March 24, 2010
Why the browsers must change their old SSL security (?) model
In a paper Certified Lies: Detecting and Defeating Government Interception Attacks Against SSL_, by Christopher Soghoian and Sid Stammby, there is a reasonably good layout of the problem that browsers face in delivering their "one-model-suits-all" security model. It is more or less what we've understood all these years, in that by accepting an entire root list of 100s of CAs, there is no barrier to any one of them going a little rogue.
Of course, it is easy to raise the hypothetical of the rogue CA, and even to show compelling evidence of business models (they cover much the same claims with a CA that also works in the lawful intercept business that was covered here in FC many years ago). Beyond theoretical or probable evidence, it seems the authors have stumbled on some evidence that it is happening:
The companys CEO, Victor Oppelman confirmed, in a conversation with the author at the companys booth, the claims made in their marketing materials: That government customers have compelled CAs into issuing certificates for use in surveillance operations. While Mr Oppelman would not reveal which governments have purchased the 5-series device, he did confirm that it has been sold both domestically and to foreign customers.
(my emphasis.) This has been a lurking problem underlying all CAs since the beginning. The flip side of the trusted-third-party concept ("TTP") is the centralised-vulnerability-party or "CVP". That is, you may have been told you "trust" your TTP, but in reality, you are totally vulnerable to it. E.g., from the famous Blackberry "official spyware" case:
Nevertheless, hundreds of millions of people around the world, most of whom have never heard of Etisalat, unknowingly depend upon a company that has intentionally delivered spyware to its own paying customers, to protect their own communications security.
Which becomes worse when the browsers insist, not without good reason, that the root list is hidden from the consumer. The problem that occurs here is that the compelled CA problem multiplies to the square of the number of roots: if a CA in (say) Ecuador is compelled to deliver a rogue cert, then that can be used against a CA in Korea, and indeed all the other CAs. A brief examination of the ways in which CAs work, and browsers interact with CAs, leads one to the unfortunate conclusion that nobody in the CAs, and nobody in the browsers, can do a darn thing about it.
So it then falls to a question of statistics: at what point do we believe that there are so many CAs in there, that the chance of getting away with a little interception is too enticing? Square law says that the chances are say 100 CAs squared, or 10,000 times the chance of any one intercept. As we've reached that number, this indicates that the temptation to resist intercept is good for all except 0.01% of circumstances. OK, pretty scratchy maths, but it does indicate that the temptation is a small but not infinitesimal number. A risk exists, in words, and in numbers.
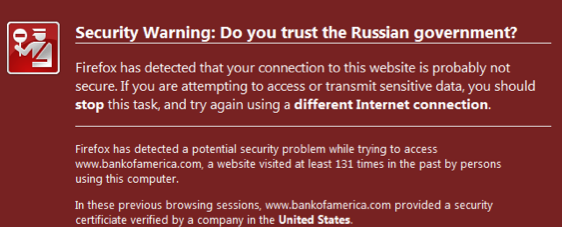
One CA can hide amongst the crowd, but there is a little bit of a fix to open up that crowd. This fix is to simply show the user the CA brand, to put faces on the crowd. Think of the above, and while it doesn't solve the underlying weakness of the CVP, it does mean that the mathematics of squared vulnerability collapses. Once a user sees their CA has changed, or has a chance of seeing it, hiding amongst the crowd of CAs is no longer as easy.
Why then do browsers resist this fix? There is one good reason, which is that consumers really don't care and don't want to care. In more particular terms, they do not want to be bothered by security models, and the security displays in the past have never worked out. Gerv puts it this way in comments:
Security UI comes at a cost - a cost in complexity of UI and of message, and in potential user confusion. We should only present users with UI which enables them to make meaningful decisions based on information they have.
They love Skype, which gives them everything they need without asking them anything. Which therefore should be reasonable enough motive to follow those lessons, but the context is different. Skype is in the chat & voice market, and the security model it has chosen is well-excessive to needs there. Browsing on the other hand is in the credit-card shopping and Internet online banking market, and the security model imposed by the mid 1990s evolution of uncontrollable forces has now broken before the onslaught of phishing & friends.
In other words, for browsing, the writing is on the wall. Why then don't they move? In a perceptive footnote, the authors also ponder this conundrum:
3. The browser vendors wield considerable theoretical power over each CA. Any CA no longer trusted by the major browsers will have an impossible time attracting or retaining clients, as visitors to those clients websites will be greeted by a scary browser warning each time they attempt to establish a secure connection. Nevertheless, the browser vendors appear loathe to actually drop CAs that engage in inappropriate be- havior a rather lengthy list of bad CA practices that have not resulted in the CAs being dropped by one browser vendor can be seen in [6].
I have observed this for a long time now, predicting phishing until it became the flood of fraud. The answer is, to my mind, a complicated one which I can only paraphrase.
For Mozilla, the reason is simple lack of security capability at the *architectural* and *governance* levels. Indeed, it should be noticed that this lack of capability is their policy, as they deliberately and explicitly outsource big security questions to others (known as the "standards groups" such as IETF's RFC committees). As they have little of the capability, they aren't in a good position to use the power, no matter whether they would want to or not. So, it only needs a mildly argumentative approach on the behalf of the others, and Mozilla is restrained from its apparent power.
What then of Microsoft? Well, they certainly have the capability, but they have other fish to fry. They aren't fussed about the power because it doesn't bring them anything of use to them. As a corporation, they are strictly interested in shareholders' profits (by law and by custom), and as nobody can show them a bottom line improvement from CA & cert business, no interest is generated. And without that interest, it is practically impossible to get the various many groups within Microsoft to move.
Unlike Mozilla, my view of Microsoft is much more "external", based on many observations that have never been confirmed internally. However it seems to fit; all of their security work has been directed to market interests. Hence for example their work in identity & authentication (.net, infocard, etc) was all directed at creating the platform for capturing the future market.
What is odd is that all CAs agree that they want their logo on their browser real estate. Big and small. So one would think that there was a unified approach to this, and it would eventually win the day; the browser wins for advancing security, the CAs win because their brand investments now make sense. The consumer wins for both reasons. Indeed, early recommendations from the CABForum, a closed group of CAs and browsers, had these fixes in there.
But these ideas keep running up against resistance, and none of the resistance makes any sense. And that is probably the best way to think of it: the browsers don't have a logical model for where to go for security, so anything leaps the bar when the level is set to zero.
Which all leads to a new group of people trying to solve the problem. The authors present their model as this:
The Firefox browser already retains history data for all visited websites. We have simply modified the browser to cause it to retain slightly more information. Thus, for each new SSL protected website that the user visits, a Certlock enabled browser also caches the following additional certificate information:
A hash of the certificate.
The country of the issuing CA.
The name of the CA.
The country of the website.
The name of the website.
The entire chain of trust up to the root CA.When a user re-visits a SSL protected website, Certlock first calculates the hash of the sites certificate and compares it to the stored hash from previous visits. If it hasnt changed, the page is loaded without warning. If the certificate has changed, the CAs that issued the old and new certificates are compared. If the CAs are the same, or from the same country, the page is loaded without any warning. If, on the other hand, the CAs countries differ, then the user will see a warning (See Figure 3).
This isn't new. The authors credit recent work, but no further back than a year or two. Which I find sad because the important work done by TrustBar and Petnames is pretty much forgotten.
But it is encouraging that the security models are battling it out, because it gets people thinking, and challenging their assumptions. Only actual produced code, and garnered market share is likely to change the security benefits of the users. So while we can criticise the country approach (it assumes a sort of magical touch of law within the countries concerned that is already assumed not to exist, by dint of us being here in the first place), the country "proxy" is much better than nothing, and it gets us closer to the real information: the CA.
From a market for security pov, it is an interesting period. The first attempts around 2004-2006 in this area failed. This time, the resurgence seems to have a little more steam, and possibly now is a better time. In 2004-2006 the threat was seen as more or less theoretical by the hoi polloi. Now however we've got governments interested, consumers sick of it, and the entire military-industrial complex obsessed with it (both in participating and fighting). So perhaps the newcomers can ride this wave of FUD in, where previous attempts drowned far from the shore.
Posted by iang at March 24, 2010 07:52 PM | TrackBackThis post confuses me because it has a real innocence that you don't normally display.
Why is stopping fraud a good thing?
Until you can answer that question I don't think it really possible to overcome the issues you have raised. I'd argue that most governments don't have a real interest is stopping fraud. They might have an interest in appearing as if they are against fraud but it's security theater.
There are two reasons for this. The first is that one has to weigh the cost of stopping fraud with the cost of fraud itself. This is why structuring remains such a bothersome problem despite all the laws against it. In economics they call this the free rider problem. It is often cheaper to let people get away with stealing than perusing the thief.
The second problem is that the chains that bind the consumer bind the government too. Likewise, a wild west type of environment provides good cover for all sorts of nefarious activities.
I think there is very little real interest in "cleaning up the internet".
Posted by: Daniel at March 25, 2010 01:22 PM