
September 17, 2004
Normal Accident Theory
A long article by Dan Bricklin entitled "Learning From Accidents and a Terrorist Attack" reviews a book about Normal Accident Theory (book entitled "Normal Accidents" by Charles Perrow). Normal Accident Theory encapsulates the design of systems that are tightly coupled and thus highly prone to weird and wonderful failures. Sounds like financial cryptography to me! The article is long, and only recommended for die-hard software engineers who write code that matters, so I'll copy only the extracts on missile early warning failures, below. For the rest, go to the source.
An example he gives of independent redundant systems providing operators much information was of the early warning systems for incoming missiles in North America at the time (early 1980's). He describes the false alarms, several every day, most of which are dismissed quickly. When an alarm comes in to a command center, a telephone conference is started with duty officers at other command centers. If it looks serious (as it does every few days), higher level officials are added to the conference call. If it still looks real, then a third level conference is started, including the president of the U.S. (which hadn't happened so far at the time). The false alarms are usually from weather or birds that look to satellites or other sensors like a missile launch. By checking with other sensors that use independent technology or inputs, such as radar, they can see the lack of confirmation. They also look to intelligence of what the Soviets are doing (though the Soviets may be reacting to similar false alarms themselves or to their surveillance of the U.S.).
In one false alarm in November of 1979, many of the monitors reported what looked exactly like a massive Soviet attack. While they were checking it out, ten tactical fighters were sent aloft and U.S. missiles were put on low-level alert. It turned out that a training tape on an auxiliary system found its way into the real system. The alarm was suspected of being false in two minutes, but was certified false after six (preparing a counter strike takes ten minutes for a submarine-launched attack). In another false alarm, test messages had a bit stuck in the 1 position due to a hardware failure, indicating 2 missiles instead of zero. There was no loopback to help detect the error.
September 16, 2004
CPUs are now a duopoly market
Reports coming out suggest that AMD has outsold Intel in the desktop market [1].
So it's official: CPUs are now in a two-player game. This is only good news for us CPU users, for the last 20 years we've watched and suffered the rise and rise of Intel's 8086 instruction set and their CPUs. It was mostly luck, and marketing: Intel, like Microsoft, got picked by IBM for the PC, and thus were handed the franchise deal of the century. The story goes that Motorola wouldn't lie about their availability date, and it was a month late for the MC68000.
Then, the task became for Intel to hold onto the PC franchise, something any ordinary company can do.
20 years later, Intel's luck ran out. They decided to try a new instruction set for their 64 bit adventure (named Itanium), thinking they could carry the day. It must have been new people at the helm, not seasoned computing vets, as anyone with any experience could tell you that trying a new instruction set in an established market was a dead loss. The path from 1983 to here is littered with the bodies: PowerPC, Sparc, Alpha, ...
In the high end (which is now thought of simply but briefly as the 64 bit end) Itanium is outsold 10 to 1 by AMD's 64 bit ... which just so happens to be the same instruction set as its 32 bit 8086 line offering [2]. By leaving compatibility aside, Intel left themselves wide open to AMD, and to the latter's credit, they took their 32 balls and ran twice as fast.
Sometime about 6 months back Intel realised their mistake and started the posturing to rewind the incompatibility. (Hence the leaks of 64 bit compatibility CPUs.)
But by then it was way too late. Notice how in the above articles, AMD is keeping mum, as is Intel. For the latter, it doesn't want the stock market to realise the rather humungous news that Intel has lost the crown jewels. For the former, there are equally good reasons: AMD's shareholders already know the news, so there's no point in telling them. But, the more it keeps the big shift out of the media, and lets Intel paper up the disaster, the slower Intel is in responding. Only when the company is forced to admit its mistake from top to bottom will it properly turn around and deal with the upstart.
In other words, Intel has no Bill Gates to do the spin-on-a-sixpence trick. So AMD is not trying too hard to let everyone know, and getting on with the real business of selling CPUs against an internally-conflicted competitor. They've cracked the equal position, and now they have a chance of cracking leadership.
Keep quiet and watch [3] !
[1] AMD desktops outsell Intel desktops 54% to 45%
[2] AMD Opteron outsold Intel Itanium by 10X
[3] You can buy this sort of education at expensive B-schools, or get it here for free: AMD Adds Athlon to its Fanless Chips
September 06, 2004
CPUs going dual core
In the news this week is AMD's display of dual-core CPUs - chips with two processors on them that are promised available mid next year. Intel are expected to show the same thing next week [1]. AMD showed Opterons with dual cores, and Intel are expected to show Itaniums (which puts Intel behind as Itaniums haven't really succeeded). Given the hesitation evident in discussions of clock speed improvements, this may signal a shift towards a symmetric future [2].
What this means for the FCer is that we need to assume a future of many smaller processors rather than one big hulking fast one. Which means our state machines need to be more naturally spread across multiple instances. Already covered if you use a threading architecture, or a DB or disk-based state machine architecture, but a nuisance if your state machines are all managed out of one single Unix process.
This isn't as ludicrous as it seems - unless one is actually running on multiprocessor machines already, there are good complexity and performance reasons to steer clear of complicated threading methods.
[1] http://www.eweek.com/article2/0,1759,1642846,00.asp
[2] http://www.informationweek.com/story/showArticle.jhtml?articleID=46800190&tid=5978
September 05, 2004
Financial Cryptography v. The Enterprise
People often say, you should be using XXX. Where, XXX includes for today's discussion, J2EE, and various other alphabet soup systems, also known hilariously as "solutions". (I kid you not, there is a Java Alphabet Soup!) I've been working on one area of this jungle for the last many months, for a website frontend to payments systems - mostly because when it comes to websites, simple solutions don't cut it any more.
I came across this one post by Cameron Purdy which struck as a very clear example of why FC cannot use stuff like J2EE application servers for the backends [1]. The problem is simple. What happens when it crashes? As everything of importance is about transactional thinking, the wise FCer (and there are many out there) builds only for one circumstance: the crash.
Why do we care so much? It's straight economics. Every transaction has the potential to go horribly wrong. Yet, almost all transactions will earn about a penny if they go right. This means that the only economic equation of import in this world is: how many support calls per 1000 transactions, and how much revenue per 1000 transactions? If the answer to the first question is anything different to zero, worry. The worst part of the worry is that it will all seem ok until well after you think you are successful... You won't see it coming, and neither did a half dozen examples I can think of right now!
So every transaction has to be perfect and flawless. To do that, you have to be able to answer the question, what happens if it crashes? And the answer has to be, restart and it carries on. You lose time, but you never have to manually bury a transaction.
And here's the rub: as soon as you pull in one of these enterprise tools (see below for a definition of enterprise!) you can't answer the question. For JBoss, the open source application server under question below, it's "maybe." For all those big selling solutions like Oracle, IBM, SAP etc etc, the answer is: "Oh, yes, we can do that," and how is what Cameron's post describes. In words very briefly, it's a maybe, and it's more expensive [2].
Assuming that you can do all that, and you really do know the issues to address, and you pick the right solution, then the cost to take a fully capable transaction system, and show that it is "right" is probably about the same cost as writing the darn thing from scratch, and making it right. The only difference is that the first solution is more expensive.
That's all IMHO - but I've been there and done that about a half-dozen times now, and I know others in who've made the same soup out of the same staple ingredients. Unfortunately, the whole software market place has no time for anything but an expensive tin of jumbled letters, as you can't sell something that the customer does himself.
[1] What is the recovery log for in a J2EE engine? Cameron Purdy answers: Recovery Log.
[2] Scroll down a bit to message 136589 if you're unsure of this. Ignore the brand and keep the question firmly in mind.
Recovery log
Posted By: Cameron Purdy on September 01, 2004 @ 08:58 AM in response to Message #136449 1 replies in this thread
Does it have a recovery log now? The ability to survive a crash is important.
??? I thought recovery logs was a feature of DB engines. I've never seen that in a J2EE application server. Did you mean a JTA transactions recovery service, used to automatically switch the started JTA transactions to another server in the cluster in case of failure ?
It is for transactions that contain more than one transactional resource, or "Resource Manager" (RM) in OTS parlance. For example, let's say I have MQ Series and an Oracle database, and one of my transactions processes a message from MQ Series and does updates to Oracle. If I fail to commit, then I don't want my partial changes being made to Oracle, which is what a simple JDBC transaction does for me. Even more importantly, if I fail to commit, then I want someone else to get the message from MQ Series, as if I had never seen it.
This is called "recoverable two-phase commit with multiple resource managers," and implies that a recoverable transaction manager log the various steps that it goes through when it commits a transaction. In this case, the "transaction" is a virtual construct with two "branches" - one going to an Oracle transaction and one going to MQ Series. Let's consider what can happen:
1) Something screws up and we roll back the transaction. In this case both branches are rolled back, and everyone is happy. Since we never tried to commit (i.e. we never "prepared" the transactions,) each of the branches would know to automatically roll back if a certain time period passed without notification. This is called "assumed rollback before prepare."
2) Nothing screws up and we commit the transaction. This commit in turn prepares both branches, and if both succeed, then it does a commit on both branches. Everyone is happy.
3) The problem areas exist only once the first branch is requested to prepare, until all branches have been either committed or rolled back. For example, if both branches are prepared, but then the server calling "prepare" and "commit" dies before it gets both "commit" commands out. In this case, the transaction is left hanging and has to be either manually "rolled forward" or "rolled back," or the transaction log needs to be recovered.
This "transaction log" thingie is basically a record of all the potential problem points (prepares, commits, post-prepare rollbacks) that the server managing the "virtual transaction" has encountered. The problem is that when the server restarts and reads its log, it doesn't have the old JDBC connection object that it was using to manage the Oracle transaction, and it doesn't have whatever JMS (etc.) objects that it was using to manage MQ Series. So now it has to somehow contact Oracle and MQ Series and figure out "what's up." The way that it keeps track of the transactions that it no longer has "references" to is to create identifiers for the transactions and each branch of the transaction. These are "transaction IDs", or "XIDs" since "X" is often used to abreviate "transaction." These XIDs are logged in a special kind of file (called a transaction log) that is supposed to be safely flushed to disk at each stage (note that I gloss over the details because entire books are written on this tiny subject) so that when the server comes back up, it is sure to be able to find out everything important that happened before it died.
Now, getting back to the JBoss question, it used to have a non-recoverable implementation, meaning that if the server died during 2PC processing, those transactions would not be recoverable by JBoss. I haven't looked lately, so it could have been fixed already .. there are several open source projects that they could have glued in to resolve it with minimal effort. (JBoss is 90% "other projects" anyway .. which is one of the benefits of being able to make new open source stuff out of existing open source stuff.)
As far as whether it is an important feature is largely irrelevant to most "J2EE" applications, since they have exactly one transactional resource -- the database. However, "enterprise" applications often have more than one RM, and in fact that is what qualifies the applications as being "enterprise" -- the fact that they have to glue together lots of ugly crap from previous "enterprise" applications that in turn glued together ugly crap from previous generations and so-on. (For some reason, some people think that "enterprise applications" are just apps that have lots of users. If that were the case, Yahoo! would be an "enterprise application." ;-)
The funny thing about this particular article is that it's written by a guy who gets paid to sell you open source solutions, so he's writing an article that says it's OK for you to pay him to sell you on JBoss. That doesn't mean that he's right or wrong, it just means that the article is about as objective as a marketing user story .. but at least it was submitted to TSS by the US Chamber of Commerce. ;-)
To answer the question, is JBoss ready for enterprise deployment .. that's a tough one. I know what Bill Burke would say, and if you had Bill Burke working for you full time, then you would probably be comfortable using JBoss for some enterprise deployments. I think that the best way to ascertain the applicability of JBoss (or any product) to a particular problem is to find users who were braver than you and already tried it to solve a similar problem. Further, it's more than just asking "Does it work?" but also finding out "How does it react when things go wrong?" For example, without a recovery log, JBoss will work fine with 2PC transactions .. until a JBoss server crashes. How does it react when you reboot the server? How do you deal with heuristically mixed transactional outcomes? Is it a manual process? Do you know how to resolve the problem? How much does it cost to get support from JBoss to answer the questions?
JBoss if fine for 90% of "J2EE" applications. In fact, it's probably overkill for the 75% of those that should just use Caucho Resin. ;-) The question remains, is it fine for "enterprise deployments." I'm not convinced, but it's only a matter of time until it (or Apache Geronimo) gets there.
Peace,
Cameron Purdy
Tangosol, Inc.
Coherence: Shared Memories for J2EE Clusters
August 25, 2004
Using PGP with an USB smartcard token
The financial cryptographer's decade old dream of token-based security is inching closer. The ideal is a custom configured iPaq or palmPilot with only the secure application on it.
Although lacking a display, here's a cost effective compromise - a USB "keyfob" token that generates your PGP keys and keeps them safe inside the internal smart card. Edwin Woudt wrote up how to hook up a USB token with PGP Inc's current (paid) product, using tokens from OpenFortress.
Hint to the GPG guys - how cool is this?
July 29, 2004
The protocol wars
One of the forgotten wars - TCP/IP versus the OSI stack - was reminded by Lynn Wheeler in a discussion of history. It was so forgotten that it took me a while to recall that indeed it was a war.
For a while, in about 1988, I was part of the standards committee for OSI, or at least the national chapter. My logic for joining was that I would learn about the future, and get a jump on everyone else.
Also, I got the protocols for free which made for a significant benefit, as no-one could afford to buy them. Every week protocol drafts turned up for review, and I read most of them diligently, looking for issues and recommendations. I didn't have much to say, because by the time they got to me, the protocols were either pretty "correct" or too big to absorb. I think others felt the same way, as I never came across any evidence that any one else was reading them.
After a year of this, I got a bit disillusioned. I'd submitted a bug in one of them - the sliding window calculations in the core TCP-like protocol were wrong - and nothing had happened. Mysteriously, the bug is still there, as far as I know. I'd noticed that the stack of protocols was exploding - upwards, sideways, backways, every way you could think of - but there wasn't that much evidence that anyone except big corporates was doing any implementation.
Meanwhile, those who wrote protocols were chugging along and connecting people, as if ISO didn't exist. And those networks were delivering value, whereas the standards bodies were not. So I left, and got back to real work.
My time was well spent. It taught me the value of real work as opposed to time wasting committees. Today's alliances and cartels and these or those initiatives are no different. Quick test - which Internet alliance has deployed a real successful product? Longer test, what percentage do you get dividing that number into the total number of cartels?
For old timers, Lynn's words are spooky. I was there, I was!
-----Original Message-----
From: Anne & Lynn Wheeler [mailto:lynn@garlic.com]
Sent: Sunday, 25 July 2004 12:38 PM
To: ian.peter@ianpeter.com
Subject: history and technology
some of this was replayed in alt.folklore.computers a number of different times over the past 8-10 years. i have a little of it archived at http://www.garlic.com/~lynn/internet.htm as referred to in the above ... there is big difference between technology and operational service. while tcp/ip came into deployment in 1/1/83, a big change-over was the deployment of NSFNET1 & NSFNET2 backbones. These were NSF contracts with commercial entities. There is something to the effect that commercial entities sunk into NSFNET1 between four to five times what NSF actually paid in the contract (as part of promoting an operational, viable infrastructure ... and even more in NSFNET2).
misc. additional refs at:
http://www.garlic.com/~lynn/rfcietf.htm#history
in the late '80s and the early 90s the federal gov. had switched was actively trying to kill tcp/ip and was mandating OSI ... there was a bunch of stuff about GOSIP ... the federal government mandate to eliminate tcp/ip and move to OSI. some specific posts on gosip
http://www.garlic.com/~lynn/99.html#114
http://www.garlic.com/~lynn/99.html#115
http://www.garlic.com/~lynn/2001i.html#5
http://www.garlic.com/~lynn/2001i.html#6
at Interop '88, well over half the booths were demo'ing some sort of OSI related stuff. misc. past post/thread talking about OSI
http://www.garlic.com/~lynn/subnetwork.html#xtphsp
misc. posts discussing interop '88
http://www.garlic.com/~lynn/subnetwork.html#interop
one of the issues (during this period) in the ISO & ANSI standards bodies was there was a mandate that no standards work could happen on anything that didn't conform to the OSI model. That represented a big problem. The "IP" or internetworking layer doesn't exist in OSI and therefor nothing could happen that involved internetworking (strong assertion that the internet is successful precisely because of the internetworking layer ... which is forbidden by ISO & ANSI as not existing in the OSI model. Another thing that doesn't exists in the OSI model is LANs. I was involved in some work with high speed protocol to standardize in ISO/ANSI. However it was rejected for 1) it went directly to the LAN/MAC interface (forbidden because LAN/MAC doesn't exist in the OSI model) and 2) it wen directly from layer 4 to MAC layer (bypassing the layer 3/4 interface, also a violation of the OSI model).
random other arpanet, nsfnet, internet postings
http://www.garlic.com/~lynn/subnetwork.html#internet
concurrent with the tcp/ip in the early & mid '80s was bitnet in the US and earn overseas
http://www.garlic.com/~lynn/subnetwork.html#bitnet
specific post of NSFNET announcement
http://www.garlic.com/~lynn/2002k.html#12
misc. additional NSFNET references
http://www.garlic.com/~lynn/2000e.html#10
--
Anne & Lynn Wheeler | http://www.garlic.com/~lynn/
July 27, 2004
Unix's founding fathers
The Economist has covered the early days of Unix, searching for why Unix and its companion language, C, became so important. They cover it fairly well.
Each successful technology carries its lessons; indeed it is hard to see how a successful technology cannot bring forth some new lessons, just in order to beat the status quo. The cleanliness of the Java virtual machine over the evils of C's buffer overflows and core dumps, for example.
The article didn't get it all, of course. One of the results of the beauty of the design was that the doco was rather small. I recall an experienced programmer, John, standing up in an early user group meeting holding up the manual. "I can take this home in my briefcase," he said, whereas other operating systems filled boxes and book shelves.
Of course, that bug was eventually fixed, and Unix joined its competitors in shipping with boxes of manuals.
Another artifact of the nominal or free delivery to Universities was that by the time the late 80s came around, there were enough software engineers that had trained at University that Unix was an easy sell. When selecting an OS for some project, it was pretty easy to say, "I want something like Unix." And that's one of the two punches that defeated IBM, the other being the PC.
The article also glosses over the role of BSD. It became the competitor, and it also became the one that fixed the (academic) shortfalls for the (commercial) real world. Virtual memory being the chief of those, but also more features, and less security. It's mostly forgotten these days, but BSD blazed the insecurity trail by mostly ignoring issues that the Bell Labs people thought sacrosanct, in the quest for more features.
Yes, we in the Bell labs religion hated the Berkeley religion, but it became the one to open up the net and practically every other application. Partly because the Californians didn't care about security, and partly because they could see the benefit in fast and furious communications. Of course, there were a dozen other lessons, and that's the story of the Internet, not of Unix, but the parallels with Microsoft's current day dilemma are worth pondering over.
On a closing note,
"Dr Pike says that the thing he misses most from the 1970s at Bell Labs was the terminal room."
It's true, I grew up in those places, and now that I think about it, we are only just now recapturing that spirit. The article seems to think that the open source community has inherited the legacy of Unix's collaborative spirit, but I disclaim that: email is too clunky.
Only with IM and potentially VoIP are we at the verge of re-creating the terminal room.
July 26, 2004
Eavesdropping III - do customers get badly hurt?
Over on the cryptography list, Perry Metzger writes:
> I hope you have no customers who you have advised to ignore the
> eavesdropping problem, because they stand a good chance of getting
> badly hurt.
As Perry Metzger declined to permit a rejoinder to that astouning claim on his list, I'll respond here. Warning: It takes few words to be wrong, many words to present a fairer picture.
Perry Metzger is confused by my search for Eve. We can address this at several levels:
1. Firstly, "In Search of Eve - the upper boundary on Mallory."
2. In the crypto world, what we do is to attack crypto systems. In fact, over in the cryptography algorithms side (as opposed to the protocols world of software engineering) professionals are encouraged to attack other people's systems for a decade or so before attempting to invent their own.
But, attacking crypto systems should not be misunderstood as meaning anything beyond the search for weakness so as to improve the result. Exposing a weakness is not a suggestion to turn off the system. It's an invitation to think about the weakness and improve it in future deployments.
3. Oddly enough, in our systems for financial trading, we do indeed tend to tell customers not to worry about the eavesdropping problem! That's because:
a) almost all financial fraud happens on the inside, and our systems are very strong there - unlike anyone else's financial systems who are generally wide open to fraud (not to do with crypto or software engineering,
but see for example "Mutual Funds and Financial Flaws"),
b) even if people could do eavesdropping, the frauds are more limited to things like insider trading and external attacks like competitive trading (recall I posted on fibre vampires earlier this year!),
c) we (and other financial cryptographers) throw in end-to-end encryption protection as a giveaway.
Perry Metzger is almost correct in what he suspects - our system would run 99% as strongly without any eavesdropping protection because most of the threat is on the inside. But, hey, once the software is built in, we tend to leave it in place. It's free, it's end-to-end, and it's transparent. Refreshingly unlike the protection that people are accustomed to getting from the CA/PKI model employed in SSL.
4. On the point of actual cryptographic protection: The systems we have implemented in financial cryptography have generally used RSA 1024+/-, triple DES and so forth. The difference between those systems and the systems others are perhaps more used to is that financial cryptography systems are much more strongly aligned to the customer's needs. For example, my work is the only work where anyone has successfully integrated digital signatures with human contracts, AFAIK, just by way of example ("The Ricardian Contract").
Gary H's SOX is in fact stronger than SSL not because it uses more or less bits but because it is integrated end-to-end. From the issuer to every transaction, it much more clearly aligns to patterns of trade than say something like SSL, which is a connection-oriented product and is thus extremely limited in the protection it can give to any particular business. (Although SOX is almost entirely unscrutinised by outsiders, so there may be bugs in there. I know of one, for example.) See 3., above for why we don't make a song and dance about it.
5. People in financial cryptography have a long history in basic crypto. We started the Cryptix group - the first solution for Java cryptography of any form. I believe it stands on its merits (albeit, it has being overtaken by BouncyCastle these days). Our work with PGP in Java (libraries in 2.6 and OpenPGP) was based on a view that it provides far more security as a model than others can ever hope to achieve (SSL and SSH), simply because the OpenPGP as a model is more aligned to what is needed by people and businesses.
Our Cryptix group provided all the Java infrastructure for the AES competition, running the gauntlet of Americans and foreigners working together to develop strong crypto. Even though we were there at the start, and the finish, we still haven't got around to putting our (public domain) Rijndael into SOX. Why? 3DES does the job.
In closing, when financial cryptographers say "don't worry about the eavesdropping problem," then customers don't need to worry. It's been taken care of, one way or another.
July 24, 2004
In Search of Eve - the upper boundary on Mallory
The primary reason for looking at threats is to develop a threat model [1]. This model then feeds into a security model, which latter decides which threats we can afford to deal with, and how.
But I have a secondary reason for looking at threats. An ulterior motive, as it were. I'm looking for reports of eavesdropping. Here's why. It's not the normal reason.
For the sake of today's polemic, on-the-wire threats divide into a few broad classes: denial of service, traffic analysis, eavesdropping, and the man-in-the-middle attack (MITM). Let's ignore the first two [2] and look at how the HTTPS protocol addresses eavesdropping, committed by Eve, and the MITM, committed by Mallory.
To defend itself, browsing has three major possibilities open to it: open HTTP, self-signed certificates and Certificate Authority (CA) signed certificates [3].
Of those, HTTP defends merely by the presence of masses of other traffic. Hiding in the noise of the net, as it where, which isn't much protection if someone is looking at you, directly, but it's better than nothing, and it's free.
CA-signed certs, on the other hand, protect by comprehensively negotiating secure connections between known parties. Sounds great, but they are expensive both to buy and to install [4] This is the reason why HTTPS is not widely deployed [5]: it's simply too darn expensive for an Internet that was built on "free".
Somewhere in the middle sits the self-signed cert. It can be generated within software, for free. There's no technical reason why a server can't deploy a self-signed cert automatically, and no good business reason why not, either [6]. It's a matter of a few seconds to create, and the SSL protocol handles it just fine.
It would seem to be a no-brainer that HTTPS would deploy much more widely, more rapidly, and more conveniently if it could bootstrap with self-signed certs.
Self-signed certs provide complete, 100% protection from eavesdropping. But they do have one weakeness - the MITM. Mallory can sneak in on the first connection or use and take control. And this weakness is touted as the major reason why, de facto, browsers force the use of CA-signed certs by discriminating against self-signed certs with popup warnings and dialogs and complicated security displays.
So the question comes down to this: How much security do we get by choosing CA-signed certs over self-signed certs? That question comes down to two things: how costly is an MITM, and how frequent is it.
Declaring my hand immediately, I don't think the MITM exists [7]. Or, Mallory is so rare that he will never be a threat. But I can't prove a negative. Also, say some, surely there is some merit in the argument that he isn't there because we deployed HTTPS? But that is to confuse cause and effect - we still need to prove that Mallory is present in any sense if we need to show that we have to protect against him.
There was little or no evidence of Mallory before HTTPS. And there is precious little now, in any field of computing endeavour [8].
There is another way however - instead of measuring Mallory, we can measure a *proxy* for Mallory. This is quite a sensible approach, and is widely used in statistics and risk measurement.
Eve is a great proxy. Here's why: Anyone likely to launch a man-in-the-middle attack is almost certainly eavesdropping already. And anyone who can't eavesdrop has no chance of running an MITM, skills-wise. Plus, Eve is a low risk attack, whereas Mallory takes risks by sending out packets.
So, the set of all MITMs is a subset of all eavesdroppers, at least for statistical purposes. We find Eve and we find something about Mallory - an upper bound.
We can't measure Mallory, he's simply too rare. But we could set at least an upper bound with a measure of Eve, his naughty cousin. And if that upper bound comes in at serious levels, we might deal with it. If not, then not.
The search for Eve is on! I've been looking for a year, by scanning all the news of threats, and last month I kept the list and posted a summary [9]. Yup, there's Eve, right up there in the first on on the list (obviously):
"Via eavesdropping, terror suspects nabbed" / Intelligence officials use cellphone signals to track Al Qaeda operatives, as number of mid-level arrests rises [10].
The attacker (in security terms) is listening to the victim (again, in security terms) using the cell phone network. That's over in Iraq, where they have armies and killing and destruction and things, so you'll pardon me if I present that as an example that has only hypothetical relevence to the Internet.
Which remains blissfully peaceful, and also apparently unlistened to, certainly in the last month. And that's been the pattern on the net, since whenever.
What can we conclude about MITMs? Here's a total stab in the dark: MITMs will be about 2 orders of magnitude less common than eavesdropping attacks (that's my guess, you make your own). So if there are 100 cases every month of eavesdropping - which might happen, and we'd not know about it - then there could be one MITM every month.
100 Eves a month might happen - the Internet's a big place [11]. I'd personally be suspicious of a claim of 1000 per month, that's too high to not be noticed [13].
So, I conclude that there might be about one Mallory per month, and we simply can't find him. Mallory gets away with his MITM.
Should we then protect against him? Sure, if you want to, but definitely optional, if it costs money. One case - hypothetical or otherwise - can never create enough cost and risk to cover society-wide costs. Remember, the Internet's a big place, and we only worry about things that happen to a lot of people.
The MITM is thus ruled out as a threat that simply must be protected against. Therefore, there is no foundation to the treatment of self-signed certificates as being too weak to promote!
That's the logic. Tricky, wasn't it? Eve is quite rare, and measurably so. Therefore Mallory is even rarer. Which means we don't need to pay any money to worry about him.
When doing scientific analysis of complex systems, especially for security purposes, we often have to make do with proxies (approximations) instead of the real measures. The same thing happens with economics; we can't easily test our designs against reality, we have to deploy and wait for the crooks to find us. This means we always have to keep our feet close to the ground, and take very careful steps, otherwise w
e start floating away on our assumptions.
Then, we end up with systems that are widely exploitable, and we just don't know how we got there. Or how to deal with it. (Well-read readers will recognise that phishing has that floating feeling of "just how did this happen?")
The logic above shows why a vote against self-signed certs is actually a vote *against* eavesdropping protection [14]. The fact that we got there by measuring eavesdropping and finding it low is interesting and perverse [15]. Nonetheless, the question remains whether we want to protect against eavesdropping: if so, then the answer is to deploy the self-signed cert.
In the meantime, keep your eye out for more reports of Eve. She will slip up one day, she's very natty, but not perfect.
[1] As an example, here is some work on a threat model for secure browsing, done for the Mozilla effort.
http://iang.org/ssl/browser_threat_model.html and http://iang.org/maps/
[2] I'm ignoring DOS and traffic analysis just for this argument. In a real security analysis, they should be better treated.
[3] There is another way: anonymous Diffie-Hellman (ADH), or ephemeral Diffie Hellman. Again, I'll ignore that, because it is deprecated in the RFC for TLS and also because most browser / server combos fail to implement it.
[4] All this cost falls on merchants, but they simply pass it on to consumers, so, yes, it costs us all.
[5] http://iang.org/ssl/how_effective.html or this month's embarrassment at http://www.securityspace.com/s_survey/sdata/200406/certca.html
gives 177k certs across 14 million servers. About 1%.
[6] There are many known bad reasons. I won't address those today.
[7] http://iang.org/ssl/mallory_wolf.html
[8] I've actually been scanning news reports for rumour of stolen credit cards - off the wire - since HTTPS started. But, no joy, not even amongst the many smaller merchants that don't use SSL. The credit card companies confirm that they have never ever seen it.
[9] There are some anecdotes. For the record, we generally rule out demos and techie boasts as threats.
[10] http://www.financialcryptography.com/mt/archives/000183.html
[11] By Faye Bowers June 02, 2004 http://www.csmonitor.com/2004/0602/p02s01-usmi.html
[12] By way of example, about 10,000 to 20,000 Linux servers get hacked every month, and people notice. Meanwhile about 200 BSD boxes get hacked a month, and that's so small that nobody notices. See the mi2g figures.
[13] Again, you pick your own numbers and justify your assumptions. It's called science.
[14] Voting against self-signed certs is also a vote against protecting against Mallory. For this even more perverse result, think of the stalled deployment, and check out the marketing angle:
[15] For the record, I believe that eavesdropping will increase dramatically in the future. But that's another story.
http://iang.org/ssl/dr_self_signed.html
July 16, 2004
History of OpenPGP
The OpenPGP project has a long and interesting history. Here's some links on the worthwhile effort to document the rise and rise of this great project.
Fabian Rodriguez
PGP Corp
Wikipedia
It seems one story has been forgotten, including my own small contribution - the great saga of the PGP 5.0 source code book. The scanning was finished by a team that I coordinated at HIP97. We completed the task, but most of the work had been done by an international team which was coordinated out of Norway by Ståle Schumacher. Not to mention the work done by the original publishers, PGP Inc themselves, and Lucky Green's carriage of the books past the unhappy border guards tasked to protect the world from American cryptography.
Once the book was in the hands of the infidel foreigners, the task was to scan and OCR each page, and construct the source code from the results. To us at HIP was left the last 1% of the OCRs. As it was all the tail-end stuff, the 1% was the hardest - the ones with errors that defied the simpl scanning, OCRing and checksumming process. With about 20 volunteers (of the 3000 or so people at HIP), we set to with a vengeance. Proofreading and error correction was the order of the day.
We must have been going for about 24 hours on the project, and what was left was a bunch of pages that just defied checksums. I wrote a bunch of scripts that did things like insert tabs in where they could be hidden amongst spaces, and mass crunched through errant pages. The final page fell when the Scandanavians read out to us over the phone one particular line - where it should have had a vertical bar "|", it had a digit one "1". An easy mistake to make but it left us cussing and swearing.
It was 3 in the morning when we finally sent out the last fixes, and 2 hours later the Scandanavians pushed out the source code world wide. By this time, the party had broken, there were snoring dead bodies everywhere, and nothing intelligent was being done - a lot of the final work was completed surrounded by one of those head banging disco scenes the Dutch are infamous for.
I thought I'd written about the great adventure somewhere, but I couldn't find any evidence of that. For those interested in more HIP colour, read these rants:
It's cool to be iang@hip97.nl
Hipped on PGP
And bear in mind that we may be due for another in the series. Anybody know anything of plans for 2005? Also, see this additional story of PGP 5.5 - where our OCR experience was put to much good use with new tools and formats, and enabled Teun Nijssen and Stale to do the whole lot in a tenth of the time, by themselves.
July 02, 2004
Real Time Java is coming...
This article announces the arrival of real time Java. Being the premier big systems language, the niggles and flaws in Java have always been writ large - the lack of access to the OS is my particular bug bear due to the dramatic expense of dealing with it in real world systems that need to be reliable. Another big problem in performance systems is getting the garbage collector under control. There's only desultory efforts for that, things like the WeakReferences allow a programmer to code defensively, but they don't give control.
Real time is another area where Java just won't cut it, and not only because of the GC issue. In my experience, real time is hard. It requires a top-to-bottom philosophy, and most after-the-fact reworks of systems end up being near-real-time but not the real McCoy. Still, the features that get added always find a use somewhere, so even near-real-time is useful for expanding the solution set.
June 28, 2004
The Legacy of ASCII
The creator of ASCII, Bob Bemer, has died [1]. I didn't even know who he was, until he was dead, but I certainly knew what ASCII was. And is.
The effect of the creation of ASCII is hard to exaggerate. Growing up as a boy with toys in the 70s, there were many new machines with strange ways of doing things. HP calculators, big desktop calculating machines with multilayered neon numbers, hobby kits owned by mad professors, and apple IIs; these all had their quirks. As late as the early 80s, the big supercomputer at my University used 60 bit words, into which 10 characters were packed. Yes, String instructions for modern languages had "pack" and "unpack" in them, an acknowledged compromise, but the Cyber engineers knew better.
ASCII, and the power of 2, changed all that. It took a while, but slowly, everything became multiples of 8 bits, and all text became straight ASCII. EBCDIC became a bad joke and others were used as trivia questions at hacker gatherings (yes, we were all called hackers in those days). RS232 followed, and we found ourselves in a world where any computer could talk to any other. Albeit, slowly, via a 2400 baud cable soldered to 25 pins, or a tape calculated in 3/4 inch stop blocks. But it could be done with a 50 line program (typed from memory) or a blocking conversion routine (written from scratch, or using some learnt-by-heart parameters for a strange program).
Following on from this slow revolution in compatibility, there have been few standards developments as impressive. Here's a stab at a few:
- The IBM PC
- IP - being Internet Protocol, not intellectual property
- WWW
- DOC.
- the mobile or cellular phone
- C
Yes, DOC files are in there as the ubiquitous poor man's text transmission method. It's impossible to tell people that they don't need to attach a file to an email, the 10 line email as a 100k Word attachment has achieved ubiquity. Maybe it's just some secret popup I haven't found yet "Microsoft believes the email you are about to send is too efficient, do you wish to send a Word Attachment instead?"
Note that which is not in the list: PDF, IM/chat, ISO networking, Windows (Microsoft or X), Google, PDAs, smartcards, XML, ... YMMV, but these haven't really made it to the level of pervasiveness that the above list expresses. Comments please, but be prepared to argue your case!
[1] Key computer coding creator dies
http://www.zeropaid.com/news/articles/auto/06252004b.php
May 05, 2004
Cost of Phishing - Case in Texas
Below is the first quantitative estimate of costs for phishing that I have seen - one phisher took $75,000 from 400 victims. It's a number! What is needed now is a way to estimate what the MITM attack on secure browsing has done in terms of total damages across the net.
U.S. shuts down Internet 'phishing' scam
Monday, March 22, 2004 Posted: 3:59 PM EST (2059 GMT)
WASHINGTON (Reuters) -- The U.S. government said Monday it had arrested a Texas man who crafted fake e-mail messages to trick hundreds of Internet users into providing credit card numbers and other sensitive information.
Zachary Hill of Houston pleaded guilty to charges related to a "phishing" operation, in which he sent false emails purportedly from online businesses to collect sensitive personal information from consumers, the Federal Trade Commission said.
According to the FTC, Hill sent out official-looking e-mail notices warning America Online and Paypal users to update their accounts to avoid cancellation.
Those who clicked on a link in the message were directed to a Web site Hill set up that asked for Social Security numbers, mothers' maiden names, bank account numbers and other sensitive information, the FTC said.
Phishing has emerged as a favorite tool of identity thieves over the past several years and experts say it is a serious threat to consumers.
Hill used the information he collected to set up credit-card accounts and change information on existing accounts, the FTC said. He duped 400 users out of at least $75,000 before his operation was shut down December 4, FTC attorneys said.
Hill will be sentenced on May 17, according to court documents.
A lawyer for Hill was not immediately available for comment.
Scam artists have posed as banks, online businesses and even the U.S. government to gather personal information, setting up Web pages that closely mirror official sites.
FTC officials said consumers should never respond to an e-mail asking for sensitive information by clicking on a link in the message. "If you think the company needs your financial information, it's best to contact them directly," FTC attorney Lisa Hone said.
Those who believe they may be victims of identity theft should visit the FTC's Web site (www.consumer.gov/idtheft), she said.
America Online is a division of Time Warner Inc., as is CNN. Paypal is owned by eBay Inc.
Addendum: The FTC appears to have settled with Zachary. The amount phished is now set at $125k but is unrecovered. (This is over the *two* cases charged below, who appear to be the same case.)
"Phishers" Settle Federal Trade Commission Charges
Friday, June 18 2004 @ 06:17 AM Contributed by: ByteEnable
Operators who used deceptive spam and copycat Web sites to con consumers into turning over confidential financial information have agreed to settle Federal Trade Commission charges that their scam violated federal laws.
The two settlements announced today will bar the defendants from sending spam, bar them from making false claims to obtain consumers' financial information, bar them from misrepresenting themselves to consumers, and bar them from using, selling, or sharing any of the sensitive consumer information collected.
Based on financial records provided by the defendants, the FTC agreed to consider the $125,000 judgments in each case satisfied. If the court finds that the financial documents were falsified, however, the defendants will pay $125,000 in consumer redress. One of the defendants also faces 46 months in prison on criminal charges filed by the Justice Department.
The scam, called "phishing," worked like this: Posing as America Online, the con artists sent consumers e-mail messages claiming that there had been a problem with the billing of their AOL accounts. The e-mail warned consumers that if they did not update their billing information, they risked losing their accounts. The messages directed consumers to click on a hyperlink in the body of the e-mail to connect to the "AOL Billing Center." When consumers clicked on the link they landed on a site that contained AOL's logo, AOL's type style, AOL's colors, and links to real AOL Web pages. It appeared to be AOL's Billing Center. But it was not. The defendants had hijacked AOL's identity and used it to steal consumers' identities. The defendants ran a similar scam using the hijacked identity of PayPal.
The FTC charged the defendants with violating the FTC, which bars unfair and deceptive practices, and the Gramm Leach Bliley Act, which bars using false or fictitious statements to obtain consumers' financial information.
The settlements bar the defendants from sending spam for life. They bar the defendants from:
- Misrepresenting their affiliation with a consumer's ISP or online payment service provider;
- Misrepresenting that consumers' information needs to be updated;
- Using false "from" or "subject" lines; and
- Registering Web pages that misrepresent the host or sponsor of the page.
The settlements bar the defendants from making false, fictitious, or fraudulent statements to obtain financial information from consumers. They bar the defendants from using or sharing the sensitive information collected from consumers and require that all such information be turned over to the FTC. Financial judgments were stayed based on financial disclosure documents provided by the defendants showing they currently are unable to pay consumer redress. Should the court find that the financial disclosure documents were falsified, the defendants will be required to give up $125,000 in ill-gotten gains. The settlements contain standard record keeping provisions to allow the FTC to monitor compliance with the orders.
The defendant named in one of the complaints is Zachary Keith Hill. The Hill case was filed in December 2003, in the U.S. District Court for the Southern District of Texas. The other case, filed in May 2004, charged an unnamed minor in U. S. District Court for the Eastern District of New York.
These cases were brought with the invaluable assistance of the Department of Justice Criminal Division's Computer Crimes and Intellectual Property Section, Federal Bureau of Investigation's Washington Field Office, and United States Attorney for the Eastern District of Virginia's Computer Hacking and Intellectual Property Squad.
The Commission vote to accept the settlements was 5-0.
A newly revised FTC Consumer Alert, "How Not to Get Hooked by a 'Phishing' Scam" warns consumers who receive e-mail that claims an account will be shut down unless they reconfirm their billing information not to reply or click on the link in the e-mail. Consumers should contact the company that supposedly sent the message directly. More tips to avoid phishing scams can be found at http://www.ftc.gov/bcp/conline/pubs/alerts/phishingalrt.htm.
Consumers who believe they have been scammed by a phishing e-mail can file a complaint at http://www.ftc.gov, and then visit the FTC's Identity Theft Web site at www.consumer.gov/idtheft to learn how to minimize their risk of damage from ID theft. Consumers can also visit www.ftc.gov/spam to learn other ways to avoid e-mail scams and deal with deceptive spam.
NOTE: Stipulated final judgments and orders are for settlement purposes only and do not constitute an admission by the defendant of a law violation. Consent judgments have the force of law when signed by the judge.
Copies of the complaints and stipulated final judgments and orders are available from the FTC's Web site at http://www.ftc.gov and also from the FTC's Consumer Response Center, Room 130, 600 Pennsylvania Avenue, N.W., Washington, D.C. 20580. The FTC works for the consumer to prevent fraudulent, deceptive, and unfair business practices in the marketplace and to provide information to help consumers spot, stop, and avoid them. To file a complaint in English or Spanish (bilingual counselors are available to take complaints), or to get free information on any of 150 consumer topics, call toll-free, 1-877-FTC-HELP (1-877-382-4357), or use the complaint form at http://www.ftc.gov. The FTC enters Internet, telemarketing, identity theft, and other fraud-related complaints into Consumer Sentinel, a secure, online database available to hundreds of civil and criminal law enforcement agencies in the U.S. and abroad.
April 05, 2004
The Future of Phishing
The Future of Phishing
by Dr. Jonathan Tuliani - UK Technical Manager for Cryptomathic Ltd. - Monday, 5 April 2004.
This article examines how attackers are likely to respond to the current move towards 2-factor authentication as a defence against phishing scams, and describes an alternative approach, available today, that provides a longer-term solution.
In recent months, newspaper and television reports have highlighted how highly-organised criminal gangs are launching large-scale, carefully planned attacks against high-street banks and other services, both in the UK and overseas. These so-called 'phishing' attacks begin with an email. Appearing to come from the bank, it leads the recipient to a convincing web page, at which point he is tricked into entering his username and password.
Of course the web page has been set up by the attacker and does not belong to the bank at all. Once obtained, these details are used by the attacker to log-in to the user's account and drain it of funds.
Surely, in an ideal world the user would realise that the web page is bogus - that's what SSL/TLS is all about, right? Unfortunately, a combination of browser flaws, DNS attacks, lack of control over root SSL certificates and the need to make systems user-friendly means that for most users, detecting a fraudulent web page is nigh-on impossible. Moreover, the economics of spam requires that only a very small percentage of users need to fall for the scam for it to be worthwhile.
The current industry trend to counter this threat is the introduction of stronger user authentication. For reasons of cost, mobility, ease of deployment and user acceptance, password-generating tokens are the most commonly adopted technology. These supply the user with a one-time-password, a random string of letters or digits that is valid only for a single use. The idea is that the attacker is thwarted since the one-time-password, once obtained, has already been used or has expired.
Password-generating tokens are offered by a variety of vendors. The password is generated cryptographically based on a key shared with the bank, and varied either by means of a clock, a counter value or a user-input challenge - perhaps even a combination of the three. The key may be internal to the token or a separate card and card reader may be used - the Association of Payment Clearing Services (APACS) has devised a scheme based on existing retail banking chip-cards and PINs. Each scheme has both advantages and disadvantages, and these must be considered and balanced in the context of the business requirements.
The history of security teaches us that it would be wrong to assume that the introduction of two-factor authentication will be the end of the story. Faced with additional security measures, we must assume that the attacks will evolve, and more advanced exploits will emerge. What might these be, and how might we prepare for or respond to them?
My firm belief is that the next few years will see the emergence of internet man-in-the-middle attacks. Here, the user is tricked exactly as described above, except that instead of just the user communicating with the attacker, the attacker is also communicating in real-time with the bank. Two (or even ten) factor authentication is of no help, since the attacker doesn't interfere with the log
-in process. Both the user and the bank are unaware of the presence of the attacker, and believe they have a secure connection directly from one to the other.
Once established, the man-in-the-middle has complete control. He can modify instructions, for example transferring funds to a different account to that specified by the user. Most simply, he can simply cut the user off and submit whatever instructions he desires directly to the bank. The most obvious way to combat this problem is to stop it arising in the first place. Unfortunately, this requires the widespread deployment of a trustworthy and foolproof PC interface, something which is beyond the current technology horizon. In the absence of this, a more lateral approach is required.
The widespread adoption of mobile phones and SMS text messaging offers an alternative channel between the user and the bank. Whilst it is neither authenticated nor encrypted, it is in practice infeasible for an attacker to compromise both the SSL/TLS channel and the SMS channel to a particular user simultaneously.
Several vendors already offer the option of one-time-password distribution via SMS as a cost-effective alternative to password-generating tokens. However, this independent channel also offers a way around the man-in-the-middle. To achieve this, it is necessary to move away from session-based security (based on a secure log-in), to message-based security (based on explicit authentication of individual transactions).
In this scenario, the user would log on using his username and password, exactly as he does today. For each transaction entered, a summary would be returned to the user together with a one-time-password, in the form of an SMS. For example, 'Pay \xa350 to British Gas a/c 12345? Confirm: ADJPEQ'. Any tampering with the transaction details would be evident at this point. Assuming all is correct, the user enters the one-time-password into his PC to confirm the transaction.
As well as thwarting man-in-the-middle attacks, this approach defends against another significant emerging threat, namely malicious 'Trojans' on the user's PC. Apart from being used in direct attacks, a user may claim infection in an attempt to repudiate a legitimate transaction. The mobile phone is a separate user interface, independent of the (possibly infected) PC, thereby effectively closing this vulnerability.
Adoption of SMS-based security measures must be carefully managed, particularly the procedures used for registering and maintaining records of users' mobile phone numbers. The benefits, however, are great: there is no other cost-effective system offering defence against phishing, man-in-the-middle and Trojan attacks whilst maintaining a simple and intuitive user experience.
----
Cryptomathic Ltd. are exhibiting at Infosecurity Europe 2004 which is Europe's number one IT Security Exhibition. Now in its 9th year, the show features Europe's most comprehensive FREE education programme, and over 200 exhibitors at the Grand Hall at Olympia from 27th to the 29th April 2004.
cybersecurity FUD
The "Security Across the Software Development Lifecycle Task Force" has released a report on cybersecurity[1]. Released on the 1st April, 2004, this report was dismissed in some circles as an April Fool's joke. By others, it was seen to presage future legislation for this, that or the other favourite hobby horse (liability for vulnerabilities, exculpation from vulnerabilities...) [2][3].
Either way, the report is a scary document. Not for the security it promises, but for the power and assurance of its routine socialist claptrap. There is momentum in Washington-based circles to do something, anything, about security, and this report predicts some of those directions.
These people cannot grasp the nature of security, notwithstanding the "impressive credentials" assembled. The whole thing reads like the usual suspects, writing the report to steer criticism away, and curry favour towards. For that reason, it's a prediction of a direction, and not reliable in detail. The ultimate prescription to save America's cyberspace from harm will be subject to more political whim and weather before we know how much damage is to be done.
In summary form, what "simply must be done" is: educate, by instructing the universities on what they should teach, instruct software developers on suitable practices to be employed, fix the patches so they work, and align incentives for developers and against "Cyber Criminals."
Space and time do not permit a larger review, but one can make these observations. The prescriptions on education will cause more outsourcing, not less, as desired, simply because they talk in terms that will raise costs of education, to dubious ends. I.e., less and less ROI. Means more and more real work done where the barriers aren't so exhaustive.
Also striking was the absence of any mention of actual security: things like E, Eros, etc: "No processes or practices have currently been shown to consistently produce secure software [B1.iii]." Instead, we see calls to certify this, verify that, and measure those. In short, more window dressing is required (am I the only one who's offended by the ugly nakedness behind the panes?).
[1] http://www.cyberpartnership.org/SDLCFULL.pdf
[2] http://www.fortune.com/fortune/fastforward/0,15704,606544,00.html
[3] http://www.csmonitor.com/2004/0402/dailyUpdate.html?s=entt
February 14, 2004
Crash-only Software
Here is a recent paper on the notion of programs only recovering and only recovering fast. That is, they never get shut down, only killed. They never start up "normally", only recover.
Ricardo has always done this, and in fact the accounts engine, LaMassana, makes a big play of this design principle as its secret weapon to achieve high reliability and high performance in not so many lines of code. The other components also do that, but aren't stateful, so are less interesting.
There is one area where Ricardo deviates from the paper - pre-emptive or algorithmic crash-rebooting. As we are doing transactions, we want to know the cause of every crash, and either fix it, or not mask it.
Referenced here in the FC-KB
Abstract:: "Crash-only programs crash safely and recover quickly. There is only one way to stop such software by crashing it and only one way to bring it up by initiating recovery. Crash-only systems are built from crash-only components, and the use of transparent component-level retries hides intra-system component crashes from end users. In this paper we advocate a crash-only design for Internet systems, showing that it can lead to more reliable, predictable code and faster, more effective recovery. We present ideas on how to build such crash-only Internet services, taking successful techniques to their logical extreme."
Addendum 2004-07-20 - Zooko alerted me to this blog entry on the paper.
January 21, 2004
CodeCon 2004
The program for CodeCon 2004 has been announced.
CodeCon is the premier showcase of active hacker projects. It is a workshop for developers of real-world applications with working code and active development projects. All presentations will given by one of the active developers, and accompanied by a functional demo.
Highlights of CodeCon 2004 include:
PGP Universal - Automatic, transparent email encryption with zero clicks
Osiris - A free Host Integrity Monitor designed for large scaleserver deployments that require auditable security
Tor - Second-generation Onion Routing: a TCP-based anonymizing overlay network
Vesta - An advanced software configuration management system that handles both versioning source files and building
PETmail - Permission-based anti-spam replacement for SMTP
FunFS - Fast User Network File System - An advanced network file system designed as a successor for NFS
Codeville - Distributed version control system
Audacity - A cross-platform multi-track audio editor
The third annual CodeCon takes place February 20 - 22, noon - 6pm, at Club NV (525 Howard Street) in San Francisco. CodeCon registration is $95; a $20 discount is available for attendees who register online prior to February 1, 2004.
http://www.codecon.org/2004/registration.html
December 14, 2003
RFIDs enter the payments field
More and more people are thinking about payments being done with RFIDs. Here's another article on it:
http://www.cbsnews.com/stories/2003/12/12/tech/printable588346.shtml
I feel another repeat of the smart card money story coming on... RFIDs fall in the "cool and visible" category, not the "solves many problems" category. Still, there's nothing like paying for stuff that people can hold.
RFIDs amount to numbers that can't be easily copied. To do that, they have to be physical, and the production process is very expensive at the level of one RFID, but cheap at the level of many RFIDs.
In any physical payments situation, this could make it possible to easily identify a particular person's account or a paper note purporting to be worth a dollar [1]
But, let's get relativistic here: the advantage over existing techniques is strictly marginal. We can already print difficult-to-forge paper notes, check out the recent Euros as one not-so-leading example. And, credit cards are difficult to copy until one gets access to a database of them [2].
In practice, RFIDs may make a marginal difference to these characteristics. But, make no mistake - the real differences will come in the overall architecture that employs these techniques.
RFIDs will be sugar-coated journo-food, an important role in themselves for establishing the momentum for adoption, but not as critical to the security as people would like.
Think of RFIDs as a repeat of the smart card money story [3]. Anybody who's too focused on the tech will fail. Look for systems to have real architectures behind them.
iang
[1] Retail is the obvious one, but not the most useful. In fact, these devices have more likelihood of making headway in the transport sector - driver-based payments for truckers, petrol, tolls purchases.
[2] If you want to stop credit cards being copied, stop making databases of them!
[3] Next year will be the year of the smartcard, I promise!