October 19, 2018
AES was worth $250 billion dollars
So says NIST...
10 years ago I annoyed the entire crypto-supply industry:
Hypothesis #1 -- The One True Cipher Suite In cryptoplumbing, the gravest choices are apparently on the nature of the cipher suite. To include latest fad algo or not? Instead, I offer you a simple solution. Don't.
There is one cipher suite, and it is numbered Number 1.
Cypersuite #1 is always negotiated as Number 1 in the very first message. It is your choice, your ultimate choice, and your destiny. Pick well.
The One True Cipher Suite was born of watching projects and groups wallow in the mire of complexity, as doubt caused teams to add multiple algorithms- a complexity that easily doubled the cost of the protocol with consequent knock-on effects & costs & divorces & breaches & wars.
It - The One True Cipher Suite as an aphorism - was widely ridiculed in crypto and standards circles. Developers and standards groups like the IETF just could not let go of crypto agility, the term that was born to champion the alternate. This sacred cow led the TLS group to field something like 200 standard suites in SSL and radically reduce them to 30 or 40 over time.
Now, NIST has announced that AES as a single standard algorithm is worth $250 billion economic benefit over 20 years of its project lifetime - from 1998 to now.
h/t to Bruce Schneier, who also said:
"I have no idea how to even begin to assess the quality of the study and its conclusions -- it's all in the 150-page report, though -- but I do like the pretty block diagram of AES on the report's cover."
One good suite based on AES allows agility within the protocol to be dropped. Entirely. Instead, upgrade the entire protocol to an entirely new suite, every 7 years. I said, if anyone was asking. No good algorithm lasts less than 7 years.
Crypto-agility was a sacred cow that should have been slaughtered years ago, but maybe it took this report from NIST to lay it down: $250 billion of benefit.
In another footnote, we of the Cryptix team supported the AES project because we knew it was the way forward. Raif built the Java test suite and others in our team wrote and deployed contender algorithms.
February 27, 2017
Today Im trying to solve my messaging problem...
Financial cryptography is that space between crypto and finance which by nature of its inclusiveness of all economic activities, is pretty close to most of life as we know it. We bring human needs together with the net marketplace in a secure fashion. Its all interconnected, and Im not talking about IP.
Today Im trying to solve my messaging problem. In short, tweak my messaging design to better supports the use case or community I have in mind, from the old client-server days into a p2p world. But to solve this I need to solve the institutional concept of persons, i.e. those who send messages. To solve that I need an identity framework. To solve the identity question, I need to understand how to hold assets, as an asset not held by an identity is not an asset, and an identity without an asset is not an identity. To resolve that, I need an authorising mechanism by which one identity accepts another for asset holding, that which banks would call "onboarding" but it needs to work for people not numbers, and to solve that I need a voting solution. To create a voting solution I need a resolution to the smart contracts problem, which needs consensus over data into facts, and to handle that I need to solve the messaging problem.
Bugger.
A solution cannot therefore be described in objective terms - it is circular, like life, recursive, dependent on itself. Which then leads me to thinking of an evolutionary argument, which, assuming an argument based on a higher power is not really on the table, makes the whole thing rather probabilistic. Hopefully, the solution is more probabilistically likely than human evolution, because I need a solution faster than 100,000 years.
This could take a while. Bugger.
November 15, 2015
the Satoshi effect - Bitcoin paper success against the academic review system
One of the things that has clearly outlined the dilemma for the academic community is that papers that are self-published or "informally published" to borrow a slur from the inclusion market are making some headway, at least if the Bitcoin paper is a guide to go by.
Here's a quick straw poll checking a year's worth of papers. In the narrow field of financial cryptography, I trawled through FC conference proceedings in 2009, WEIS 2009. For Cryptology in general I added Crypto 2009. I used google scholar to report direct citations, and checked what I'd found against Citeseer (I also added the number of citations for the top citer in rightmost column, as an additional check. You can mostly ignore that number.) I came across Wang et al's paper from 2005 on SHA1, and a few others from the early 2000s and added them for comparison - I'm unsure what other crypto papers are as big in the 2000s.
| Conf | paper | Google Scholar | Citeseer | top derivative citations |
|---|---|---|---|---|
| jMLR 2003 | Latent dirichlet allocation | 12788 | 2634 | 26202 |
| NIPS 2004 | MapReduce: simplified data processing on large clusters | 15444 | 2023 | 14179 |
| CACM 1981 | Untraceable electronic mail, return addresses, and digital pseudonyms | 4521 | 1397 | 3734 |
| self | Security without identification: transaction systems to make Big Brother obsolete | 1780 | 470 | 2217 |
| Crypto 2005 | Finding collisions in the full SHA-1 | 1504 | 196 | 886 |
| SIGKDD 2009 | The WEKA data mining software: an update | 9726 | 704 | 3099 |
| STOC 2009 | Fully homomorphic encryption using ideal lattices | 1923 | 324 | 770 |
| self | Bitcoin: A peer-to-peer electronic cash system | 804 | 57 | 202 |
| Crypto09 | Dual System Encryption: Realizing Fully Secure IBE and HIBE under Simple Assumptions | 445 | 59 | 549 |
| Crypto09 | Fast Cryptographic Primitives and Circular-Secure Encryption Based on Hard Learning Problems | 223 | 42 | 485 |
| Crypto09 | Distinguisher and Related-Key Attack on the Full AES-256 | 232 | 29 | 278 |
| FC09 | Secure multiparty computation goes live | 191 | 25 | 172 |
| WEIS 2009 | The privacy jungle: On the market for data protection in social networks | 186 | 18 | 221 |
| FC09 | Private intersection of certified sets | 84 | 24 | 180 |
| FC09 | Passwords: If Were So Smart, Why Are We Still Using Them? | 89 | 16 | 322 |
| WEIS 2009 | Nobody Sells Gold for the Price of Silver: Dishonesty, Uncertainty and the Underground Economy | 82 | 24 | 275 |
| FC09 | Optimised to Fail: Card Readers for Online Banking | 80 | 24 | 226 |
What can we conclude? Within the general infosec/security/crypto field in 2009, the Bitcoin paper is the second paper after Fully homomorphic encryption (which is probably not even in use?). If one includes all CS papers in 2009, then it's likely pushed down a 100 or so slots according to citeseer although I didn't run that test.
If we go back in time there are many more influential papers by citations, but there's a clear need for time. There may well be others I've missed, but so far we're looking at one of a very small handful of very significant papers at least in the cryptocurrency world.
It would be curious if we could measure the impact of self-publication on citations - but I don't see a way to do that as yet.
June 28, 2015
The Nakamoto Signature
The Nakamoto Signature might be a thing. In 2014, the Sidechains whitepaper by Back et al introduced the term Dynamic Membership Multiple-party Signature or DMMS -- because we love complicated terms and long impassable acronyms.
Or maybe we don't. I can never recall DMMS nor even get it right without thinking through the words; in response to my cognitive poverty, Adam Back suggested we call it a Nakamoto signature.
That's actually about right in cryptology terms. When a new form of cryptography turns up and it lacks an easy name, it's very often called after its inventor. Famous companions to this tradition include RSA for Rivest, Shamir, Adleman; Schnorr for the name of the signature that Bitcoin wants to move to. Rijndael is our most popular secret key algorithm, from the inventors names, although you might know it these days as AES. In the old days of blinded formulas to do untraceable cash, the frontrunners were signatures named after Chaum, Brands and Wagner.
On to the Nakamoto signature. Why is it useful to label it so?
Because, with this literary device, it is now much easier to talk about the blockchain. Watch this:
The blockchain is a shared ledger where each new block of transactions - the 10 minutes thing - is signed with a Nakamoto signature.
Less than 25 words! Outstanding! We can now separate this discussion into two things to understand: firstly: what's a shared ledger, and second: what's the Nakamoto signature?
Each can be covered as a separate topic. For example:
the shared ledger can be seen as a series of blocks, each of which is a single document presented for signature. Each block consists of a set of transactions built on the previous set. Each succeeding block changes the state of the accounts by moving money around; so given any particular state we can create the next block by filling it with transactions that do those money moves, and signing it with a Nakamoto signature.
Having described the the shared ledger, we can now attack the Nakamoto signature:
A Nakamoto signature is a device to allow a group to agree on a shared document. To eliminate the potential for inconsistencies aka disagreement, the group engages in a lottery to pick one person's version as the one true document. That lottery is effected by all members of the group racing to create the longest hash over their copy of the document. The longest hash wins the prize and also becomes a verifiable 'token' of the one true document for members of the group: the Nakamoto signature.
That's it, in a nutshell. That's good enough for most people. Others however will want to open that nutshell up and go deeper into the hows, whys and whethers of it all. You'll note I left plenty of room for argument above; Economists will look at the incentive structure in the lottery, and ask if a prize in exchange for proof-of-work is enough to encourage an efficient agreement, even in the presence of attackers? Computer scientists will ask 'what happens if...' and search for ways to make it not so. Entrepreneurs might be more interested in what other documents can be signed this way. Cryptographers will pounce on that longest hash thing.
But for most of us we can now move on to the real work. We haven't got time for minutia. The real joy of the Nakamoto signature is that it breaks what was one monolithic incomprehensible problem into two more understandable ones. Divide and conquer!
The Nakamoto signature needs to be a thing. Let it be so!
NB: This article was kindly commented on by Ada Lovelace and Adam Back.
April 29, 2015
The Sum of All Chains - Let's Converge!
Here's a rough transcript of a recent talk I did for CoinScrum & Proof of Work's Tools for the Future (video).
I was asked to pick my own topic, and what I was really interested in were some thoughts as to where we are going with the architecture of the blockchain and so forth. Something that has come out of my thoughts is whether we can converge all the different ideas out there in identification terms. It's a thought process, it's coming bit by bit, it's really quite young in its evolution. A lot of people might call it complete crap, but here it is anyway. |  |
let's converge... Imagine there is a person. We can look at a picture, what else is there to say? Not a lot. But imagine, now we've got another person. This one is Bob, who is male and blue. |  |
What does that mean? Well what it really means is that if we've got two people, we've got some differences, and we might have to give these people names. Naming only becomes important when we've got a few things, a lot of things, which is somewhat critical in some areas. What then is Identity about? In this context it is about the difference between these entities, Alice versus Bob. Things we can look at with any particular person include: Age, gender, male versus female. We could just do the old ontology thing and collect all this information together into a database, and that should be sufficient. |  |
But things can be a bit tricky. Gender used to quite simple. Now it can be unknown, unstated, it can change, as a relatively new phenomena. On this random slide off the net, down there on the right, it says "I'm bi-gender, so please use they." This brave person, they've gone out on the net, they're interested in secure properties of naming via object capability systems, which is really interesting as that's what we're talking about here, and they want us to refer to them as they. |  |
This really mucks up gender completely as we can no longer use binary assumptions. How do we deal with this? There's a trap here, a trap of over-measurement, a trap of ontology, which leads to paralysis if we're not careful. |  |
Imagine a group of people? What happens when we get a group of people together - it can be called an incorporation, we might need a number, we might need a type. We're going to need rules and regulations, or at least someone will impose regulations over the top of us. We've got quite a lot of information to collect. |  |
We can go further afield. In times historical, we might recall the old sea stories, where they would talk about the ships having names and the engines having names. In modern times, computers have names as do programs. Eliza is a famous old psychology program, and Hal and Skynet come from movies. When the Internet started up it seemed as if every second machine was named Gandalf. There's lots of attributes we can collect about these things as well -- can we identify machines in the same way that we can identify people? Why not? |  |
Let's talk about a smart contract. It's out there, it exists, it's permanent, it's got some sense of reality, so whatever we think it is -- I personally think it is a state machine with money, and there are lots of people hunting around for definitions to try and understand this -- whatever we think it is, we can measure it. We have to be able to find it, we have to be able talk to it. We can find its code, and certainly in the blockchain instantiation of the concept, it's code is everywhere, and its running. We can find its state, if it's a multistate machine, and those are the interesting ones I think. And it probably has to have a name, because it probably needs to market itself out to the world, and you can only really do that with a name. We can collect this information. |  |
If we can do a smart contract, what can't we do a blockchain? With a blockchain, there's certainly a location, there's a bunch of IP numbers out there, a bunch of places we can talk to. There's a lot of technology types out there, and these are important in interpreting the results that come back from it, or how to talk to them, protocols and so forth. There are lots of different types. There's a controller, or there's probably a controller. Bitcoin for example has alertSigningKeys and dnsSeeds. Thelonious for some reasons has a smart contract at the beginning, which is interesting in and of itself. |  |
And, blockchains have a name. Probably a bit of a surprise, there are 4 bitcoin chains. One's called "mainnet", that's the one you're used to using, then there's "testnet" and then a something net and a something-else net. So we can have a "mainnet" can we also have "AliceNet" or "Mynet?" Yes, in theory we can. If you're in the business of doing interesting things with bitcoin, you probably want to talk to corporates, and when you go into talk to corporates, they probably turn around and say "love the concept, but we want our own one! We want to run our own blockchain. We probably want a sidechain, or one of those variants. We want to change the parameters, we want to change it so the performance is different. We want it to go faster, or maybe slower. More security perhaps, or more space. Whatever it is, we want smart contracts rather than money, or money rather than smart contracts, or whatever." | |
|
If we're talking about contracts, they (corporates) probably want a legal environment because they do legal environments with everything else. When you walk into the building, there's a contract. If you walk onto a train platform, there's a contract, it's posted up somewhere. If you buy sweets in a shop, there's a contract. Corporates then likely want some form of contract in their blockchain.
Then there are sidechains. These become interesting because they break a lot of assumptions. The interest behind sidechains has a lot to do with multiple assets. Some people like counterparty or coloured coins are trying to issue multiple assets, and sidechains are trying to do this in a proper fashion. Which means we need to do things like separate out the genesis block out so that it starts the chain, not the currency. We need a separate genesis for the assets. We also need chain identifiers. This is a consequence of moving value from one chain to another, it's a sidechains thing. if you're moving coins between different chains, you then have to move them back again if you want to redeem them on the original chain. They must follow the exact same path, otherwise you get a problem if two coins coming from the same base chain go by different paths and end up on the same sidechain. Something we called diamond coins. |  |
Where is this all going? We need to make some changes. We can look at the blockchain and make a few changes. It sort of works out that if we take the bottom layer, we've got a bunch of parameters from the blockchain, these are hard coded, but they exist. They are in the blockchain software, hard coded into the source code. So we need to get those parameters out into some form of description if we're going to have hundreds, thousands or millions of block chains. It's probably a good idea to stick a smart contract in there, who's purpose is to start off the blockchain, just for that purposes. And having talked about the legal context, when going into the corporate scenario, we probably need the legal contract -- we're talking text, legal terms and blah blah -- in there and locked in. We also need an instantiation, we need an event to make it happen, and that is the genesis transaction. Somehow all of these need to be brought together, locked into the genesis transaction, and out the top pops an identifier. That identifier can then be used by the software in various and many ways. Such as getting the particular properties out to deal with that technology, and moving value from one chain to another. This is a particular picture which is a slight variation that is going on with the current blockchain technology, but it can lead in to the rest of the devices we've talked about. | 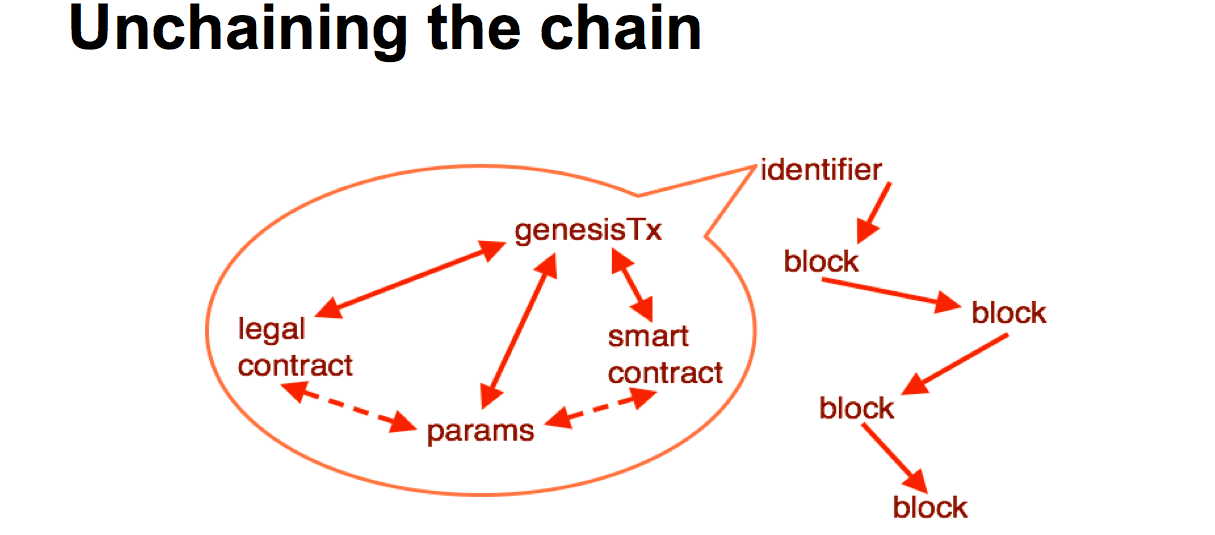 |
Let's talk about a DAO or distributed autonomous organisation. What is that - I'm not entirely sure what it is, and I don't think anyone else is either. It's a sort of corporation that doesn't have the traditional instantiation we are familiar with, it's a thing out there that does stuff, like a magic corporation. It probably lives on a chain somewhere, so it has a location. It's probably controlled by somebody. It might be autonomous, but who would set it up for autonomous reasons, what's the purpose of that? It doesn't make a lot of sense because these things generally want to make profit so the profit needs to go somewhere. Like corporations today, we expect a controller. It probably needs to make contracts with other DAOs, or other entities out there. Which means it needs to do some signing, which means it needs keys. Code, accounts, capital, it needs a whole bunch of stuff. And it has a name, because it has to market itself. |  |
What am I saying here? It kind of looks a lot like the other things above. Issuances have existed in the past, Bitcoin is not the beginning of this space. Before Bitcoin we've had the pound sterling for several hundred years as an issuance. Cyberbux was issued around 1992 as a digital currency. It was given away by David Chaum's company Digicash which issued about 750,000 of them before he was told to stop doing that. Paypal came along as an issuance. Digigold was a gold metal based currency that I was involved with back in the early 2000s, then it was quiet for long time until along came Bitcoin. These issuances all have things in common. They all had an issuer in some sense or other. It is possible to dispute it with Bitcoin, but Satoshi was there starting up the software, so he's essentially the issuer albeit unstated. The issuances have types of technology and types of value such as bonds and shares, etc. There is stuff about symbols to print out, as the user wants to know what it looks like on the screen. Is it GBP, BTC. What are the units, what are the subunits, how many decimal points. We need to know how minting is done. That's hard coded into bitcoin, but it doesn't have to be, it could be in the genesis identity package, so we can tune the parameters. There needs to be a controller, as I pointed out there are some vestiges of control with bitcoin, and future chains will have more control, whereas issuances will have even more control because issuances are typically done by issuers. You want them to be in control because they're making legal claims, which brings us to terms and conditions, so we also need a legal contract. |  |
It looks like the other things, as it has the same elements. Where I'm coming to is that there is a list of First Class Persons in this new space that have the same set of characteristics. Humans, who do stuff, Corporations making decisions, DAOs making profits, smart contracts are making decisions based on inputs, chains are running and are persistent and supposed to be there. Issuances are supposed to serve your value-storing needs for quite some time. Internet of things - it might seem a little funny but your fridge is sitting there with a chip in it, running, and it can do things. It could run a smart contract, it could run a blockchain, it could do anything you like, it has these attributes, it could act as a first class person. |  |
What do these first class persons need? If we line them up on the top axis, and run the characteristics down the left axis, it turns out that we can fill out the table and find that everything needs everything, most of the time. Sure, there are some exceptions, but that's life in the IT business. For the most part they all look the same. | 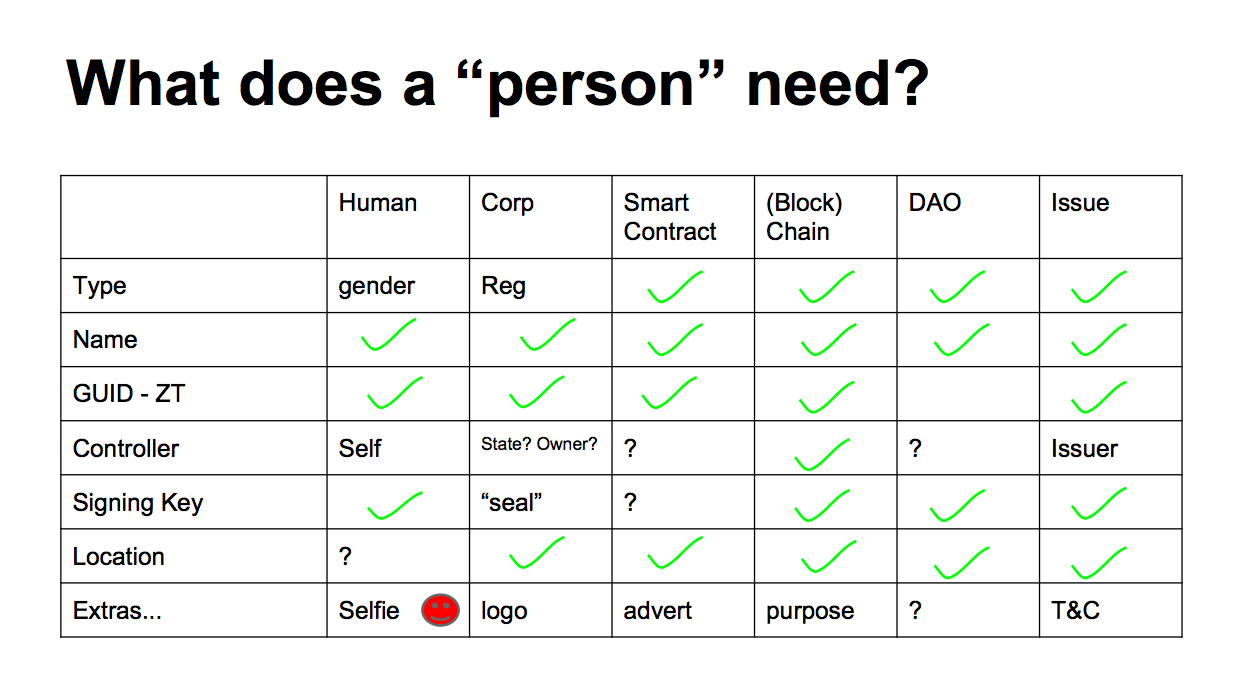 |
What do these First Class Persons do? Just quickly, they instantiate, they communicate, they name each other. Alice needs to send Bob's names to others, she needs to make claims about Bob, and send those claims onto Carol. As we're making some semblance of claim about these entities, the name has to be a decently good reference. Then there will be the normal IT stuff such as identify, share, change, blah blah. |  |
What then is a First Class Person? They have capabilities to make decisions, are apparently intelligent in some sense or other. They have state, they are holding value, they might be holding money or shares or photos, who knows? (Coming back to a question raised in the previous talk) they have intent, which is a legally significant word. |  |
So we're all the same -- we people are the same as smart contracts, as block chains, etc, and we should be able to make recipe that describes us. We should be able to collect all these things together and make it such that we all look the same. |  |
Of course we're all different - the fields in the recipes will all be different, but that's what we IT people know how to do. |  |
Although we can do this -- doing it isn't as easy as saying it. This package has to be tractable, it's got to be relatively small and powerful at the same time. It has to contain text and code at the same time which is a bit tricky. It has to be accessible and easy to implement, which probably means we don't want XML, it may mean we could do JSON, but I prefer line-based tag-equals-value because anyone can read it, nobody has to worry about it, and it's easy to write a parser. Other things: it has to include its own PKI, it cannot really resort to an external PKI because it needs to be in control of its own destiny which means it puts its root key inside itself in a sense more familiar to the OpenPGP people than the x.509 people. And it has to be able to sign things in order to show its intent. |  |
We need an identifier. The easy thing is to take a hash of the package that we've built up. But Zooko's Triangle which you really need to grok Zooko's Triangle to understand the space basically says that we can have an identifier that can have these attributes -- globally context free, securely collision free, human meaningful -- but you can only reach two of them with a single simple system. Hence we have to take the basic system we invent and then square the triangle to get the other attribute, but that's too much detail for this talk. | 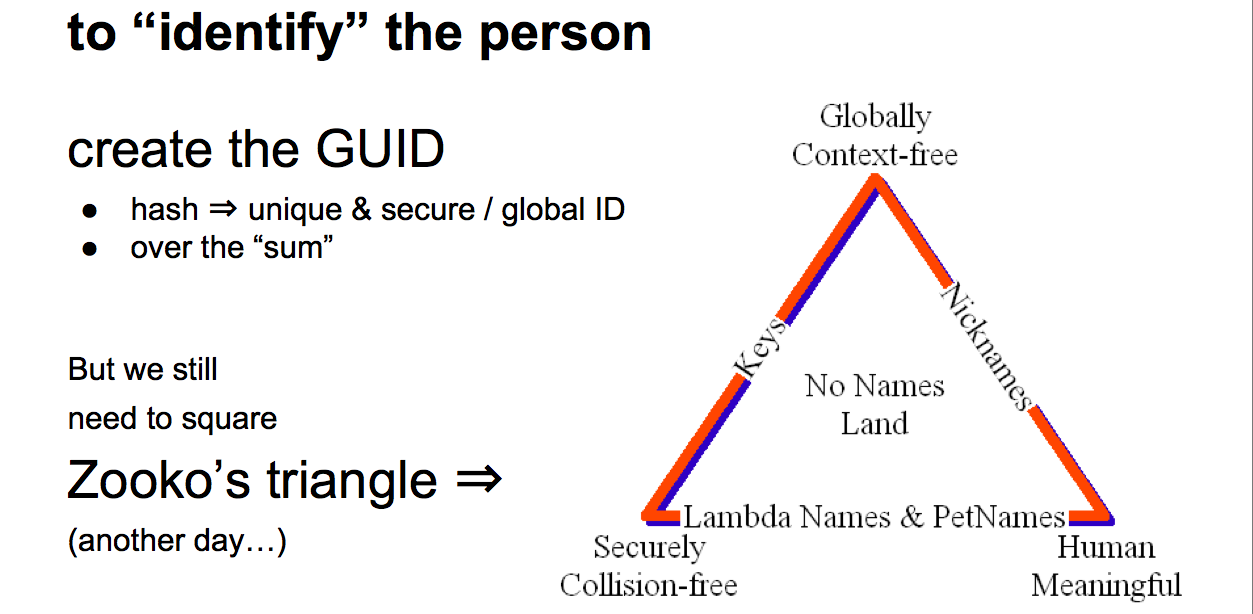 |
What are we seeing? We're capturing a lot of diversity and wrap it back into one arch-type. Capture the code, text, and params, make it work together and get it instantiated and then get the identifier out. The identifier is probably the easy part, although, you'll probably notice I'm skipping something here, which is what we do with that identifier once we've got it. In a sense what we are doing is objectifying and from an OO programming sense we are all objects and we just need to create the object arch-type in order to be able to manipulate all these First Class Persons. |  |
So what does it look like - another triangle containing a legal contract, parameters and a smart contract along the bottom. Those three elements are wrapped up and sent into a genesis transaction, into a something. That something might be a blockchain, might be a server, it might not even be what we think of as a transaction or a genesis, it looks approximately like that so I'm borrowing the buzzword. Out of that package we get an identifier! That is what it looks like today, but I admit it looked a little different yesterday and maybe next week it'll look different again. Some people on the net are already figuring this out. CommonAccord are doing legal contracts, wrapping them up into little tech objects, with a piece of code that they call an object and they have a matching legal document that relates to it. A user goes searching through their system looking for legal clauses, pull out the ones you want, compose them into a big contract. With each little legal clause you pull out, it comes with a bit of smart code, so you end up creating the whole legal text and the whole smart code in the same process. | 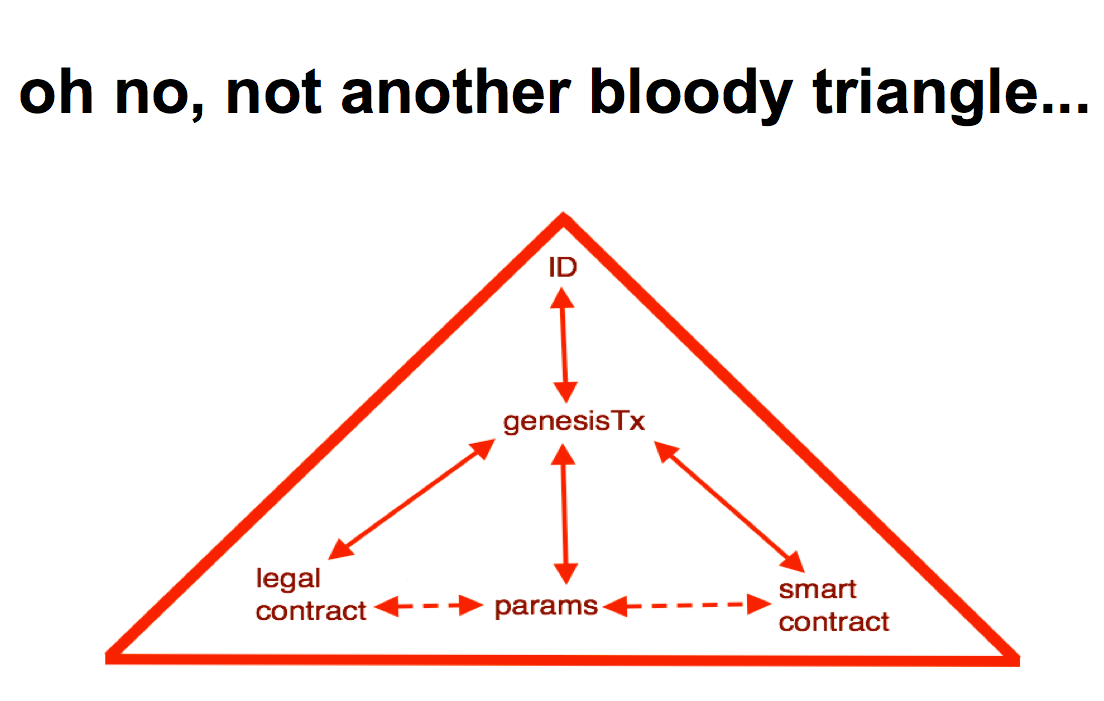 |
CommonAccord are basically doing the same thing described - wrapping together a smart contract with a legal document and then creating some form of identifier out of it when they produce their final contract. It's out there! |  |
How do we do this? Open problems include how to mix the code and text. Both the code and the text can be very big, derivatives contracts can run to 300 pages. Hence some of the new generation blockchain projects have figured out they need to add file store in their architecture. | 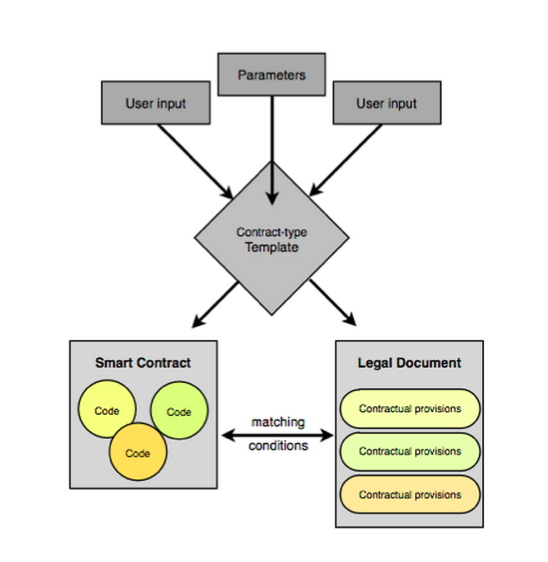 |
We need to take the genesis concept and break it out - the genesis should start the chain not the currency, and we should start the currency using a different transaction. This is already done in some of these systems. Then there are is the "other identity" -- I haven't covered whether this is safe, whether you know the other person is who they claim to be, whether there is any recourse, or intent, or even a person behind an identity, or what? We really don't know any more than what the tech says, and (hand wave) that's a subject for another day. There is a conflict in that we're surfacing more and more information which is great for security as we're locking things down, but it does rather leave aside the question of Privacy? Are we ruining things for privacy? Another question for another day. |  |
References!
- Primavera de Filippi, Legal Framework For Crypto-Ledger Transactions
- Mark Friedenbach and Jorge Timón, FreiMarkets
- Grigg, The Ricardian Contract and On the intersection of Ricardian and Smart Contracts
- Nick Szabo, Smart Contracts
- Zooko Wilcox-OHearn, Names: Decentralized, Secure, Human-Memorizable: Choose Two
Addendum
December 21, 2014
OneRNG -- open source design for your random numbers
 Paul of Moonbase has put a plea onto kickstarter to fund a run of open RNGs. As we all know, having good random numbers is one of those devilishly tricky open problems in crypto. I'd encourage one and all to click and contribute.
Paul of Moonbase has put a plea onto kickstarter to fund a run of open RNGs. As we all know, having good random numbers is one of those devilishly tricky open problems in crypto. I'd encourage one and all to click and contribute.
For what it's worth, in my opinion, the issue of random numbers will remain devilish & perplexing until we seed hundreds of open designs across the universe and every hardware toy worth its salt also comes with its own open RNG, if only for the sheer embarrassment of not having done so before.
OneRNG is therefore massively welcome:
About this projectAfter Edward Snowden's recent revelations about how compromised our internet security has become some people have worried about whether the hardware we're using is compromised - is it? We honestly don't know, but like a lot of people we're worried about our privacy and security.
What we do know is that the NSA has corrupted some of the random number generators in the OpenSSL software we all use to access the internet, and has paid some large crypto vendors millions of dollars to make their software less secure. Some people say that they also intercept hardware during shipping to install spyware.
We believe it's time we took back ownership of the hardware we use day to day. This project is one small attempt to do that - OneRNG is an entropy generator, it makes long strings of random bits from two independent noise sources that can be used to seed your operating system's random number generator. This information is then used to create the secret keys you use when you access web sites, or use cryptography systems like SSH and PGP.
Openness is important, we're open sourcing our hardware design and our firmware, our board is even designed with a removable RF noise shield (a 'tin foil hat') so that you can check to make sure that the circuits that are inside are exactly the same as the circuits we build and sell. In order to make sure that our boards cannot be compromised during shipping we make sure that the internal firmware load is signed and cannot be spoofed.
OneRNG has already blasted through its ask of $10k. It's definitely still worth contributing more because it ensures a bigger run and helps much more attention on this project. As well, we signal to the world:
*we need good random numbers*
and we'll fight aka contribute to get them.

December 04, 2014
MITM watch - sitting in an English pub, get MITM'd
So, sitting in a pub idling till my 5pm, thought I'd do some quick check on my mail. Someone likes my post on yesterday's rare evidence of MITMs, posts a comment. Nice, I read all comments carefully to strip the spam, so, click click...
Boom, Firefox takes me through the wrestling trick known as MITM procedure. Once I've signalled my passivity to its immoral arrest of my innocent browsing down mainstreet, I'm staring at the charge sheet.
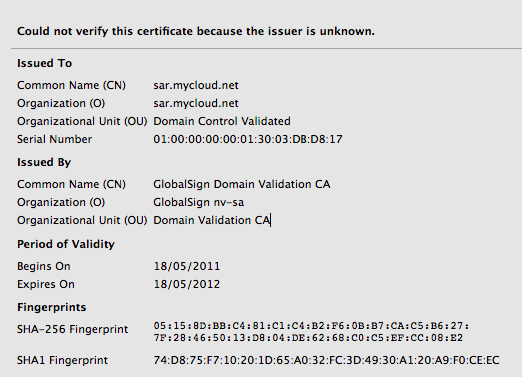
Whoops -- that's not financialcryptography.com's cert. I'm being MITM'd. For real!
Fully expecting an expiry or lost exception or etc, I'm shocked! I'm being MITM'd by the wireless here in the pub. Quick check on twitter.com who of course simply have to secure all the full tweetery against all enemies foreign and domestic and, same result. Tweets are being spied upon. The horror, the horror.
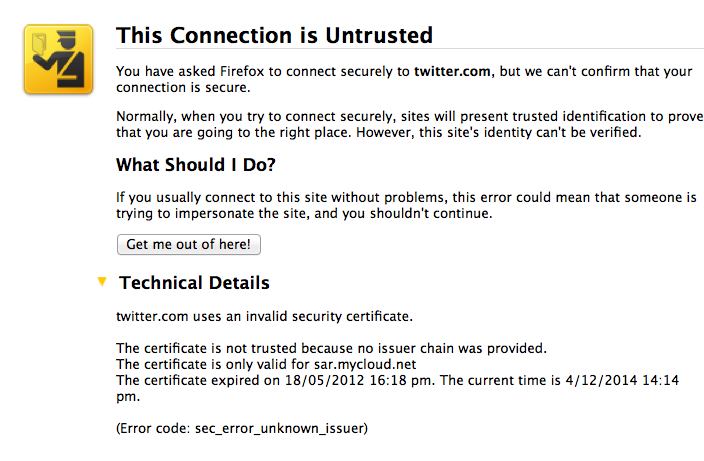
On reflection, the false positive result worked. One reason for that on the skeptical side is that, as I'm one of the 0.000001% of the planet that has wasted significant years on the business of protecting the planet against the MITM, otherwise known as the secure browsing model (queue in acronyms like CA, PKI, SSL here...), I know exactly what's going on.
How do I judge it all? I'm annoyed, disturbed, but still skeptical as to just how useful this system is. We always knew that it would pick up the false positive, that's how Mozilla designed their GUI -- overdoing their approach. As I intimated yesterday, the real problem is whether it works in the presence of a flood of false negatives -- claimed attacks that aren't really attacks, just normal errors and you should carry on.
Secondly, to ask: Why is a commercial process in a pub of all places taking the brazen step of MITMing innocent customers? My guess is that users don't care, don't notice, or their platforms are hiding the MITM from them. One assumes the pub knows why: the "free" service they are using is just raping their customers with a bit of secret datamining to sell and pillage.
Well, just another another data point in the war against the users' security.
June 15, 2014
Certicom fingered in conspiracy to insert back door in standards -- DUAL_EC patents!
In what is now a long running saga, we have more news on the DUAL_EC backdoor injected into the standards processes. In a rather unusual twist, it appears that Certicom's Dan Brown and Scott Vanstone attempted to patent the backdoor in Dual EC in or around January of 2005. From Tanja Lange & DJB:
... It has therefore been identified by the applicant that this method potentially possesses a trapdoor, whereby standardizers or implementers of the algorithm may possess a piece of information with which they can use a single output and an instantiation of the RNG to determine all future states and output of the RNG, thereby completely compromising its security.The provisional patent application also describes ideas of how to make random numbers available to "trusted law enforcement agents" or other "escrow administrators".
This appears to be before ANSI/NIST finished standardising DUAL_EC as a RNG, that is, during the process. **
Obviously one question arises -- is this a conspiracy between Certicom, NSA and NIST to push out a backdoor? Or is this just the normal incompetent-in-hindsight operations of the military-industrial-standards complex?
It's an important if conspiratorial question because we want to document the modus operandi of a spook intervention into a standards process. We'll have to wait for more facts; the participants will simply deny. One curious fact, the NSA recommended *against* a secrecy order for the patent.
What I'm more curious about today is Certicom's actions. What is the benefit to society and their customers in patenting a backdoor? How can they benefit in a way that aligns the interests of the Internet with the interests of their customers?
Or is this impossible to reconcile? If Certicom is patenting backdoors, the only plausible way I can think of this is that it intends to wield backdoors. Which means spying and hacking. Certicom is now engaged in the business of spying on ... customers? Foreign governments?
In contrast, I would have said that Certicom's responsibility as a participant in Internet security is to declare and damn an exploit, not bury it in a submarine patent.
If so, what idiot in Certicom's board put it on the path of becoming the Crypto AG of the 21st century?
If so, Certicom is now on the international blacklist of shame. Until questions are answered, do no business with them. Certicom have breached the sacred trust of trade -- to operate in the interests of their customers.
** Edited to remove this statement:
May 26, 2014
Why triple-entry is interesting: when accounting is the weapon of choice
Bill Black gave an interview last year on how the financial system has moved from robustness to criminogenia:
If you can steal with impunity, as soon as you devastate regulation, you devastate the ability to prosecute. And as soon as that happens, in our jargon, in criminology, you make it a criminogenic environment. It just means an environment where the incentives are so perverse that they are going to produce widespread crime. In this context, it is going to be widespread accounting control fraud. And we see how few ethical restraints remain in the most elite banks.You are looking at an underlying economic dynamic where fraud is a sure thing that will make people fabulously wealthy and where you select by your hiring, by your promotion, and by your firing for the ethically worst people at these firms that are committing the frauds.
No prizes for guessing he's talking about the financial system and the failure of the regulators to jail anyone, nor find any bank culpable, nor find any accounting firm that found any bank in trouble before it collapsed into the mercy of the public purse.
But where is the action? Where is the actual fraud taking place? This is the question that defies analysis and therefore allows the fraudsters to lay a merry trail of pointed fingers that curves around and joins itself. Here's the answer.
So in the financial sphere, we are mostly talking about accounting as the weapon of choice. And that is, where you overvalue assets, sometimes you undervalue liabilities. You create vast amounts of fictional income by making really bad loans if you are a lender. This makes you rich through modern executive compensation, and then it causes tremendous losses to the lender.
The first defence against this process is transparency. Which implies the robust availability of clear accounting records -- what really happened? Which is where triple-entry becomes much more interesting, and much more relevant.
In the old days, accounting was the domain of intra-firm transactions. Double entry enabled the growth of the business empire because internal errors could be eliminated by means of the double-links between separate books; clearly, money had to be either in one place or another, it couldn't slip between the cracks any more, so we didn't need to worry so much about external agents deliberately dropping a few entries.
Beyond the firm, it was caveat emptor. Which the world muddled along with for around 700 years until the development of electronic transactions. At this point of evolution from paper to electronic, we lost the transparency of the black & white, and we also lost the brake of inefficiency in transactions between firms. That which was on paper was evidence and accountable to an entire culture called accountants; that which was electronic was opaque except to a new generation of digital adepts.
Say hello to Nick Leeson, say good bye to Barings Bank. The fraud that was possible now exploded beyond imagination.
Triple-entry addresses this issue by adding cryptography to the accounting entry. In effect it locks the transaction into a single electronic record that is shared with three parties: the sender, the receiver and a third party to hold & adjudicate. Crypto makes it easy for them to hold the same entry, the third parties makes it easy to force the two interested agents not to play games.
You can see this concept with Bitcoin, which I suggest is a triple-entry system, albeit not one I envisaged. The transaction is held by the sender and the recipient of the currency, and the distributed blockchain plays the part of the third party.
Why is this governance arrangement a step forward? Look at say money laundering. Consider how you would launder funds through bitcoin, a fear claimed by the various government agencies. Simple, send your ill-gotten gains to some exchanger, push the resultant bitcoin around a bit, then cash out at another exchanger.
Simple, except every record is now locked into the blockchain -- the third party. Because it is cryptographic, it is now a record that an investigator can trace through and follow. You cannot hide, you cannot dive into the software system and fudge the numbers, you cannot change the records.
Triple-entry systems such as Bitcoin are so laughably transparent that only the stupidest money launderer would go there, and would therefore eliminate himself before long. It is fair to say that triple-entry is practically immunised against ML, and the question is not what to do about it in say Bitcoin, but why aren't the other systems adopting that technique?
And as for money laundering, so goes every other transaction. Transparency using triple-entry concepts has now addressed the chaos of inter-company financial relationships and restored it to a sensible accountable and governable framework. That which double-entry did for intra-company, triple-entry does for the financial system.
Of course, triple-entry does not solve everything. It's just a brick, we still need mortar of systems, the statics of dispute resolution, plans, bricklayers and all the other components. It doesn't solve the ethics failure in the financial system, it doesn't bring the fraudsters to jail.
And, it will take a long time before this idea of cryptographically sealed receipts seeps its way slowly into society. Once it gets hold, it is probably unstoppable because companies that show accounts solidified by triple-entry will eventually be rewarded by cheaper cost of capital. But that might take a decade or three.
________
H/t to zerohedge for this article of last year.
May 19, 2014
How to make scientifically verifiable randomness to generate EC curves -- the Hamlet variation on CAcert's root ceremony
It occurs to me that we could modify the CAcert process of verifiably creating random seeds to make it also scientifically verifiable, after the event. (See last post if this makes no sense.)
Instead of bringing a non-deterministic scheme, each participant could bring a deterministic scheme which is hitherto secret. E.g., instead of me using my laptop's webcam, I could use a Guttenberg copy of Hamlet, which I first declare in the event itself.
Another participant could use Treasure Island, a third could use Cien años de soledad.
As nobody knew what each other participate was going to declare, and the honest players amongst did a best-efforts guess on a new statically consistent tome, we can be sure that if there is at least one honest non-conspiring party, then the result is random.
And now verifiable post facto because we know the inputs.
Does this work? Does it meet all the requirements? I'm not sure because I haven't had time to think about it. Thoughts?
BADA55 or 5ADA55 -- we can verifiably create random numbers
The DJB & Tanje Lange team out of Technische Universiteit Eindhoven, Netherlands have produced a set of curves to challenge the notion of verifiable randomness. Specifically, they seem to be aiming at the Brainpool curves which had a stab at producing a new set of curves for elliptic curve cryptography (ECC).
Now, please note: if you don't understand ECC then don't worry, neither do I. But we do get to black box it like any *useful technology to society* and in that black boxing we might ask, nay, we must ask the question, where the seeds fairly chosen? Or,
Verifiably random parameters offer some additional conservative features. These parameters are chosen from a seed using SHA-1 as specified in ANSI X9.62 [X9.62]. This process ensures that the parameters cannot be predetermined. The parameters are therefore extremely unlikely to be susceptible to future special-purpose attacks, and no trapdoors can have been placed in the parameters during their generation. Certicom SEC 2 2.0 (2010)
Which claim the team set out to challenge:
The name "BADA55" (pronounced "bad-ass") is explained by the appearance of the string BADA55 near the beginning of each BADA55 curve. This string is underlined in the Sage scripts above.We actually chose this string in advance and then manipulated the curve choices to produce this string. The BADA55-VR curves illustrate the fact that, as pointed out by Scott in 1999, "verifiably random" curves do not stop the attacker from generating a curve with a one-in-a-million weakness. The BADA55-VPR curves illustrate the fact that "verifiably pseudorandom" curves with "systematic" seeds generated from "nothing-up-my-sleeve numbers" also do not stop the attacker from generating a curve with a one-in-a-million weakness.
We do not assert that the presence of the string BADA55 is a weakness. However, with a similar computation we could have selected a one-in-a-million weakness and produced curves with that weakness. Suppose, for example, that twist attacks were not publicly known but were known to us; a random 224-bit curve has one chance in a million of being extremely twist-insecure (attack cost below 2^30), and we could have generated a curve with this property, while pretending that this was a "verifiable" curve generated for maximum security.
Which highlights two problems we have with all prior sets of curves: were the curves (seeds) chosen at random, and/or were they chosen to exploit weaknesses we did not know about? The crux here is that if someone does know of a weakness, they can re-run their "verifiably random" process until they get the results get want.
Is this realistic? Snowden says it is. The choosers of the main popular set of curves were the NSA & NIST, and as they ain't saying much other than to deny anything they've already been caught with, we have enough evidence to damn the NIST curves.
This is good stuff, BADA55 as a process highlights this very well. But:
We view the terminology "verifiably random" as deceptive. The claimed randomness (a uniform distribution) is not being verified; what is being verified is merely a hash computation. We similarly view the terminology "verifiably pseudorandom" and "nothing up my sleeves" as deceptive.
goes too far. They reproduced the process (presumably) and showed that it did not meet its own claimed standard, but did not explore how to create a fair seed. We do know how to do this, and there is an entire business case for it, it is the root of a CA. Which gives us at least two answers.
In the CA industry they suggest that hard tech problems be outsourced to a thing called a HSM or High Security Module. This is a hardware device that is strictly produced to the highest standards and testing to produce what we need. In this particular case, the generation of random numbers will be done in a HSM according to a NIST or equivalent standard, and tested according to their very harsh and expensive regimes.
That's the formal, popular, and safe answer, which most CAs use to pass audit [0]. Except, it creates a complicated expensive process which can be perverted by the NSA & friends, as alleged by the Snowden revelations.
At CAcert we did something different. Because we knew that the HSM process was suspect enough to be unreliable, and it had no apparent way to mitigate this risk, we developed our own. In short this is what we do:
- Several trusted people of the community come together, each bringing a random number source of their own choosing. From an example I participated in, I personally used my laptop's webcam on a low-light white cardboard to generate quantum artifacts from the pixcells under harsh conditions. This raw photo I piped through a SHA1.
- Each of these personal sources is mixed in with a small, simple custom-written program.
- Each person examines the custom written program to verify it does the job of generating a seed.
Wrap in some governance tricks such as reporting, observation, and construction of hardware & software on the spot with bog-standard components (for destruction later) and we have a complete process. Accepting the assumptions, this design ensures that the seed is random if at least one person has reliably delivered a good input.
Or so I claim: nothing up at least one person's sleeves means there isn't anything up our collective sleeve.
Granted, there are limitations to this process. /Verifiability/ is a direct part of the process, but it is limited to being there, on the day. Thereafter, we are limited to trusting the reports of those who were there. Hence, it isn't a repeatable experiment in the sense of scientific method, for that we'd need a bit more work.
But quibbles aside about the precise semantics of verifiability, I claim this is good enough for the job. Or, it is as good as it gets. If you combine the Eindhoven process with the CAcert process, then you'll get a set of curves that are reliably and verifiably secure to known current standards.
As good as it gets? If you do that, we'll need a new name for a better, badder set of curves; sadly I can only think of 5A1A55 for Fat-Ass right now.
[0] there is a discordance between the two goals here which I'm wafting past...
April 08, 2014
A very fast history of cryptocurrencies BBTC -- before Bitcoin
Before Bitcoin, there was cryptocurrency. Indeed, it has a long and deep history. If only for the lessons learnt, it is worth studying, and indeed, in my ABC of Bitcoin investing, I consider not knowing anything before the paper as a red flag. Hence, a very fast history of what came before (also see podcasts 1 and 2).
The first known (to me) attempt at cryptocurrencies occurred in the Netherlands, in the late 1980s, which makes it around 25 years ago or 20BBTC. In the middle of the night, the petrol stations in the remoter areas were being raided for cash, and the operators were unhappy putting guards at risk there. But the petrol stations had to stay open overnight so that the trucks could refuel.
Someone had the bright idea of putting money onto the new-fangled smartcards that were then being trialled, and so electronic cash was born. Drivers of trucks were given these cards instead of cash, and the stations were now safer from robbery.
At the same time the dominant retailer, Albert Heijn, was pushing the banks to invent some way to allow shoppers to pay directly from their bank accounts, which became eventually to be known as POS or point-of-sale.
Even before this, David Chaum, an American Cryptographer had been investigating what it would take to create electronic cash. His views on money and privacy led him to believe that in order to do safe commerce, we would need a token money that would emulate physical coins and paper notes. Specifically, the privacy feature of being able to safely pay someone hand-to-hand, and have that transaction complete safely and privately.
As far back as 1983 or 25BBTC, David Chaum invented the blinding formula, which is an extension of the RSA algorithm still used in the web's encryption. This enables a person to pass a number across to another person, and that number to be modified by the receiver. When the receiver deposits her coin, as Chaum called it, into the bank, it bears the original signature of the mint, but it is not the same number as that which the mint signed. Chaum's invention allowed the coin to be modified untraceably without breaking the signature of the mint, hence the mint or bank was 'blind' to the transaction.
All of this interest and also the Netherlands' historically feverish attitude to privacy probably had a lot to do with David Chaum's decision to migrate to the Netherlands. When working in the late 1980s at CWI, a hotbed of cryptography and mathematics research in Amsterdam, he started DigiCash and proceeded to build his Internet money invention, employing amongst many others names that would later become famous: Stefan Brands, Niels Ferguson, Gary Howland, Marcel "BigMac" van der Peijl, Nick Szabo, and Bryce "Zooko" Wilcox-Ahearn.
The invention of blinded cash was extraordinary and it caused an unprecedented wave of press attention. Unfortunately, David Chaum and his company made some missteps, and fell foul of the central bank (De Nederlandsche Bank or DNB). The private compromise that they agreed to was that Digicash's e-cash product would only be sold to banks. This accommodation then led the company on a merry dance attempting to field a viable digital cash through many banks, ending up eventually in bankruptcy in 1998. The amount of attention in the press brought very exciting deals to the table, with Microsoft, Deutsche Bank and others, but David Chaum was unable to use them to get to the next level.
On the coattails of Digicash there were hundreds of startups per year working on this space, including my own efforts. In the mid 1990s, the attention switched from Europe to North America for two factors: the Netscape IPO had released a huge amount of VC interest, and also Europe had brought in the first regulatory clampdown on digital cash: the 1994 EU Report on Prepaid Cards, which morphed into a reaction against DigiCash.
Yet, the first great wave of cryptocurrencies spluttered and died, and was instead overtaken by a second wave of web-based monies. First Virtual was a first brief spurt of excitement, to be almost immediately replaced by Paypal which did more or less the same thing.
The difference? Paypal allowed the money to go from person to person, where as FV had insisted that to accept money you must "be a merchant," which was a popular restriction from banks and regulators, but people hated it. Paypal also leapt forward by proposing its system as being a hand-to-hand cash, literally: the first versions were on the Palm Pilot, which was extraordinarily popular with geeks. But this geek-focus was quickly abandoned as Paypal discovered that what people -- real users -- really wanted was money on the web browser. Also, having found a willing userbase in ebay community, its future was more or less guaranteed as long as it avoided the bank/regulatory minefield laid out for it.
As Paypal proved the web became the protocol of choice, even for money, so Chaum's ideas were more or less forgotten in the wider western marketplace, although the tradition was alive in Russia with WebMoney, and there were isolated pockets of interest in the crypto communities. In contrast, several ventures started up chasing a variant of Paypal's web-hybrid: gold on the web. The company that succeeded initially was called e-gold, an American-based operation that had its corporation in Nevis in the Caribbean.
e-gold was a fairly simple idea: you send in your physical gold or 'junk' silver, and they would credit e-gold to your account. Or you could buy new e-gold, by sending a wire to Florida, and they would buy and hold the physical gold. By tramping the streets and winning customers over, the founder managed to get the company into the black and up and growing by around 1999. As e-gold the currency issuer was offshore, it did not require US onshore approval, and this enabled it for a time to target the huge American market of 'goldbugs' and also a growing worldwide community of Internet traders who needed to do cross-border payments. With its popularity on the increase, the independent exchange market exploded into life in 2000, and its future seemed set.
e-gold however ran into trouble for its libertarian ideal of allowing anyone to have an account. While in theory this is a fine concept, the steady stream of ponzis, HYIPs, 'games' and other scams attracted the attention of the Feds. In 2005, e-gold's Florida offices were raided and that was the end of the currency as an effective force. The Feds also proceeded to mop up any of the competitors and exchange operations they could lay their hands on, ensuring the end of the second great wave of new monies.
In retrospect, 9/11 marked a huge shift in focus. Beforehand, the USA was fairly liberal about alternative monies, seeing them as potential business, innovation for the future. After 9/11 the view switched dramatically, albeit slowly; all cryptocurrencies were assumed to be hotbeds of terrorists and drugs dealers, and therefore valid targets for total control. It's probably fair to speculate that e-gold didn't react so well to the shift. Meanwhile, over in Europe, they were going the other way. It had become abundantly clear that the attempt to shutdown cryptocurrencies was too successful, Internet business preferred to base itself in the USA, and there had never been any evidence of the bad things they were scared of. Successive generations of the eMoney law were enacted to open up the field, but being Europeans they never really understood what a startup was, and the less-high barriers remained deal killers.
Which brings us forward to 2008, and the first public posting of the Bitcoin paper by Satoshi Nakamoto.
What's all this worth? The best way I can make this point is an appeal to authority:
Satoshi Nakamoto wrote, on releasing the code: > You know, I think there were a lot more people interested in the 90's, > but after more than a decade of failed Trusted Third Party based systems > (Digicash, etc), they see it as a lost cause. I hope they can make the > distinction that this is the first time I know of that we're trying a > non-trust-based system.
Bitcoin is a result of history; when decisions were made, they rebounded along time and into the design. Nakamoto may have been the mother of Bitcoin, but it is a child of many fathers: David Chaum's blinded coins and the fateful compromise with DNB, e-gold's anonymous accounts and the post-9/11 realpolitik, the cypherpunks and their libertarian ideals, the banks and their industrial control policies, these were the whole cloth out of which Nakamoto cut the invention.
And, finally it must be stressed, most all successes and missteps we see here in the growing Bitcoin sector have been seen before. History is not just humming and rhyming, it's singing loudly.
April 06, 2014
The evil of cryptographic choice (2) -- how your Ps and Qs were mined by the NSA
One of the excuses touted for the Dual_EC debacle was that the magical P & Q numbers that were chosen by secret process were supposed to be defaults. Anyone was at liberty to change them.

Epic fail! It turns out that this might have been just that, a liberty, a hope, a dream. From last week's paper on attacking Dual_EC:
"We implemented each of the attacks against TLS libraries described above to validate that they work as described. Since we do not know the relationship between the NIST- specified points P and Q, we generated our own point Q′ by first generating a random value e ←R {0,1,...,n−1} where n is the order of P, and set Q′ = eP. This gives our trapdoor value d ≡ e−1 (mod n) such that dQ′ = P. (Our random e and its corresponding d are given in the Appendix.) We then modified each of the libraries to use our point Q′ and captured network traces using the libraries. We ran our attacks against these traces to simulate a passive network attacker.
In the new paper that measures how hard it was to crack open TLS when corrupted by Dual_EC, the authors changed the Qs to match the P delivered, so as to attack the code. Each of the four libraries they had was in binary form, and it appears that each had to be hard-modified in binary in order to mind their own Ps and Qs.
So did (a) the library implementors forget that issue? or (b) NIST/FIPS in its approval process fail to stress the need for users to mind their Ps and Qs? or (c) the NSA knew all along that this would be a fixed quantity in every library, derived from the standard, which was pre-derived from their exhaustive internal search for a special friendly pair? In other words:
"We would like to stress that anybody who knows the back door for the NIST-specified points can run the same attack on the fielded BSAFE and SChannel implementations without reverse engineering.
Defaults, options, choice of any form has always been known as bad for users, great for attackers and a downright nuisance for developers. Here, the libraries did the right thing by eliminating the chance for users to change those numbers. Unfortunately, they, NIST and all points thereafter, took the originals without question. Doh!
April 01, 2014
The IETF's Security Area post-NSA - what is the systemic problem?
In the light of yesterday's newly revealed attack by the NSA on Internet standards, what are the systemic problems here, if any?
I think we can question the way the IETF is approaching security. It has taken a lot of thinking on my part to identify the flaw(s), and not a few rants, with many and aggressive defences and counterattacks from defenders of the faith. Where I am thinking today is this:
First the good news. The IETF's Working Group concept is far better at developing general standards than anything we've seen so far (by this I mean ISO, national committees, industry cartels and whathaveyou). However, it still suffers from two shortfalls.
1. the Working Group system is more or less easily captured by the players with the largest budget. If one views standards as the property of the largest players, then this is not a problem. If OTOH one views the Internet as a shared resource of billions, designed to serve those billions back for their efforts, the WG method is a recipe for disenfranchisement. Perhaps apropos, spotted on the TLS list by Peter Gutmann:
Documenting use cases is an unnecessary distraction from doing actual work. You'll note that our charter does not say "enumerate applications that want to use TLS".
I think reasonable people can debate and disagree on the question of whether the WG model disenfranchises the users, because even though a a company can out-manouver the open Internet through sheer persistence and money, we can still see it happen. In this, IETF stands in violent sunlight compared to that travesty of mouldy dark closets, CABForum, which shut users out while industry insiders prepared the base documents in secrecy.
I'll take the IETF any day, except when...
2. the Working Group system is less able to defend itself from a byzantine attack. By this I mean the security concept of an attack from someone who doesn't follow the rules, and breaks them in ways meant to break your model and assumptions. We can suspect byzantium disclosures in the fingered ID:
The United States Department of Defense has requested a TLS mode which allows the use of longer public randomness values for use with high security level cipher suites like those specified in Suite B [I-D.rescorla-tls-suiteb]. The rationale for this as stated by DoD is that the public randomness for each side should be at least twice as long as the security level for cryptographic parity, which makes the 224 bits of randomness provided by the current TLS random values insufficient.
Assuming the story as told so far, the US DoD should have added "and our friends at the NSA asked us to do this so they could crack your infected TLS wide open in real time."
Such byzantine behaviour maybe isn't a problem when the industry players are for example subject to open observation, as best behaviour can be forced, and honesty at some level is necessary for long term reputation. But it likely is a problem where the attacker is accustomed to that other world: lies, deception, fraud, extortion or any of a number of other tricks which are the tools of trade of the spies.
Which points directly at the NSA. Spooks being spooks, every spy novel you've ever read will attest to the deception and rule breaking. So where is this a problem? Well, only in the one area where they are interested in: security.
Which is irony itself as security is the field where byzantine behaviour is our meat and drink. Would the Working Group concept past muster in an IETF security WG? Whether it does or no depends on whether you think it can defend against the byzantine attack. Likely it will pass-by-fiat because of the loyalty of those involved, I have been one of those WG stalwarts for a period, so I do see the dilemma. But in the cold hard light of sunlight, who is comfortable supporting a WG that is assisted by NSA employees who will apply all available SIGINT and HUMINT capabilities?
Can we agree or disagree on this? Is there room for reasonable debate amongst peers? I refer you now to these words:

On September 5, 2013, the New York Times [18], the Guardian [2] and ProPublica [12] reported the existence of a secret National Security Agency SIGINT Enabling Project with the mission to actively [engage] the US and foreign IT industries to covertly influence and/or overtly leverage their commercial products designs. The revealed source documents describe a US $250 million/year program designed to make [systems] exploitable through SIGINT collection by inserting vulnerabilities, collecting target network data, and influencing policies, standards and specifications for commercial public key technologies. Named targets include protocols for TLS/SSL, https (e.g. webmail), SSH, encrypted chat, VPNs and encrypted VOIP.
The documents also make specific reference to a set of pseudorandom number generator (PRNG) algorithms adopted as part of the National Institute of Standards and Technology (NIST) Special Publication 800-90 [17] in 2006, and also standardized as part of ISO 18031 [11]. These standards include an algorithm called the Dual Elliptic Curve Deterministic Random Bit Generator (Dual EC). As a result of these revelations, NIST reopened the public comment period for SP 800-90.
And as previously written here. The NSA has conducted a long term programme to breach the standards-based crypto of the net.
As evidence of this claim, we now have *two attacks*, being clear attempts to trash the security of TLS and freinds, and we have their own admission of intent to breach. In their own words. There is no shortage of circumstantial evidence that NSA people have pushed, steered, nudged the WGs to make bad decisions.
I therefore suggest we have the evidence to take to a jury. Obviously we won't be allowed to do that, so we have to do the next best thing: use our collective wisdom and make the call in the public court of Internet opinion.
My vote is -- guilty.
One single piece of evidence wasn't enough. Two was enough to believe, but alternate explanations sounded plausible to some. But we now have three solid bodies of evidence. Redundancy. Triangulation. Conclusion. Guilty.
Where it leaves us is in difficulties. We can try and avoid all this stuff by e.g., avoiding American crypto, but it is a bit broader that that. Yes, they attacked and broke some elements of American crypto (and you know what I'm expecting to fall next.). But they also broke the standards process, and that had even more effect on the world.
It has to be said that the IETF security area is now under a cloud. Not only do they need to analyse things back in time to see where it went wrong, but they also need some concept to stop it happening in the future.
The first step however is to actually see the clouds, and admit that rain might be coming soon. May the security AD live in interesting times, borrow my umbrella?
March 31, 2014
NSA caught again -- deliberate weakening of TLS revealed!?
In a scandal that is now entertaining that legal term of art "slam-dunk" there is news of a new weakness introduced into the TLS suite by the NSA:
We also discovered evidence of the implementation in the RSA BSAFE products of a non-standard TLS extension called "Extended Random." This extension, co-written at the request of the National Security Agency, allows a client to request longer TLS random nonces from the server, a feature that, if it enabled, would speed up the Dual EC attack by a factor of up to 65,000. In addition, the use of this extension allows for for attacks on Dual EC instances configured with P-384 and P-521 elliptic curves, something that is not apparently possible in standard TLS.
This extension to TLS was introduced 3 distinct times through an open IETF Internet Draft process, twice by an NSA employee and a well known TLS specialist, and once by another. The way the extension works is that it increases the quantity of random numbers fed into the cleartext negotiation phase of the protocol. If the attacker has a heads up to those random numbers, that makes his task of divining the state of the PRNG a lot easier. Indeed, the extension definition states more or less that:
4.1. Threats to TLS
When this extension is in use it increases the amount of data that an attacker can inject into the PRF. This potentially would allow an attacker who had partially compromised the PRF greater scope for influencing the output.
The use of Dual_EC, the previously fingered dodgy standard, makes this possible. Which gives us 2 compromises of the standards process that when combined magically work together.
Our analysis strongly suggests that, from an attacker's perspective, backdooring a PRNG should be combined not merely with influencing implementations to use the PRNG but also with influencing other details that secretly improve the exploitability of the PRNG.
Red faces all round.
February 10, 2014
Bitcoin Verification Latency -- MtGox hit by market timing attack, squeezed between the water of impatience and the rock of transactional atomicity
Fresh on the heels of our release of "Bitcoin Verification Latency -- The Achilles Heel for Time Sensitive Transactions" it seems that Mt.Gox has been hit by exactly that - a market timing attack based on latency. In their own words:
Non-technical Explanation:A bug in the bitcoin software makes it possible for someone to use the Bitcoin network to alter transaction details to make it seem like a sending of bitcoins to a bitcoin wallet did not occur when in fact it did occur. Since the transaction appears as if it has not proceeded correctly, the bitcoins may be resent. MtGox is working with the Bitcoin core development team and others to mitigate this issue.
Technical Explanation:
Bitcoin transactions are subject to a design issue that has been largely ignored, while known to at least a part of the Bitcoin core developers and mentioned on the BitcoinTalk forums. This defect, known as "transaction malleability" makes it possible for a third party to alter the hash of any freshly issued transaction without invalidating the signature, hence resulting in a similar transaction under a different hash. Of course only one of the two transactions can be validated. However, if the party who altered the transaction is fast enough, for example with a direct connection to different mining pools, or has even a small amount of mining power, it can easily cause the transaction hash alteration to be committed to the blockchain.
The bitcoin api "sendtoaddress" broadly used to send bitcoins to a given bitcoin address will return a transaction hash as a way to track the transaction's insertion in the blockchain.
Most wallet and exchange services will keep a record of this said hash in order to be able to respond to users should they inquire about their transaction. It is likely that these services will assume the transaction was not sent if it doesn't appear in the blockchain with the original hash and have currently no means to recognize the alternative transactions as theirs in an efficient way.This means that an individual could request bitcoins from an exchange or wallet service, alter the resulting transaction's hash before inclusion in the blockchain, then contact the issuing service while claiming the transaction did not proceed. If the alteration fails, the user can simply send the bitcoins back and try again until successful.
Which all means what? Well, it seems that while waiting on a transaction to pop out of the block chain, one can rely on a token to track it. And so can ones counterparty. Except, this token was not exactly constructed on a security basis, and the initiator of the transaction can break it, leading to two naive views of the transaction. Which leads to some game-playing.
Let's be very clear here. There are three components to this break: Latency, impatience, and a bad token. Latency is the underlying physical problem, also known as the coordination problem or the two-generals problem. At a deeper level, as latency on a network is a physical certainty limited by the speed of light, there is always an open window of opportunity for trouble when two parties are trying to agree on anything.
In fast payment systems, that window isn't a problem for humans (as opposed to algos), as good payment systems clear in less than a second, sometimes known as real time. But not so in Bitcoin; where the latency is from 5 minutes and up to 120 depending on your assumptions, which leaves an unacceptable gap between the completion of the transaction and the users' expectations. Hence the second component: impatience.
The 'solution' to the settlement-impatience problem then is the hash token that substitutes as a final (triple entry) evidentiary receipt until the block-chain settles. This hash or token used in Bitcoin is broken, in that it is not cryptographically reliable as a token identifying the eventual settled payment.
Obviously, the immediate solution is to fix the hash, which is what Mt.Gox is asking Bitcoin dev team to do. But this assumes that the solution is in fact a solution. It is not. It's a hack, and a dangerous one. Let's go back to the definition of payments, again assuming the latency of coordination.
A payment is initiated by the controller of an account. That payment is like a cheque (or check) that is sent out. It is then intermediated by the system. Which produces the transaction.
But as we all know with cheques, a controller can produce multiple cheques. So a cheque is more like a promise that can be broken. And as we all know with people, relying on the cheque alone isn't reliable enough by and of itself, so the system must resolve the abuses. That fundamental understanding in place, here's what Bitcoin Foundation's Gavin Andresen said about Mt.Gox:
The issues that Mt. Gox has been experiencing are due to an unfortunate interaction between Mt. Goxs implementation of their highly customized wallet software, their customer support procedures, and their unpreparedness for transaction malleability, a technical detail that allows changes to the way transactions are identified.Transaction malleability has been known about since 2011. In simplest of terms, it is a small window where transaction IDs can be renamed before being confirmed in the blockchain. This is something that cannot be corrected overnight. Therefore, any company dealing with Bitcoin transactions and have coded their own wallet software should responsibly prepare for this possibility and include in their software a way to validate transaction IDs. Otherwise, it can result in Bitcoin loss and headache for everyone involved.
Ah. Oops. So it is a known problem. So one could make a case that Mt.Gox should have dealt with it, as a known bug.
But note the language above... Transaction malleability? That is a contradiction in terms. A transaction isn't malleable, the very definition of a transaction is that it is atomic, it is or it isn't. ACID for those who recall the CS classes: Atomic, consistent, independent, durable.
Very simply put, that which is put into the beginning of the block chain calculation cycle /is not a transaction/ whereas that which comes out, is, assuming a handwavy number of 10m cycles such as 6. Therefore, the identifier to which they speak cannot be a transaction identifier, by definition. It must be an identifier to ... something else!
What's happening here then is more likely a case of cognitive dissonance, leading to a regrettable and unintended deception. Read Mt.Gox's description above, again, and the reliance on the word becomes clearer. Users have known to demand transactions because we techies taught them that transactions are reliable, by definition; Bitcoin provides the word but not the act.
So the first part of the fix is to change the words back to ones with reliable meanings. You can't simply undefine a term that has been known for 40 years, and expect the user community to follow.
(To be clear, I'm not suggesting what the terms should be. In my work, I simply call what goes in a 'Payment', and what comes out a 'Receipt'. The latter Receipt is equated to the transaction, and in my lesson on triple entry, I often end with a flourish: The Receipt is the Transaction. Which has more poetry if you've experienced transactional pain before, and you've read the whole thing. We all have our dreams :)
We are still leaves the impatience problem.
Note that this will also affect any other crypto-currency using the same transaction scheme as Bitcoin.Conclusion
To put things in perspective, it's important to remember that Bitcoin is a very new technology and still very much in its early stages. What MtGox and the Bitcoin community have experienced in the past year has been an incredible and exciting challenge, and there is still much to do to further improve.
When we did our early work in this, we recognised that the market timing attack comes from the implicit misunderstanding of how latency interferes with transactions, and how impatience interferes with both of them. So in our protocols, there is no 'token' that is available to track a pending transaction. This was a deliberate, early design decision, and indeed the servers still just dump and ignore anything they don't understand in order to force the clients away from leaning on unreliable crutches.
It's also the flip side of the triple-entry receipt -- its existence is the full evidence, hence, the receipt is the transaction. Once you have the receipt, you're golden, if not, you're in the mud.
But Bitcoin had a rather extraordinary problem -- the distribution of its consensus on the transaction amongst any large group of nodes that wanted to play. Which inherently made transactional mechanics and latency issues blow out. This is a high price to pay, and only history is going to tell us whether the price is too high or affordable.
January 30, 2014
Hard Truths about the Hard Business of finding Hard Random Numbers
Editorial note: this rant was originally posted here but has now moved to a permanent home where it will be updated with new thoughts.
As many have noticed, there is now a permathread (Paul's term) on how to do random numbers. It's always been warm. Now the arguments are on solid simmer, raging on half a dozen cryptogroups, all thanks to the NSA and their infamous breach of NIST, American industry, mom's apple pie and the privacy of all things from Sunday school to Angry Birds.
Why is the topic of random numbers so bubbling, effervescent, unsatisfying? In short, because generators of same (RNGs), are *hard*. They are in practical experience trickier than most of the other modules we deal with: ciphers, HMACs, public key, protocols, etc.
Yet, we have come a long way. We now have a working theory. When Ada put together her RNG this last summer, it wasn't that hard. Out of our experience, herein is a collection of things we figured out; with the normal caveat that, even as RNs require stirring, the recipe for 'knowing' is also evolving.
- Use what your platform provides. Random numbers are hard, which is the first thing you have to remember, and always come back to. Random numbers are so hard, that you have to care a lot before you get involved. A hell of a lot. Which leads us to the following rules of thumb for RNG production.
- Use what your platform provides.
- Unless you really really care a lot, in which case, you have to write your own RNG.
- There isn't a lot of middle ground.
- So much so that for almost all purposes, and almost all users, Rule #1 is this: Use what your platform provides.
- When deciding to breach Rule #1, you need a compelling argument that your RNG delivers better results than the platform's. Without that compelling argument, your results are likely to be more random than the platform's system in every sense except the quality of the numbers.
- Software is our domain.
- Software is unreliable. It can be made reliable under bench conditions, but out in the field, any software of more than 1 component (always) has opportunities for failure. In practice, we're usually talking dozens or hundreds, so failure of another component is a solid possibility; a real threat.
- What about hardware RNGs? Eventually they have to go through some software, to be of any use. Although there are some narrow environments where there might be a pure hardware delivery, this is so exotic, and so alien to the reader here, that there is no point in considering it. Hardware serves software. Get used to it.
- As a practical reliability approach, we typically model every component as failing, and try and organise our design to carry on.
- Security is also our domain, which is to say we have real live attackers.
- Many of the sciences rest on a statistical model, which they can do in absence of any attackers. According to Bernoulli's law of big numbers, models of data will even out over time and quantity. In essence, we then can use statistics to derive strong predictions. If random numbers followed the law of big numbers, then measuring 1000 of them would tell us with near certainty that the machine was good for another 1000.
- In security, we live in a byzantine world, which means we have real live attackers who will turn our assumptions upside down, out of spite. When an attacker is trying to aggressively futz with your business, he will also futz with any assumptions and with any tests or protections you have that are based on those assumptions. Once attackers start getting their claws and bits in there, the assumption behind Bernoulli's law falls apart. In essence this rules out lazy reliance on statistics.
- No Test. There is no objective test of random numbers, because it is impossible to test for unpredictability. Which in practical terms means that you cannot easily write a test for it, nor can any test you write do the job you want it to do. This is the key unfortunate truth that separates RNs out from ciphers, etc (which latter are amenable to test vectors, and with vectors in hand, they become tractable).
- Entropy. Everyone talks about entropy so we must too, else your future RNG will exhibit the wrong sort of unpredictability. Sadly, entropy is not precisely the answer, enough such that talking about is likely missing the point. If we could collect it reliably, RNs would be easy. We can't so it isn't.
- Entropy is manifest physical energy, causing events which cannot be predicted using any known physical processes, by the laws of science. Here, we're typically talking about quantum energy, such as the unknown state of electrons, which can collapse either way into some measurable state, but it can only be known by measurement, and not predicted earlier. It's worth noting that quantum energy abounds inside chips and computers, but chips are designed to reduce the noise, not increase it, so turning chip entropy into RNs is not as easy as talking about it.
- There are objective statements we can make about entropy. The objective way to approach the collection of entropy is to carefully analyse the properties of the system and apply science to estimate the amount of (e.g.) quantum uncertainty one can derive from it. This is possible and instructive, and for a nice (deep) example of this, see John Denker's Turbid.
- At the level of implementation, objective statements about entropy fail for 2 reasons. Let's look at those, as understanding these limitations on objectivity is key to understanding why entropy does not serve us so willingly.
- Entropy can be objectively analysed as long as we do not have an attacker. An attacker can deliver a faulty device, can change the device, and can change the way the software deals with the device at the device driver level. And much more...
- This approach is complete if we have control of our environment. Of course, it is very easy to say Buy the XYZ RNG and plug it in. But many environments do not have that capability, often enough we don't know our environment, and the environment can break or be changed. Examples: rack servers lacking sound cards; phones; VMs; routers/firewalls; early startup on embedded hardware.
- In conclusion, entropy is too high a target to reach. We can reach it briefly, in controlled environments, but not enough to make it work for us. Not enough, given our limitations.
- CSRNs. The practical standard to reach therefore is what we call Cryptographically Secure Random Numbers.
- Cryptographically secure random numbers (or CSRNs) are numbers that are not predictable /to an attacker/. In contrast to entropy, we might be able to predict our CSRNs, but our enemies cannot. This is a strictly broader and easier definition than entropy, which is needed because collecting entropy is too hard, as above.
- Note our one big assumption here: that we can determine who is our attacker and keep him out, and determine who is friendly and let them in. This is a big flaw! But it happens to be a very basic and ever-present one in security, so while it exists, it is one we can readily work with.
- Design. Many experiments and research seem to have settled on the following design pattern, which we call a Trident Design Pattern:
Entropy collector ----\
In short, many collectors of entropy feed their small contributions in to a Mixer, which uses the melded result to seed an Expander. The high level caller (application) uses this Expander to request her random numbers.
\ _____ _________ / \ / \
Entropy collector ---->( mixer )----->( expansion )-----> RNs
\_____/ \_________/
/
Entropy collector ----/ - Collectors. After all the above bad news, what is left in the software toolkit is: redundancy .
- A redundant approach tells us to draw our RNs from different places. The component that collects RNs from one place is called a Collector. Therefore we want many Collectors.
- Each of the many places should be uncorrelated with each other. If one of these were to fail, it would be unlikely that others also would fail, as they are uncorrelated. Typical studies of fault-tolerant systems often suggest the number 3 as the target.
-
 Some common collector ideas are:
Some common collector ideas are:- the platform's own RNG, as a Collector into your RNG
- any CPU RNG such as Intel's RDRAND,
- measuring the difference between two uncorrelated clocks,
- timings and other measurands from events (e.g., mouse clicks and locations),
- available sensors (movement on phones),
- differences seen in incoming new business packets,
- a roughly protected external source such as a business feed,
- An attacker is assumed to be able to take a poke at one or two of these sources, but not all. If the attacker can futz with all our sources, this implies that he has more or less unlimited control over our entire machine. In which case, it's his machine, and not ours. We have bigger problems than RNs.
- We tend to want more numbers than fault-tolerant reliability suggests because we want to make it harder for the attacker. E.g., 6 would be a good target.
- Remember, we want maximum uncorrelation. Adding correlated collectors doesn't improve the numbers.
- Because we have redundancy, on a large scale, we are not that fussed about the quality of each Collector. Better to add another collector than improve the quality of one of them by 10%. This is an important benefit of redundancy, we don't have to be paranoid about the quality of this code.
- Mixer. Because we want the best and simplest result delivered to the caller, we have to take the output of all those above Collectors, mix them together, and deliver downstream.
- The Mixer is the trickiest part of it all. Here, you make or break. Here, you need to be paranoid. Careful. Seek more review.
- The Mixer has to provide some seed numbers of say 128-512 bits to the Expander (see below for rationale). It has to provide this on demand, quickly, without waiting around.
- There appear to be two favourite designs here: Push or Pull. In Push the collectors send their data directly into Mixer, forcing it to mix it in as it's pushed in. In contrast, a Pull design will have the Mixer asking the Collectors to provide what they have right now. This in short suggests that in a Push design the Mixer has to have a cache, while in Pull mode, the Collectors might be well served in having caches within themselves.
- Push or Mixer-Cache designs are probably more popular. See Yarrow and Fortuna as perhaps the best documented efforts.
- We wrote our recent Trident effort (AdazPRING) using Pull. The benefits include: simplified API as it is direct pull all the way through; no cache or thread in mixer; and as the Collectors better understand their own flow, so they better understand the need for caching and threading.
- Expander. Out of the Mixer comes some nice RNs, but not a lot. That's because good collectors are typically not firehoses but rather dribbles, and the Mixer can't improve on that, as, according to the law of thermodynamics, it is impossible to create entropy.
- The caller often wants a lot of RNs and doesn't want to wait around.
- To solve the mismatch between the Mixer output and the caller's needs, we create an expansion function or Expander. This function is pretty simple: (a) it takes a small seed and (b) turns that into a hugely long stream. It could be called the Firehose...
- Recalling our truth above of (c) CSRNs being the goal, not entropy, we now have a really easy solution to this problem: Use a cryptographic stream cipher. This black box takes a small seed (a-check!) and provides a near-infinite series of bytes (b-check!) that are cryptographically secure (c-check!). We don't care about the plaintext, but by the security claims behind the cipher, the stream is cryptographically unpredictable without access to the seed.
- Super easy: Any decent, modern, highly secure stream cipher is probably good for this application. Our current favourite is ChaCha20 but any of the NESSIE set would be fine.
- In summary, the Expander is simply this: when the application asks for a PRNG, we ask the Mixer for a seed, initialise a stream cipher with the seed, and return it back to the user. The caller sucks on the output of the stream cipher until she's had her fill!
- Subtleties.
- When a system first starts up there is often a shortage of easy entropy to collect. This can lead to catastrophic results if your app decides that it needs to generate high-value keys as soon as it starts up. This is a real problem -- scans of keys on the net have found significant numbers that are the same, which is generally traced to the restart problem. To solve this, either change the app (hard) ... or store some entropy for next time. How you do this is beyond scope.
- Then, assuming the above, the problem is that your attacker can do a halt, read off your RNG's state in some fashion, and then use it for nefarious purposes. This is especially a problem with VMs. We therefore set the goal that the current state of the RNG cannot be rolled forward nor backwards to predict prior or future uses. To deal with this, a good RNG will typically:
- stir fresh entropy into its cache(s) even if not required by the callers. This can be done (e.g.) by feeding ones own Expander's output in, or by setting a timer to poll the Collectors.
- Use hash whiteners between elements. Typically, a SHA digest or similar will be used to protect the state of a caching element as it passes its input to the next stage.
- As a technical design argument, the only objective way that you can show that your design is at least as good as or better than the platform-provided RNG is the following:
- Very careful review and testing of the software and design, and especially the Mixer; and
- including the platform's RNG as a Collector.
- Business Justifications.
As you can see, doing RNGs is hard! Rule #1 -- use what the platform provides. You shouldn't be doing this. About the only rationales for doing your own RNG are the following.
- Your application has something to do with money or journalism or anti-government protest or is a CVP. By money, we mean Bitcoin or other forms of hard digital cash, not online banking. The most common CVP or centralised vulnerability party (aka TTP or trusted third party) is the Certification Authority.
- Your operating platform is likely to be attacked by a persistent and aggressive attacker. This might be true if the platform is one of the following: any big American or government controlled software, Microsoft Windows, Java (code, not applets), any mobile phone OS, COTS routers/firewalls, virtual machines (VMs).
- You write your own application software, your own libraries *and* your own crypto!
- You can show objectively that you can do a better job.
That all said, good luck! Comments to the normal place, please, and Ed's note: this will improve in time.
January 19, 2014
The Shamir-Grigg-Gutmann challenge -- DJB's counterexamples
Last month, I wrote to explain that these challenges by Dan Bernstein:
2011 Grigg-Gutmann: In the past 15 years "no one ever lost money to an attack on a properly designed cryptosystem (meaning one that didn't use homebrew crypto or toy keys) in the Internet or commercial worlds".2002 Shamir: "Cryptography is usually bypassed. I am not aware of any major world-class security system employing cryptography in which the hackers penetrated the system by actually going through the cryptanalysis."
could be simply reduced to:
"Show us the money!"
Perhaps uniquely, Dan Bernstein took umbrage and went looking for the money. He found two potentials. Out of order, let's look at potential "in the money" option #2: WEP.
WEP
WEP introduced in 1997 in 802.11 wireless standard.
2001 Borisov-Goldberg-Wagner:
24-bit "nonce" frequently repeats, leaking plaintext xor and allowing very easy forgeries.
2001 Arbaugh-Shankar-Wan:
this also breaks user auth.
2001 Fluhrer-Mantin-Shamir:
WEP builds RC4 key (k; n) from secret k, "nonce" n; RC4 outputs leak bytes of k.
Implementations, optimizations of k-recovery attack: 2001 Stubblefield-Ioannidis-Rubin, 2004 KoreK, 2004 Devine, 2005 d'Otreppe, 2006 Klein, 2007 Tews-Weinmann-Pyshkin, 2010 Sepehrdad-Vaudenay-Vuagnoux, 2013 S-Suˇsil-V-V, . . .
The interesting thing about WEP is that we've always known that it was a joke, as far as security goes, and Dan agrees, labelling it as scary. What was then somewhat amazing is that although we see worldwide deployment of WEP, WAP, WPA, WaBlaBla and yet more, and that, we all know that the entire family is weak, why wasn't any money lost on it?
"These are academic papers!
Nobody was actually attacked."Fact: WEP blamed for 2007 theft of 45 million credit-card numbers from T. J. Maxx. Subsequent lawsuit settled for $40900000.
Until 2007 that is. Taking what it is written in the article as the facts, WEP was cracked and T. J. Maxx was raided for millions of cards. Within 6 months they agreed to settle for the damages.
But, the challenge survives! WEP is ruled out of scope, because it is not a properly designed cryptosystem (Grigg-Gutmann), nor a world-class security system (Shamir). At least, no serious security person recommends it for other than stopping your teenage neighbours stealing the bandwidth with 24/7 youtube. One can ask: why did T. J. Maxx ignore the warnings and assume that WEP was secure enough to protect their credit card database? Their bad, not for us to follow their leadership into losses.
On to Dan's option #1, Flame:
Windows code signatures Flame broke into computers, spied on audio, keystrokes, etc.
2012.06.03 Microsoft:
"We recently became aware of a complex piece of targeted malware known as 'Flame' and immediately began examining the issue. . . . We have discovered through our analysis that some components of the malware have been signed by certificates that allow software to appear as if it was produced by Microsoft."
Flame is an intelligence gathering virus that was launched as part of Operation Olympic Games (NSA, CIA, Mossad) against the Iranian nuclear programme. It was facilitated by being a code-signed virus, and to do this, the attackers crunched a Microsoft code-signing certificate to acquire a forged private key. In this case, the attack was done on MD5-signed certs. Once the private key was forged by the attackers, it was game on! Sign Havoc! and let slip the dogs of cyberwar.
Flame is definitely an attack on a cryptosystem, but we have two difficulties before we can hand out the prize.
Firstly, nobody recommends MD5! It has in effect been deprecated since 1996, when SHA1 came on line. And that's well before the 2004 warnings from the Chinese cryptographers, so the message was loud and clear then.
But, wait! the CA world has been consistently saying that their product was world-class. Because the PKI/CA/browser world is so convinced that they know what they are doing, maybe we have to accept that MD5-signed certificates are a strong system, and it was OK for Microsoft to be signing with it in 2012? Even though nobody much recommends x509 PKI for serious stuff, committees, standards, regulators and auditors, all opine faithfully on the ability of PKI to serve and protect.
We could take the PKI viewpoint seriously, and assume a world in which signed certificates are indeed major world-class and/or properly designed cryptographic tools. Browsers ship strong security based on MD5, and everyone says that's strong, and please don't bother us because we're too busy increasing RSA length to 2048, and phishing wasn't in our mandate so stop mentioning the $100m or so per year damages there! Dammit...
Sorry, no, it doesn't wash, and I don't have the space or patience to write about planetary cognitive dissonance today. If we give MD5 and certificates and PKI a pass, it is begrudging, fingers-crossed, marketing waffle compliance claim, and no serious security person should be fooled. But we have another difficulty:
*Flame shows no damages*. There is no easy way to tie any loss into the affects that Flame wrought, other than the normal bluster and FUD and journalistic froth and so forth. We don't even know if Flame exflitrated anything, all we've got is claim and counterclaim. As I wrote in the last post:
"Unreported losses don't exist. The reason for this is simple: risk analysis is based on what we know. What we don't know is not a good basis for assessing risks. In the crypto business, we refer to this as FUD, security theatre, snake oil, bogeymen, bla bla, movie plots, perverted & interested parties, etc. If we rely on a claim that we cannot show then we are lost, totally. If we work on a hypothetical, we're not doing risk analysis, we're not doing science, and we've no integrity."
Flame's not in the money. Then, no pass. Are we sunk? Not quite. Flame goes down, yet Stuxnet stalks forth. Damages! Over on CAcert it is written (by me):
Consequences: Various estimates suggested that Stuxnet succeeded in knocking out and perhaps destroying some 1000 centrifuges, estimated at 10% of Iran's centrifuge capacity (ISIS) and delaying Iran's weapon building program by 1.5-2 years (NYT20120601.2, Langner).
That's a hefty piece of change. Stuxnet stole its certs, it didn't crunch them. But it could have ... and Flame and Stuxnet both came from the same people, for the same purpose. It is hypothesized that Flame exfiltrated the data and Stuxnet zeroed in on the target with Flame's intel product. OlympicGames is a hypothesis of causal connection, and combined, we have a result that seriously challenges our claims.
We can argue about the detailed check-marks of success here, but I for one would say that our claims can now be rendered more accurate as historical. One detail remains -- when?
Gutmann and I made our outrageous pronouncement above in the May/June 2011 issue of IEEE Security&Privacy, and Shamir, much earlier, 2002 at the Turing awards.
Stuxnet was first noticed in second half of 2010, and Flame was found at the end of May 2012. George "cyberWarrior" Bush launched the digital Pearl Harbour against Iraq much earlier (earliest I have seen is 2007) but it wasn't until early 2011 that we were able to assemble the picture into what it was: a full declaration of cyberwar.
Looking wider, at the overall history of breaches on the net, there is a notable spike of *other activity* including CA breaches in 2011. Therefore, my current view is something like this:
2013 Grigg-Gutmann-bis: Until 2011, we had no recorded history of anyone ever losing money to an attack on a properly designed cryptosystem (meaning one that didn't use homebrew crypto or known-insecure crypto) in the Internet or commercial worlds.
While Peter and I were making those remarks, behind the scenes, the Internet was in the process of losing her maidenhood. We can quibble about dates and losses and what marks the first casebook study of a serious crypto-system breach, but the wider point we wanted to make was that, before 2011, we had no compass. Now we do. And, necessarily from this observation, all systems designed without the benefit of where the compass is now pointing should be considered ripe for a re-think.
Now it's serious. Now it's personal. Now you stand to lose money.
(Editorial note: these are my words not theirs.)
December 29, 2013
The Ka-Ping challenge -- so you think you can spot a bug?
It being Christmas and we're all looking for a little fun, David Wagner has posted a challenge that was part of a serious study conducted by Ka-Ping Yee and himself:
Are you up to it? Are you a hacker-hero or a manager-mouse? David writes:
I believe I've managed to faithfully reconstruct the version of Ping's code that contains the deliberately inserted bug. If you would like to try your hand at finding the bug, you can look at it yourself:
http://www.cs.berkeley.edu/~daw/tmp/pvote-backdoored.zip
I'm copying Ping, in case he wants to comment or add to this.
Some grounds rules that I'd request, if you want to try this on your own:
- Please don't post spoilers to the list. If you think you've found a bug, email Ping and David privately (off-list), and I'll be happy to confirm your find, but please don't post it to the list (just in case others want to take a look too).
- To help yourself avoid inadvertently coming across spoilers, please don't look at anything else on the web. Resist the temptation to Google for Pvote, check out the Pvote web site, or check out the links in the code. You should have everything you need in this email. We've made no attempt to conceal the details of the bug, so if you look at other resources on the web, you may come across other stuff that spoils the exercise.
- I hope you'll think of this as something for your own own personal entertainment and edification. We can't provide a controlled environment and we can't fully mimic the circumstances of the review over the Internet.
Here's some additional information that may help you.
We told reviewers that there exists at least one bug, in Navigator.py, in a region that contains 100 lines of code. I've marked the region using comments. So, you are free to focus on only that part of the code (I promise you that we did not deliberately insert any bug anywhere else outside that region). Of course, I'm providing all the code, because you may need to understand how it all interacts. The original Pvote code was written to be as secure and verifiable as we could make it; I'm giving you a modified version that was modified to add a bug after the fact. So, this is not some "obfuscated Python" contest where the entire thing was designed to conceal a malicious backdoor: it was designed to be secure, and we added a backdoor only as an afterthought, as a way to better understand the effectiveness of code review.
To help you conduct your code review, it might help to start by understanding the Pvote design. You can read about the theory, design, and principles behind Pvote in our published papers:
- An early version of Pvote, with many of the main ideas: paper: http://pvote.org/docs/evt2006/index.html Ping's slides: http://pvote.org/docs/evt2006/talk.pdf
- Many improvements to the initial idea, and the final Pvote: paper: http://pvote.org/docs/evt2007/index.html slides: http://pvote.org/docs/evt2007/talk.pdf
The Pvote code probably won't make sense without understanding some aspects of its design and how it is intended to be used, so this background material might be helpful to you.
We also gave reviewers an assurance document, which outlines the "assurance case" (a detailed argument describing why we believe Pvote is secure and fit for purpose and free of bugs). Here's most of it:
http://www.cs.berkeley.edu/~daw/tmp/pvad-excerpts.pdf
Why not all of it? Because I'm lazy. The full assurance document contains the actual, unmodified Pvote code. We wrote the assurance document for the unmodified version of Pvote (without the deliberately inserted bug), and the full assurance document includes the code of the unmodified Pvote. If you were to look at that and compare it to the code I gave you above, you could quickly identify the bug by just doing a diff -- but that would completely defeat the purpose of the exercise. If I had copious free time, I'd modify the assurance document to give you a modified document that matches the modified code -- but I don't have time to do that. So, instead, I've just removed the part of the assurance document that contained the region of the code where we inserted our bug (namely, Navigator.py), and I'm giving you the rest of the assurance document.
In the actual review, we provided reviewers with additional resources that won't be available to you. For instance, we outlined for them the overall design principles of Pvote. We also were available to interactively answer questions, which helped them quickly get up to speed on the code. During the part where we had them review the modified Pvote with a bug inserted, we also answered their questions -- here's what Ping wrote about how we handled that part:
Since insider attacks are a major unaddressed threat in existing systems, we specifically wanted to experiment with this scenario. Therefore, we warned the reviewers to treat us as untrusted adversaries, and that we might not always tell the truth. However, since it was in everyones interest to use our limited time efficiently, we settled on a time-saving convention. We promised to truthfully answer any question about a factual matter that the reviewers could conceivably verify mechanically or by checking an independent source for example, questions about the Python language, about static properties of the code, about its runtime behaviour, and so on.
Of course, since this is something you're doing on your own, you won't get the benefit of interacting with us and having us answer questions for you (to save you time). I realize this does make code review harder. My apologies.
You can assume that someone else has done some runtime testing of the code. We deliberately chose a bug that would survive "Logic & Accuracy Testing" (a common technique in elections, where election officials conduct a test in advance where they cast some ballots, typically chosen so that at least one vote has been cast for each candidate, and then check that the system accurately recorded and tallied those votes). Focus on code review.
-- David
December 21, 2013
Dan Bernstein rises to the Shamir-Grigg-Gutmann challenge: show me the money!
In an invited talk at the March 2013 FSE in Singapore, Dan Bernstein highlighted a challenge expressed in distinct ways:

2011 Grigg-Gutmann: In the past 15 years "no one ever lost money to an attack on a properly designed cryptosystem (meaning one that didn't use homebrew crypto or toy keys) in the Internet or commercial worlds".2002 Shamir: "Cryptography is usually bypassed. I am not aware of any major world-class security system employing cryptography in which the hackers penetrated the system by actually going through the cryptanalysis."
H/t to Twan for pointing this presentation out. DJB then went on to ask about this challenge:
- Do these people mean that it's actually infeasible to break real-world crypto?
- Or do they mean that breaks are feasible but still not worthwhile for the attackers?
- Or are they simply wrong: real-world crypto is breakable; is in fact being broken; is one of many ongoing disaster areas in security?
Fair questions, one supposes! Let's break it down.
Adi Shamir stated that "Cryptography is usually bypassed." From this, we can suggest that the security job in real life is typically done if the economic results of attacking the crypto happens to be less than the economic results of some other attack.
This is the old sage advice about your door locks -- they don't have to be great, they just have to be better than your neighbours' locks.
This assumes several things: that for the particular business of real life, most of us aren't typically aware of who our attacker is, and further, that any attacker is economically motivated. That is, they want to steal money, by one means or another, and they are not motivated necessarily by the more esoteric of threats that us geeks wish we had to take seriously: revenge, espionage, sabotage, massive crunching farms, exploitation of deep bugs, etc.
Further, it assumes that we are all doing risk analysis. So it's about money, in the simplified world of general purpose crypto. Which brings us to the more practical question:
how strong shall a system be?
There are two answers: the cryptographer's answer and the business answer. The former's answer is: infeasible to break.
The latter's answer is more nuanced, and in order to understand that answer we have to get into how business operates.
In the world of business, we do risk analysis. In quick words, this starts from a model of the business, and from business experience we posit a model of threats. Then, we use risk analysis to estimate the likelihood of each threat, by looking at history and expected cost to the attacker, and multiply it by the consequences (a.k.a. monetary damages) to us to get an expected value.
risk = likelihood * consequences
The result is a set of risks, which we can then order by expected damages. We then start working on the highest priorities, being the highest expected damages. And, similar to our lock model, as long as the priorities are mitigated such that the attacker feels it more economic to move elsewhere, we're good.
In even shorter words, we concentrate our defences where we are currently losing money. It is therefore all about money, which is a completely different answer to the cryptographer's answer of infeasible to break.
So, what about the money? Now, as it happens, in the Internet, there is remarkably little reporting of money being stolen by breaching a cryptosystem! Which leaves us with a dilemma. If nobody has ever reported any money, why are we bothering to protect?
Hence the Gutmann-Grigg comment that puts the point: "no one ever lost money..." and we have the answer to the first two questions:
- Do these people mean that it's actually infeasible to break real-world crypto?
NO!- Or do they mean that breaks are feasible but still not worthwhile for the attackers?
YES!
Now we can address the third question. We can probably state with some confidence that someone has lost some money, somewhere, from some attack on a crypto system, but has never reported those losses. So we now must ask what do we do about non-reported losses?
The answer to that is clear: nothing.
Unreported losses don't exist. The reason for this is simple: risk analysis is based on what we know. What we don't know is not a good basis for assessing risks. In the crypto business, we refer to this as FUD, security theatre, snake oil, bogeymen, bla bla, movie plots, perverted & interested parties, etc. If we rely on a claim that we cannot show then we are lost, totally. If we work on a hypothetical, we're not doing risk analysis, we're not doing science, and we've no integrity. Hence, the answer to the third question,
- Or are they simply wrong: real-world crypto is breakable; is in fact being broken; is one of many ongoing disaster areas in security?
"show us the money!"
This is really what the challenge is about. Because if you can't do that, you're doing something other than business. Call it cryptography or call it voodoo, it doesn't really matter, because only business is business, business is about analysing risks, and you can't analyse risks without facts. Chief amongst those facts is how much money is lost.
Which many have tried to do, gamely, and failed (look at the history of SB1386, in which the reported losses were most or all attributed to non-crypto, non-thefts). Dan also:
Let's look at some examples.
Having established what we all meant by those challenges, I'll leave Dan's examples to another post.
ps; this post was written by Iang. Peter and Adi have not actually written a word here, so any errors in interpretation of their position are mine and mine alone.
December 04, 2013
DJB on 'algorithm agility' -- it sucks
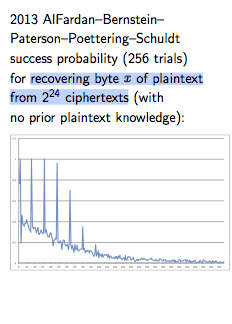
Dan Bernstein discussed various attempts to resolve bugs in ciphersuites in his keynote "Failures of secret-key cryptography" at the March Fast Sofware Encryption event. Then (fast-forwarding to pages 35-38) he says:
Cryptographic algorithm agility:
(1) the pretense that bad crypto is okay if theres a backup plan +
(2) the pretense that there is in fact a backup plan.SSL has a crypto switch that in theory allows switching to AES-GCM.
But most SSL software doesnt support AES-GCM.The software does support one non-CBC option: RC4.
Now widely recommended, used for 50% of SSL traffic.
 after which, DJB then proceeds to roundly trash RC4 as a favoured algorithm... Which is entirely fair, as RC4 has been under a cloud and deprecated since the late 1990s. In the slides, he reportst results from AlFardanBernstein PatersonPoetteringSchuldt that somewhere between 2^24 and 2^32 ciphertexts is what it takes to recover a plaintext byte. Ouch!
after which, DJB then proceeds to roundly trash RC4 as a favoured algorithm... Which is entirely fair, as RC4 has been under a cloud and deprecated since the late 1990s. In the slides, he reportst results from AlFardanBernstein PatersonPoetteringSchuldt that somewhere between 2^24 and 2^32 ciphertexts is what it takes to recover a plaintext byte. Ouch!
This attack on algorithm agility is strongly reminiscent of the One True Cipher Suite, which hypothesis also takes as a foundational assumption that algorithm agility doesn't work. So, abandon algorithm agility if you value your users.
(For further amusement, in slide 2-3, he takes aim at what I and Gutmann pronounced in 2011 and Adi's Shamir's statement that crypto is bypassed, which I'll post on later.)
November 25, 2013
The NSA's golden age of SIGINT: declare war on commercial crypto
 Thanks to Edward Snowden and John Young, we now have further indication that the NSA explicitly and deliberately targets for perversion the open world of cryptography:
Thanks to Edward Snowden and John Young, we now have further indication that the NSA explicitly and deliberately targets for perversion the open world of cryptography:
"SIGINT Goals for 2012-2016...
2.1.2. (S//REL) Counter the challenge of ubiquitous, strong, commercial network encryption
2.1.3. (TS//SI//REL) Counter indigenous cryptographic programs by targeting their industrial bases with all available SIGINT and HUMINT capabilities
2.1.4. (TS//SI//REL) Influence the global commercial encryption market through commercial relationships, HUMINT, and second and third party partners"
It's their mission! Read it how you will, but the hint is pretty strong:
They will undermine, slow, misdirect, block or infect the market to their sole advantage.
There is no limit to their attack, they will apply all available SIGINT and HUMINT capabilities . HUMINT is their terminology for spies & espionage, but we can also presume that black ops, sabotage and cyberwar are on the table. Nor are they shy of using using their captured industrial partners to "influence" the shipping of faulty product.
The attack on NIST was in alignment with these goals, further highlighting that the NSA has no particular qualms in undermining an own-country national champion of standards.
Everyone is a valid target, no limits. This isn't a USA versus the world question, nor an open source versus commercial cryptography skirmish. The questions that remain are these:
- who else do they attack? Who did they infect? Earlier, I mentioned Microsoft's CAPI and Oracle's JCE as standouts. Who else?
- do we care?
- what are we going to do about it?
October 20, 2013
NIST should publish Suite A
We now have a crisis of confidence in the world of cryptography. The Snowden revelations have thrown the deck in the air, and while we have not seen all the cards land as yet, we can draw some points of agreement.
One point of agreement is that public key and Elliptic Curve Cryptography now has a cloud over it. Just as one example, seen on OpenPGP list (archived therefore open for reposting) is discussion about using 1024 bit curves:
On 18/10/13 10:20 AM, Gregory Maxwell wrote:
> Jon Callas <jon at callas.org> wrote:
>> Why ever would you want a 1Kbit curve?
>> Sure, arguably, but please make the argument.
>> As it is, Curve3617 is more than one really needs.
>> I'm genuinely interested.> The fastest method for solving the discrete log problem in finite
> fields is index calculus. It is not known to be applicable to the
> elliptic curves we use for cryptography (or obviously we wouldn't be
> using them), modifications of the technique are applicable to
> super-singular curves / extension fields and where applicable they
> have sub-exponential scaling similar to the number field sieve for
> factoring. While it's not believed that there can exist a
> straightforward adaptation currently-believed strong curves, if one
> were to be discovered it would render any of the common sizes
> practically insecure.> It would be terrible indeed to migrate to ECC only to end up with keys
> no more secure than 512 bit RSA.> But by comparison to performance in other groups a of size to around
> 1024 bits but leave the crypto system secure in practice even if index
> calculus could be directly applied.> (Sorry for delay in responding, but I spent a little while googling
> around to see if I was the only person thinking like this. I found a
> number of things, the most amusing an old post of Bruce Schneier's:
> "Realize, though, that someday -- next year, in ten years, in a
> century -- someone may figure out how to define smoothness, or
> something even more useful, in elliptic curves. If that happens, you
> will have to use the same key lengths as you would with conventional
> discrete logarithm algorithms, and there will be no reason to ever use
> elliptic curves. "
> https://www.schneier.com/crypto-gram-9911.html#EllipticCurvePublic-KeyCryptography )
The point here is not that the above argumentation is valid or otherwise, but that *the suspicion runs deep*. How deep does the EC rabbit hole go?
The best I've seen so far is as found on this site http://safecurves.cr.yp.to/ which seems to say (my reading only) that the prior standards work on curves is suspect, but we can do a good job ourselves if we recalculate to best of ability (us meaning not me).
But we really don't know. As a side pointer as to how far the 'defaults' trap has taken us, yesterday I posted the story of how Android degraded its SSL preferences to an old, deprecated suite from Georg Lukas:
Android is using the combination of horribly broken RC4 and MD5 as the first default cipher on all SSL connections . This impacts all apps that did not care enough to change the list of enabled ciphers (i.e. almost all existing apps). This post investigates why RC4-MD5 is the default cipher, and why it replaced better ciphers which were in use prior to the Android 2.3 release in December 2010.
If you're into Java or Android, and you love the JCE, this will leave a sinking pit in your stomach. A herd of rabbits were stampeded deep down that hole...
I would suggest -- point of agreement? -- that we now have *a crisis of confidence in standards and crypto* .
If I was a standards organisation, or a player who was invested deeply in industry in some sense or other, I'd be also thinking about how to increase confidence.
There is one possibility to increase confidence dramatically:
what's in Suite A?
Consider this as a thought experiment. If we knew what Suite A used for PK work, being the NSA's private cryptography of choice, we would then be able to triangulate. Although this is a claim based on experience rather than evidence, I predict that we'd be able to triangulate the question of ECC and settle the question of confidence. If Suite A algorithms specify ECC, then we would then know that ECC is good in some circumstances. We can further look at their curves and figure out what those circumstances are.
We all win? Treason or revelation? You pick.
This revelation may even be so useful to industry (billion dollar losses?) that it might be a dominating interest over the normal unquestioning patriotic duty of following the say-so of those previously wiser heads in Fort Meade. If American crypto suppliers could show that they were now using techniques that were previously jealously guarded for own-protection, they might actually repair some of their lost reputation.
It might be cost-effective. We would hear the teeth gnashing in Fort Meade from here, but it might even be a 'fair cop'. They can always sit down and build some replacements; and it is not as if American security players have lots of options here.
October 19, 2013
The evil of cryptographic choice -- how defaults destroy the security equation
In the light of NSA disclosures, there is somewhat of a shift towards skepticism of bad decisions. Welcome, but it is also putting light on the dark scary bad decisions that we can't deal with easily. As an example, here is a tale of woe and misfortune from Georg Lukas:
Android is using the combination of horribly broken RC4 and MD5 as the first default cipher on all SSL connections . This impacts all apps that did not care enough to change the list of enabled ciphers (i.e. almost all existing apps). This post investigates why RC4-MD5 is the default cipher, and why it replaced better ciphers which were in use prior to the Android 2.3 release in December 2010.
Georg stresses that this applies to all SSL connections ; following the herd exposes has become a bad life-style choice. For my part, I highlight that he is talking specifically about the default!
So, where did this default of evil come from? Georg dug deeper and found:
The commit message tells us: We now have a default cipher suite list that is chose to match RI behavior and priority, not based on OpenSSLs default and priorities. Translated into English: before, we just used the list from OpenSSL (which was really good), now we make our own list... with blackjack! ...and hookers! with RC4! ...and MD5!The test suite comes with another hint:
// Note these are added in priority order as defined by RI 6 documentation.That RI 6 for sure has nothing to do with MI 6, but stands for Reference Implementation, the Sun (now Oracle) Java SDK version 6.
So what the fine Google engineers did to reduce our security was merely to copy what was there, defined by the inventors of Java!
Whoops! It seems that the Java security team copied the list in RFC2246 from the TLS1.0 team that dates back to 1999, and it's been maintained as the Reference for up until Java 6. Android security team then copied Java security team, and hey presto ... we're secure because we're following best practices and we're unsecure because we have no clue what is going on under the hood!
Defenders of the truth will rush forth to remind us that Sun/Oracle updated their list somewhat in Java 7; granted:
Java 7 added Elliptic Curves and significantly improved the cipher list in 2011, but Android is based on JDK 6, making the effective default cipher list over 10 years old now.
But the nature of the upgrade cycle and the trap that is defaults is that those who follow the leader are screwed: Not only Android but also all of Mac OSX currently ship Java 6! Sheep! To the slaughter!
It is somewhat pointless going into the errors committed by the Java and Android teams, it's too involved, and there will be too much of an emphasis on defending, and distracting. Clearly however these errors are compounding on each other, in ways that these teams will never understand, because some of their very foundational assumptions are broken: don't copy others, don't use defaults, and don't lean on the crutch of user choice.
What is topical today is to look at the above process and highlight how easy it was to manipulate. Considering the attack by the NSA on NIST, now documented, and it is clearly seen that this attack could just as well have happened on Java's security team.
The change from the strong OpenSSL cipher list to a hardcoded one starting with weak ciphers is either a sign of horrible ignorance, security incompetence or a clever disguise for an NSA-influenced manipulation - you decide!
Conspiracy theory? That is how it was seen. But we now have the Snowden revelations, we know the modus operandi, and we now know that they did it to Dual_EC. So it gains credence.
But we also have one other data point that hints at manipulation, and that is the design of the JCE, Java's Cryptography Engine. If you are serious about security, and you reverse engineer the design (as my old Cryptix team did) then it raises serious questions. Why was it done that way? Skipping the long discussion, we can summarize with the one thing that JCE screams out at the reviewer:
The entire Java Cryptography approach (Architecture is an odd term here?) was designed to take control of the crypto. Not only the crypto, but the entire market for Java Crypto. Without a clear mandate to control the market, there is no good engineering reason to do it that way, and dozens of engineering reasons to run screaming.
Of course, the design is no smoking gun. And people involved will deny it as conspiracy theorizing, and damn the detractors to high hell.
But things have changed. We are now in the world where all major players have to prove the negative: since the disclosure that Apple, Google, Facebook, Microsoft and probably the others are delivering real time data to the NSA, we can conclude that the JCE attack was a likely one, and the onus is now on the Java security team to deal with this new reality.
That's a negative that will be difficult to prove. Which pretty much undermines the entire foundation of Oracle/Sun's approach to crypto. All of Java crypto is now completely undermined by the new revelations.
 What to do? If one is stuck in Java-lala-land, as many of us are? Only because some will dismiss any thought process without a list of positive suggestions, here are some options:
What to do? If one is stuck in Java-lala-land, as many of us are? Only because some will dismiss any thought process without a list of positive suggestions, here are some options:
- Use BouncyCastle (my old Cryptix team no longer being active). But, you have to use their non-JCE lightweight library. Which means you have to get adept at cryptoplumbing.
- Use Niel Alexander's port of NaCl to Java. This appears to be a clean port, although lacks any semblance of documentation. And, using NaCl only covers basic needs -- the cryptobox idea assumes you want to send an authenticated message from one place to another, with PK. It doesn't cover you outside that box, so to speak.
- It's your job, do it! This means becoming an adept at crypto. The upside of this is you get to align your responsibilities. The downside is that you have to learn quickly, and get good at asking for help from others. FTR, this is what I do.
What is clear is that we can no longer use the recommended crypto from Java, and at the same time maintain that we've done our job as security folk if our threat model is serious. Using Java's JCE is only workable if you are the threat model, or are otherwise an adept at cognitive dissonance.
October 05, 2013
The NSA's breach of RSA Inc's crypto: what to do? Where do we stand? My Answer: avoid American crypto
We now know -- on balance of probabilities -- that the NSA conducted a 3 phased attack on the crypto world. First step was to insert a dodgy random number generator (RNG) into a NIST standard, called Dual_EC. Second step was to convince major suppliers to implement and set that RNG as the default. Third step is: Profit! which is to say, defeat your crypto.
This step is effected by decrypting your traffic, knowing how the random numbers were fed into your protocol, and being able to predict them with some degree of crunchability. We have no information on that third step, but the information that has come out in the post-Snowden world is damning. We can conclude that this was a phased and deliberate approach.
 What then to do? As Jon Callas of Silent Circle puts it:
What then to do? As Jon Callas of Silent Circle puts it:
The problem one faces with the BULLRUN documents gives a decision tree. The first question is whether you think they're credible. If you don't think BULLRUN is credible, then there's an easy conclusion -- stay the course. If you think it is credible, then the next decision is whether you think that the NIST standards are flawed, either intentionally or unintentionally; in short, was BULLRUN *successful*. If you think they're flawed, it's easy; you move away from them.The hard decision is the one that comes next -- I can state it dramatically as "Do you stand with the NSA or not?" which is an obnoxious way to put it, as there are few of us who would say, "Yes, I stand with the NSA." You can phrase less dramatically it as standing with NIST, or even less dramatically as standing with "the standard." You can even state it as whether you believe BULLRUN was successful, or lots of other ways.
Where do we stand? We need to answer a bunch of questions in order to get to a conclusion.
The first question surrounds the nature of defaults. RSA Inc's alleged crime against its customers was to set the dodgy RNG as a default. Some will argue that this leaves the user the choice and responsibility of adjusting the defaults, whereas others will argue that the customer buys from RSA so that it gets a secure-by-default product.
Who is right? Peter points to compelling evidence that defaults are sticky: "Software Defaults as De Facto Regulation: The Case of Wireless APs ," Rajiv Shah and Christian Sandvig, TPRC'07, September 2005,
Our results show that default settings play a powerful role in how people use technology. People are hesitant to change the manufacturers default settings and defer to them. While this argument is well known to scholars in this area, this study found empirical evidence to quantify this effect using multiple measures from two very different sources of data (one of them very large). In our empirical study, we found that most people do not change default settings.
Time and time again we've found that out in userland, systems are insecure because the configuration issues are beyond the users. Users cannot deal with crypto and security decisions, and they are not asking us to offer them these choices. Users ask us to supply a secure product, and, forcing "freedom of choice" on users is just a nonsense if empirically we know they cannot adequately handle any choice.
The evidence and observation now suggests that setting an insecure default will leave a majority insecure, and is therefore a monumental fail:
Specifically, we found that when a manufacturer sets a default setting to ON, 9699 percent of users follow the manufacturers suggestion. When a manufacturer sets a default setting to OFF, and users are exhorted to change the setting by the media, instruction manuals, and online help, only 2857 percent of users will do so. About half of the users of the most popular product changed no defaults at all, and there was a small positive association between changing one default setting and changing another, even though the qualitative nature of the default settings we considered was quite different. There is also a suggestion that those living in areas with lower incomes, lower levels of education, and higher minority populations are less likely to change defaults, ...
The choice of default is integral to the provision of security, and an insecure default is an insecure product. Security defaults must then be secure. Indeed, I go even further than Shah & Sandvig, and ban choice altogether:
There is only one mode and it is secure.
If you want to deliver security to users, take the choice away, and this mess shouldn't happen.
Back to RSA: we can conclude that they lived dangerously and promoted the choice of an NSA-influenced RNG as a default. Their decision was indeed a dramatically bad one, and a damaging one, and I'd place this mistake akin to the famous Debian bug.
And our next question: Was their choice justified at the time? And, when or if did it become unjustified? Who knew what, when?
We can make an argument that when RSA did the contract work for the US government around 2004-2005, Dual_EC was a good idea. This argument survives because:
- the RNG was based on Elliptic Curve cryptography, which was strongly recommended by the NSA in for example Suite B,
- the NSA had designed the RNG, said it was good, and had impeccable credentials for that recommendation, and finally
- NIST reviewed and accepted Dual_EC as a standard.
But this argument quickly became controversial, as Dual_EC was criticised almost immediately on becoming a standard. Criticisms continued to mount, and Dual_EC didn't survive unscathed for long: In 2007, cryptographers at Microsoft announced that the design appeared architectured as if for a backdoor. At that point, the scales of cryptojustice tipped the other way: Dual_EC had been fatally undermined, and it behoved all suppliers of security to re-think its place in the world.
What did RSA do at this point? Nothing, or at least nothing that affected their users, which is the same thing. In the face of severe criticism of Dual_EC, RSA left it as the default.
Should they have acted? As their job is to provide secure crypto software, they have a duty of care on exactly that point: they knew or should have known that Dual_EC was no longer secure, and to leave in Dual_EC was an epic fail.
As of day of writing, RSA's website reads: *Crypto Kernel
RSA BSAFE Crypto Kernel offers versions of popular cryptographic algorithms optimized for both small code size and high performance. Unlike alternatives such as open source, our technology is backed by highly regarded cryptographic experts.
My emphasis.
In short, RSA Inc. was negligent. RSA did not manage that tool for the benefit of users until it became so blindingly embarrassing that NIST itself struck the tool off the standard. It continued to act in the interests of one customer, the US government, and against the interests of its other customers, up until it was too late.
RSA therefore deserves to be excoriated as a security provider, and dropped for its failure. It deserves to lose all business outside its one favoured customer. Not because it made a mistake, as did for example Debian, but because RSA did not take reasonable care, that care due to the customer in the security business, by not rectifying the mistake when the writing was on the wall.
The same logic would apply to any other supplier that set and left Dual_EC as a default and/or was influenced by the NSA to favour them and not their smaller, more vulnerable customers. Which leads us to the next question:
How can we damn RSA and not the others? Are we just on a witchhunt? Who are the others? Are we just being unfair?
This is where we have to rely more on reasoned logic than on facts. We know that this attack happened. If it happened, was it only limited to RSA, or was it a broad-based attack on many suppliers? Reason suggests that it must have happened to others because
- the attack cost a lot of time and money to push through,
- it was set up well in advance of any attack event, and therefore
- would not be precise enough to target anyone in particular.
It has to be a campaign, it has to have targetted as many suppliers as possible.
Then, who? Perhaps RSA Inc are only guilty of being the honest ones, or the ones caught out? Who else was likely at risk, possibly influenced?
This influence would likely have happened at the intersection of those suppliers with the most interesting customers, and those that the NSA had most influence on.

Who has the most interesting customers? Well, let's say that the NSA was sticking to its mandate of spying on foreigners, and ignore any Americans. This would mean that "interesting suppliers" are those that sell worldwide, to interesting foreigners.
But, influence is only strong on USA suppliers who have to export (and seek a USA export licence), or those who engage in large US government contracts. Either way, we can suggest that all USA suppliers who export are most at risk. In a nutshell, speaking as foreigners:
American-influenced cryptography should be avoided.
Simple enough to say, bit this is a bit more dramatic than it sounds at first blush. Under this conclusion, not only RSA's BSafe product and any similar FIPS approved products, but also Java's JCE/JCA (Java Cryptography Engine/Architecture), and Microsoft's CAPI (Cryptographic API) are tainted. Which leaves most of finance, most of mobile and most of the desktop in a state of uncertainty. And, inevitably, questions will circulate around Apple, IBM and google and others that ship and use crypto.
Even OpenSSL has FIPS-approved distributions. Linux ships with SELinux security modifications with influence from the NSA. Lavabit was running a website in the USA. This is going to be one very busy microscope.
Does this pass the laugh test? Unfortunately, yes. Too much information has come from Snowden (and too many hints existed before) that in sum suggests this was a persistent and deliberate campaign. Recall, the 'crown jewels' disclosure revealed that the NSA were happy to destroy the security credentials of major American Internet companies in order to get an advantage! By which I mean, Google, Facebook, Microsoft, etc, companies that have still not responded to the allegations in a meaningful way, so their credibility is damaged.
It's serious stuff. Worse, we don't have easy solutions. We don't have enough independent sources of crypto. We don't have enough cryptoplumbers to go around, as the stuff is complicated and esoteric, and users have never paid heed to it. We don't have enough evidence to know which other countries are also impacted, whether there are other, non-USA products that they got at.
What if you are an American supplier of cryptographic trust? You're in a bind:
And absolutely, this is an emotional response. It's protest. Intellectually, I believe that AES and SHA2 are not compromised. Emotionally, I am angry and I want to distance myself from even the suggestion that I am standing with the NSA. As Coderman and Iang put it, I want to *signal* my fury. I am so pissed off about this stuff that I don't *care* about baby and bathwater, wheat and chaff, or whatever else. I also want to signal reassurance to the people who use my system that yes, I actually give a damn about this issue.
Avoiding American-influenced crypto is just today's logic, based on what we know, today. The crypto industry is now in a crisis of trust. This is going to get worse.
September 21, 2013
The Anatomy of an NSA intervention -- NIST & RSA fingered as breached

It is now almost good enough to take to a jury -- the NSA perverted the public standards process, and convinced at least one major supplier of crypto tools to weaken customer's infrastructure by using that flawed standard.
We don't have an admission of guilt from the NSA, and never will have that! But at the least, we now know enough to understand the anatomy of the breach. Here goes:
Part one. The NSA participated in a public standards process run by NIST (USA's National Institute for Standards and Technology) to create a new federal standard for random number generation, called Special Publication 800-90.
This is really important to us in the security world because of two things: good random numbers are the bedrock of many cryptographic protocols. Secondly, where NIST goes, the USA federal government *must* go, most of the USA industry slots into line without question, and the rest of the world also tends to nod wisely and follow.
The power of NIST standards over the crypto world is something without parallel, which made it a prize worth fighting for. The goal then was to force into NIST standards a flawed cryptographic random number generator that the NSA could crack -- that is, render the numbers un-random and therefore the cryptographic protocols broken and weak -- but nobody else would see the difference.
Details are on Mathew Greene's site, if you like a little math.
This was achieved, under the unlikely name of Dual_EC_DRBG! On to part two: the next act in the drama is to pay/extort/pressure/trick various suppliers of software into using the flawed standard. This is actually a lot easier than it sounds. Firstly, it was a standard, and most companies will bow and scrape before such a thing without question. OpenSSL ships it, so the ruse was far spread.
Secondly, where necessary, pressure can be brought to bear, and explanations can be fluffed. Crucial in this case was the logic that the Dual_EC concept used elliptic curve mathematics which were impenetrable to many, and rather new to industry. Hence it was possible to 'snow' the discussion with a lot of bla bla, and normally critical people were seemingly lulled from skepticism to acquiescence.
Which, once done then leads to part three: profit! Or in this case, eavesdrop. If there are all these systems out there using the flawed random number generator, it is possible for the NSA (only) to attack them. Listen, change, pervert, whichever. Unfortunately, we have little information on this phase; we don't know how many companies have been tricked into using the flawed generator (so far, NIST records: RSA and Thales, Catbird, McAfee, Cummings, OpenSSL, ARX, Certicom, RIM/Blackberry, Mocana, Microsoft, Cisco, Juniper, Blackberry, OpenPeak, Samsung, Symantec, Riverbed, CoCo, Kony, Lancope, SafeNet, SafeLogic, Panzura, GE Healthcare), and we don't know what successful penetration occurred as a result.
Little matter, for the potential for damage is huge. We know now how the attack happened, and it is important to document it as a case study, for future defence efforts.
Having said all that, the attack did not happen without some drama. Firstly, Dual_EC had some suspicious absences: a lack of any security proof and some unclear foundations. In a rump session at Crypto 2007, a couple of smart cryptographers from Microsoft laid out a theory by which if the NSA had been malicious, it could have spiked the design, kept a hidden backdoor, and nobody would be the wiser.
Unfortunately there was no proof. And the custom to label people as 'conspiracy theorists' until they bring PROOF, real solid actual proof of malicious actions, was enough to quell the concerns. If we know one thing, it is this: there is never ever any proof, and thus the temptation to downgrade any such crazy criticisms as tinfoil conspiracy theory fruitcakes from Microsoft works very well for the NSA.
Secondly, the NSA did not count on one thing which they should have known: a secret that big would have eventually outed. While it turns out that more than one knew about the attack, it was Edward Snowden that set the cat amongst the pigeons. When he commented recently that a 2006 NIST standard had been perverted, it took about a day to figure which one, because of the already published criticisms.
Then, within the week, NIST declared itself extremely uncomfortable with the flawed standard, and recommended against it. A couple of days later, RSA announced it was pulling that product.
RSA? The venerable old company that provided the crypto behind SSL's PKI? Yes the same company that was once responsible for the majority of ecommerce had placed the flawed random number generator as its default. Worse, allegations have circulated that serious amounts of money changed hand in exchange for the favour to NSA, although we'll never likely see any serious evidence of that scandalous claim.
Update -- the approach was one of influence via an existing large contract for $10m with the NSA. Of course.

So there we have it -- the anatomy of a breach, from NSA to NIST to RSA. This was a serious effort. It should lay to rest claims that this would not happen elsewhere. If the NSA went to that sort of trouble, breaching individual companies and other governments should now be seen as entirely plausible.
Addendum: more evidence from NSA's $250m SIGINT Enabling project:

December 06, 2012
Time for another One True Crypto Suite ?
My software for secure payments, inter alia, is somewhat in need of a crypto refit.
This is unusual -- the old dicta of /the one true cipher suite/ has it that there is rarely a good reason to change the crypto or to include multiple options. However there is a rare and subtle need to deal with new stuff after sufficient time has passed. In the rant, I said wait for a minimum of 7 years, and that's now passed.
Back in the late 1990s, we settled on: SHA1 for message digests, triple-DES + CBC for encryption, and variously RSA and DSA for signing and PK encryption.
A mid 2000s update brought in AES. We steered clear of the emerging authenticated encryption mode issue by using CBC and SHA1-HMAC over the AES (encrypt-then-hmac). Very conservative!
Now I find myself at the cusp of a new system. Time to upgrade before it gets bedded in too tightly. This is what I am thinking:
| Signing: | Rabin-Williams? RSA? ECDSA? |
| Public Key Encryption: | Curve25519 ? |
| Message Digest: | KECCAK |
| Secret Key Encryption: | AES 128: ?? |
| authentication mode: | ??? |
The hardest question I have is what to use as a public key signing algorithm. On the one hand, signing is the cornerstone of security in the system, so I do want something solid. In a way, the rest are all negotiable in strength because they gain from the cornerstone.
On the other hand, public key cryptography involves real maths which makes it impenetrable to a mere cryptoplumber like myself. It is easy to compare block algorithms, HMACs, message digests etc, but public key crypto gets hairy rapidly.
Comments? What is the best signing algorithm these days?
October 14, 2012
More surreal events in the Crypto Cold War - the BitCoin blockade of Iran
 There is a popular view that the crypto wars of the 1990s were won when President Clinton signed the order making open source free of export controls. An alternative theory is that, on retiring in 2000, he allowed the intelligence community to defang the crypto-geeks by handing them a victory - colourful, public but empty of strategic significance. Meanwhile, the war is carried on by other means. Here's some evidence that suggests that the other means are still well in force - Sourceforge has blocked Iranian users from accessing BitCoin software. Jon Matonis writes:
There is a popular view that the crypto wars of the 1990s were won when President Clinton signed the order making open source free of export controls. An alternative theory is that, on retiring in 2000, he allowed the intelligence community to defang the crypto-geeks by handing them a victory - colourful, public but empty of strategic significance. Meanwhile, the war is carried on by other means. Here's some evidence that suggests that the other means are still well in force - Sourceforge has blocked Iranian users from accessing BitCoin software. Jon Matonis writes:
The original and official Bitcoin client is hosted in the United States on GeekNets SourceForge.net who explained their denial of site access policy on their blog:The specific list of sanctions that affect our users concern the transfer and export of certain technology to foreign persons and governments on the sanctions list. This means users residing in countries on the United States Office of Foreign Assets Control (OFAC) sanction list, including Cuba, Iran, North Korea, Sudan, and Syria, may not post content to, or access content available through, SourceForge.net. Last week, SourceForge.net began automatic blocking of certain IP addresses to enforce those conditions of use.
This is mightily curious. One assumes the US State Department has put pressure on Sourceforge by denial means. In that, if it isn't them or one of their many proxies, why would SourceForge care? Only if there were serious messages brought to bear would any Internet business really respond.
If so, I think the US State Department may very well have shot itself in the foot.
By forcing an open community actor to go public with the export controls, it adds more emphasis to the message that the international crypto community was duped, yet again -- we remain in a crypto cold war, whether we choose to recognise it or not. And, do not forget that this war delivers substantial collatoral damage. A large part of our problem with defending our own corporate and utility infrastructure from enemies, financial and statal, derives directly from the US Government's war on defensive crypto.
Back to BitCoin. Worse, the Bitcoiners have little truck with US policy, by their nature. The are more likely see an Iran blockade as a an opportunity to test their blockade running skills, rather than a call to play their part in the responsible policing of the world.
Even perversely, it gets worse. The State Department has now endorsed BitCoin as a tool of choice. Which message will certainly not go unheard by the Iranians, and even the rest of the US government will be scratching its head over this antithetical marketing.
It's somewhat curious as to where the US State Department is getting its advice from, if this is for real. What is the department or desk responsible for such strategy? How do they top this? Do they issue guidelines for placing one foot above the other, and trying to get both in one shot next time?
Ob-Bitcoin:
- a good explanation on BitCoin from Morgen Peck in Scientific American.
- An article penned by Philipp Güring and myself entitled "Bitcoin & Gresham's Law - the economic inevitability of Collapse.
October 02, 2012
SHA3 announced by NIST: KECCAK (pronounced Catch-Ack in English)
The National Institute of Standards and Technology (NIST) is pleased to announce the selection of KECCAK as the winner of the SHA-3 Cryptographic Hash Algorithm Competition and the new SHA-3 hash algorithm. KECCAK was designed by a team of cryptographers from Belgium and Italy, they are:
Guido Bertoni (Italy) of STMicroelectronics,
Joan Daemen (Belgium) of STMicroelectronics,
Michaël Peeters (Belgium) of NXP Semiconductors, and
Gilles Van Assche (Belgium) of STMicroelectronics.
NIST formally announced the SHA-3 competition in 2007 with an open call for the submission of candidate hash algorithms, and received 64 submissions from cryptographers around the world. In an ongoing review process, including two open conferences, the cryptographic community provided an enormous amount of expert feedback, and NIST winnowed the original 64 candidates down to the five finalist candidates BLAKE, Grøstl, JH, KECCAK and Skein. These finalists were further reviewed in a third public conference in March 2012.
NIST chose KECCAK over the four other excellent finalists for its elegant design, large security margin, good general performance, excellent efficiency in hardware implementations, and for its flexibility. KECCAK uses a new sponge construction chaining mode, based on a fixed permutation, that can readily be adjusted to trade generic security strength for throughput, and can generate larger or smaller hash outputs as required. The KECCAK designers have also defined a modified chaining mode for KECCAK that provides authenticated encryption.
Additionally, KECCAK complements the existing SHA-2 family of hash algorithms well. NIST remains confident in the security of SHA-2 which is now widely implemented, and the SHA-2 hash algorithms will continue to be used for the foreseeable future, as indicated in the NIST hash policy statement. One benefit that KECCAK offers as the SHA-3 winner is its difference in design and implementation properties from that of SHA-2. It seems very unlikely that a single new cryptanalytic attack or approach could threaten both algorithms. Similarly, the very different implementation properties of the two algorithms will allow future application and protocol designers greater flexibility in finding one of the two hash algorithms that fits well with their requirements.
NIST thanks the many people in companies, universities, laboratories and organizations around the world that participated in and contributed to the SHA-3 competition, especially the submitters of all the candidate algorithms, and the many others who contributed expert cryptanalysis, and performance studies. NIST could not have done the competition without them.
A detailed report of the final round of the competition will be published in the near future. Information about the SHA-3 competition is available at: www.nist.gov/hash-competition.
October 14, 2010
philosophical question about strengths and attacks at impossible levels
Zooko writes to SHA-3 designers for the NIST hash competition:.
Folks:
If a hash has 32-bit pre-image-resistance then this means an attacker might spend about 2^32 resources to find a pre-image.
If a hash has 64-bit pre-image-resistance then this means an attacker might spend about 2^64 resources to find a pre-image.
What if a hash has 512-bit collision-resistance? What would that mean? That an attacker might spend about 2^512 resources to find a collision in it? That is a meaningless possibility to discuss since 2^512 resources will never exist in the life of this universe, so it can't mean that, or if it does mean that then there is no use in talking about "512-bit collision-resistance". Maybe it means something else?
By analogy, suppose you considered the construction of a bridge that withstood 10^3 tons of pressure. You could also consider a bridge that could withstand 10^6 tons of pressure. If the bridge were to be deployed in a situation where more than 10^3 tons but less than 10^6 tons might rest on it, then this would be a very important distinction to make.
But what would it mean to discuss a design for a bridge that could withstand 10^150 tons of pressure? Such an amount of pressure could never be applied to the bridge. Would there be any value in a distinction between one bridge design that would withstand 10^150 tons of pressure and another that would withstand 10^300? Even though neither of them could ever experience as much as 10^150 tons of pressure, perhaps the latter bridge would still be safer against some other threat -- an error on the part of the builders or designers or a stressful event that was not included in the model which we used to evaluate our bridges in the first place.
Or perhaps not. Perhaps the bridge which is designed to withstand 10^300 tons of pressure is actually *more* likely to fail than the other one when hit by this unpredicted, unmodelled event. Who can tell?
One reasonable position to take is that it was a mistake for NIST to specify that some of the SHA-3 hashes had to have 512-bit preimage resistance. (If it *was* a mistake the I really have no idea what to do about it at this juncture!)
That position says that there *is* a need for a hash function which takes much more CPU time than SHA-3-256 does in order to provide much less likelihood that an attacker will be able to find a pre-image in it than in SHA-3-256, but that this "much less likelihood" is not in any meaningful sense correlated with the idea of having "512-bit pre-image resistance".
Another reasonable position to take is that a hash function which is known to have at most 384-bit pre-image resistance is *more likely to fail* than one which is known to have at most 512-bit pre-image resistance. This is where my limited understanding of hash function cryptanalysis comes to an end. Is that plausible? If I give you two hash functions like that, are you confident that you could learn how to find pre-images in the former before they find pre-images in the latter? How sure are you? Is it possible that it would be the other way around--that you would discover a method of finding pre-images in the latter before discovering a method of finding pre-images in the former?
If someone who has real hash function cryptanalysis expertise and who takes the latter position could explain what they mean by "more likely to fail", then I would be fascinated to hear it.
In any case, I'm pretty sure that as a *user* of hash functions what I care about is "more likely to fail" (and efficiency), not about "bits of security" for any bit-level greater than about 128 (including consideration of quantum attacks, multi-target attacks, etc.)
Thank you for taking the time to read this.
Regards,
Zooko Wilcox-O'Hearn
October 05, 2010
Cryptographic Numerology - our number is up
Chit-chat around the coffeerooms of crypto-plumbers is disturbed by NIST's campaign to have all the CAs switch up to 2048 bit roots:
On 30/09/10 5:17 PM, Kevin W. Wall wrote:> Thor Lancelot Simon wrote:<...snip...>
> See below, which includes a handy pointer to the Microsoft and Mozilla policy statements "requiring" CAs to cease signing anything shorter than 2048 bits.> These certificates (the end-site ones) have lifetimes of about 3 years maximum. Who here thinks 1280 bit keys will be factored by 2014? *Sigh*.No one that I know of (unless the NSA folks are hiding their quantum computers from us :). But you can blame this one on NIST, not Microsoft or Mozilla. They are pushing the CAs to make this happen and I think 2014 is one of the important cutoff dates, such as the date that the CAs have to stop issuing certs with 1024-bit keys.I can dig up the NIST URL once I get back to work, assuming anyone actually cares.
The world of cryptology has always been plagued by numerology.
Not so much in the tearooms of the pure mathematicians, but all other areas: programming, management, provisioning, etc. It is I think a desperation in the un-endowed to understand something, anything of the topic.
E.g., I might have no clue how RSA works but I can understand that 2048 has to be twice as good as 1024, right? When I hear it is even better than twice, I'm overjoyed!
This desperation to be able to talk about it is partly due to having to be part of the business (write some code, buy a cert, make a security decision, sell a product) and partly a sense of helplessness when faced with apparently expert and confident advice. It's not an unfounded fear; experts use their familiarity with the concepts to also peddle other things which are frequently bogus or hopeful or self-serving, so the ignorance leads to bad choices being made.
Those that aren't in the know are powerless, and shown to be powerless.
When something simple comes along and fills that void people grasp onto them and won't let go. Like numbers. As long as they can compare 1024 to 2048, they have a safety blanket that allows them to ignore all the other words. As long as I can do my due diligence as a manager (ensure that all my keys are 2048) I'm golden. I've done my part, prove me wrong! Now do your part!
This is a very interesting problem [1]. Cryptographic numerology diverts attention from the difficult to the trivial. A similar effect happens with absolute security, which we might call "divine cryptography." Managers become obsessed with perfection in one thing, to the extent that they will ignore flaws in another thing. Also, standards, which we might call "beliefs cryptography" for their ability to construct a paper cathedral within which there is room for us all, and our flock, to pray safely inside.
We know divinity doesn't exist, but people demand it. We know that religions war all the time, and those within a religion will discriminate against others, to the loss of us all. We know all this, but we don't; cognitive dissonance makes us so much happier, it should be a drug.
It was into this desperate aching void that the seminal paper by Lenstra and Verheul stepped in to put a framework on the numbers [2]. On the surface, it solved the problem of cross-domain number comparison, e.g., 512 bit RSA compared to 256 bit AES, which had always confused the managers. And to be fair, this observation was a long time coming in the cryptographic world, too, which makes L&V's paper a milestone.
Cryptographic Numerology's star has been on the ascent ever since that paper: As well as solving the cipher-public-key-hash numeric comparison trap, numerology is now graced with academic respectability.
This made it irresistible to large institutions which are required to keep their facade of advice up. NIST like all the other agencies followed, but NIST has a couple of powerful forces on it. Firstly, NIST is slightly special, in ways that other agencies represented in keylength.com only wish to be special. NIST, as pushed by the NSA, is protecting primarily US government resources:
This document has been developed by the National Institute of Standards and Technology (NIST) in furtherance of its statutory responsibilities under the Federal Information Security Management Act (FISMA) of 2002, Public Law 107-347. NIST is responsible for developing standards and guidelines, including minimum requirements, for providing adequate information security for all agency operations and assets, but such standards and guidelines shall not apply to national security systems.
That's US not us. It's not even protecting USA industry. NIST is explicitly targetted by law to protect the various multitude of government agencies that make up the beast we know as the Government of the United States of America. That gives it unquestionable credibility.
And, as has been noticed a few times, Mars is on the ascendancy: *Cyberwarfare* is the second special force. Whatever one thinks of the mess called cyberwarfare (equity disaster, stuxnet, cryptographic astrology, etc) we can probably agree, if anyone bad is thinking in terms of cracking 1024 bit keys, then they'll be likely another nation-state interested in taking aim against the USG agencies. c.f., stuxnet, which is emerging as a state v. state adventure. USG, or one of USG's opposing states, are probably the leading place on the planet that would face a serious 1024 bit threat if one were to emerge.
Hence, NIST is plausibly right in imposing 2048-bit RSA keys into its security model. And they are not bad in the work they do, for their client [3]. Numerology and astrology are in alignment today, if your client is from Washington DC.
However, real or fantastical, this is a threat model that simply doesn't apply to the rest of the world. The sad sad fact is that NIST's threat model belongs to them, to US, not to us. We all adopting the NIST security model is like a Taurus following the advice in the Aries section of today's paper. It's not right, however wise it sounds. And if applied without thought, it may reduce our security not improve it:
![]()
Writes Thor:
> At 1024 bits, it is not. But you are looking
> at a factor of *9* increase in computational
> cost when you go immediately to 2048 bits. At
> that point, the bottleneck for many applications
> shifts, particularly those ...
> Also,...
> ...and suddenly...
>
> This too will hinder the deployment of "SSL everywhere",...
When US industry follows NIST, and when worldwide industry follows US industry, and when open source Internet follows industry, we have a classic text-book case of adopting someone else's threat, security and business models without knowing it.
Keep in mind, our threat model doesn't include crunching 1024s. At all, any time, nobody's ever bothered to crunch 512 in anger, against the commercial or private world. So we're pretty darn safe at 1024. But our threat model does include
*attacks on poor security user interfaces in online banking*
That's a clear and present danger. And one of the key, silent, killer causes of that is the sheer rarity of HTTPS. If we can move the industry to "HTTPS everywhere" then we can make a significant different. To our security.
On the other hand, we can shift to 2048, kill the move to "HTTPS everywhere", and save the US Government from losing sleep over the cyberwarfare it created for itself (c.f., the equity failure).
And that's what's going to happen. Cryptographic Numerology is on a roll, NIST's dice are loaded, our number is up. We have breached the law of unintended consequences, and we are going to be reducing the security of the Internet because of it. Thanks, NIST! Thanks, Mozilla, thanks, Microsoft.
[1] As well as this area, others have looked at how to make the bounty of cryptography more safely available to non-cognicenti. I especially push the aphorisms of Adi Shamir and Kerckhoffs. And, add my own meagre efforts in Hypotheses and Pareto-secure.
[2] For detailed work and references on Lenstra & Verheul's paper, see http://www.keylength.com/ which includes calculators of many of the various efforts. It's a good paper. They can't be criticised for it in the terms in this post, it's the law of unintended consequences again.
[3] Also, other work by NIST to standardise the PRNG (psuedo-random-number-generator) has to be applauded. The subtlety of what they have done is only becoming apparent after much argumentation: they've unravelled the unprovable entropy problem by unplugging it from the equation.
But they've gone a step further than the earlier leading work by Ferguson and Schneier and the various quiet cryptoplumbers, by turning the PRNG into a deterministic algorithm. Indeed, we can now see something special: NIST has turned the PRNG into a reverse-cycle message digest. Entropy is now the MD's document, and the psuedo-randomness is the cryptographically-secure hash that spills out of the algorithm.
Hey Presto! The PRNG is now the black box that provides the one-way expansion of the document. It's not the reverse-cycle air conditioning of the message digest that is exciting here, it's the fact that it is now a new class of algorithms. It can be specified, paramaterised, and most importantly for cryptographic algorithms, given test data to prove the coding is correct.
(I use the term reverse-cycle in the sense of air-conditioning. I should also stress that this work took several generations to get to where it is today; including private efforts by many programmers to make sense of PRNGs and entropy by creating various application designs, and a couple of papers by Ferguson and Schneier. But it is the black-boxification by NIST that took the critical step that I'm lauding today.)
September 28, 2010
Crypto-plumbers versus the Men in Black, round 16.
Skype, RIM, and now CircleTech v. the governments. This battle has been going on for a while. Here's today's battle results:

BIS [Czech counter-intelligence] officers first offered to Satanek that his firm would supply an encryption system with "a defect" to the market which would help the secret service find out the content of encrypted messages. "This is out of question. It is as if we were proclaiming we are selling bullet-proof vests that would actually not be bullet-proof," Satanek told MfD.This is why BIS offered a deal to the firm's owners. BIS wanted CircleTech to develop a programme to decipher the codes. It would only partially help the secret service since not even CircleTech is capable of developing a universal key to decipher all of its codes. Nevertheless, software companies are offering such partial services, and consequently it would not be a problem for CircleTech to meet the order, MfD notes.
However, BIS officers said the firm need not register the money it would receive from BIS for the order, the paper writes. "You will have on opportunity to get an income that need not be subject to taxation," MfD cites the secret recording of a BIS officer at a meeting with the firm. Satanek rejected the offer and recorded the meetings with BIS.
BIS then gave it up. However, two months ago it contacted Satanek again, MfD writes. "They told me that we are allegedly meeting suspicious persons who pose a security risk to the state. In such a case we may not pass security vetting of the National Security Office (NBU)," Satanek told MfD.
Subversion, bribes, and threats, it's all in there! And, no wonder every hot new code jockey goes all starry-eyed at the thought of working on free, open encryption systems.
June 15, 2010
new attacks on AES
Last year, a spate of attacks on AES caused the shine to come off. Vincent Rijmen, one of the designers, has now announced an attack on AES that reduces the key strength from 128 bits to 32 bits.
Ouch! But there's a catch:
This attack clearly endangers all practical applications where an attacker can halt the computer in the middle of the execution of an encryption routine , apply the specific difference δ to the state, and roll back the interrupted encryption and obtain the modified plaintext p*.
Which is to say, the attacker must have something else. He must be able to stop the encryption, inject some different values, and then restart it.
Is this a worry? Well, no. If the attacker has that ability -- stop, inject, restart -- then the attacker probably has lots of other powers too. Yes, in that the result seems to again undermine the strength of the algorithm. As they say in cryptoland, the attacks only get better.
In sum, I wouldn't be too worried. If this attack breaks you, then you've got another problem: can't be too careful about those environmental factors! But we might start to think about the replacement of AES somewhat sooner than expected (e.g., last year, Bruce Schneier suggested simply increasing the rounds of AES128 from 10 to 16) and whether we need to incorporate specific environmental defences in the next design competition.
As more information comes in, especially analysis by real cryptographers rather than cryptography realists, I'll update the post. Hat tip to Alfonso De Gregorio who spotted it and added his own variant.
October 19, 2009
Denial of Service is the greatest bug of most security systems
 I've had a rather troubling rash of blog comment failure recently. Not on FC, which seems to be ok ("to me"), but everywhere else. At about 4 in the last couple of days I'm starting to get annoyed. I like to think that my time in writing blog comments for other blogs is valuable, and sometimes I think for many minutes about the best way to bring a point home.
I've had a rather troubling rash of blog comment failure recently. Not on FC, which seems to be ok ("to me"), but everywhere else. At about 4 in the last couple of days I'm starting to get annoyed. I like to think that my time in writing blog comments for other blogs is valuable, and sometimes I think for many minutes about the best way to bring a point home.
But more than half the time, my comment is rejected. The problem is on the one hand overly sophisticated comment boxes that rely on exotica like javascript and SSO through some place or other ... and spam on the other hand.
These things have destroyed the credibility of the blog world. If you recall, there was a time when people used blogs for _conversations_. Now, most blogs are self-serving promotion tools. Trackbacks are dead, so the conversational reward is gone, and comments are slow. You have to be dedicated to want to follow a blog and put a comment on there, or stupid enough to think your comment matters, and you'll keep fighting the bl**dy javascript box.
The one case where I know clearly "it's not just me" is John Robb's blog. This was a *fantastic* blog where there was great conversation, until a year or two back. It went from dozens to a couple in one hit by turning on whatever flavour of the month was available in the blog system. I've not been able to comment there since, and I'm not alone.
This is denial of service. To all of us. And, this denial of service is the greatest evidence of the failure of Internet security. Yet, it is easy, theoretically easy to avoid. Here, it is avoided by the simplest of tricks, maybe one per month comes my way, but if I got spam like others get spam, I'd stop doing the blog. Again denial of service.
Over on CAcert.org's blog they recently implemented client certs. I'm not 100% convinced that this will eliminate comment spam, but I'm 99.9% convinced. And it is easy to use, and it also (more or less) eliminates that terrible thing called access control, which was delivering another denial of service: the people who could write weren't trusted to write, because the access control system said they had to be access-controlled. Gone, all gone.

According to the blog post on it:
The CAcert-Blog is now fully X509 enabled. From never visited the site before and using a named certificate you can, with one click (log in), register for the site and have author status ready to write your own contribution.
Sounds like a good idea, right? So why don't most people do this? Because they can't. Mostly they can't because they do not have a client certificate. And if they don't have one, there isn't any point in the site owner asking for it. Chicken & egg?
But actually there is another reason why people don't have a client certificate: it is because of all sorts of mumbo jumbo brought up by the SSL / PKIX people, chief amongst which is a claim that we need to know who you are before we can entrust you with a client certificate ... which I will now show to be a fallacy. The reason client certificates work is this:
If you only have a WoT unnamed certificate you can write your article and it will be spam controlled by the PR people (aka editors).If you had a contributor account and havent posted anything yet you have been downgraded to a subscriber (no comment or write a post access) with all the other spammers. The good news is once you log in with a certificate you get upgraded to the correct status just as if youd registered.
We don't actually need to know who you are. We only need to know that you are not a spammer, and you are going to write a good article for us. Both of these are more or less an equivalent thing, if you think about it; they are a logical parallel to the CAPTCHA or turing test. And we can prove this easily and economically and efficiently: write an article, and you're in.

Or, in certificate terms, we don't need to know who you are, we only need to know you are the same person as last time, when you were good.
This works. It is an undeniable benefit:
There is no password authentication any more. The time taken to make sure both behaved reliably was not possible in the time the admins had available.
That's two more pluses right there: no admin de-spamming time lost to us and general society (when there were about 290 in the wordpress click-delete queue) and we get rid of those bl**dy passwords, so another denial of service killed.
Why isn't this more available? The problem comes down to an inherent belief that the above doesn't work. Which is of course a complete nonsense. 2 weeks later, zero comment spam, and I know this will carry on being reliable because the time taken to get a zero-name client certificate (free, it's just your time involved!) is well in excess of the trick required to comment on this blog.
No matter the *results*, because of the belief that "last-time-good-time" tests are not valuable, the feature of using client certs is not effectively available in the browser. That which I speak of here is so simple to code up it can actually be tricked from any website to happen (which is how CAs get it into your browser in the first place, some simple code that causes your browser to do it all). It is basically the creation of a certificate key pair within the browser, with a no-name in it. Commonly called the self-signed certificate or SSC, these things can be put into the browser in about 5 seconds, automatically, on startup or on absence or whenever. If you recall that aphorism:
There is only one mode, and it is secure.
And contrast it to SSL, we can see what went wrong: there is an *option* of using a client cert, which is a completely insane choice. The choice of making the client certificate optional within SSL is a decision not only to allow insecurity in the mode, but also a decision to promote insecurity, by practically eliminating the use of client certs (see the chicken & egg problem).
And this is where SSL and the PKIX deliver their greatest harm. It denies simple cryptographic security to a wide audience, in order to deliver ... something else, which it turns out isn't as secure as hoped because everyone selects the wrong option. The denial of service attack is dominating, it's at the level of 99% and beyond: how many blogs do you know that have trouble with comments? How many use SSL at all?
So next time someone asks you, why these effing passwords are causing so much grief in your support department, ask them why they haven't implemented client certs? Or, why the spam problem is draining your life and destroying your social network? Client certs solve that problem.
 SSL security is like Bismarck's sausages: "making laws is like making sausages, you don't want to watch them being made." The difference is, at least Bismark got a sausage!
SSL security is like Bismarck's sausages: "making laws is like making sausages, you don't want to watch them being made." The difference is, at least Bismark got a sausage!
Footnote: you're probably going to argue that SSCs will be adopted by the spammer's brigade once there is widespread use of this trick. Think for minute before you post that comment, the answer is right there in front of your nose! Also you are probably going to mention all these other limitations of the solution. Think for another minute and consider this claim: almost all of the real limitations exist because the solution isn't much used. Again, chicken & egg, see "usage". Or maybe you'll argue that we don't need it now we have OpenID. That's specious, because we don't actually have OpenID as yet (some few do, not all) and also, the presence of one technology rarely argues against another not being needed, only marketing argues like that.
September 05, 2009
What-the-heck happened to AES-256?
A month ago, the crypto-tea rooms were buzzing about the result in AES-256. Apparently, now weaker than AES-128. Can it be? Well, at first I thought this was impossible, because the cryptographers were not panicking, they were simply admiring the result. But the numbers that were reported indicated a drop in attack complexity to below AES-128, and the world was lapping it up.
So, a week back I got a chance to ask Dani Nagy of epointsystem.org, a real cryptographer, what the story is. Here it is. I've edited it for flow & style, but hopefully it unfolds like the original conversation:
Iang: btw ... did you follow the recent AES-256 news?
Dani: No. What happened?
Iang: There is a related key attack on AES-256 that apparently it reduces its strength to something *less* than AES-128
Dani: Do you have a reference?
Iang:
On July 1, 2009, Bruce Schneier blogged about a related-key attack on the 192-bit and 256-bit versions of AES discovered by Alex Biryukov and Dmitry Khovratovich; the related key attack on the 256-bit version of AES exploits AES' somewhat simple key schedule and has a complexity of 2^119. This is a follow-up to an attack discovered earlier in 2009 by Alex Biryukov, Dmitry Khovratovich, and Ivica Nikolic, with a complexity of 2^96 for one out of every 2^35 keys.Another attack was blogged by Bruce Schneier on July 30, 2009 and published on August 3, 2009. This new attack, by Alex Biryukov, Orr Dunkelman, Nathan Keller, Dmitry Khovratovich, and Adi Shamir, is against AES-256 that uses only two related keys and 2^39 time to recover the complete 256-bit key of a 9-round version, or 2^45 time for a 10-round version with a stronger type of related subkey attack, or 2^70 time for a 11-round version. 256-bit AES uses 14 rounds, so these attacks aren't effective against full AES.
Dani: I agree with Scheier's assessment. Moreover, I think that AES-256 is no pareto-improvement over AES-128 (which is what I always use), and has all sorts of additional costs that are not justified. On the other hand, 32-bit optimized implementation of AES-128 are faster than RC4, which is absolutely amazing, IMHO.
Iang: OK. What I don't follow is, has the attack reduced the complexity of attacking AES-256 down from o(128) *OR* o(256) ? or alternatively, what is the brute force order of magnitude complexity of each of the algorithms?
Iang: The (3rd attack) abstract mentions:
However, AES-192 and AES-256 were recently shown to be breakable by attacks which require $2^{176}$ and $2^{119}$ time, respectively.
Dani: The abstract of the Biryukov-Khorvatovich paper does not give any quantitative description of the result about AES-128 ...
Abstract. In this paper we present two related-key attacks on the full AES. For AES-256 we show the first key recovery attack that works for all the keys and has complexity 2119 , while the recent attack by Biryukov-Khovratovich-Nikoli´c works for a weak key class and has higher complexity. The second attack is the first cryptanalysis of the full AES- 192. Both our attacks are boomerang attacks, which are based on the recent idea of finding local collisions in block ciphers and enhanced with the boomerang switching techniques to gain free rounds in the middle.
Dani: Oh, it's actually from 2^256 to 2^119 indeed for a first key recovery!
Iang: that's the implication ... a massive drop in orders of magnitude ... people are saying that with this attack, AES-256 is now weaker than AES-128 !
Dani: That's not entirely true, because it's also the space complexity (you need a database that long), while brute-forcing AES-128 has a space complexity of 1 key (the one being tried). For example, at my lab, we can manage a time complexity of 2^56, but we have nowhere near that amount of space.
Iang: hmmm.... so one part of the attack is down to 2^119 which space complexity is still 2^256?
Dani: No, the space complexity is also 2^119. But that's huge.
Dani: (the space complexity cannot be greater than time complexity, btw)
Iang: AES-128 has its 128 bit key ... so its space complexity is ... 2^128 ?
Dani: No, it's space complexity is 1.
Dani: You don't need pre-computed tables at all to brute-force it. When brute-forcing, you try one key at a time, 2^128 times.
Iang: Ah! (lightbulb) So AES-256 had time complexity of 2^256 and space complexity of 1, being the one brute forced key. Now, under this new attack, it has a time complexity of 2^119 and a space complexity of 2^119?
Dani: Yes, Time of 2^256 down to both time and space of 2^119.
Iang: Hmmm... so maybe that is why nobody reported the real comparison. So it is strictly not true to say AES-128 is now stronger than AES-256
Dani: It all depends on the time-space tradeoff one has to make. AES-128 is time-complexity of 2^128, and space complexity of 1. Is that stronger or weaker than 2^119 and 2^119?
Dani: But it seems true that AES-256 is strictly weaker than AES-192. The immediate practical implication is that it is even less worth bothering with larger AES keys than before. AES-128 is so much cheaper than the other two.
Iang: This explains the advice I have seen: "use AES-128"
Dani: But I would advise using AES-128 even without any weaknesses found. It is several times faster and more handy with both 32-bit and 64-bit architectures than the other two, without opening new practical avenues of attack even for the most powerful of adversaries.
Iang: Sounds good to me, especially as I chose it in my last crypto project :)
Iang: thanks for the clarification ... the real message was not easy to figure out from the press reports, and the abstract was cunningly written to cast in the best light, as always.
Dani: Thanks for the heads-up! Interesting developments and well-written papers.
December 08, 2008
an infinite number of maths students...
Chris told me this one last night: an infinite number of maths students go into a bar, and decide to have some fun with the bartender. The first says "I'll have a pint." The second says "I'll have half a pint." The third: "I'll have a quarter of a pint," and the fourth "and an eighth..."
To which the bartender says, "you guys are pathetic, I'll just give you two pints."

(No, I've no idea what the TV show is about...)
June 03, 2008
Technologists on signatures: looking in the wrong place
Bruce Schneier writes about the classical technology / security view and how it applies to such oddities as the fax signature. As he shows, we have trouble making them work according to classical security & tools thinking.
In a 2003 paper, "Economics, Psychology, and Sociology of Security," Professor Andrew Odlyzko looks at fax signatures and concludes:Although fax signatures have become widespread, their usage is restricted. They are not used for final contracts of substantial value, such as home purchases. That means that the insecurity of fax communications is not easy to exploit for large gain. Additional protection against abuse of fax insecurity is provided by the context in which faxes are used. There are records of phone calls that carry the faxes, paper trails inside enterprises and so on. Furthermore, unexpected large financial transfers trigger scrutiny. As a result, successful frauds are not easy to carry out by purely technical means.He's right. Thinking back, there really aren't ways in which a criminal could use a forged document sent by fax to defraud me.
The problem that shakes the above comments is that signatures are not tools to make things secure, nor to stop fraud. Instead, they are signals of legal intent. The law has developed them over centuries or millenia not as tools to make contracts binding, as per the simplistic common myth, or to somehow make it hard for fraudsters, the above security myth, but signals to record the intent of the person.
These subtleties matter. When you send a fax with your signature on it, it doesn't matter that the signature can be copied; it is the act of you creating and sending the fax with signature that establishes intent. Indeed, the intent can be shown without the signature, and the source of the fax is then as important as anything else. For this reason, we generally confirm what you intended somehow. Or we should, as Bruce Schneier writes:
On October 30, 2004, Tristian Wilson was released from a Memphis jail on the authority of a forged fax message. It wasn't even a particularly good forgery. It wasn't on the standard letterhead of the West Memphis Police Department. The name of the policeman who signed the fax was misspelled. And the time stamp on the top of the fax clearly showed that it was sent from a local McDonald's.The success of this hack has nothing to do with the fact that it was sent over by fax. It worked because the jail had lousy verification procedures. They didn't notice any discrepancies in the fax. They didn't notice the phone number from which the fax was sent. They didn't call and verify that it was official. The jail was accustomed to getting release orders via fax, and just acted on this one without thinking. Would it have been any different had the forged release form been sent by mail or courier?
It's all backwards, according to the law. There should have been an intent, but there wasn't one. It wasn't that the policeman's signature established an intent, it was that the signature should have been a final step in confirming an intent that already existed. The point of phoning the policeman wasn't to check the signature, but to establish the intent. Which the signature would have nicely confirmed, but the check on intent isn't substitutable with the check on signature. As Jeff commented on the post:
Most people don't understand that signatures don't generally perform a security function, they perform a solemnization function. At least that was the case before the mathematicians got involved and tried to convince folks of the value of digitial signatures . . .. :-)
Before they got it totally backwards, that is. Your copied signature does not show intent by you, instead, it suggests an intent by you, that should be confirmed regardless. For you, this is good, as the principle of redundancy applies: you need something much more than one signature to lock you into a contract, or get you out of prison. And this process of showing intent bounces back to the signature in a particularly powerful protocol that is used in the legal world. This is a closely held secret, but I shall now reveal it and risk censure and expulsion for breaking the code:
Ask!
That's it, just ask the question. This can happen anywhere, but is best seen in a court setting: The judge says "Did you sign this?" If you did, then you say yes. (Else you're up for perjury, which is a serious risk.) If you didn't, you deny it, and then the court has a claim that it is not yours. The court now looks further to establish who's intent was behind this act.
It is for these reasons that digital signatures failed to make any mark on the real world, when cast as some sort of analogue to the human signature. Indeed, the cryptography community got it backwards, upside down and inside out. They thought that the goal was to remove the uncertainty and simplify the procedure, when in fact the goal was to preserve and exploit the uncertainty, and to augment the procedure. They were thinking non-repudiation, yet the signature is there to entice repudiation. They thought the signature was sufficient, yet it is no more than a signal of something much more important. They thought simplicity, when redundancy is the principle.
Digital signatures were presented as a new beginning and ending for electronci contracts, and users intuitively recognised they were neither a beginning nor an ending. Digital signatures were nothing, without a custom, and within a custom were shown to be more trouble than they were worth. Case in point: this is the reason why the digital signature on Ricardian Contracts is just cryptographic sugar: the intent is better shown by the server mounting the contract, by the issuer saying "I'm selling this contract", and by the system memorialising all these events in other signed records.
You might ask, why they are there, but I'll side-step that question for now :) Instead, let us ask, how then do we move forward and use digital signatures?
We should be able to see now that it is the wrong question. The right question is firstly, how do we establish intent, and the follow-up is, intent of what? Attest to a statement, conclude a negotiation, sell a house, contract for a road to be dug up, marriage with or without a shotgun? Once we have established that, we can construct a custom (techies would say a protocol) that captures the intent _and_ the agreement, suitable for the value at hand.
We might find a way to slip in some digsigs or we might not. That's because the role is to capture intent, not the signature. Intent is obligatory, signature is not.
(Indeed, this is why we say, in financial cryptography, the cryptography is optional, which causes no end of head-scratching. What then does a poor vendor of cryptographic digsigs do with them? Simple: define the digsig as meaning nothing, legally, outside an additional custom. Nothing, nix, nada, zip! And use them purely for their cryptographic properties, only. Which happen to be useful enough, if properly designed.)
November 19, 2007
How to crack RSA
Adi Shamir is currently circulating a research note that looks like, on the face of it, a stunning piece of research. In short: how a powerful enemy can routinely and trivially crack RSA, and other public key algorithms. If found valid, this will again shake up the dusty world of cryptography in a way generally only seen every 5-10 years. The NYT report
Research Announcement: Microprocessor Bugs Can Be Security DisastersAdi Shamir
Computer Science Department
The Weizmann Institute of Science
IsraelWith the increasing word size and sophisticated optimizations of multiplication units in modern microprocessors, it becomes increasingly likely that they contain some undetected bugs. This was demonstrated by the accidental discovery of the obscure Pentium division bug in the mid 1990's, and by the recent discovery of a multiplication bug in the Microsoft Excel program. In this note we show that if some intelligence organization discovers (or secretly plants) even one pair of integers a and b whose product is computed incorrectly (even in a single low order bit) by a popular microprocessor, then ANY key in ANY RSA-based security program running on ANY one of the millions of PC's that contain this microprocessor can be trivially broken with a single chosen message. A similar attack can be applied to any security scheme based on discrete logs modulo a prime, and to any security scheme based on elliptic curves (in which we can also exploit division bugs), and thus almost all the presently deployed public key schemes will become vulnerable to such an attack.
Let's work it through: if an agency can pervert a maths processor in your standard CPU chip, it can also craft a single message that when processed (encrypted, signed, etc) will result in revealing to the attacker the entire key.
Assumption 1: an agency can pervert the modern CPUs. Such commodity hardware is mostly all created in American design studios, and we know that the chip manufacturers work closely with US intelligence agencies for special instructions, special spaces inside the chip, and no doubt other things. Conclusion: they are all ready working at that level so the only reasons that they haven't done it is that they chose not to, or they didn't think of it first.
Assumption 2: a message is processed, and the results are returned. Now, this means providing something to decrypt or encrypt, and seeing the both plaintext and ciphertext, *OR* presenting something to sign, and looking at the signature. The latter looks much more likely, as there is a basis for seeing both before and after texts (although, normally the signer can fudge the issue by firstly adding some random junk, and secondly hashing the message). Conclusion: it's not entirely clear what the vector of attack is here.
Either way, this is pretty big. What to do about it? Nothing today, as one thing is to bear in mind the caveat: until the cryptography community can comment on this, it is difficult for us non-cryptographers to really understand the scope and breadth. Indeed, the man I would have asked to explain this result is Adi Shamir himself, as he has an almost unique ability in the cryptography world to separate the interesting from the theoretical.
Meanwhile I suppose we start thinking of software designs for RSA. This would be like using a Virtual Machine, as in Java, Perl, Python, etc, where the software insulates against a rogue CPU's attempt to follow and pervert the higher layer semantics. Alternatively, we may now have found a reason to encourage open design cryptographic hardware.
September 15, 2007
Snake oil is snake oil?
An interesting debate emerged over on crypto list as to whether to chase down snake oil vendors and read them the good word until they beg for forgiveness. Then, a thing called IronKey stepped in as a exemplar or sinner or both:
On 12/09/07 08:56, Aram Perez wrote:
The IronKey appears to provide decent security while it is NOT plugged into a PC. But as soon as you plug it in and you have to enter a password to unlock it, the security level quickly drops. This would be the case even if they supported Mac OS or *nix.
So, is it snake oil? Here's my take. First, let's define terms:
I wrote:
So, is snake oil:
- a crap product?
- a fine product with weaknesses?
- a marketing campaign that goes OTT?
- a term used to slander the opposing security model?
- an adjective that applies to any of the above?
To which Hagai responds:
Just like any term, it can have many interpretations. However, the most useful definition is the one that you can find at http://en.wikipedia.org/wiki/Snake_oil_(cryptography) and which quite accurately reflects what the people who first brought this term into use used it for.
From which we find:
"used to describe commercial cryptographic methods and products which are considered bogus or fraudulent."
OK, so that means crap products, my first choice above, and indeed that might be the consensus of the commentators in the list. What distinguishes is that most people here seem to subscribe to the IronKey product as being ok, as a good product, but accept the exuberant marketing, and the potential weaknesses which are part and parcel of the product.
So, if a good product is clean, and the marketing is not, then the onus would apparently be on the commentators to (a) correctly distinguish good product from bad, and (b) describe this choice to the public.
My take: Good luck, guys.
It's not as if we have a good record here. Do we all remember the "snake oil signed certificates" which are now shown to be not snake oil, but *stronger* solutions than their counterpart, if used correctly? To stress this point, then, the wikipedia entry goes on to say:
Distinguishing secure cryptography from insecure cryptography can be difficult from the viewpoint of a user. Many cryptographers, such as Bruce Schneier and Phil Zimmermann, undertake to educate the public in how secure cryptography is done, as well as highlighting the misleading marketing of some cryptographic products.The Snake Oil FAQ describes itself as, "a compilation of common habits of snake oil vendors. It cannot be the sole method of rating a security product, since there can be exceptions to most of these rules. [...] But if you're looking at something that exhibits several warning signs, you're probably dealing with snake oil."
So, it points out its own weaknesses in definition. In other words, to pick a good product, it's a crap shoot, and maybe you need a famous "name" to tell you what's good or not.
Ouch. To play the devil's advocate here, I'm not sure that the average public can see the difference between overly exuberant marketing and a crap product.
Hence, there appears to be some merit in complaining about unprofessional marketing. Extending the snake oil term to it might be justified; It might be that the only tool we have left is professional and ethical marketing of security products.
Also, there is the normal discordance between weaknesses and, well, other weaknesses:
- IronKey doesn't protect when plugged in and decrypted. In that sense (threat model), neither does the SecureId token. The new threats are moving to the PC ... so we are definately in the area of comparing a partial, subvertible token to ... another partial, subvertible token.
- military-grade security means what? A field-grade cipher which can be generally weak, or a national-security cipher which shouldn't be? Actually, it probably means the latter in common usage, but the term itself is just bad.
- classical "snake-oil" (secret crypto, home-designs, one-time pads from PRNGs, etc) actually do provide reasonable coverage against today's other threat: having the laptop stolen, with or without the USB key. Almost all losses and thefts of this nature will be motivated by the hardware; what thief do you know who is going to muck around breaking kid-sister crypto?
What then can we conclude from all this? #1: If you are trying to apply a one-word claim to a complex product, then you are already lost. Snake oil may well itself be to sell snake oil.
Conclusion #2: the complexity would seem to indicate that any over-exuberant marketing is a bad thing. Perhaps they go hand in hand, so if you find yourself failing to understand the product being offered, then be skeptical.
And, also #3 reminded to us by Russ Nelson, who said:
"Remember, crypto without a threat model is like cookies without milk. ..... Cryptography without a threat model is like motherhood without apple pie. Can't say that enough times. More generally, security without a threat model is by definition going to fail."
I gather the first two comments are limited to the jurisdiction of the former colonies of King George III. The last however is spot on.
August 16, 2007
FUDWatch: NSA's shift to ECC, IESG lowers boom on cryptostrength, John Young on Fud versus Fud
The NSA is shifting to ECC. Old news, but here is some FUD:
Although RSA and Diffie-Hellman are both public-key algorithms, experts say they dont scale well for the future. To make RSA and Diffie-Hellman keys, which now can go to 1,024 bits, secure for the next 10 to 20 years, organizations would have to expand to key lengths of at least 2,048 bits, said Stephen Kent, chief scientist at BBN Technologies. Eventually, key sizes would need to expand to 4,096 bits. Thats enormous keys. To do the math operations underlying the keys takes longer and is more computationally intensive, Kent said.
Shock, horror, what are the men in shadows saying? It's total nonsense. If you can recall that 1024 was more or less a mid 1990s standard, and we're a decade++ on in Moore's Law terms, you also can see through this bureaucratic stupidity.

What's going on? It's not clear. Maybe the NSA is indeed concentrating on very low power devices such as mobile phones, which do not have the grunt to do long keys (because they use their Moore's Law bounty to buy battery power).
But for everyone else, 4k keys are find. There's no problem. Well, maybe one. Here's what the IESG said about OpenPGP:
Add to the end of section 15:* OpenPGP does not put limits on the size of RSA public keys. However, large keys are not necessarily good. Larger keys take more computation time to use, and this can quickly be unusable. Most OpenPGP implementations set an upper bound of 4096 bits in RSA public keys. Some have allowed 8K or 16K, which are large enough to have problems in many environments. If an implementation creates keys larger than 4096 bits, it will sacrifice interoperability with most other implementations.
Now, let's not name names, but these two statements are so at odds that one wonders what they are smoking at the IESG. What, you might ask, is really going on!?!?
Let's ask John Young. Here is a great article on him and the Cryptome. If you want to avoid getting on his shitlist, read this article today!

To Young, complaints about agents' safety is pure tradecraft. You can't argue with spies, because everything they say is a lie. Former covert operatives have told him as much, he says. "They say, 'Don't believe that, it's just standard fare. It's a ploy.' If you believe any of this, you don't understand how spies operate. They lie so much and run so many false operations and plant so many false agents. They expose their own agents so muchthere's nothing you can do that they haven't already done. In fact, they hope you will do it. To muddy the waters."
You didn't believe a word, right?
"There's a massive organization of hundreds of thousands of people around the world totally counting on secrecy," he says of the intelligence agencies he covers. "They are the most unreliable people in the world. And it's corrupted our culture. There's nothing that should be secret. Period."
Amen to that. I'll bet John Young uses 4k keys.
August 09, 2007
The Uneasy Ride on the Cryptography Bandwaggon
It is good to look beyond the basics and address the systemic aspects of failure. Neal Koblitz, who had something to do with the invention of ECC, describes in a forthcoming paper two bandwaggons that cryptographers have leaped on:
Koblitz describes two pernicious effects of this mixing of the two fields. One he calls the "bandwagon effect", in which mathematicians have distorted their research grant proposals in an effort to appeal to funding entities like the National Security Agency.The other is the effort by various cryptographers to add an aura of reliability to their cryptographic systems by claiming the systems are "provably" secure---that is, by claiming there exists an ironclad mathematical proof of the system's security. Koblitz and a colleague have written several papers critiquing claims of "provable security", and he describes the heated and sometimes bizarre reactions that greeted their critique.
We've seen both those. Certainly the first is widespread.
What makes the second so interesting is that it wouldn't work in any other field, it is so hard for someone to knock down, and the concept has done so much damage that we now also write papers about why this error is so prevalent. C.f., Pareto-secure was an attempt on my part to explain just where "probably-secure" takes us, positively, and where the limitations are.

And, no, there is no connection to the photo. I just want one and I'm not at CCC to steal one...
May 22, 2007
No such thing as provable security?
I have a lot of skepticism about the notion of provable security.
To some extent this is just efficient hubris -- I can't do it so it can't be any good. Call it chutzpah, if you like, but there's slightly more relevance to that than egotism, as, if I can't do it, it generally signals that businesses will have a lot of trouble dealing with it. Not because there aren't enough people better than me, but because, if those that can do it cannot explain it to me, then they haven't got much of a chance in explaining it to the average business.
Added to that, there have been a steady stream of "proofs" that have been broken, and "proven systems" that have been bypassed. If you look at it from a scientific investigative point of view, generally, the proof only works because the assumptions are so constrained that they eventually leave the realm of reality, and that's particularly dangerous to do in security work.
Added to all that: The ACM is awarding its Godel prize for a proof that there is no proof:
In a paper titled "Natural Proofs" originally presented at the 1994 ACM STOC, the authors found that a wide class of proof techniques cannot be used to resolve this challenge unless widely held conventions are violated. These conventions involve well-defined instructions for accomplishing a task that rely on generating a sequence of numbers (known as pseudo-random number generators). The authors' findings apply to computational problems used in cryptography, authentication, and access control. They show that other proof techniques need to be applied to address this basic, unresolved challenge.The findings of Razborov and Rudich, published in a journal paper entitled "Natural Proofs" in the Journal of Computer and System Sciences in 1997, address a problem that is widely considered the most important question in computing theory. It has been designated as one of seven Prize Problems by the Clay Mathematics Institute of Cambridge, Mass., which has allocated $1 million for solving each problem. It asks - if it is easy to check that a solution to a problem is correct, is it also easy to solve the problem? This problem is posed to determine whether questions exist whose answer can be quickly checked, but which require an impossibly long time to solve.
The paper proves that there is no so-called "Natural Proof" that certain computational problems often used in cryptography are hard to solve. Such cryptographic methods are critical to electronic commerce, and though these methods are widely thought to be unbreakable, the findings imply that there are no Natural Proofs for their security.
If so, this can count as a plus point for risk management, and a minus point for the school of no-risk security. However hard you try, any system you put in place will have some chances of falling flat on its face. Deal with it; the savvy financial cryptographer puts in place a strong system, then moves on to addressing what happens when it breaks.
The "Natural Proofs" result certainly matches my skepticism, but I guess we'll have to wait for the serious mathematicians to prove that it isn't so ... perhaps by proving that it is not possible to prove that there is no proof?
May 03, 2007
Hal Finney on 'AACS and Processing Key'
Hal Finney posts an explanation of the AACS movie encryption scheme. This FC scheme has just been cracked, and the primary keys published, to much media and legal attention. As digital rights management is a core financial cryptography application, it's worth recording the technology story as a case study, even if the detail is overwhelming!
Since this is the cryptography mailing list, there might be interest in the cryptography behind this infamous key. This is from AACSLA Specifications page, particularly the first spec, Common Cryptographic Elements. The basic cryptography is from Naor, Naor and Lotspiech.
The AACS system implements broadcast encryption. This is a scheme which has also been used for satellite TV. The idea is that you want to encrypt data such that any of a large number of devices can decrypt it, with also the possibility of efficiently revoking the keys in a relatively small subset of devices. The revocation is in case attackers manage to extract keys from devices and use them to decrypt data without authorization.
Broadcast encryption schemes such as that used by AACS equip each device with a set of keys, and encrypt a content key to various subsets of these keys such that each authorized device can decrypt the content key but the revoked devices cannot. Various methods have been proposed for achieving this, with tradeoffs between the number of keys held by each device and the amount of data which must be broadcast to hold all of the necessary encryptions.
AACS uses a binary tree based method, where each device corresponds to the leaf node of a tree. It uses a tree with depth of 31, so there are 2^31 leaf nodes and 2^32 - 1 nodes in all. At this point it is believed that software players of a particular type are all considered a single device, while hardware players are each a unique device. This will allow individual hardware players to be revoked, while requiring all software players of a given brand or type to be revoked at once. This tradeoff is assumed to be acceptable because it is easy to get a new version of a software player.
The method of assigning and handling the keys is called subset-difference. It allows a single encryption to be decrypted by any of the devices in a given subtree of the main tree, minus any sub-subtree of that subtree. In this way, any set of revoked nodes can be handled by the union of an appropriate chosen set of subset-difference encryptions. For example, suppose two nodes A and B are to be revoked. Let A be to the left of B, and call their lowest common ancestor node C. Encrypt to the whole tree minus the subtree rooted at C; also to C's left child's subtree minus A; also to C's right child's subtree minus B. This will cover all nodes except A and B.
To implement subset-difference, the root node of each subtree is assigned a unique key called a device key. Then going down the subtree from that node, each node gets its own device key as a distinct one-way hash of its parent's device key. The result is that if you know a node's device key, you can deduce the device keys of all descendants of that node.
This assignment of keys is carried out independently for each subtree, so a node at level n has n+1 device keys associated with it, one for each of the n+1 subtrees that it is a part of.
Leaf nodes correspond to devices, but devices do not get the device keys for "their" leaf node. Instead, they are given the device keys of the sibling node of their leaf, as well as the device keys of all of the siblings of their ancestor nodes. Because knowing a device key allows deducing the device keys of all its descendents, this assignment allows each physical device to deduce all device keys in the tree except for their "ancestor" nodes: those on the one branch of the tree leading to the leaf node.
To implement subset-difference encryption, suppose we want to encrypt to all nodes in the subtree rooted at node A except those nodes in the sub-subtree rooted at node B. Then we encrypt to the device key of node B that was assigned as part of the device key system rooted at node A. All nodes in the node-A subtree except those below node B can deduce this device key, because B is not one of their ancestors. Nodes below B cannot deduce the device key because B is an ancestor, and nodes not below A cannot deduce it because this set of device keys was unique to the node-A subtree.
In order to get the system started, one node is considered pre-revoked and not assigned to any physical device. Initially, the data is encrypted to the device key assigned to that node as part of the system for the whole tree. Every device will be able to deduce that device key and decrypt the data.
That one key is the "processing key" about which so much fuss is being made. All HD-DVD disks that were initially produced have their content keys encrypted to that single key. Knowing this processing key, along with other information available from the disk, allows determining all necessary decryption keys and provides access to the plaintext of the content. With this value having been published, all of the first generation of HD-DVD disks can be played.
The interesting thing is that publishing a processing key like this does not provide much information about which device was cracked in order to extract the key. This might leave AACSLA in a quandary about what to revoke in order to fix the problem. However in this particular case the attackers made little attempt to conceal their efforts and it was clear which software player(s) were being used. This may not be the case in the future.
AACSLA has announced that they will be changing the processing keys used in disks which will begin to be released shortly. Software players have been updated with new device keys, indicating that the old ones will be revoked. In the context of the subset-difference algorithm, there will now probably be a few encryptions necessary to cover the whole tree while revoking the old software player nodes as well as the pre-revoked node. This will make the processing key which has been published useless for decrypting new disks.
Because processing keys do not unambiguously point to their source, AACSLA may choose to set up subset-difference encryptions in which each software player is part of a different subtree and therefore uses a different processing key. This might require a few more encryptions than the minimal number that subset-difference allows, but it would reduce the chance that AACSLA would find themselves unable to determine the source of a published processing key. This will only work as long as attackers restrict themselves to the relatively few software players. If some group were to succeed in extracting keys from a hardware player and publish a processing key that might apply to the majority of hardware players in use, AACSLA would seemingly have no way to determine how to address the problem.
Now I must confess that this already long message has oversimplified the AACS system in certain respects. First, the subset-difference system is only carried on for the lowest 22 levels of the 31 level tree. There are effectively 512 independent trees where the algorithm is applied, each with a single pre-revoked leaf node. However at this time it appears that only one is in use.
Second, the processing key is not actually the same as the node's device key, but rather is a hash of the device key. Further, the exact details of how you go from the processing key to the various disk content keys involve several levels of indirection and encryption.
Third, even given the processing key, some of the information needed to derive all of the disk's content is not easily available. One piece needed is a per-title Volume ID which is not readable from the disk in a straightforward way. Volume IDs have been discovered by eavesdropping on the USB bus connected to a disk player, or by hacking disk player firmware. At this point it is hard for typical end users to read Volume IDs, so knowing the processing key is not generally sufficient to read disks. Databases of Volume IDs have been published online, but disk media keys could just as easily have been published.
Speculating now, the AACS system is flexible but it is possible that publication of processing keys may not have been fully anticipated by the designers. The difficulty of tracing processing keys to their source in an environment in which new disks may require many weeks or even months of lead time may interfere with the planned revocation system. The current processing key will soon be rendered invalid for new releases, so AACSLA's aggressive legal tactics seem disproportionate compared to the relative unimportance of this particular key. Perhaps these legal actions are primarily intended to limit distribution of future processing keys that are found on the next set of disk releases. That would further point to technical difficulties in revocation strategy when a new processing
key is published.
Hal Finney
January 25, 2007
NIST Competition to create new Hash algorithm
Buzzing around the cryptosphere for the last few years has been the name that hashes fear: Wang. The allegedly mild and timid Professor Wang has destroyed all hashes up to SHA1 itself (prior posts in FC) and even that bulwark of western cryptography has wobbled at her attack. Here's a somewhat stylised and inaccurate portrait published in China
Now, NIST have announced:
Due to recent attacks on the SHA-1 hash function specified in FIPS 180-2 , Secure Hash Standard, NIST is initiating an effort to develop one or more additional hash algorithms through a public competition, similar to the development process for the Advanced Encryption Standard (AES). Two workshops (see menu at left) have been held to assess the status of the NIST-approved hash functions, to discuss possible near- and long-term options, and to discuss hash function research in preparation for launching such a competition. In addition, NIST has published its policy on the use of the current hash functions, and has proposed a tentative timeline for the competition.As a first step in initiating the competition, NIST is publishing draft minimum acceptability requirements, submission requirements, and evaluation criteria [Federal Register Notice (January 23, 2007)] for candidate hash algorithms, and public comment is requested.
Let the party begin! You have until 3Q 2008 to submit your design. If the AES experience is anything to go by, that's not a lot of time.
What's all this about then? Some background. When these oriental broadsides first started lobbying in, many thought a crypto competition would be just the shot. The AES competition, to develop a new secret key cipher, was one of the greatest cryptological parties of the late 90s. Everyone and his dog submitted an algorithm; my buddies in the Cryptix group provided the Java framework.
The winner, Rijndael, is now standardised as AES for Advanced Encryption Standard, and it is stronger for its world-wide scrutiny (but note that I stuck my neck out and predicted a shock ...).
When it came to hashes, however, NIST instead contracted for the creation of extensions to SHA1. These are SHA256, SHA512, etc, algorithms released around the same time as the AES competition.
Longer, bigger, better, or so they claimed. NIST knew their hashes:
- Hash algorithms don't exactly collapse when challenged, as they are part of wider systems;
- the breaks were only effective against unpredicted collisions, that is, we cannot attack an existing hash.
- Even if you find a break, it is still not clear how to exploit it for money.
- We (in higher layers of FC) simply don't need the hash to be as strong as a castle, whereas we absolutely need the encryption algorithm to be as strong and stronger even than any castle.
Fair enough! On the one hand, NIST stuck with the aged MD4 design and expanded it. Economically sensible. But on the other hand, Prof Wang continued her work undaunted, and the foundations kept getting weaker. Although there is no "big problem" with industry, there is a "big problem" with the theory of cryptography, and that's embarrassing.
What does this mean for the rest of us, those who are users cryptography? Well, hash agility is here to stay. What that means is that your designs and protocols need to be able to shift: first to SHA256, etc, and then later on to NewSHA. This has fairly nasty implications all through software and within security itself; something I encapsulate within a hypothesis (#1): The One True Crypto Suite. I'll have to write that up some time.
Beyond pain for software developers, it represents excitement for cryptologers, no more.
And, because you read this blog, let's close with this comment from the timeline:
A tentative timeline for developing the new hash functions was presented, and discussed at length, at the Second Cryptographic Hash Workshop held on August 24-25, 2006 at UCSB. At the workshop, there seemed to be a pretty strong sense that, although the general theory and understanding of hash functions leaves a lot to be desired, and is not as good as our understanding of block ciphers when NIST started the AES competition, it's still better to get on with the competition, rather than to keep refining our understanding to identify the precise selection criteria for the competition. Based on this public feedback, NIST has decided to start the process sooner, and has adjusted the timeline accordingly.
That's the spirit!
November 22, 2006
CFP: 6W on the Economics of Information Security (WEIS 2007)
The Heinz School, Carnegie Mellon University Pittsburgh (PA), USA
June 7-8, 2007
http://weis2007.econinfosec.org/
C A L L F O R P A P E R S
Submissions due: March 1, 2007
How much should we spend on security? What incentives really drive privacy decisions? What are the trade-offs that individuals, firms, and governments face when allocating resources to protect data assets? Are there good ways to distribute risks and align goals when securing information systems?
The 2007 Workshop on the Economics of Information Security builds on the success of the previous five Workshops and invites original research papers on topics related to the economics of information security and the economics of privacy. Security and privacy threats rarely have purely technical causes. Economic, behavioral, and legal factors often contribute as much as technology to the dependability of information and information systems. Until recently, research in security and dependability focused almost exclusively on technical factors, rather than incentives. The application of economic analysis to these problems has now become an exciting and fruitful area of research.
We encourage economists, computer scientists, business school researchers, law scholars, security and privacy specialists, as well as industry experts to submit their research and attend the Workshop. Suggested topics include (but are not limited to) empirical and theoretical economic studies of:
- Optimal security investment
- Software and system dependability
- Privacy, confidentiality, and anonymity
- Vulnerabilities, patching, and disclosure
- DRM and trusted computing
- Trust and reputation systems
- Security models and metrics
- Behavioral security and privacy
- Information systems liability and insurance
- Information threat modeling and risk management
- Phishing and spam
**Important dates**
- Submissions due: March 1, 2007
- Notification of acceptance: April 10, 2007
- Workshop: June 7-8, 2007
For more information visit http://weis2007.econinfosec.org/.
November 18, 2006
The Grnch writes: "Am I supposed to trust your opinion on cryptography?"
Sometimes comments just have to be shared. Someone called "Grnch" wrote:
I just stumbled across this site, and I'm trying to decide if it's worth my time. You purport to be some kind of expert on cryptography, yet you are unable to even configure SSL (https) properly for your site, and even worse, you seem to have no clue when it actually makes sense to use cryptography at all.In other words, I access this site through the www.financialcryptography.com domain with a regular non-encrypted connection, yet my browser pops up an invalid certificate for www2.futureware.at?
First, if you need to have secure connections to your site for some reason, get a properly signed certificate for your proper domain.
Second, I looked at your source to see what on earth you need secure connections for, and it's only for the god damn stylesheet. Who the hell uses a normal connection for the content, yet an encrypted one for the stylesheet? It only causes an "invalid certificate" pop-up each time I open your site, with no discernible benefit whatsoever.
And I'm supposed to trust your opinion on security and cryptography issues?
The content does seem interesting to be sure, but this level of cryptography misuse is simply pathetic, and casts a huge shadow on your credibility.
October 18, 2006
Evils of Crypto Buzzword Plague -- AES is Pareto-secure but ECB is not
One of the points behind Pareto-secure, if not *the* point (disagree here), is that only a few components ever achieve the strength to be rated Pareto-secure or even Pareto-complete. In short, that means they are so good that you don't need to worry about them in your design within your context (Pareto-secure) or even forever, in any reasonable scenario (Pareto-complete).
The headline component for this treatment is today's encryption algorithms. AES and the like are so strong we don't need to worry about them. But the corollary is that the protocols we use them in are nowhere near so secure, and our faith in Pareto-secure components has to be very carefully contained.
That extends to "modes," being those short protocols to create streams out of blocks. Which brings us to this very nice description from Mark Pustilnik of how short the distance between "strong" and "ridiculous" is with cipher modes.

Figure 2a Plaintext

Figure 2b ECB Encryption

Figure 2c CBC Encryption
Just spotted, another excellent exposition of mathematics in pictures on Nick Szabo's site.
August 25, 2006
SHA1 weakened further in new attacks
The move away from SHA1 gained momentum:
Researchers of the Krypto group of the IAIK succeeded in constructing a collision for a simplified variant of the standard hash function SHA-1. The simplified variant differs from the standard only in the number of iterations of the step functions that is used: 64 instead of 80. The previously best result was a collision for a variant with 58 iterations, first shown by Wang et al. in 2005.
Heise was first to report (in German and now on their English site) about what I guess is their paper presented at Crypto2006.
If you are wondering just where we are on SHA-1 usage and a replacement, CAcert have a page on compatibility of various certificate based distros to SHA-256 and SHA-512. All CAs are at the mercy of the application distributors to keep up with security developments.
It's not looking good for a move from SHA-1 just yet for certificates... People who didn't take account of the now 2-year-old presentations by Prof Wang include those still on OpenSSL 0.9.7 (FreeBSD, NetBSD, Apple Mac OSX, and OpenBSD themselves!). A rare black mark for the BSD family.
I'll adjust this post as more comes in, and bear in mind that it will take days for the paper to be analysed and summarised. Also note that this time last year, Wang and friends presented a 63 bit attack, and some observers jumped the gun to say it was "broken" .... the message is still the same, SHA-1 is no longer Pareto-complete, which means you have to now analyse whether it suits your application, you can't simply assume it is good for all applications.
July 23, 2006
Case Study: Thunderbird's brittle security as proof of Iang's 3rd Hypothesis in secure design: there is only one mode, and it's secure.
In talking with Hagai, it was suggested that I try using the TLS/IMAP capabilities of Thunderbird, which I turned on (it's been a year or two since the last time I tried it). Unfortunately, nothing happened. Nothing positive, nothing negative. Cue in here a long debate about whether it was working or not, and how there should be a status display, at least, and various other remedies, at most.
A week later, the cleaning lady came in and cleaned up my desk. This process, for her, also involves unpowering the machine. Darn, normally I leave it on for ever, like a couple of months or so.
On restarting everything, Thunderbird could not connect to the mail servers. Our earlier mystery is thus resolved - the settings don't take effect until restart. Doh!
So, how then did Thunderbird handle? Not so well, but it may have got there in the end. This gives me a change to do a sort of case study in 1990s design weaknesses, a critique in (un)usability, leading to design principles updated for this decade.
To predict the punch line, the big result is that there should only be one mode, and it should be secure. To get there more slowly, here's what I observed:
Firstly, Thunderbird grumbled about the certificate being in the wrong name. I got my negative signal, and I knew that there was something working! Hooray!
But, then it turned out that Thunderbird still could not connect, because "You have chosen secure authentication, but this server does not offer it. Therefore you cannot log in..." Or somesuch. Then I had to go find that option and turn it off. This had to be done for all mail accounts, one by one.
Then it worked. Well, I *guess* it did... because funnily enough it already had the mail, and again had not evidenced any difference.
Let's break this up into point form. Further, let's also assume that all competing products to be as bad or worse. I actually *choose* Thunderbird as my preferred email client, over say Kmail. So it's not as bad as it sounds; I'm not "abandoning Thunderbird", I'm just not getting much security benefit from it, and I'm not recommending it to others for security purposes.
- No caching of certs. There is no ability to say "Yes, use that cert for ever, I do know that the ISP is not the same name as my domain name, dammit!!!!" This is an old debate; in the PKI world, they do not subscribe to the theory that the user knows more than any CA about her ISP. One demerit for flat earth fantasies.
- No display anywhere that tells me what the status of the security is. One demerit. (Keep in mind that this will only be useful for us "qualified cryptoplumbers" who know what the display means.)
- I can choose "secure authentication" and I can choose "secure connection." As a dumb user, I have no idea what that means, either of them. One demerit.
- If I choose one of those ON, and it is not available, it works. Until it doesn't -- it won't connect at some later time and it tells me to turn it off. So as a user I have a confusing choice of several options, but ramifications that do not become clear until later.
Another demerit: multiple options with no clear relationship, but unfortunate consequences.
- Once it goes wrong, I have to navigate from a popup telling me something strange, across to a a series of boxes in some other strange area, and turn off the exact setting that I was told to, if I can remember what was on the popup. Another demerit.
- All this took about 5 minutes. It took longer to do the setting up of some security options than it takes to download, install, and initiate an encrypted VoIP call over Skype with someone who has *never used Skype before*. I know that because the previous night I had two newbies going with Skype in 3 minutes each, just by talking them through it via some other chat program.
- Normal users will probably turn it all off, as they won't understand what's really happening, and "I need my mail, darnit!"
(So, we now start to see what "need" means when used by users... it means "I need my email and I'll switch the darned security rubbish off and/or move to another system / supplier / etc.)
- This system is *only useable by computer experts.* The only reason I was able to "quickly" sort this out was because I knew (as an experienced cryptoplumber) exactly what it was trying to do. I know that TLS requires a cert over the other end, *and* there is a potential client-side cert. But without that knowledge, a user would be lost. TLS security as delivered here is a system is not really up to use by ordinary people - hence "brittle."
We can conclude that this is a nightmare in terms of:
- usability.
- implementation.
- design.
- standards.
Let's put this in context: when this system was designed, we didn't have the knowledge we have now. Thunderbird's security concept is at least 3 years old, probably 8-10 years old. Since those years have passed, we've got phishing, usability studies, opportunistic crypto, successful user-level cryptoapps (two, now), and a large body of research that tells us how to do it properly.
We know way more than we did 3 years ago - which was when I started on phishing. (FTR, I suggested visit counts! How hokey!)
Having got the apologies off our chest, let's get to the serious slamming: If you look at any minor mods to the Thunderbird TLS-based security, like an extra popup, or extra info or displays, you still end up with a mess. E.g., Hagai suggested that there should be an icon to display what is going on - but that only helps *me* being an experience user who knows exactly what it is trying to tell me. I know what is meant by 'secure authentication' but if you ask grandma, she'll offer you some carrot cake and say "yes, dear. now have some of this, I grew the carrots myself!"
(And, in so doing, she'll prove herself wiser than any of us. And she grows carrots!)
Pigs cannot be improved by putting them in dresses - this security system is a pig and won't be improved by frills.
The *design* is completely backwards, and all it serves to do is frustrate the use of the system. The PKI view is that the architecture is in place for good reasons, and therefore the user should be instructed and led along that system path. Hence,
"We need to educate the users better."
That is a truly utterly disastrous recommendation. No! Firstly, the system is wrong, for reasons that we can skip today. Secondly, the technical choices being offered to the users are beyond their capabilities. This can never be "educated." Thirdly, it's a totally inefficient use of the user's time. Fourthly, the end effect is that most users will not ever get the benefit.
(That would be a mighty fine survey -- how many users get the benefit of TLS security in Thunderbird? If it is less than 10%, that's a failure.)
The system should be reversed in logic. It should automatically achieve what it can achieve and then simply display somewhere how far it got:
- Try for the best, which might be secure auth, and then click into that. Display "Secure Auth" if it got that far.
- If that fails, then, fallback to second best: try the "Secure Conn" mode, and display that on success.
- Or finally, fall back to password mode, and display "Password only. Sorry."
The buttons to turn these modes on are totally unneccessary. We have computers to figure that sort of nonsense out.
Even the above is not the best way. Fallback modes are difficult to get right. They are very expensive, brittle even. (But, they are better - far far far cheaper - than asking the user to make those choices.) There is still one way to improve on this!
Hence, after 5 demerits and a handful of higher-level critiques, we get to the punchline:
To improve, there should only be one mode. And that mode is secure. There should be only one mode, because that means you can eliminate the fallback code. Code that falls back is probably twice as large as code that does not fallback. Twice as brittle, four times as many customer complaints. I speak from experience...
The principle, which I call my 3rd Hypothesis in Secure Protocol Design, reads like this:
There is only one mode, and it is secure.
If you compare and contrast that principle with all the above, you'll find that all the above bugs magically disappear. In fact, a whole lot of your life suddenly becomes much better.
Now, again, let's drag in some wider context. It is interesting that email can never ever get away from the fact that it will always have this sucky insecure mode. Several of them, indeed. So we may never get away from fallbacks, for email at least.
That unfortunate legacy should be considered as the reality that clashes with the Hypothesis. It is email that breaches the Hypothesis, and it and all of us suffer for it.
There is no use bemoaning the historical disaster that is email. But: new designs can and will get it right. Skype has adopted this Hypothesis, and it took over - it owns VoIP space in part because it delivered security without the cost. SSH did exactly the same, before.
In time, other communication designs such as for IM/chat and emerging methods will adopt Hypothesis #3, and they will compete with Skype. Some of the mail systems (Start/TLS ?) have also adopted it, and where they do, they do very well, allegedly.
(Nobody can compete with SSH, because we only need one open source product there - the task is so well defined there isn't any room for innovation. Well, that's not exactly true - there are at least two innovations coming down the pipeline that I know of but they both embrace and extend. But that's topic drift.)
June 27, 2006
It's official! SSH whips HTTPS butt! (in small minor test of no import....)
Finally some figures! We've known for a decade that the SSH model consumes all in its path. What we haven't known is relative quantities. Seen somewhere on the net, this week's report shows Encrypted Traffic. In SSH form: 3.42% In HTTPS form: 1.11%, by volume. For number of packets, it is 3.51 and 1.67 respectively.
| SSH | 3.42% | 17.45T | 3.51% | 20.98% |
|---|---|---|---|---|
| HTTPS | 1.11% | 5.677T | 1.67% | 10.00G |
| IPsec ESP | 0.14% | 0.697T | 0.21% | 1.211G |
| IPsec AH | 0.01% | 0.054G | 0.01$ | 0.089G |
| IPsec IKE | 0.00% | 0.001G | 0.00% | 0.006G |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Approximately a three times domination which is our standard benchmark for a good whipping in military terms. Although this is not a pitched battle of like armies contesting the same space (like the VPN bloodletting to come) it is important to establish that SSH usage is significant, non trivial and exceeds HTTPS on all measures.
IPsec barely twitched the needle and others weren't reported. Curiously, the amount of HTTPS is way up compared to HTTP: about 7-8%. I would have expected much less, the many silent but resiliant readers of FC have more impact than previously thought.
There's one monster catch: this is "Internet 2" which is some weird funded different space, possibly as relevant to the real net as candy prices are to the economy. Also, no mention of Skype. Use of Rsync and FTP slightly exceeds that of all encrypted traffic. Hmmm.... people still use Rsync. What is wrong here? I have not come across an rsync user since ... since ... Any clues?
Still it's a number. Any number is good for an argument.
June 04, 2006
CryptoKids, education or propaganda, ECC, speed or agenda capture?
The NSA has a newish site for kids at http://www.nsa.gov/kids/ with a Flash download and a bunch of cartoon characters. It might be fun for kids interested in crypto. Of course it is imbued with current political policies or moralities of the Bush era, and there is a slamming over on Prison Planet.

I think quite mild really. Educating kids is relatively benign as long as they don't cross the line into propaganda. What is of more worry is the continued policy of organised and paid-for propaganda by western governments through all sorts of channels, domestic and foreign. This in my view is unacceptable. In a democratic nation, the people decide such questions and vote. In a dictatorship, the dictator decides and imposes by means of control of the media.
While we are on the subject, Philipp asked me why everyone keeps asking for 16k keys. Well, other than just being perverse in the normal crypto blah blah sense, there turns out to be a reason. I'll leave it to you to decide whether this is a good reason or not.
I discovered this browsing over on Mozo's site in pursuit of something or other. Mozilla are planning to introduce SNI - the trick needed to do SSL virtual hosting - in some near future, as are Microsoft and Opera. But also mentioned was that Mozilla are introducing elliptic curve cryptography, at least into their crypto suite 'NSS'.
ECC is an emerging cryptographic standard which can be used instead of the RSA algorithm. It uses smaller keys than RSA, which means it can be faster than RSA for the same level of cryptographic strength. The US Government is moving away from the RSA cryptosystem, and onto ECC, by the year 2010. See this page from the NSA for more information.
So jumping over to the always engaging NSA's pages on ECC:
... The following table gives the key sizes recommended by the National Institute of Standards and Technology to protect keys used in conventional encryption algorithms like the (DES) and (AES) together with the key sizes for RSA, Diffie-Hellman and elliptic curves that are needed to provide equivalent security.
Symmetric Key Size
(bits)RSA and Diffie-Hellman
Key Size (bits)Elliptic Curve Key Size
(bits)80 1024 160 112 2048 224 128 3072 256 192 7680 384 256 15360 521 Table 1: NIST Recommended Key Sizes To use RSA or Diffie-Hellman to protect 128-bit AES keys one should use 3072-bit parameters: three times the size in use throughout the Internet today. The equivalent key size for elliptic curves is only 256 bits. One can see that as symmetric key sizes increase the required key sizes for RSA and Diffie-Hellman increase at a much faster rate than the required key sizes for elliptic curve cryptosystems. Hence, elliptic curve systems offer more security per bit increase in key size than either RSA or Diffie-Hellman public key systems.
And, if you wish to use AES 256, then the NIST suggested length for RSA is 15360, or 16k in round numbers. The NSA also points out that the equivalent strengths in that area are computationally more expensive, perhaps 20 times as much.
Does all this matter? Not as much as one would think. Firstly, for financial cryptography, we are not so fussed about the NSA's ability to attack and crack our codes. So the Suite B standard is not so relevant, although it is an interesting sign post to what the NSA thinks is Pareto-secure (or more likely Pareto-complete) according to their calculations.
For protecting both classified and unclassified National Security information, the National Security Agency has decided to move to elliptic curve based public key cryptography. Where appropriate, NSA plans to use the elliptic curves over finite fields with large prime moduli (256, 384, and 521 bits) published by NIST.
And, we'd better not be worried about that, because when the NSA starts cracking the financial codes and sharing that data, all bets in modern democracy are off. The definition of a fascist state is that you are allowed to own stuff, but the government controls that ownership via total control of the financial apparatus. In financial cryptography, we're quite happy to deal with the 128 bit strength of the smaller AES, and 4k RSA keys or less, and rely on warnings about what's reasonable behaviour. It's called risk management.
Further, machines are fast and getting faster. Only at the margin is there an issue, and most big sites offload the crypto to hardware anyway, which perforce limits the crypto sizes to what the hardware can handle (notice how the NSA even agrees that we are still mucking around at 1k keys for the most part).
Literally, if you are worried about key sizes, you are worried about the wrong thing (completely, utterly). So it is important to understand that even though the browsers (IE7 as well, not sure about others) are moving to add ECC, and this involves sexy mathematics and we get to share beers and tall stories with the spooks, this development has nothing to do with us. Society, the Internet, the world at large. It is a strictly USG / NSA issue. In fact:
Despite the many advantages of elliptic curves and despite the adoption of elliptic curves by many users, many vendors and academics view the intellectual property environment surrounding elliptic curves as a major roadblock to their implementation and use. Various aspects of elliptic curve cryptography have been patented by a variety of people and companies around the world. Notably the Canadian company, Certicom Inc. holds over 130 patents related to elliptic curves and public key cryptography in general.As a way of clearing the way for the implementation of elliptic curves to protect US and allied government information, the National Security Agency purchased from Certicom a license that covers all of their intellectual property in a restricted field of use. The license would be limited to implementations that were for national security uses and certified under FIPS 140-2 or were approved by NSA. ... NSA's license includes a right to sublicense these 26 patents to vendors building products within the restricted field of use. Certicom also retained a right to license vendors both within the field of use and under other terms that they may negotiate with vendors.
Commercial vendors may receive a license from NSA provided their products fit within the field of use of NSA's license. Alternatively, commercial vendors may contact Certicom for a license for the same 26 patents. Certicom is planning on developing and selling software toolkits that implement elliptic curve cryptography in the field of use. With the toolkit a vendor will also receive a license from Certicom to sell the technology licensed by NSA in the general commercial marketplace. Vendors wishing to implement elliptic curves outside the scope of the NSA license will need to work with Certicom if they wish to be licensed.
The NSA is being quite proper and is disclosing it in full. If you didn't follow here it is: You can't use this stuff without a licence. The NSA has one for USG stuff. You don't.
The RSA algorithm and the related DH family now go head-to-head with a patented and licensed alternative. As a curious twist in fate, this time RSA and friends are on the other side. We fought this battle in the 90s, as the RSA patent was used as a lever to extract rents - that's the point of the patent - but also to roll out agendas and architectures that ultimately failed and ultimately cost society a huge amount of money. (Latest estimate for America is $2.7 bn per year and the UK is up to UKP800 mn. Thanks guys!)
The way I see it, there is no point in anyone using elliptic curve crypto. It could even be dangerous to you to do this - if it results in agendas being slipped in via licensing clauses that weaken your operations (as happened last time). I can't even see the point of the NSA doing it - they are going to have to pay through the nose to get people to touch this stuff - but one supposes they want this for on-the-margin hardware devices that have no bearing on the commercial hard reality of economics.
Indeed, somewhere it said that the Mozo code was donated by Sun. One hopes that these guys aren't trying too hard to foister another agenda nightmare on the net, as we still haven't unwound the last one.
Courts as Franchises - the origins of private law as peer-to-peer government
Over on Enumerated, Nick Szabo posts twice on the framework of the courts in anglo-norman history. He makes the surprising claim that up until the 19th century, the tradition was all of private courts. Franchises were established from the royal perogative, and once granted as charters, were generally inviolate. I.e., courts were property.
There were dozens of standard jurisdictional franchises. For example, "infangthief" enabled the franchise owner to hang any thief caught red-handed in the franchise territory, whereas "outfangthief" enabled the owner to chase the thief down outside the franchise territory, catch him red-handed, and then hang him. "Gallows" enabled the owner to try and punish any capital crime, and there were a variety of jurisdictions correponding to several classes of lesser offenses. "View of frankpledge" allowed the owner to control a local militia to enforce the law. "The sheriff's pleas" allowed the owner to hear any case that would normally be heard in a county court. There were also franchises that allowed the collection of various tolls and taxes.
A corporation was also a franchise, and corporations often held, as appurtenances, jurisdictional franchises. The City of London was and is a corporate franchise. In the Counties Palatine the entire government was privately held, and most of the American Colonies were corporate franchises that held practically all jurisdiction in their territory, sometimes subject to reservations (such as the common law rights of English subjects and the right of the king to collect customs reserved in the American charters). The colonies could in turn grant franchises to local lords (as with the Courts Baron and Courts Leet in early Maryland) and municipalities. American constitutions are largely descended from such charters.
Consider the contrast with the European hierarchical view. Not property but master-servant dominated, as it were. And, some time in the 19th century the European hierarchical view won:
The Anglo-Norman legal idea of jurisdiction as property and peer-to-peer government clashed with ideas derived from the Roman Empire, via the text of Justinian's legal code and its elaboration in European universities, of sovereignty and totalitarian rule via a master-servant or delegation hierarchy. By the 20th century the Roman idea of hierarchical jurisdiction had largely won, especially in political science where government is often defined on neo-Roman terms as "sovereign" and "a monopoly of force." Our experience with totalitarianism of the 19th and 20th centuries, inspired and enabled by the Roman-derived procedural law and accompanying political structure (and including Napoleon, the Csars, the Kaisers, Communist despots, the Fascists, and the National Socialists), as well as the rise of vast and often oppressive bureaucracies in the "democratic" countries, should cause us to reconsider our commitment to government via master-servant (in modern terms, employer-employee) hierarchy, which is much bettter suited to military organization than to legal organization.
Why is that? Nick doesn't answer, but the correlation with the various wars is curious. In my own research into Free Banking I came to the conclusion that it was stronger than any other form, yet it was not strong enough to survive all-out war - and specifically the desires of the government and populace to enact extraordinary war powers. Which led to the annoying game theory result that central banking was stronger, as it could always pay the nation into total war. If we follow the same line in causality, Nick suggests that the hierarchical government is stronger because it can control the nation into total war. And, if we assume that any nation with these two will dominate, this explains why Free Banking and Franchise Law both fell in the end; and fell later in Britain.
May 01, 2006
Fido reads your mind
Fido is a maths puzzle (needs Flash, hopefully doesn't infect your machine) that seems counter-intiutive... Any mathematicians in the house? My sister wants to know...
In terms of presence, the site itself seems to be a web presence company that works with music media. Giving away fun things like that seems to work well - I wouln't have looked further if they had pumped their brand excessively.
April 20, 2006
Is Provenzano a Kindergarten Cryptographer?
I wasn't going to write about the crypto angle of Mafia Boss Bernardo Provenzano because it just seemed more popular science than serious financial cryptography. But the Mafia Boss needs some defence, not for his murders and brutalities for which I'm sure the Italians will do the right thing and incacerate him forever, but for the suggestion that he didn't know what he was doing.

He knew precisely what he was doing. First off, a report on the recent capture of the Mafia Boss of Bosses in Italy, copied from the cryptography list (edited for style):
It seems not everyone has gotten the message that monoalphabetic substitution was broken many hundreds of years ago. Excerpt:The recently arrested "boss of bosses" of the Sicilian Mafia, Bernardo Provenzano, wrote notes using an encryption scheme similar to the one used by Julius Caesar more than 2,000 years ago, according to a biography of Italy's most wanted man....
The article is interesting and well worth reading:
Also known as "Binnu u tratturi" (Binnu the tractor) because of his reputation for mowing down people in his youth, Provenzano had been on the run for more than 40 years, many of them spent writing cryptograms on little pieces of paper, known in Sicilian dialect as pizzini. The Italian police found about 350 pizzini in Provenzano's hideaway. A few dozen of these notes contained requests to his family, such as having lasagne on Easter. All the others, featuring orders to his lieutenants, displayed numeric sequences that concealed the names of people.
What's going on here? Why isn't he using better stuff? Indeed:
"Looks like kindergarten cryptography to me. It will keep your kid sister out, but it won't keep the police out. But what do you expect from someone who is computer illiterate?" security guru Bruce Schneier, author of several books on cryptography, told Discovery News.Indeed, no high-tech ran the Mafia network under Provenzano's rule. Top Mafia businesses were conducted on an obsolete Olivetti Lettera 32 typewriter. Pizzini were delivered by a chain of messengers. The fact that the boss code was rather straightforward may be explained by Provenzano's lack of education. It stopped when he dropped out of school at about eight.
Well, clearly the guy was a schmuck and could only just manage a manual typewriter ... but wait! There's one final clue. Back on the cryptography list, another post tries to analyse an older mafia case:
and a second data point, not everyone in the mafia chooses good passphrases;a few years ago the government got a black bag warrant (once and a renewal) to install some still undescribed keystroke monitoring technology on nicky scarfo jr's pc, to find out the pgp key of a spreadsheet of a smalltime mafioso whose hard drive they'd already taken a copy of.
it turned out to be his father's federal prison number.
The password was clearly good enough to force the Feds to go for the black bag operation, so it did its job. However, the real clue here is that because Scarfo put all his reliance in PGP, he was vulnerable to an attack on his PC. The PGP was perfect, the algorithm was uncrackable, but all that falls to dust the moment the feds get in and take over the machine. Your agent is perverted.
Which takes us back to Provenzano. He knew that the use of secure ciphers brought in a new risk - it makes him vulnerable to whoever knows more about the PC and the software than him. Which is numbered in the millions, when you come to think of it.
On the other hand, if he used pencil and paper, his risks sink right down: he knows and controls the pen and the paper. He can destroy the pen, and instruct recipients to eat the message. His only risks then are the delivery system and the recipient, both of which are securable with simple strategies.
Provenzano knew his threat model. It included his kid sister which explains the use of the simple codes. Obviously he didn't want the people in his household, nor his messengers, gaining too much information by reading the pizzini they might have found. His kid sister wasn't going to copy the pieces of paper because if she was caught with the evidence she'd become his ex-kid sister. But she could memorise names, and hence Provenzano used a simple code to futz with the memories of those around him.
Italians are noted for making simple things into works of art. Like a real italian pasta dish, Provenzano had a perfect understanding of his threat model. It worked for him for 40 years ... and even the occasional breach, as posted on the Internet, did not seriously impact his operation.
He may have been using kindergarten cryptography, but he was a maestro of security.
April 02, 2006
Thank Skype for not listening
A day rarely passes in the crypto community where people do not preach that you should use standard protocols for all your crypto work. Many systems have foundered on this advice, something I tried to explain in more depth in the GP rants. Thankfully, not Skype. They wrote the whole thing from scratch, and they did it well.
Arguably the worlds' most successful crypto application (with approximately 5 million people enjoying its protection right now) it had to run the gauntlet of full industry skepticism for doing the cryptoplumbing thing on its own.
I earlier wrote that even if they bungled the crypto protocol, they still did the right thing. Philipp pointed me at some work from a few months back that claims their protocols have been audited and are relatively A-OK. Even better!
The designers of Skype did not hesitate to employ cryptography widely and well in order to establish a foundation of trust, authenticity, and confidentiality for their peer-to-peer services. The implementers of Skype implemented the cryptographic functions correctly and efficiently. As a result, the confidentiality of a Skype session is far greater than that offered by a wired or wireless telephone call or by email and email attachments.
So wrote Tom Berson in "Skype Security Evaluation," a name I've not come across. His analysis is worth reading if you are into reading up on cryptoprotocols for fun and profit. Although he doesn't reveal the full story, he reveals enough to know what they are up to at the crypto level, making up somewhat for the absence of open source. Here's some observations on his observations, spiced up with two other researches listed below.
The nymous identity creation is more or less the same as SOX, with a CA layered over the top. That is, the client creates the key and registers it with a pseudonym at the central server. The CA then signs that key, presumably making a statement that the pseudonym is unique in the Skype space.
I'm not entirely sure the addition of the CA is worth the cost. Given what we know about petnaming and so forth, and the fact that it opens up the vulnerability of the TTP MITMs, this appears to be a weakspot in the protocol - if Skype are going to be listening, then this is where they are going to do it. The weakness was identified by the Blackhat presentation (see below) and the Blackhat guys also claim that it is possible to set up a separate net and trick users into that net - not good news if true, and an indictment on the use of CAs over more modern constructs if it can't stop a darknet.
The key exchange is not entirely described. Both sides exchange their certificates and can then encrypt and sign to each other. They exchange 128 random bits each and combine this into the shared key of 256 bits - makes sense given the other assumptions. Before that, however, they do this, which I did not understand the point of:
To protect against playback, the peers challenge each other with random 64-bit nonces, and respond by returning the challenge, modified in a standard way, and signed with the responders private signing key.
How can there be a replay unless both sides have clagged PRNGs and are generating the same 128 bit inputs each time? The effect of this is, AFAICS, to duplicate the key exchange process by exchanging nonces ... but then throw that useful key entropy away! If you can explain this, please do so.
The data stream is encrypted by XORing the sound onto the output of an AES algorithm running in a stream generation mode. I'm not sure why this is done. My first guess is that any data corruption is self-correcting; a useful property in phones as you can just drop the bad data. But checksums over the packets seem to also cover that. Alternatively, it might be that it results in rather small amounts of packet expansion. (My own efforts at SDP1, with Zooko, resulted in significant expansion of packets, something I find annoying, but acceptable.) (I should note that the cryptophone.de design XORs the sound with *two* cipher streams, in case one is considered dodgy.)
Other plus points - the Skype engineers wisely chose their own key formats, a device that pays of by reducing the amount of code needed dramatically, and reduces dependencies on outside formats like x.509 and ASN1. Minus points appear to be in the complexity of the use of TCP and UDP, and a lot of duplicated packet flows. This is brought out more in the other presentations though.
In closing, Tom writes:
4. The Bottom Line
I started as a skeptic. I thought the system would be easy to defeat. However, my confidence in the Skype grows daily. The more I find out about it, the more I like.In 1998 I observed that cryptography was changing from expensive to cheap, from arcane to usual, from difficult to easy, from scarce to abundant. My colleagues and I tried to predict what difference, if any, abundant cryptography might make in the world. What new forms of engineering, business, economics, or society would be possible? We did not predict Skype. But, now that I am coming to know it well, I recognize that Skype is an early example of what abundant cryptography can yield.
I don't think it is quite that rosy, but it is on the whole good.
Juicy and more Skeptical Addendums:
- Some reverse engineering of the wider protocol shows many UDP and TCP dataflows: Philippe BIONDI Fabrice DESCLAUX, " Silver Needle in the Skype." Blackhat Europe, 2-3 March, 2006
- Some reverse engineering of the obfuscated client including 2 weaknesses in the protocol: Salman A. Baset and Henning Schulzrinne, "An Analysis of the Skype Peer-to-Peer Internet Telephony Protocol." Columbia University working paper? 2004.
March 14, 2006
NIST opens new DSA format for comments
In what looks like a surprise announcement, NIST has published a request-for-comments on a new Digital Signature Algorithm that expands the hash size to the newer SHA-2 family.
March 13, 2006: Draft Federal Information Processing Standard (FIPS) 186-3 - Digital Signature Standard (DSS)Draft FIPS 186-3 is the proposed revision of FIPS 186-2. The draft defines methods for digital signature generation that can be used for the protection of messages, and for the verification and validation of those digital signatures. Three techniques are allowed: DSA, RSA and ECDSA. This draft includes requirements for obtaining the assurances necessary for valid digital signatures. Methods for obtaining these assurances are provided in Draft NIST Special Publication 800-89, Recommendation for Obtaining Assurances for Digital Signature Applications. (see write-up for draft SP 800-89 below)
David Shaw notes the larger sizes:
In the OpenPGP context, probably the most interesting bit is that the 160-bit hash limit has been removed. The sizes supported are:
- 1024-bit key, 160-bit hash (the current DSA)
- 2048-bit key, 224-bit hash (presumably aimed at SHA-224)
- 2048-bit key, 256-bit hash (presumably aimed at SHA-256)
- 3072-bit key, 256-bit hash (presumably aimed at SHA-256)
It also adds the concept of using a larger hash than will fit by taking the leftmost bits.
More later ...
January 07, 2006
RSA comes clean: MITM on the rise, Hardware Tokens don't cut it, Certificate Model to be Replaced!
In a 2005 document entitled Trends and Attitudes in Information Security that someone sent to me, RSA Security, perhaps the major company in the security world today, surveys users in 4 of the largest markets and finds that most know about identity theft, and most are somewhat scared of ecommerce today. (But growth continues, so it is not all doom and gloom.)

This is an important document so I'll walk through it, and I hope you can bear with me until we get to the important part. As we all know all about identity theft, we can skip to the end of that part. RSA concludes its longish discussion on identity theft with this gem:
ConclusionConsumers are, in many respects, their own worst enemies. Constantly opening new accounts and providing personal information puts them at risk. Ally this to the naturally trusting nature of people and it is easy to see why Man-in-the-middle attacks are becoming increasingly prevalent. The next section of this e-Book takes a closer look at these attacks and considers how authentication tokens can be a significant preventative.
Don't forget to blame the users! Leaving that aside, we now know that MITM is the threat of choice for discerning security companies, and it's on the rise. I thought that last sentance above was predicting a routine advertisement for RSA tokens, which famously do not cover the dynamic or live MITM. But I was wrong, as we head into what amounts to an analysis of the MITM:
9. Offline [sic] Man-in-the-Middle attackWith online phishing, the victim receives the bogus e-mail and clicks through to the falsified Web site. However, instead of merely collecting rapidly changing passwords and contact information, the attacker now inserts himself in the middle of an online transaction stream. The attacker asks for and intercepts the users short-time-window, onetime password and stealthily initiates a session with the legitimate site, posing as the victim and using the victims just-intercepted ID and OTP.
Phishing is the MITM. More importantly, the hardware tokens that are the current rage will not stop the realtime attack, that which RSA calls "online phishing." That's a significant admission, as the RSA tokens have a lot to do with their current success (read: stock price). The document does not mention the RSA product by name, but that's an understandable omission.
Maybe, your pick.... But let's get back to reading this blurb. Here comes the important part! Heads up!
 | The need for site verification |
Read it again. And again, below, so you don't think I make this shit up. RSA Security is saying we need a site verification system, and not mentioning the one that's already there!

SSL and certificates and the secure browsing system are now persona non gratis, never to be mentioned again in corporate documents. The history book of security is being rewritten to remove reference to a decade or so of Internet lore and culture. Last time such a breathtaking revision occurred was when Pope Gregory XIII deleted 10 days from the calendar and caused riots in the streets by people wanting their birthdays back. (Speaking of which, did anyone see the extra second in the new year? I missed it, darn it. What was it like?)
So, what now? I have my qualms about a company that sells a solution in one decade, makes out like bandits, and then gets stuck into the next decade selling another solution for the same problem. I wrote recently about how one can trust a security project more when it admits a mistake than when it covers it up or denies its existance.
But ones trust or otherwise of RSA Security's motives or security wisdom is not at issue, except for those stock price analysts who hadn't figured it out before now. The important issue here for the Internet community is that when RSA admits, by default or by revisionism, that the certificates in the secure browsing model need to be replaced, that's big news.
This is another blackbird moment. RSA wrote the rule book when it came to PKI and certificates. They were right in the thick of the great ecommerce wars of 1994-1995. And now, they are effectively withdrawing from that market. Why? It's had a decade to prove itself and hasn't. Simple. Some time soon, the rest of the world will actually admit it too, so better be ahead of the curve, one supposes.
Get the message out - RSA has dumped the cert. We still have to live with it, though, so there is still lots of work to be done. Hundreds of companies are out there pushing certificates. Thousands of developers believe that these things work as is! A half-billion or so browsers carry the code base.
Without wishing to undermine the importance of RSA Security's switch in strategy, they do go too far. All that certificate code base can now be re-factored and re-used for newer, more effective security models. I'll leave you with this quasi-recognition that RSA is searching for that safe answer. They're looking right at it, but not seeing it, yet.
Browser plug-inWith this method, a locally resident browser plug-in cryptographically binds the one-time password (or challenge-response) to the legitimate sitei.e., the actual URL, rather than the claimed site name. This means that the password is good only for the legitimate site being visited.
This is an implicit level of site verification and is a far better approach than token-based host authentication and can prevent man-in-the-middle attacks. There are drawbacks and vulnerabilities, however. First, a browser plug-in presents all of the attendant issues of client software: it must be successfully loaded by the customer and updated, supported, and maintained by the site host. And, if the PC has been compromised through some form of co-resident malware, it remains vulnerable to subsequent exploitation.
Huh. So what they are saying is "we see good work done in plugins. But we don't see how we can help?" Well, maybe. I'd suggest RSA Security could actually do good work by picking up something like Trustbar and re-branding it. As Trustbar has already reworked the certificate model to address phishing, this provides the comfortable compromise that RSA Security needs to avoid the really hard questions. Strategically, it has everything a security company could ever want, especially one cornered by its past.
I said that was the last, but I can't resist one more snippet. Notice who else is dropped from the lexicon:
In the end, trust is a human affair and the right technology foundations can create a much stronger basis for forming that trusted relationship. As consumers and vendors continue to respond to new and emerging threats to identity theft, it will be essential for them to bear these principles in mind. For more information about any of the issues raised in this document please visit www.rsasecurity.com or contact:
If anyone can send me the URL for this document I'll gladly post it. All in all, thanks to RSA Security for coming clean. Better late than never! Now we can get to work.
December 26, 2005
How the Chinese avoided insider fraud for over a millenium - The Chinese Remainder Theorem
Guest poster Daniel Nagy writes me a human readable explanation of the Chinese Remainder Theorem. That's too valuable a thing to go unposted:
> > Yes, I can agree with that. Yet, it is important to formalize the
> > methodology. (e.g. the Chinese Remainder Theorem was used in ancient China
> > on the basis of experience for more than a millenium before it was exactly
> > formulated and proven.)
>
> Ha! I didn't know that. Yes.....
Hmm. The Chinese Number Theorem was the first use of number theory in security. The Chinese, unlike people in India, did not have a place value system, and did not have floating-point notation, like Babylonians/Greeks either.
However, they did trade in large quantities of stuff (bricks, pottery, etc.). When they shipped a large number of something to some other place, they would write down the remainders of several counts done in modular arithmetic, as divided by a number of small, relative prime numbers. E.g. 1,2,3,4,5,6,7, 1,2,3,4,5,6,7, 1,2,3,4,5,6,7, 1,2 would leave 2 as the remainder for 23 divided by 7. This could be done several times with different primes, like 13, 17, etc,etc.
Now, if all the remainders from the several counts matched, the total number must have matched as well and nothing was stolen. Since addition and subtraction work in this modular arithmetic, this was a very convenient way of accounting for large quantities. This method has the rather stunning benefit that the actual counting can be done by unskilled people, who are only able to count up to a small number.
The only drawback (when compared to place-value system used in India and later in the whole world) is that it does not preserve ordering: finding out which quantity is bigger and which one is smaller is difficult.
Written records (actually, archived letters accompanying shipments) with such counts have been found from as early as the third century A.D. The exact formulation was given by Qin Jiushao in his commentary to the classic book called Mathematics in Nine Chapters (or something like that -- my notes on number theory are in Hungarian), which (the commentary, not the book) was written in 1247 A.D. Nine Chapters is a classic text in Chinese math, similar to Elements by Euclid.
The statement of the theorem is that up to the product of all the moduli, the remainders are unique. Also, Qin Jiushao provided an algorithm for finding the number given the remainders. In his original example, he would make his two disciples measure the distance between his home and a river by holding hands and stepping together, one counting 23, the other counting 17. When they tell the results to their master, he can figure out the distance of three hundred-something steps.
And perhaps as a humorous footnote, consider this: the Chinese managed to get away with using this unproven mathematics in a security system for a millenium or so...
--
Daniel
Addendum: Nick comments and also points at a more mathematical treatment.
October 12, 2005
The Mojo Nation Story - Part 2
[Jim McCoy himself writes in response to MN1] Hmmm..... I guess that I would agree with most of what Steve said, and would add a few more datapoints.
Contributing to the failure was a long-term vision that was too complex to be implemented in a stepwise fashion. It was a "we need these eight things to work" architecture when we were probably only capable of accomplishing three or four at any one time. Part of this was related to the fact the what became Mojo Nation was originally only supposed to be the distributed data storage layer of an anonymous email infrastructure (penet-style anonymous mailboxes using PIR combined with a form of secure distributed computation; your local POP proxy would create a retrieval ticket that would bounce around the network and collect your messages using multiple PIR calculations over the distributed storage network....yes, you can roll your eyes now at how much we underestimated the development complexity...)
As Bram has shown, stripping MN down to its core and eliminating the functionality that was required for persistent data storage turned out to create a pretty slick data distribution tool. I personally placed too much emphasis on the data persistence side of the story and the continuing complexity of maintaining this aspect was probably our achilles heel, if we had not focused on persistence as a design goal and let it develop as an emergent side-effect things might have worked but instead it became an expensive distraction.
In hindsight, it seems that a lot of our design and architecture goals were sound, since most of the remaining p2p apps are working on adding MN-like features to their systems (e.g. combine Tor with distributed-tracker-enabled BitTorrent and you are 85% of the way towards re-creating MN...) but the importance of keeping the short- term goal list small and attainable while maintaining a compelling application at each milestone was a lesson that I did not learn until it was too late.
I think that I disagree with Steve in terms of the UI issues though. Given the available choices at the time we could have either created an application for a single platform or use a web-based interface. The only cross-platform UI toolkit available to us at the time (Tk) was kinda ugly and we didn't have the resources to put a real UI team together. If we were doing this again today our options would include wxWidgets for native UI elements or AJAX for a dynamic web interface, but at the time a simple web browser interface seemed like a good choice. Of course, if we had re-focused on file-sharing instead of distributed persistent data storage we could have bailed on Linux & Mac versions and just created a native win32 UI...
The other point worth mentioning is that like most crypto wonks, we were far too concerned with security and anonymity. We cared about these features so we assumed our users would as well; while early adopters might care the vast majority of the potential user base doesn't really care as much as we might think. These features added complexity, development time, and a new source of bugs to deal with.
Jim
Back to Part 1 by Steve.
October 01, 2005
Wikicrypto
A while ago, Matt pointed me to several links in Wikipedia on "Project Cryptography", crypto topics1, topics2, digital signatures, etc etc. All could do with some updating, but that's the nature of Wikis, right?
Which reminds me to check in and post the current definition of Financial Cryptography, that breed of crypto that might not include any crypto...
Financial cryptography (FC) is the use of cryptography in applications with strong financial motivation.The field found its original inspiration in the work of Dr David Chaum who invented the blinded signature. This special form of a cryptographic signature permitted a coin to be signed without the signer seeing the actual coin, and permitted a form of digital token money that offered untraceability. This form is some known as Digital Cash.
The term "financial cryptography" was coined by Hettinga to encompass that innovation and also all of the other potential ways in which cryptography could lead to finance applications. These applications include a very wide range of possibilities, including finance, retail payment systems, trading, digital rights management (DRM), virtual gaming, reputational systems, community currencies, and access and authentication systems.
As a business, FC followed the guide of cryptography and only the simplest ideas were adopted. Account money systems protected by SSL such as PayPal, e-gold and GoldMoney were relatively successful, but DRM, blinded token money and efforts by banks were not.
Financial cryptography is frequently seen as of broad scope. Grigg sees financial cryptograpy in seven layers [1], being the combination of seven distinct disciplines: cryptography, software engineering, rights, accounting, governance, value, and financial applications. Business failures can often be traced to missing disciplines or poor application of same. This view has FC as a crossdiscipline subject.
Don't like it? Then change it!
September 14, 2005
RSA keys - crunchable at 1024?
New factoring hardware designs suggest that 1024 bit numbers can be factored for $1 million. That's significant - that brings ordinary keys into the reach of ordinary agencies.
If so, that means most intelligence agencies can probably already crunch most common key sizes. It still means that the capability is likely limited to intelligence agencies, which is some comfort for many of us, but not of comfort if you happen to live in a country where civil liberties are not well respected and keys and data are considered to be "on loan" to citizens - you be the judge on that call.
Either way, with SHA1 also suffering badly at the hands of the Shandong marauders, it puts DSA into critical territory - not expected to survive even given emergency surgery and definately no longer Pareto-complete. For RSA keys, jump them up to 2048 or 4096 if you can afford the CPU.
Here is the source of info, posted by Steve Bellovin.
Open to the PublicDATE: TODAY * TODAY * TODAY * WEDNESDAY, Sept. 14 2005
TIME: 4:00 p.m. - 5:30 p.m.
PLACE: 32-G575, Stata Center, 32 Vassar Street
TITLE: Special-Purpose Hardware for Integer Factoring
SPEAKER: Eran Tromer, Weizmann InstituteFactoring of large integers is of considerable interest in cryptography and algorithmic number theory. In the quest for factorization of larger integers, the present bottleneck lies in the sieving and matrix steps of the Number Field Sieve algorithm. In a series of works, several special-purpose hardware architectures for these steps were proposed and evaluated.
The use of custom hardware, as opposed to the traditional RAM model, offers major benefits (beyond plain reduction of overheads): the possibility of vast fine-grained parallelism, and the chance to identify and exploit technological tradeoffs at the algorithmic level.
Taken together, these works have reduced the cost of factoring by many orders of magnitude, making it feasible, for example, to factor 1024-bit integers within one year at the cost of about US$1M (as opposed to the trillions of US$ forecasted previously). This talk will survey these results, emphasizing the underlying general ideas.
Joint works with Adi Shamir, Arjen Lenstra, Willi Geiselmann, Rainer Steinwandt, Hubert K?pfer, Jim Tomlinson, Wil Kortsmit, Bruce Dodson, James Hughes and Paul Leyland.
Some other notes:
http://www.keylength.com/index.php
http://citeseer.ist.psu.edu/287428.html
August 17, 2005
SHA1 attack updated at Crypto, US responds by stifling research
At this year's Crypto conference, a 2^63 collisions attack on SHA1 was announced by Wang, but not delivered by her personally because the US State Department would not issue her a Visa. (According to participants, Adi Shamir humourously pointed out it was because she had admitted to attacking US systems with her collisions attack).
This is far superior to the suggestion from last year's conference, which destroyed all smaller hashes except SHA1 and suggested a 2^69 attack. That was 11 bits off the brute force searching limit of 2^80, and still was not really doable. Taking it to 17 bits and down to 2^63 puts it in reach of Internet attacks as we've already seen similar efforts (64 bit ciphers have been crunched on the net).
Note that this is on collisions between two random hashes, and most systems do not rely on this property. Rather, most systems rely on not being able to find another document from a given hash, or seeing through to the document from a given hash.
The strength of that normal usage is 2^160, the full length of brute forcing the entire hash space. Simplistically, if that space lost 2*17 bits, SHA1 would still be as strong as 2^126, which is well secure from crunching.
But it does mean that SHA1 is no longer Pareto-complete - no longer secure regardless of the circumstances. Crypto Engineers will have to check to make sure they are not relying on collision resistance between random hashes.
(I'll update this as more info comes to hand, check the blog. Here's a snippet:)
"Perry E. Metzger" writes:
...I was unable to watch webcast of the rump session at the Crypto conference last night, but I have heard that a proxy announced that Wang has an order 2^63 attack on SHA-1. Can anyone confirm that, and give details?Shamir gave her rump session talk (and first gave a humorous presentation on why she couldn't get a visa -- she admitted to attacking U.S. government systems, and used collisions). She is indeed claiming a 2^63 attack, and found a new path to use in the attack. Because of the new path, there is reason to think the attack will get even better. Shamir noted that 2^63 is within reach of a distributed Internet effort to actually find one.
--Steven M. Bellovin, http://www.cs.columbia.edu/~smb
Addendum: Bruce Schneier's blog has refs to the papers.
May 01, 2005
HCI/security - start with Kerckhoffs' 6 principles
It seems that interest in the nexus at HCI (human computer interface) and security continues to grow (added ec fc1 fc2). For my money I'd say we should start at Kerckhoff's 6 principles. Now, unfortunately we have only the original paper in French, so we can only guess at how he derived his 6 principles.
Are there any French crypto readers out there who could have a go at translating this? Kerckhoffs was a Dutchman, and perhaps this means we need to find Dutch cryptographers who can understand all his nuances... Nudge, nudge...
(Ideally the way to start this, I suspect, is to open up a translation in a Wiki. Then, people can debate the various interpretations over an evolving document. Just a guess - but are there any infosec wikis out there?)
April 19, 2005
Spitzer - securing your data to become a crime?
Elliot Spitzer's office of the Attorney General has introduced a
package of legislation intended to "rein in identity theft." Well, good luck! But here's one thing that won't help:
Facilitating prosecutions against computer hackers by creating specific criminal penalties for the use of encryption to conceal a crime, to conceal the identity of another person who commits a crime, or to disrupt the normal operation of a computer;
What the AG probably doesn't realise is that efforts to suppress crypto are one of the core underlying factors that got us into this mess in the first place.
The 'unintended consequences' of the US Government's war on crypto has over the years stifled the use of protection technologies in the Internet. Instead of being a basic technique that is used at every place and juncture, like a PIN, it is an arcane, difficult subject, only permitted to the elect few who dare to challenge the twin demons of the Crypto Guild and the USG's export restrictions. (Yes, that's right. The underlying weaknesses that create cyberterrorism and cyberwarfare and cracking are the President's executive orders. Nice one guys.)
Since Unix sparked the open source revolution, the effect of the insecurity of the successive Executive Orders has been felt; the simple one was passwords which were originally encrypted by DES could not be encrypted in many Unix systems because DES couldn't be shipped. It took decades for that to sort itself out, and the message was clear: don't add strong security to your system because you won't be able to share it.
The good uses of encryption far outweigh the bad uses. I'm not talking like 10%, I'm talking like 3 orders or more of magnitude. Crypto isn't like guns, where the only use of them is to shoot things. Crypto can be used for all sorts of governance, protection, and self-protection ideas. But stick a law on it, and the stuff slows to sludge. Another data point is the digital signature laws, which because they got passed in advance of any experience or understanding, basically killed the arisal of the technology in ordinary commerce.
Not only is criminalising encryption a bad idea, and one guaranteed to reduce security as history shows, it's also completely opposed by the existing data protection law from California: if you encrypt the data, says California, then you do not have to notify. But if you encrypt the data, says New York, then you get an extra crime added on if you ever get in trouble yourself, and as every new yorker knows, Elliot Spitzer's got a reputation for wanting the data pursuant to some criminal investigation or other.
Creating "extra super coverall" crimes like wire fraud, mail fraud and money laundering doesn't ever address the true problems. Only hard police work and luck addresses real crimes. But it certainly makes the life of the citizen and the task of the programmer much more difficult if they are too scared to use encryption.
http://www.oag.state.ny.us/press/2005/apr/apr18a_05.html
LEGISLATIVE PACKAGE AIMED AT REINING IN IDENTITY THEFT
Spitzer Calls for Regulation of Information Brokers and
Increased Penalties for Computer Hacking
Attorney General Eliot Spitzer and representatives of consumer advocacy and crime victims organizations today urged the State Legislature to pass legislation to protect consumers' from identity theft and the unauthorized use of personal data.
Spitzer has submitted a package of bills aimed at providing consumers better control over the dissemination of their personal information, strengthening government's ability to prosecute crimes leading to identity theft and increasing penalties for such crimes.
"It has been said that the theft of one's identity and personal information is not a matter of 'if' but a matter of 'when'," Spitzer said. "New York State must enact reforms to strengthen consumers' ability to control personal information and to facilitate the prosecution of identity theft crimes."
In February, the Federal Identity Theft Data Clearinghouse reported that 38 percent of all fraud claims in 2004 related to identity theft, and New York State ranked seventh in the nation in per-capita identity theft reports. Moreover, a national survey conducted by the Federal Trade Commission estimated that the number of victims in 2002 approached 10 million, including 663,300 New Yorkers.
Spitzer noted that in the last nine weeks alone, numerous incidents have highlighted the issue including:
* Two major information brokerage companies, ChoicePoint, Inc. and LexisNexis have admitted that data files of over 455,000 consumers were breached;
* One of the world's largest financial institutions, Bank of America, confirmed that backup tapes containing personal data on 1.2 million accounts were missing;
* Federal authorities confirmed an investigation into the electronic hacking theft of eight million credit card accounts from the processor of credit transactions for MasterCard, Visa, Discover and American Express;
* A popular shoe store chain, DSW Shoe Warehouse admitted that customer credit information was stolen from over 100 of its stores; and
* Approximately 180,000 GM Mastercard holders will soon receive notification that someone might have stolen their personal information in a data breach at Polo Ralph Lauren Inc.
Spitzer's legislative proposals would address many of these incidents by:
* Providing identity theft victims better control over their personal identifying information, including: allowing for "security freezes" on credit files; and providing significantly increased protections against a private company's disclosure of a customers' social security numbers;
* Requiring companies to provide notice to individual consumers involved in instances in which a security breach has exposed personal information concerning 500 or more New Yorkers;
* Facilitating the ability of victims to file criminal complaints with law enforcement agencies;
* Requiring that information brokers notify consumers whenever a report containing personal information - such as telephone numbers, bank account information, income, medical information, driving record, and purchasing preferences - has been issued and mandating the disclosure include contact information of the entity that requested the report. The bill also would provide consumers access to their profiles compiled by information brokers;
* Establishing statewide personal information "opt-out" lists, similar to the Telemarketing Do Not Call program, for consumers who want to ensure their confidential personal information is not disclosed;
* Facilitating prosecutions against computer hackers by creating specific criminal penalties for the use of encryption to conceal a crime, to conceal the identity of another person who commits a crime, or to disrupt the normal operation of a computer;
* Increasing criminal penalties for gaining unauthorized access through a computer to data about employment, salary, credit or other financial or personal information;
* Facilitating prosecutions against hackers and others who surreptitiously gain access to computers, but do not steal or destroy computer material.
For more information about identity theft or to file a complaint, consumers are encouraged to visit the Attorney General's website at www.oag.state.ny.us/consumer/consumer_issues.html or call his consumer help line at (800) 771-7755. Consumers also can go to Federal Trade Commission to file complaints by calling (877) IDTHEFT.
March 30, 2005
Microsoft to use blinded sigs?
Stefan spotted a new patent awarded to Microsoft for a minor variant in blinded signatures, and added to a few other clues, muses that they may be about to launch some privacy system based on Chaumian blinding. I doubt this very much, so I'll get the skepticism up front.
Microsoft does not as a rule experiment with "new stuff" or unproven stuff. Blinded signatures in the marketplace would have to fall into the unproven category. Microsoft's role in society is to absorb borg-like the innovations of other companies, and this would be a step outside that mould. Every other time they've done the innovation thing, it has mucked up on them, and students of innovation know why.
There is a plausible theory that they will use this as a teaser for the marketplace. That would be well and good, certainly blinded signatures in use for any purpose would raise the penny stock of cryptography beyond its current de-listed level. But the real privacy question is in the architecture, and as Stefan pointed out earlier today, the challenge they will face is avoiding being caught in doublespeak, and that goes for internal architecture as much as external marketing.
March 13, 2005
How to Break MD5 and Other Hash Functions
Wang and Yu have released their draft paper(s) for Eurocrypt 2005:
Xiaoyun Wang and Hongbo Yu, "How to Break MD5 and Other Hash Functions"
Xiaoyun Wang and Hongbo Yu, "Cryptanalysis of the Hash Functions MD4 and RIPEMD"
Meanwhile, Vlastimil Klima has released a draft on his research trying to reverse engineer the Shandong team's results. Whereas the Shandong team managed MD5 collisions in one hour on their IBM P690 supercomputer, Klima claims he can do a collision, using different techniques, in only 8 hours on his 1.6GHz laptop!
V. Klima, Finding MD5 Collisions - a Toy For a Notebook
And, expect this to improve, Klima says, when the two differing techniques are compared and combined.
What does this mean, especially considering my earlier post on cryptographer's responsibility?
It is now easy to find a junk document that matches some MD5 hashed document. This is a collision attack. But, it will be harder to find a valid attacking document that hashs to the same MD5. This is called a pre-image attack, and is far more serious.
Further it remains harder to breach a protocol that relies on other things. But, do move from MD5 with due haste, as if collisions are easy to find, then pre-images can't be that far behind. And once we have pre-images, we can substitute in real live key pairs into the certs attack described earlier today.
Cryptographers have a Responsibility to Explain Results
I see signs of a wave of FUD spreading through the net as cryptoplumbers try and interpret the latest paper on MD5 collisions in certs from Lenstra, Wang, Weger. I didn't have time to read the paper at the time, and wasn't easily able to divine from the chit chat what the result meant. When the dust settled, this was not an attack, but many assumed it was.
Why? Because it wasn't explained, neither in the paper nor anywhere else that I read. Reading the paper, the closest I came to a limitation on damage in human language was this:
``The RSA moduli are secure in the sense that they are built up from two large primes. Due to our construction these primes have rather different sizes, but since the smallest still are around 512 bits in size while the moduli have 2048 bits, this does not constitute a realistic vulnerability, as far as we know.''
The last part (my emphasis) may seem pretty clear, but the reasoning behind it is inaccessible to non-cryptographers. Further, it is buried deep: the key phrase is not in the abstract or conclusion, nor on the more accessible HTML page.
Now, in all probability, the authors may be surprised to know that non-cryptographers read these papers. That's because normally most of the output from cryptology is not of importance to the outside world - small improvements and small suggestions. And, frankly, it's economic for us all to let the people doing to work get on and do it without the distraction of the real world.
This time is different however. The Wang, Yin, Yu results go beyond the limited world of cryptography as they have shifted the security statement of a large class of algorithms in which we previously trusted and relied upon. This time we are all effected, and those who understand have a responsibility to explain what the real significance of the results is.
Here is my own limited interpretation:
The paper describes how to create a false or forged certificate based on MD5. But what it does not seem to say is that the key within the certificate can be forged, neither in private key form nor in useful public key form (on this last point I am not sure).Without the private key, the certificate cannot take place in a normal signature protocol. That's the point of the public key: to prove that the other party has control of the private key.
Which means no attack, as yet, in general. Yes, we should with all due speed deprecate MD5 in the production of certificates, but we are a long way from seeing the situation turn into an economic attack.
Addendum:But it looks like I got it wrong in detail. See cypherpunk's comment below, which explains how it is. We do concur on results though - no attack.
So where's the danger? People on the net are drawing out the unexplained results and assuming that things are totally broken. And that crosses the line into FUD.
It may be that encouraging a sense of Fear, Uncertainty and Doubt will help the Internet run like scared lemmings away from the now weakened MD5 hash. It may help build emphasis towards what we need - a serious effort to construct a new theory of message digest functions along the lines of NIST's AES competition.
But, more than likely, FUD will do what it has always done: spread confusion and cause people to make bad decisions. And, as those bad decisions are often made in the direction of the spreaders of FUD, we must understand that there is a financial benefit to those spreading FUD. More sales, more exposure.
This is not responsible behaviour. Now, to be clear, the primary authors of this paper are focused on the result, and we understand that distractions of dotting the i's and crossing the t's will slow down the real work. But those of us who are not involved in the creation of the new result have a duty to explain and teach, rather than steal the limelight.
Cryptographers as scientists and wider security specialists as advisers have a duty to deliver value in terms of security, not sales. We all have to be on the watch for the tempation to use FUD as the easy way for sales. In the long run, spreading FUD and reaping easy sales results in a mess that we as the security community have to clean up.
Worse, it spreads the doubt that cryptography and security as a science and specialisation is not worth listening to, because whatever we say next time has to fight the failure of last time. Selling FUD now means we are damned for all time to sell snake oil forever.
February 17, 2005
Idle speculation - I wonder if the NSA knew this all along?
The SHA-1 crack (below) by the now legendary team from Shandong University has me thinking. It's great work. It opens the door to some really serious thinking (this remark was made by Ron Rivest at Crypto 2004, I recall).
But the crack doesn't quite get there. 69 bits is still too many. It's even more than MD5 had at full 64 bit strength. This all sounds like a replay of the fabled Skipjack case, where the algorithm had so many interesting artifacts that cryptographers expected it to break ... but try as they might, they couldn't quite get there.
Skipjack was a case of excellent engineering. Almost no margin for error, and a clear sign that the NSA knew precisely where the limits were.
Now we know that SHA-1 moves from 80 bit strength to 69 bit strength. Maybe it is destined to lose a few more bits. That still makes it good and practical, albeit a little dated. Maybe, just maybe when the NSA fixed up the flaws in SHA-0 that took it from its now 39 bit strength to 69 bits, they consulted a table just like Lenstra and Verhal's and decided on what they needed?
Just idle speculation, mind!
Collision Search Attacks on SHA1 - the Shandong note
The note on the SHA1 attack from the team from Shandong - Xiaoyun Wang, Yiqun Lisa Yin, Hongbo Yu - is now available in PDF. Firstly, it is a summary, not the real paper, so the attack is not outlined. Examples are given of _reduced rounds in SHA1_ which is not the real SHA1. However, they established their credibility at Crypto 2004 by turning around attacks over night on new challenges. Essential text, sans numbers, below...
Collision Search Attacks on SHA1
Xiaoyun Wang, Yiqun Lisa Yin, Hongbo Yu
February 13, 20051 Introduction
In this note, we summarize the resulted of our new collision search attacks on SHA1. Technical details will be provided in a forthcoming paper.
We have developed a set of new techniques that are very effective for searching collisions in SHA1. Our analysis shows that collisions of SHA1 can be found with complextity less than 269 hash operations. This is the first attack on the full 80-step SHA1 with complexity less than 280 theoretical bound. Based on our estimation, we expected that real collisions of SHA1 reduced to 70-steps can be found using today's supercomputers.
In the past few years, there have been significant research advances in the analysis of hash functions. The techniques developed in the early work provide an important foundation for our new attacks on SHA1. In particular, our analysis is built upon the original differential attack on SHA0, the near collision attack on SHA0, the multi-block collision techniques, as well as the message modification techniques used in the collision search attack on MD5. Breaking SHA1 would not be possible without these powerful analytical techniques.
Our attacks naturally apply to SHA0 and all reduced variants of SHA1. For SHA0, the attack is so effective that we were able to find real collisions of the full SHA0 with less than 239 hash operations. We also implemented the attack on SHA1 reduced to 58 steps and found collisions with less than 233 hash operations. Two collision examples are given in this note.
2 A collision example for SHA0
<skip some numbers>
Table 1: A collision of the full 80-step SHA0. The two messages that collide are (M0, M1) and (M0 , M'1). Note that padding rules were not applied to the messages.
3 A collision example for 58-step SHA1
<skip some numbers>
"Table 2: A collision of SHA1 reduced to 58 steps. The two messages that collide are M0 and M'0. Note that padding rules were not applied to the messages."
The last footnote generated some controversy which is now settled: padding is irrelevant. A quick summary of our knowledge is that "the Wang,Yin,Yu attack that can reduce the strength of SHA-1 from 80 bits to 69 bits." This still falls short of a practical attack, as it leaves SHA-1 as stronger than MD5 (only 64 bit strength), but SHA-1 is now firmly on the "watch" list. To use my suggested lingo, it is no longer Pareto-complete, so any further use would have to be justified within the context of the application.
February 16, 2005
Shandong team attacks SHA-1
The draft note on the Chinese team's exploits of message digests has now alleged that SHA-1 suffers from the same cryptanalytic attack as that which broke the others. Note that this refers to collisions between two random hashes, finding a hash for your document is still unattacked, it seems. Early leaked reports may be exaggerated...
Over on Bruce Schneier's blog he reports presumably from the RSA conference. Collisions in 2^69 operations are indicated, which is to be compared to the brute force strength of 2^80; collisions in SHA-0 were found in 2^39. This would seem to suggest that SHA-256 and variants may be OK for now.
Steve Bellovin has this to say in response:
... a team has found collisions in full SHA-1. It's probably not a practical threat today, since it takes 2^69 operations to do it and we haven't heard claims that NSA et al. have built massively parallel hash function collision finders, but it's an impressive achievement nevertheless -- especially since it comes just a week after NIST stated that there were no successful attacks on SHA-1.
That sounds more to my liking. Remember, 2^69 is well in excess of say the 56-bit key strength of DES, so I suspect the crunch is still out of reach of anyone without access to hardware that can dim the town lights. Also,as Eric points out the reduction in collision resistance has to be taken in context, most systems rely on it being hard to find a particular hash, not a collision between two random hashes.
All in all, this is shaping up to be the closing chapter on the current generation of hashes. The killer in the plot was as announced back last year at Crypto 2004.
Luckily, there are a few thinking blogs out there: Scott's stuff, and Rick's crypto blog is thinking on how to wrap the hash.
Postscript: Rumours had circulated (see comments below) that the 'break' was only applicable under some conditions related to including the padding. Those rumours have been debunked, the padding issue is irrelevant.
Addendum: this entry has changed many times to update new information!
February 15, 2005
Plans for Scams
Gervase Markham has written "a plan for scams," a series of steps for different module owners to start defending. First up, the browser, and the list will be fairly agreeable to FCers: Make everything SSL, create a history of access by SSL, notify when on a new site! I like the addition of a heuristics bar (note that Thunderbird already does this).
Meanwhile, Mozilla Foundation has decided to pull IDNs - the international domain names that were victimised by the Shmoo exploit. How they reached this decision wasn't clear, as it was taken on insider's lists, and minutes aren't released (I was informed). But Gervase announced the decision on his blog and the security group, and the responses ran hot.
I don't care about IDNs - that's just me - but apparently some do. Axel points to Paul Hoffman, an author of IDN, who pointed out how he had IDN spoofing solutions with balance. Like him, I'm more interested in the process, and I'm also thinking of the big security risks to come and also the meta-risks. IDN is a storm in a teacup, as it is no real risk beyond what we already have (and no, the digits 0,1 in domains have not been turned off).
Referring this back to Frank Hecker's essay on the foundation of a disclosure policy does not help, because the disclosure was already done in this case. But at the end he talks about how disclosure arguments fell into three classes:
Literacy: What are the words? Numeracy: What are the numbers? Ecolacy: And then what?
"To that end [Frank suggests] to those studying the economics of disclosure that we also have to study the politics of disclosure and the ecology of disclosure as well."
Food for thought! On a final note, a new development has occurred in certs: a CA in Europe has issued certs with the critical bit set. What this means is that without the code (nominally) to deal with the cert, it is meant to be rejected. And Mozilla's crypto module follows the letter of the RFC in this.
IE and Opera do not it seems (see #17 in bugzilla), and I'd have to say, they have good arguments for rejecting the RFC and not the cert. Too long to go into tonight, but think of the crit ("critical bit") as an option on a future attack. Also, think of the game play that can go on. We shall see, and coincidentally, this leads straight back into phishing because it is asking the browser to ... display stuff about the cert to the user!
What stuff? In this case, the value of the liability in Euros. Now, you can't get more FC than that - it drags in about 6 layers of our stack, which leaves me with a real problem allocating a category to this post!
February 10, 2005
Open disclosure - OpenPGP reports minor attack
In what looks like a nice piece of cryptanalysis, Serge Mister and Robert Zuccherato have found an oracle attack on OpenPGP. Don't worry, it's quite obscure - it would only effect automated systems that were prepared to handle a flood of messages, and it would only effect secret-key encrypted messages that the attacker has already got - something he only gets from your harddrive. [1]
Fixing it is a bit more trouble, but it looks like a fix has been designed, and it will roll out in due course. The more interesting thing is that this sets a good precedent for getting things out in the open as soon as possible.
February 01, 2005
Blogs on Crypto
Searching through Blogshares, I've found some blogs on Cryptography. Hal asked, and here they are!
(Caveat: I wouldn't normally post on QC but it's a blog, and I have a secret agenda!)
January 27, 2005
The Green Shoots of Opportunistic Cryptography
In a New Scientist article, mainstream popular press is starting to take notice that the big Wi-Fi standards have awful crypto. But there are some signs that the remedy is being pondered - I'll go out on a limb and predict that within a year, opportunistic cryptography will be all the rage. (links: 1, 2, 3,4 5)
(Quick explanation - opportunistic cryptography is where you generate what you need to talk to the other party on the fly, and don't accept any assumptions that it isn't good enough. That is, you take on a small risk of a theoretical attack up front, in order to reach cryptographic security quickly and cheaply. The alternate, no-risk cryptography, has failed as a model because its expense means people don't deploy it. Hence, it may be no-risk, but it also doesn't deliver security.)
Here's what has been seen in the article:
Security experts say that the solution lies in educating people about the risks involved in going wireless, and making the software to protect them easier to use. "Blaming the consumer is wrong. Computers are too complex for the average person to secure. It's the fault of the network, the operating system and the software vendors," says California-based cryptographer Bruce Schneier in the US. "Products need to be secure out of the box," he says.
Skipping the contradiction between "educating people" and "blaming the consumer", it is encouraging to see security people pushing for "secure out of the box." Keys should be generated opportunistically and on install, the SSH model (an SSH blog?). If more is wanted, then the expert can arrange that, but there is little point in asking an average user to go through that process. They won't.
Schneier is pessimistic. "When convenience and features are in opposition to security, security generally loses. As wireless networks become more common, security will get worse."
Schneier is unduly pessimistic. The mistake in the above logic is to consider the opposition between convenience and security as an invioble assumption. The devil is in those assumptions, and as Modadugu and Rescorla said recently:
"Considering the complexity of modern security protocols and the current state of proof techniques, it is rarely possible to completely prove the security of a protocol without making at least some unrealistic assumptions about the attack model."
(Apologies, but it's buried in a PDF. Post.) That's a green shoot, right there! Adi Shamir says that absolutely secure systems do not exist, so as soon as we get over that false assumption that we can arrange things perfectly, we can start to work out what benefits us most, in an imperfect world.
There's no reason why security and convenience can't walk hand in hand. In the 90s, security was miscast as needing to be perfect regardless of convenience. This simply resulted in lost sales and thus much less security. Better to think of security as what we can offer in alignment with convenience - how much security can we deliver for our convenience dollar? A lot, as it turns out.
January 08, 2005
Skype analysed - Jedi Knights of the Crypto Rebellion, Score 1
Adam picked up an article analysing Skype. For those on the cutting edge, you already know that Skype is sweeping the boards in VOIP, or turning your computer into a phone. Download it today ... if you have a Mac. Or Linux or even Windows. (I don't.)
What might be less well known is that Skype put in crypto to secure the telephone conversation. This means that eavesdroppers can't ... well, eavesdrop! Great stuff. Now, even better, they built it themselves, so not only do we have a secure VOIP solution, downloadable for free, but we also have a mystery on our hands: is it really secure?
Unfortunately, we don't know for sure as they didn't release the source. And they won't say a thing ... Simson Garfinkel looked at the packets and the sorta look encrypted. Or compressed .. or something.
So where are we? Well, it's still a darn sight better than anything else. Go guys! We have a clear benefit over anything else on the table.
And even if it's not secure, nobody knows that. We have to wait until the cryptanalysts have pored over the packets and found the weaknesses. Or, more likely, the hackers have disassembled the core crypto code, worked out what it does, and handed the crypto guys the easy bit.
Even after they announce a weakness, it's still secure! Because nobody can exploit it, until someone else comes up with a toolkit to breach and exploit the weaknesses. (Generally, it's a different group of people, don't ask me why.)
But, even then it's still secure! Simply because nobody bothers to download the exploit and listen to people's conversation. Get real, there aren't exactly hordes of people driving around listening to poorly secured WEP connections (exploit available!) now are there?
The measure of security is positively dependent on the cost to the *attacker*. So an attacker still has to download the exploit, attach the alligator clips to the ethernet, sit in the van, chew donuts, drink bad coffee and listen to bad jokes while waiting for the call. Well, maybe, but a full analysis of the attacker's costs for eavesdropping shows ... it's too sodding expensive, even with the exploit available. Don't worry about it.
In which case, Skype gives you great security, a bit like the momentous defeat of the GSM crypto protocol over the paparazzi scanners! Scoreboard: Jedi Knights of the Crypto Rebellion, 1. Forces of the Dark Empire, 0.
December 28, 2004
STORK - strategic roadmap for crypto - New Trends in Cryptology
Phong Nguyen has edited for STORK a long 'New Trends' discussion of what cryptologers are concentrating on at the moment. It's very much a core, focused scientists view, and engineers in the field will find it somewhat disjoint from the practical problems being faced in applications today. E.g., no mention of economic or opportunistic models. Still for all that, it is a useful update on a broad range of areas for the heavy crypto people.
November 30, 2004
"Amateurs study cryptography; professionals study economics."
Udhay alerted us to a new aphorism (a short pithy instructive saying) from AMS on cryptography which I thought worth sharing:
"Amateurs study cryptography; professionals study economics."
This immediately made me think of the military aphorism of "amateurs study tactics; generals study logistics." Lo and behold, here is what AMS said, in full, over on his blog:
"I've come up with (writes AMS) an aphorism that captures my feeling about where the effort in building secure systems needs to go. Echoing the old saying about the importance of tactics versus logistics in military studies I say:
Amateurs study cryptography; professionals study economics."
Ha! It's pretty neat. The only thing I'm unsure of is whether it should be economics or risk. But as I roll it around my mind, I keep coming back to the conclusion that in the public's mind, the popular definition of economics is closer to the image that we are trying to convey. Which is to say, when we say economics, people think of something close to risk.
November 27, 2004
SDP1 - Secure Datagram Protocol #1
After years of thought and days of hacking, Zooko and I have put together a new crypto protocol: Secure Datagram Protocol #1 or SDP1 . It provides for encrypting and MACing a single datagram, within a previously established secret key context.
The sexy details: The inner layer of plaintext is a Pad and a Payload, where the Pad expands to block, as well as incorporating nonce, time and random elements in order to make a good IV. The plaintext is then encrypted with AES128 in CBC mode. A token is prepended to the ciphertext so that receivers can determine where to find the keys, and the whole lot is MACed with HMAC-SHA1. The token, the ciphertext and the MAC then form the on-the-wire datagram.
I have implemented SDP1 in Java and am in the process of using it to create secure back-channels from server-to-client comms within SOX (this is a major mod to the basic paradigm of public key nymous cryptosystems which are normally all client-to-server oriented). Secret sharing was a breeze, and is already done, but usage in a full cryptosuite is much more work!
As SDP1 is intended to be used for financial applications, and is thus datagram oriented, we can't really make use of the many other protocols that have been developed, such as SSL and SSH. In fact, it seems as if there is a bit of a hole in the market for datagram products; I found ESP which has too much of a relationship to IP, and is also a little old, but little else in this area. Architecturally, SDP1 relates quite closely to ESP, but in detail it is different.
Any comments are welcome! The SDP1 docs are reasonably fullsome, but still need some touching up. The entire layout is subject to change, at least until we get to the point of deploying too many nodes to change. At that point, we'll freeze SDP1 in whatever state and plan on a redesign called SDP2.
November 07, 2004
Al Qaeda's use of cryptography - scant evidence
This article by Debka announces a new "Terrorist Encyclopedia" that is apparently written and issued by Al Qaeda to its troops (if that's the correct term). It is described to be an intelligence or operations manual, and is credited to the intelligence chief of the organisation, one Seif bin Adel.
Where they (the manual and the aticle) bear relevance is in the penultimate paragraph:
``large part of the book is devoted to questions on "How to communicate and relay messages safely on the Internet and by e-mail." Offered here are instructions on how to use Microsofts Word to transmit messages without leaving a trace and how to pirate usernames and passwords unbeknownst to their owners to plant alien content in their computer files. An electronic or telephone notice then goes out to the al Qaeda recipients informing them of the username, password and filename the need to unload the secret message buried in the pirated file.' '
No mention of cryptography there; it would seem that for cryptography policy and cryptography in general, terrorists do not number amongst our flock. See an earlier blog entry on their soldier's basic field manual for ciphers of limited strength.
Still, it behoves us all (on all sides of all fences) to know and appreciate just what sort of threat is raised here. If this is the state of the art of communications security by this and similar organisations, then we can set the record straight when ignorant threat claims are made and poorly thought-out policy is proposed.
(I haven't found the actual documents. Someone obviously has these and will translate this work and make copies available digitally - keep an eye out for them!)
(An addendum: Adam Shostack's trackback pointed at this good description of Al Qaeda commsec security practices. Only passing mention of crypto.)
(A further addendum 2004-12-21: NYT article Surveillance is daunting in the Net's dark alleys states:
Terrorists rarely have to be technically savvy to cloak their conversations. Even simple prearranged code words can do the job when the authorities do not know whose e-mail to monitor or which Web sites to watch. Interviews conducted by Al Jazeera, the Arab television network, with the terror suspects Khalid Shaikh Mohammed and Ramzi bin al-Shibh two years ago - both have since been arrested - suggested that the Sept. 11 attackers communicated openly using code words. The "faculty of urban planning," for instance, referred to the World Trade Center. The Pentagon was the "faculty of fine arts."
October 28, 2004
Encrypt everything...
AlertBox, the soapbox of one Jakob Nielsen, has had enough with nonsense security prescriptions. Its 25th October entry says:
"Internet scams cannot be thwarted by placing the burden on users to defend themselves at all times. Beleaguered users need protection, and the technology must change to provide this."
Sacrilege! Infamy! How can this rebel break ranks to suggest anything other than selling more crypto and certs and solutions to the users?
Yet, others agree. Cory Doctorow says Nielsen is cranky, but educating the users is not going to solve security issues, and "our tools conspire against us to make us less secure...." Mitch Wagner agrees, saying that "much security is also too complicated for most users to understand."
And they all three agree on Nielsen's first recommendation:
"Encrypt all information at all times, except when it's displayed on the screen. In particular, never send plaintext email or other information across the Internet: anything that leaves your machine should be encrypted."
Welcome to the movement.
October 18, 2004
The Arab Cryptanalysts
Simon Singh's The Code Book is a very readable account of the development of cryptography over the ages [1]. It seems to skate over much material, but Singh shows an ability to pick out the salient events in history, and open them up. Here is an extract entitled "The Arab Cryptanalysts [2]."
Curiously it mirrors the evolution of financial cryptography: only after a significant array of other disciplines were brought to bear by the enlightened scholars of the Islamic world, for a wide range of motives and interests, was the invention of frequency analysis discovered and applied to cryptograms. Thus, the monoalphabetic cipher fell, and cryptanalysis was born.
[1] Simon Singh, The Code Book, 1999
[2] Ibid, "The Arab Cryptanalysts", pp 14-20.
September 01, 2004
VeriSign's conflict of interest creates new threat
There's a big debate going on the US and Canada about who is going to pay for Internet wire tapping. In case you hadn't been keeping up, Internet wire-tapping *is* coming. The inevitability of it is underscored by the last ditched efforts of the ISPs to refer to older Supreme Court rulings that the cost should be picked up by those requiring the wire tap. I.e., it's established in US law that the cops should pay for each wiretap [1].
I got twigged to a new issue by an article [2] that said:
"To make wiretapping possible, Internet phone companies have to buy equipment and software as well as hire technicians, or contract with VeriSign or one of its competitors. The costs could run into the millions of dollars, depending on the size of the Internet phone company and the number of government requests."
What caught me by surprise was the mention of Verisign. So I looked, and it seems they *are indeed* in the business of subpoena compliance [3]. I know most won't believe me, given their public image as a trusted ecommerce player, so here's the full page:
NetDiscovery Service for CALEA Compliance Complete Lawful Intercept Service
VeriSigns NetDiscovery service provides telecom network operators, cable operators, and Internet service providers with a streamlined service to help meet requirements for assisting government agencies with lawful interception and subpoena requests for subscriber records. Net Discovery is the premier turnkey service for provisioning, access, delivery, and collection of call information from operators to law enforcement agencies (LEAs).
Reduce Operating Expenses
Compliance also requires companies to maintain extensive records and respond to government requests for information. The NetDiscovery service converts content into required formats and delivers the data directly to LEA facilities. Streamlined administrative services handle the provisioning of lawful interception services and manage system upgrades.
One Connection to LEAs
Compliance may require substantial capital investment in network elements and security to support multiple intercepts and numerous law enforcement agencies (LEAs). One connection to VeriSign provides provisioning, access, and delivery of call information from carriers to LEAs.
Industry Expertise for Continued Compliance
VeriSign works with government agencies and LEAs to stay up-to-date with applicable requirements. NetDiscovery customers benefit from quick implementation and consistent compliance through a single provider.
CALEA is the name of the bill that mandates law enforcement agency (LEA) access to telcos - each access should carry a cost. The cops don't want to pay for it, and neither do the suppliers. Not to mention, nobody really wants to do this. So in steps VeriSign with a managed service to handle wiretaps, eavesdropping, and other compliance tasks as directed under subpoena. On first blush, very convenient!
Here's where the reality meter goes into overdrive. VeriSign is also the company that sells about half of the net's SSL certificates for "secure ecommerce [4]." These SSL certificates are what presumptively protect connections between consumers and merchants. It is claimed that a certificate that is signed by a certificate authority (CA) can protect against the man-in-the-middle (MITM) attack and also domain name spoofing. In security reality, this is arguable - they haven't done much of a job against phishing so far, and their protection against some other MITMs is somewhere between academic and theoretical [5].
A further irony is that VeriSign also runs the domain name system for the .com and the .net domains. So, indeed, they do have a hand in the business of domain name spoofing; the trivial ease of mounting this attack has in many ways influenced the net's security architecture by raising domain spoofing to something that has to be protected against [6]. But so far nothing much serious has come of that [7].
But getting back to the topic of the MITM protection afforded by those expensive VeriSign certificates. The point here is that, on the one hand, VeriSign is offering protection from snooping, and on the other hand, is offering to facilitate the process of snooping.
The fox guarding the chicken coop?
Nobody can argue the synergies that come from the engineering aspects of such a mix: we engineers have to know how to attack it in order to defend it. This is partly the origin of the term "hacker," being one who has to crack into machines ... so he can learn to defend.
But there are no such synergies in governance, nor I fear in marketing. Can you say "conflict of interest?" What is one to make of a company that on the one hand offers you a "trustworthy" protection against attack, and on the other hand offers a service to a most likely attacker [8]?
Marketing types, SSL security apologists and other friends of VeriSign will all leap to their defence here and say that no such is possible. Or even if it was, there are safeguards. Hold on to that thought for a moment, and let's walk through it.
How to MITM the CA-signed Cert, in one easy lesson
Discussions on the cryptography list recently brought up the rather stunning observation that the Certificate Authority (CA) can always issue a forged certificate and there is no way to stop this. Most attack models on the CA had assumed an external threat; few consider the insider threat. And fair enough, why would the CA want to issue a bogus cert?
In fact the whole point of the PKI exercise was that the CA is trusted. All of the assumptions within secure browsing point at needing a trusted third party to intermediate between two participants (consumer and merchant), so the CA was designed by definition to be that trusted party.
Until we get to VeriSign's compliance division that is. Here, VeriSign's role is to facilitate the "provisioning of lawful interception services" with its customers, ISPs amongst them [9]. Such services might be invoked from a subpoena to listen to the traffic of some poor Alice, even if said traffic is encrypted.
Now, we know that VeriSign can issue a certificate for any one of their customers. So if Alice is protected by a VeriSign cert, it is an easy technical matter for VeriSign, pursuant to subpoena or other court order, to issue a new cert that allows them to man-in-the-middle the naive and trusting Alice [10].
It gets better, or worse, depending on your point of view. Due to a bug in the PKI (the public key infrastructure based on x.509 keys that manages keys for SSL), all CAs are equally trusted. That is, there is no firewall between one certificate authority and another, so VeriSign can issue a cert to MITM *any* other CA-issued cert, and every browser will accept it without saying boo [11].
Technically, VeriSign has the skills, they have the root certificate and now they are in the right place. MITM never got any easier [12]. Conceivably, under orders from the court Verisign would now be willing to conduct an MITM against its own customers and its own certs, in every place that it has a contract for LEA compliance.
Governance? What Governance?
All that remains is the question of whether VeriSign would do such a thing. The answer is almost certainly yes: Normally, one would say that the user's contract, the code of practice, and the WebTrust audit would prevent such a thing. After all, that was the point of all the governance and contracts and signing laws that VeriSign wrote back in the mid 90s - to make the CA into a trusted third party.
But, a court order trumps all that. Judges strike down contract clauses, and in the English common law and the UCC, which is presumably what VeriSign uses, a judge can strike out clauses in the law or even write an entire law down.
Further, the normal way to protect against over zealous insiders or conflicts of interests is to split the parties: one company issues the certs, and another breaches them. Clearly, the first company works for its clients and has a vested interest in protecting the clients. Such a CA will go to the judge and argue against a cert being breached, if it wants to keep selling its wares [13].
Yet, in VeriSign's case, it's also the agent for the ISP / telco - and they are the ones who get it in the neck. They are paying a darn sight more money to VeriSign to make this subpoena thing go away than ever Alice paid for her cert. So it comes down to "big ISP compliance contract" versus "one tiny little cert for a dirtbag who's probably a terrorist."
The subpoena wins all ways, well assisted by economics. If the company is so ordered, it will comply, because it is its stated goal and mission to comply, and it's paid more to comply than to not comply.
All that's left, then, is to trust in the fairness of the American juridical system. Surely such a fight of conscience would be publically viewed in the courts? Nope. All parties except the victim are agreed on the need to keep the interception secret. VeriSign is protected in its conflict of interest by the judge's order of silence on the parties. And if you've been following the news about PATRIOT 1,2, National Security Letters, watchlists, no-fly lists, suspension of habeus corpus, the Plame affair, the JTTF's political investigations and all the rest, you'll agree there isn't much hope there.
What's are we to do about it?
Then, what's VeriSign doing issuing certs? What's it doing claiming that users can trust it? And more apropos, do we care?
It's pretty clear that all three of the functions mentioned today are real functions in the Internet market place. They will continue, regardless of our personal distaste. It's just as clear that a world of Internet wire-tapping is a reality.
The real conflict of interest here is in a seller of certs also being a prime contractor for easy breachings of certs. As its the same company, and as both functions are free market functions, this is strictly an issue for the market to resolve. If conflict of interest means anything to you, and you require your certs to be issued by a party you can trust, then buy from a supplier that doesn't also work with LEAs under contract.
At least then, when the subpoena hits, your cert signer will be working for you, and you alone, and may help by fighting the subpoena. That's what is meant by "conflict of interest."
I certainly wouldn't recommend that we cry for the government to fix this. If you look at the history of these players, you can make a pretty fair case that government intervention is what got us here in the first place. So, no rulings from the Department of Commerce or the FCC, please, no antitrust law suits, and definitely no Star Chamber hearings!
Yet, there are things that can be done. One thing falls under the rubric of regulation: ICANN controls the top level domain names, including .net and .com which are currently contracted to VeriSign. At least, ICANN claims titular control, and it fights against VeriSign, the Department of Commerce, various other big players, and a squillion lobbyists in exercising that control [14].
It would seem that if conflict of interest counts for anything, removing the root server contracts from VeriSign would indicate displeasure at such a breach of confidence. Technically, this makes sense: since when did we expect DNS to be anything but a straight forward service to convert domain names into numbers? The notion that the company now has a vested interest in engaging in DNS spoofing raises a can of worms that I suspect even ICANN didn't expect. Being paid to spoof doesn't seem like it would be on the list of suitable synergies for a manager of root servers.
Alternatively, VeriSign could voluntarily divest one or other of the snooping / anti-snooping businesses. The anti-snooping business would be then a potential choice to run the DNS roots, reflecting their natural alignments of interest.
Addendum: 2nd February 2005. Adam Shostack and Ian Grigg have written to ICANN to stress the dangers in conflict of interest in selection of the new .net TLD.
[1] This makes only sense. If the cops didn't pay, they'd have no brake on their activity, and they would abuse the privilege extended by the law and the courts.
[2] Ken Belson, Wiretapping on the Net: Who pays? New York Times, http://www.iht.com/articles/535224.htm
[3] VeriSign's pages on Calea Compliance and also Regulatory Compliance.
[4] Check the great statistics over at SecuritySpace.com.
[5] In brief, I know of these MITMs: phishing, click-thru-syndrome, CA-substitution. The last has never been exploited, to my knowledge, as most attacks bypass certificates, and attack the secure browsing system at the browser without presenting an SSL certificate.
[6] , D. Atkins, R. Austein, Threat Analysis of the Domain Name System (DNS), RFC 3833.
[7] There was the famous demonstration by some guy trying to get into the DNS business.
[8] Most likely? 'fraid so. The MITM is extraordinarily rare - so rare that it is unmeasurable and to all practical intents and purposes, not a practical threat. But, as we shall see, this raises the prospects of a real threat.
[9] VeriSign, op cit.
[10] I'm skipping here the details of who Alice is, etc as they are not relevent. For the sake of the exercise, consider a secure web mail interface that is hosted in another country.
[11] Is the all-CAs-are-equal bug written up anywhere?
[12] There is an important point which I'm skipping here, that the MITM is way too hard under ordinary Internet circumstances to be a threat. For more on that, see Who's afraid of Mallory Wolf?.
[13] This is what is happening in the cases of RIAA versus the ISPs.
[14] Just this week: VeriSign to fight on after ICANN suit dismissed
U.S. Federal District Court Dismisses VeriSign's Anti-Trust Claim Against ICANN with Prejudice and the Ruling from the Court.
Today: VeriSign suing ICANN again
August 24, 2004
An Overview of Steganography for the Computer Forensics Examiner
A pretty good review of steganography. The taxonomy and references look good, and the explanations and examples are easy to understand: there are innocent looking pictures, and the maps that are hidden in them.
The only thing that dampened the scientific credibility was the conclusion that because we can't find any steganography (references well supplied and well analysed!) that doesn't mean there isn't any! As the author drifts off into law enforcement wet dreams, his grip on reality diminishes: "Steganography will not be found if it is not being looked for." Nonsense. It'll be found when it does some damage, and the correct posture is to ignore it, until found, along with all the MITM attacks, alien abductions, snipers in the street, and other things that go bump in the night.
Still, aside from that one little blemish, it's a good resource that refers to a lot of good stego programs for making and for searching.
http://www.garykessler.net/library/fsc_stego.html
August 15, 2004
SHA0 is cracked
According to the below post, SHA-0 has been cracked. The researchers crunched their way through lots of data and lots of cycles and finally found some text that hashes to the same value. And people at Crypto 2004 in Santa Barbara are reporting the fall of many older message digests such as MD5 as well.
A brief explanation: SHA-0 is one of a big class of messaging digest algorithms that has a particular magical property: it gives you a big number that is one-to-one with a document. So take any document and hash it with a message digest, and you get this big number, reliably. Here's one for the dollar contract my company issues: SHA#e3b445c2a6d82df81ef46b54d386da23ce8f3775. It's big, but small enough to post or send around in email [0].
Notwithstanding last week's result, you can't find a document that also hashes to that number, so software and people can reliably say, oh, yes, that's the Systemics PSD dollar. In short, message digests make wonderful digital identifiers, and also digital signatures, and we use them bountifully in Ricardo [1].
So if SHA-0 has been cracked, it might be a big deal. Is our digital infrastructure at risk? Yes, it's a big deal, but no, there is little risk. Here's why.
In cryptographic terms, this is a big deal. When the NSA designed SHA back in the early 90s, it was designed to be strong. Then, as the standards process plodded along, the NSA came out with a correction. It seems as though a flaw had been discovered, but they didn't say what that flaw was.
So we ended up with SHA-0, the suspect one, and SHA-1, the replacement. Of course, cryptographers spent years analysing the tiny differences, and about 6 years ago it all became clear (don't ask me, ask them). And now, those flaws have been exploited by the crack and by the machines. So now we know it can be done to SHA-0.
Luckily, we all use the replacement, SHA-1, but this will also fall in time. Once again, it is lucky that there is a new generation coming online: SHA-256, SHA-512 and the like.
But as a practical matter, this is not a big issue. When we as financial cryptographers build systems based on long term persistence of hashes, we weave the hash and its document into a system. This is called entanglement, whereby the hash and the document are verified over time and usage [2]. We use the software to lay a trail, as it were, and if someone were to turn up with a bogus document but a matching hash, there would be all sorts of other trip wires to catch any simplistic usage.
Also, bear in mind that the two documents that hashed to the same value are pretty useless. It took Antoine Joux and his team 80,000 CPU hours to do it, even then. So in cryptography terms, this is a milestone in knowledge, not a risk: For practical purposes, any message digest still fits the bill, as long as it is designed into a comprehensive system that provides backup by entanglement [3].
Addendums:
Also see SHA0 crack paper. Especially, at Crypto, Wang, Feng, Lai, Yu announced a fast crack: Collisions for Hash Functions MD4, MD5, HAVAL-128 and RIPEMD. This reportedly also improves Joux, et al's result by 1000 on SHA-0, see Greg Rose's comment posted below.
Ed Felton reported a rumour that SHA-1 had already suffered the same fate, but this appeared to unfounded: so far, nothing but suggestions that SHA-1 looks shaky.
Also, Eric Rescorla gets more technical with the risks to systems, and agrees that this is big news but not big risks.
More links:
http://www.theregister.com/2004/08/19/hash_crypto/
http://www.certainkey.com/news/?12
http://eprint.iacr.org/2004/146
http://www.md5crk.com/sha0col/
http://www.tcs.hut.fi/~mjos/md5/
http://www.freedom-to-tinker.com/archives/000662.html
http://www.iacr.org/conferences/crypto2004/rump.html
http://www.computerworld.com/securitytopics/security/story/0,,95343,00.html?SKC=security-95343
[0] And it is in SHA-1 ...
[1] To see how message digests make a fine digital signature, see The Ricardian Contract which as an aside also carries a private-key signature as well.
[2] Maniatis and Baker, Secure History Preservation through Timeline Entanglement
[3] MD5 is the old favourite, which was first attacked in Dobertin's 1996 paper (and here) and now seems to be trashed in Wang, Feng, Lai, Yu paper Collisions for Hash Functions MD4, MD5, HAVAL-128 and RIPEMD.
-------- Original Message --------
Subject: Joux found a collision for SHA-0 !
Date: Fri, 13 Aug 2004 15:32:29 +0200
From: Pascal Junod
Organization: EPFL - LASEC
To: cryptography@metzdowd.com
Hi !
This has appeared on a french mailing-list related to crypto. The results of
Joux improve on those of Chen and Biham which will be presented next week at
CRYPTO'04.
Enjoy !
<quote>
</quote>Thursday 12th, August 2004
We are glad to announce that we found a collision for SHA-0.
First message (2048 bits represented in hex):
a766a602 b65cffe7 73bcf258 26b322b3 d01b1a97 2684ef53 3e3b4b7f 53fe3762
24c08e47 e959b2bc 3b519880 b9286568 247d110f 70f5c5e2 b4590ca3 f55f52fe
effd4c8f e68de835 329e603c c51e7f02 545410d1 671d108d f5a4000d cf20a439
4949d72c d14fbb03 45cf3a29 5dcda89f 998f8755 2c9a58b1 bdc38483 5e477185
f96e68be bb0025d2 d2b69edf 21724198 f688b41d eb9b4913 fbe696b5 457ab399
21e1d759 1f89de84 57e8613c 6c9e3b24 2879d4d8 783b2d9c a9935ea5 26a729c0
6edfc501 37e69330 be976012 cc5dfe1c 14c4c68b d1db3ecb 24438a59 a09b5db4
35563e0d 8bdf572f 77b53065 cef31f32 dc9dbaa0 4146261e 9994bd5c d0758e3dSecond message:
a766a602 b65cffe7 73bcf258 26b322b1 d01b1ad7 2684ef51 be3b4b7f d3fe3762
a4c08e45 e959b2fc 3b519880 39286528 a47d110d 70f5c5e0 34590ce3 755f52fc
6ffd4c8d 668de875 329e603e 451e7f02 d45410d1 e71d108d f5a4000d cf20a439
4949d72c d14fbb01 45cf3a69 5dcda89d 198f8755 ac9a58b1 3dc38481 5e4771c5
796e68fe bb0025d0 52b69edd a17241d8 7688b41f 6b9b4911 7be696f5 c57ab399
a1e1d719 9f89de86 57e8613c ec9e3b26 a879d498 783b2d9e 29935ea7 a6a72980
6edfc503 37e69330 3e976010 4c5dfe5c 14c4c689 51db3ecb a4438a59 209b5db4
35563e0d 8bdf572f 77b53065 cef31f30 dc9dbae0 4146261c 1994bd5c 50758e3dCommon hash value (can be found using for example "openssl sha file.bin"
after creating a binary file containing any of the messages)
c9f160777d4086fe8095fba58b7e20c228a4006bThis was done by using a generalization of the attack presented at Crypto'98
by Chabaud and Joux. This generalization takes advantage of the iterative
structure of SHA-0. We also used the "neutral bit" technique of Biham and
Chen (To be presented at Crypto'2004).The computation was performed on TERA NOVA (a 256 Intel-Itanium2 system
developped by BULL SA, installed in the CEA DAM open laboratory
TERA TECH). It required approximatively 80 000 CPU hours.
The complexity of the attack was about 2^51.We would like to thank CEA DAM, CAPS Entreprise and BULL SA for
their strong support to break this challenge.Antoine Joux(*) (DCSSI Crypto Lab)
Patrick Carribault (Bull SA)
Christophe Lemuet, William Jalby
(Universit'e de Versailles/Saint-Quentin en Yvelines)(*) The theoretical cryptanalysis was developped by this author.
The three others authors ported and optimized the attack on the TERA NOVA
supercomputer, using CAPS Entreprise tools.$hexdump fic1.bin
0000000 66a7 02a6 5cb6 e7ff bc73 58f2 b326 b322
0000010 1bd0 971a 8426 53ef 3b3e 7f4b fe53 6237
0000020 c024 478e 59e9 bcb2 513b 8098 28b9 6865
0000030 7d24 0f11 f570 e2c5 59b4 a30c 5ff5 fe52
0000040 fdef 8f4c 8de6 35e8 9e32 3c60 1ec5 027f
0000050 5454 d110 1d67 8d10 a4f5 0d00 20cf 39a4
0000060 4949 2cd7 4fd1 03bb cf45 293a cd5d 9fa8
0000070 8f99 5587 9a2c b158 c3bd 8384 475e 8571
0000080 6ef9 be68 00bb d225 b6d2 df9e 7221 9841
0000090 88f6 1db4 9beb 1349 e6fb b596 7a45 99b3
00000a0 e121 59d7 891f 84de e857 3c61 9e6c 243b
00000b0 7928 d8d4 3b78 9c2d 93a9 a55e a726 c029
00000c0 df6e 01c5 e637 3093 97be 1260 5dcc 1cfe
00000d0 c414 8bc6 dbd1 cb3e 4324 598a 9ba0 b45d
00000e0 5635 0d3e df8b 2f57 b577 6530 f3ce 321f
00000f0 9ddc a0ba 4641 1e26 9499 5cbd 75d0 3d8e
$ hexdump fic2.bin
0000000 66a7 02a6 5cb6 e7ff bc73 58f2 b326 b122
0000010 1bd0 d71a 8426 51ef 3bbe 7f4b fed3 6237
0000020 c0a4 458e 59e9 fcb2 513b 8098 2839 2865
0000030 7da4 0d11 f570 e0c5 5934 e30c 5f75 fc52
0000040 fd6f 8d4c 8d66 75e8 9e32 3e60 1e45 027f
0000050 54d4 d110 1de7 8d10 a4f5 0d00 20cf 39a4
0000060 4949 2cd7 4fd1 01bb cf45 693a cd5d 9da8
0000070 8f19 5587 9aac b158 c33d 8184 475e c571
0000080 6e79 fe68 00bb d025 b652 dd9e 72a1 d841
0000090 8876 1fb4 9b6b 1149 e67b f596 7ac5 99b3
00000a0 e1a1 19d7 899f 86de e857 3c61 9eec 263b
00000b0 79a8 98d4 3b78 9e2d 9329 a75e a7a6 8029
00000c0 df6e 03c5 e637 3093 973e 1060 5d4c 5cfe
00000d0 c414 89c6 db51 cb3e 43a4 598a 9b20 b45d
00000e0 5635 0d3e df8b 2f57 b577 6530 f3ce 301f
00000f0 9ddc e0ba 4641 1c26 9419 5cbd 7550 3d8e$ diff fic1.bin fic2.bin
Binary files fic1.bin and fic2.bin differ$ openssl sha fic1.bin
SHA(fic1.bin)= c9f160777d4086fe8095fba58b7e20c228a4006b$ openssl sha fic2.bin
SHA(fic2.bin)= c9f160777d4086fe8095fba58b7e20c228a4006b
--
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
* Pascal Junod
* Security and Cryptography Laboratory (LASEC) *
* Swiss Federal Institute of Technology (EPFL), CH-1015 Lausanne *
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
---------------------------------------------------------------------
The Cryptography Mailing List
Unsubscribe by sending "unsubscribe cryptography" to majordomo@metzdowd.com
August 10, 2004
Kerckhoffs' 6 principles from 1883
Auguste Kerckhoffs, a Dutch cryptographer who taught in France in the latter part of the 19th century, wrote an influential article that expounded basic principles of a communications security system [1]. Kerckhoffs' 6 basic principles are:
- The system must be practically, if not mathematically, indecipherable;
- It must not be required to be secret, and it must be able to fall into the hands of the enemy without inconvenience;
- Its key must be communicable and retainable without the help of written notes, and changeable or modifiable at the will of the correspondents;
- It must be compatible with the means of communication;
- It must be portable, and its usage and function must not require the concourse of several people;
- Finally, it is necessary, given the circumstances that command its application, that the system be easy to use, requiring neither mental strain nor the knowledge of a long series of rules to observe.
This list was derived from the translation from the original French [2], also one on Wikipedia [3], and slightly updated for modern times (point 4).
Principle 2 is often referred to as Kerckhoffs' law, and also known as Shannon's maxim: "the enemy knows the system [4]." I guess cryptographers think that makes it more important, but I can't see it myself, there are plenty of systems around that fail on the other principles, and plenty of systems around that deliver security through obscurity.
Like any set of principles, knowing them is a given. It's knowing when to break them that distinguishes [5].
[1] Auguste Kerckhoffs, "La cryptographie militaire ('Military Cryptography')," Journal des sciences militaires, vol. IX, pp. 5-38, Jan. 1883, pp. 161-191, Feb. 1883.
[2] fabien a. p. petitcolas's site includes the original French article as well.
http://www.petitcolas.net/fabien/kerckhoffs/index.html#english
[3] http://en.wikipedia.org/wiki/Auguste_Kerckhoffs
[4] http://en.wikipedia.org/wiki/Kerckhoffs'_law
[5] See for example Leo Marks' use of written keys silk as described in "Between Silk and Cyanide". Steve Bellovin summarised this on 9th September 2004, which might be in the cryptography archives by tomorrow.
July 17, 2004
Hubristic Cryptography
Koblitz and Menezes have posted a new paper Another Look at "Provable Security". Serious readers in cryptography and philosophy of science (you know who you are) should grab a copy, but for the rest of us, turn to Eric Rescorla's shorter review.
In summary of his summary, the proofs are unproven, their assumptions are unrealistic, and a lot of the attacks that are contrived are also unrealistic. The result? Designers and programmers bypass all that and just code up what they can.
I especially like the "Fundamental Tenet of Cryptography" [Kaufman, Perlman, and Speciner]
"If lots of smart people have failed to solve a problem, then it probably won't be solved (soon).."
which brings to mind Adi Shamir's 1st law of cryptology:
"There are no secure systems..."
Come to think of it, Adi's other comments on that link bear much re-reading! These signs of revisionism from the academic side of cryptology are very welcome. They make utter sense to us higher layer geeks who have to build systems based on these weird and wonderful psuedo mathematical properties. It's definitely the case that for 99% of the geeks I've ever met, the notion that some claim or other is proven gets glossed over very quickly.
Not that the coders and other users of cryptography are so much better; we are currently going through our own era of revisionism. No-risk cryptosystems such as SSL and certificate authority-signed certs are being dissected in all their embarrassing real world weakness, you can't give away a PKI system these days, and all the while, opportunistic cryptography systems such as SSH and PGP continue to plod along, doing the work in a no-fuss but secure fashion.
Bringing the hubrists to task is a noble one, and only made more noble by a future generation's challenge to our own hubris.
July 12, 2004
Jabber does Simple Crypto - Yoo Hoo!
Will K has alerted me to this: Over in the Jabber community, the long awaited arisal of opportunistic, ad hoc cryptography has spawned a really simple protocol to use OpenPGP messages over chat. It's so simple, you can see everything you want in this piece of XML:
<message to='reatmon@jabber.org/jarl' from='pgmillard@jabber.org/wj_dev2'>
<body>This message is encrypted.</body>
<x xmlns='jabber:x:encrypted'>
qANQR1DBwU4DX7jmYZnncmUQB/9KuKBddzQH+tZ1ZywKK0yHKnq57kWq+RFtQdCJ
[snip]
Oin0vDOhW7aC
=CvnG</x>
</message>
Well, life doesn't get much simpler. So far it is lacking a key exchange format, but hey, here's one I knocked up:
<message to='reatmon@jabber.org/jarl' from='pgmillard@jabber.org/wj_dev2'>
<body>This message includes sender's public key.</body>
<x xmlns='jabber:x:publickey'>
mQGiBDjddDERBADBnXl2kf4gLFNSLs4BRt/tt/ilv+wnC5HFgSpKyUk/ja2uKJ2C
[snip]
E7U1RhQBQTI=
=ze8A</x>
</message>
Yeah gods, it is so simple, it's embarrassing. Here's the wishlist for a portable, popular IM protocol for secure chat:
- Add a button to create a PGP key pair and store it.
- Add a message to send the public key from Alice to Bob (like above).
- Add some GUI glue to do a "bootstrap to secure comms".
- Clean up issues like key verification ANOTHER DAY.
Hey presto, a secure chat. Yeah, sure, those nasty ugly bogeymen, the MITMs, could sneak in and do something nasty, but when that happens (don't hold your breath), we can worry about that (hint: web of trust is easy to add...).
One thing wasn't clear - the JEP document above indicates that Presence messages were signed. Anybody got a clue as to why anyone would sign a presence message?
June 12, 2004
WYTM - who are you?
The notion of WYTM ("what's your threat model?") is the starting point for a lot of analysis in the cryptographic world. Accepted practice has it that if you haven't done the WYTM properly, the results will be bad or useless.
Briefly, the logic goes, if you don't understand the threats that you are trying to secure against, then you will likely end up building something that doesn't cover those threats. Because security is hard, it's complex, and it is so darn easy to get drawn down the wrong path. We saw this in secure browsing, and the results are unfortunate [1].
So we need a methodology to make sure the end result justified the work put in. And that starts with WYTM: identify your threats, categorise and measure their risks & costs. Then, when we construct the security model, we decide what risks we can afford to cover, and which ones we can't.
But some systems seem to defy that standard security modelling. Take, for example, email.
It is difficult to identify a successful email security system; it's one of those areas that seems so obvious it should be easy, but email to date remains deplorably unprotected.
It could well be that the fault for this lies in WYTM. The problem is rather blatent when pointed out: who is the "you" in "what's your threat model?"
Who are is it we are talking about when we decide to protect someone? All systems of computing include lots of users, but most of them generally have something in common: they work in a firm or they are users of some corporate system, for example. At least, when going to the effort of building a crypto system, there is generally enough commonality to construct a viable model of who the target user is.
This doesn't work for email - "who" changes from person to person, it includes near a billion parties, and many more combinations. What's more, the only commonality seems to be that they are humans, and even that assumption is a little weak given all the automatic senders of email.
The guys who wrote the original email system, and indeed the Internet, cottoned on to one crucial point here: there is no permission needed and no desire to impose the sort of structure that would have made profiling of the user plausible.
No profile of "who" may mean no WYTM.
For example, when Juan sends sexy email to Juanita, it has a very different threat model to when legal counsel sends email to a defendent. Consider contracts fly between trading partners. Or, soon-to-be-divorcees searching for new partners via dating agencies.
Or ... the list goes on. There is literally no one threat model that can deal with this, as the uses are so different, and some of the requirements are diametrically opposed: legal wants the emails escrowed, and authenticated, whereas dating women consider their anonymity and untraceability valuable.
Seen in this light, there isn't one single threat model. Which means either we develop the threat model to end all threat models (!) or we have lots of different threat models.
It is clearly intractable to develop one single threat model, and it quite possibly is intractable to develop a set of them.
So what is a poor cryptoplumber to do? Well, in the words of Sherlock Holmes, "when you have eliminated the impossible, whatever remains, however improbable, must be the truth."
For some systems, WYTM is simply inadequate. What then must we do? Design without WYTM.
With no threat model, to hand, we need a new measure to judge whether to include a given protection or not. About the only answer that I can come up with is based on economic criteria.
In building email security, nobody is paying us for it, so whatever is good and free should be used. This is is opportunistic cryptography: protect what you can for free, or for cheap, and worry about the rest later.
In email terms, this would involve:
* tunnelling over SSH to SMTP servers,
* implementing START/TLS, with self-signed certs
* implementing PGP-enabled gateways like the "Universal" product and many forerunners
* and more...
By definition, there are gaps. But with opportunistic cryptography, we don't so much worry about that, because what we are doing is free anyway.
[1] WYTM?
June 10, 2004
Big and Brotherly
The White House administration has apparently defied the US Congress and kept the controversial "Total Information Awareness" going as a secret project. A politics journal called Capitol Hill Blue has exposed what it claims is the TIA project operating with no change.
Whether this is all true, or just another anti-Bush story by Democrat apologists in the leadup to the election, is all open to question. Republican apologists can now chime in on cue. While they are doing that, here are some of the impressive claims of monitoring of the US citizen's habits:
- cellphone calls, indexed by serial numbers, matched with billing records
- key word monitoring - the old echelon thing
- use of private contractors to get around prohibitions on federal spying
- trains, planes, and automobiles. Oh, and hotels reservations.
- satellite TV - program purchases on adult movies reported to DOJ.
If you're looking for the fire, that's an awful lot of smoke. What does all this mean? Well, for one, it should start to put pressure on the open source crypto community to start loosening up. Pretty much all of that can be covered using free and easy techniques that have otherwise been eschewed for lack of serious threat models. I speak of course of using opportunistic cryptography to get protection deployed as widely as possible.
This could take as back to the halcyon days of the 90s, when the open source community fought with the dark side to deploy crypto to all. A much more noble battle than today's windmill tinting against credit card thieves and other corporately inspired woftams. We didn't, it seems, succeed in protecting many people, as crypto remains widely undeployed, and where it is deployed, it is of uncertain utility. But, we're older and wiser now. Maybe it's time for another go
From Capitol Hill Blue
What Price Freedom?
How Big Brother Is Watching, Listening and Misusing Information About You
By TERESA HAMPTON & DOUG THOMPSON
Jun 8, 2004, 08:19
You're on your way to work in the morning and place a call on your wireless phone. As your call is relayed by the wireless tower, it is also relayed by another series of towers to a microwave antenna on top of Mount Weather between Leesburg and Winchester, Virginia and then beamed to another antenna on top of an office building in Arlington where it is recorded on a computer hard drive.
The computer also records you phone digital serial number, which is used to identify you through your wireless company phone bill that the Defense Advanced Research Projects Agency already has on record as part of your permanent file.
A series of sophisticated computer programs listens to your phone conversation and looks for "keywords" that suggest suspicious activity. If it picks up those words, an investigative file is opened and sent to the Department of Homeland Security.
Congratulations. Big Brother has just identified you as a potential threat to the security of the United States because you might have used words like "take out" (as in taking someone out when you were in fact talking about ordering takeout for lunch) or "D-Day" (as in deadline for some nefarious activity when you were talking about going to the new World War II Memorial to recognize the 60th anniversary of D-Day).
If you are lucky, an investigator at DHS will look at the entire conversation in context and delete the file. Or he or she may keep the file open even if they realize the use of words was innocent. Or they may decide you are, indeed, a threat and set up more investigation, including a wiretap on your home and office phones, around-the-clock surveillance and much closer looks at your life.
Welcome to America, 2004, where the actions of more than 150 million citizens are monitored 24/7 by the TIA, the Terrorist Information Awareness (originally called Total Information Awareness) program of DARPA, DHS and the Department of Justice.
Although Congress cut off funding for TIA last year, the Bush Administration ordered the program moved into the Pentagon's "black bag" budget, which is neither authorized nor reviewed by the Hill. DARPA also increased the use of private contractors to get around privacy laws that would restrict activities by federal employees.
Six months of interviews with security consultants, former DARPA employees, privacy experts and contractors who worked on the TIA facility at 3701 Fairfax Drive in Arlington reveal a massive snooping operation that is capable of gathering - in real time - vast amounts of information on the day to day activities of ordinary Americans.
Going on a trip? TIA knows where you are going because your train, plane or hotel reservations are forwarded automatically to the DARPA computers. Driving? Every time you use a credit card to purchase gas, a record of that transaction is sent to TIA which can track your movements across town or across the country.
Use a computerized transmitter to pay tolls? TIA is notified every time that transmitter passes through a toll booth. Likewise, that lunch you paid for with your VISA becomes part of your permanent file, along with your credit report, medical records, driving record and even your TV viewing habits.
Subscribers to the DirecTV satellite TV service should know - but probably don't - that every pay-per-view movie they order is reported to TIA as is any program they record using a TIVO recording system. If they order an adult film from any of DirecTV's three SpiceTV channels, that information goes to TIA and is, as a matter of policy, forwarded to the Department of Justice's special task force on pornography.
"We have a police state far beyond anything George Orwell imagined in his book 1984," says privacy expert Susan Morrissey. "The everyday lives of virtually every American are under scrutiny 24-hours-a-day by the government."
Paul Hawken, owner of the data information mining company Groxis, agrees, saying the government is spending more time watching ordinary Americans than chasing terrorists and the bad news is that they aren't very good at it.
"It's the Three Stooges go to data mining school," says Hawken. "Even worse, DARPA is depending on second-rate companies to provide them with the technology, which only increases the chances for errors."
One such company is Torch Concepts. DARPA provided the company with flight information on five million passengers who flew Jet Blue Airlines in 2002 and 2003. Torch then matched that information with social security numbers, credit and other personal information in the TIA databases to build a prototype passenger profiling system.
Jet Blue executives were livid when they learned how their passenger information, which they must provide the government under the USA Patriot Act, was used and when it was presented at a technology conference with the title: Homeland Security - Airline Passenger Risk Assessment.
Privacy Expert Bill Scannell didn't buy Jet Blue's anger.
"JetBlue has assaulted the privacy of 5 million of its customers," said Scannell. "Anyone who flew should be aware and very scared that there is a dossier on them."
But information from TIA will be used the DHS as a major part of the proposed CAPSII airline passenger monitoring system. That system, when fully in place, will determine whether or not any American is allowed to get on an airplane for a flight.
JetBlue requested the report be destroyed and the passenger data be purged from the TIA computers but TIA refuses to disclose the status of either the report or the data.
Although exact statistics are classified, security experts say the U.S. Government has paid out millions of dollars in out-of-court settlements to Americans who have been wrongly accused, illegally detained or harassed because of mistakes made by TIA. Those who accept settlements also have to sign a non-disclosure agreement and won't discuss their cases.
Hawken refused to do business with DARPA, saying TIA was both unethical and illegal.
"We got a lot of e-mails from companies - even conservative ones - saying, 'Thank you. Finally someone won't do something for money,'" he adds.
Those who refuse to work with TIA include specialists from the super-secret National Security Agency in Fort Meade, MD. TIA uses NSA's technology to listen in on wireless phone calls as well as the agency's list of key words and phrases to identify potential terrorist activity.
"I know NSA employees who have quit rather than cooperate with DARPA," Hawken says. "NSA's mandate is to track the activities of foreign enemies of this nation, not Americans."
© Copyright 2004 Capitol Hill Blue
May 26, 2004
Turing Lecture by Adi Shamir
The eponymous inventors of RSA, Drs Rivest, Shamir, and Adleman, were awarded the Turing Award for 2002 [1]. For those who don't know, the Turing Award, named after Alan Turing (the inventor of the modern computer architecture, and also the inventor of the Turing Test), is the premier prize in the computing world. It's a bit like a Nobel for software, but software was invented after dynamite.
In the three-way Turing Lectures, Professors Adleman and Rivest talked about the early days of RSA, and it was left to Professor Adi Shamir to present "A Status Report [2]" as his contribution. Three (quick) slides that leaped out, see below.
What is Prof Shamir trying to say? To me, he is confiming that the current cycle of revisionism in cryptography and software engineering is now acceptable mainstream thinking, if not complete. It is now accepted that Internet security modelling in the 90s was flawed, based on a poor understanding of the role of risk in cryptography systems.
The goal of practical cryptography is to improve the security, at a cost that is less than the benefit gained. Don't try and solve it, because you can't. As Prof. Shamir says, "absolutely secure systems do not exist.
Cryptographic misconceptions
- By policy makers: crypto is dangerous, but: - weak crypto is not a solution - controls can't stop the inevitable
- By researchers: A provably secure system is secure, but:
- proven false by indirect attacks
- can be based on false assumptions
- requires careful choice of parameters- By implementers: Cryptography solves everything, but:
- only basic ideas are successfully deployed
- only simple attacks are avoided
- bad crypto can provide a false sense of security
The three laws of security:
- Absolutely secure systems do not exist
- To halve your vulnerability, you have to double your expenditure
- Cryptography is typically bypassed, not penetrated
Cryptographic predictions:
- AES will remain secure for the forseeable future
- Some PK schemes and key sizes will be successfully attacked in the next few years
- Crypto will be invisibly everywhere
- Vulnerabilities will be visibly everywhere
- Crypto research will remain vigorous, but only its simplest ideas will become practically useful
- Non-crypto security will remain a mess
[1] 2002 A.M. Turning Award Winners, for seminal contributions to the theory and practical applications of Public Key Cryptography, Dr. Leonard M. Adleman, Dr. Ronald L. Rivest, Dr. Adi Shamir,
http://www.acm.org/awards/turing_citations/rivest-shamir-adleman.html?code=nlsec121
[2] Dr. Adi Shamir, "Turing Lecture on Cryptology: A Status Report,"
http://www.acm.org/awards/turing_lectures_project/turing/S/s-pp/shamir_1files.html
May 20, 2004
Mutual Funds - Timestamping
In a rare arisal of a useful use of cryptography in real life, the mutual funds industry is looking to digital timestamping to save its bacon [1]. Timestamping is one of those oh-so-simple applications of cryptography that most observers dismiss for its triviality.
Timestamping is simply where an institution offers to construct a hash or message digest over your document and the current time. By this, evidence is created that your document was seen at that time. There are a few details as to how to show that the time in ones receipt is the right one, but this is trivial (meaning we know how to do it, not that it is cheap to code up..) by interlinking a timestamp with the preceeding and following ones. So without even relying on the integrity of the institution, we can make strong statements such as "after this other one and before this next one."
The SEC is proposing rule changes to make the 4pm deadline more serious and proposes USPS timestamping as one way to manage this [2]. There are several things wrong with the USPS and SEC going into this venture. But there are several things right with timestamping in general, to balance this. On the whole, given the complicated panopoly of strategic issues outlined earlier, timestamping could be a useful addition to the mutual funds situation [3].
First what's wrong: timestamping doesn't need to be regulated or charged for, as it could easily be offered as a loss leader by any institution. A server can run a timestamping service and do 100,000 documents a day without noticing. If there is any feeling that a service might not be reliable, use two! And, handing this commercial service over to the USPS makes no regulatory sense in a competitive market, especially when there are many others out there already [4].
Further, timestamping is just a small technical solution. It shouldn't need to be regulated at all, as it should be treated in any forum as evidence. Either the mutual fund accepts orders with timestamps, or it doesn't. If it doesn't, then it is taking a risk of being gamed, and not having anything to cover it. An action will now be possible against it. If it does only accept timestamped orders, then it's covered. Timestamping is better seen as "best practices" not as Regulation XXX.
Especially, there are better ways of doing it. A proper RTGS transactional system has better protections built in of its nature than timestamping can ever provide, and in fact a regulation requiring timestamping will interfere with the implementation of proper solutions (see for example the NSCC solution in [1]). It will become just another useless reg that has to be complied with, at cost to all and no benefit to anyone.
Further, it should be appreciated that timestamping does not "solve the problem" (but neither does the NSCC option). What it allows for is evidence that orders were received by a certain time. As explained elsewhere, putting a late order in is simply one way of gaming the fund [5]. There are plenty of other ways.
Coming back to where we are now, though, timestamping will allow the many small pension traders to identify when they got their order in. One existing gaping loophole is that small operators are manual processors and can take a long time about what they do. Hence 4pm was something that could occur the next day, as agreed by the SEC! With timestamping, 4pm could still be permitted to occur tomorrow, as long as the pension trader has timestamped some key piece of info that signals the intent.
For this reason, timestamping helps, and it won't hinder if chosen. The SEC is to be applauded for pushing this forward with a white paper. Just as long as they hold short of regulation, and encourage mutual funds to adopt this on an open, flexible basis as we really don't want to slow down the real solutions, later on.
[1] U.S. Postal Service Wants to Deliver Fairness to Mutual Funds
http://www.wbex.com/script/headline_newsmanager.php?id=294597&pagecontent=business&feed_id=43
[2] White Paper on Mutual Fund Reform and the USPS Electronic Postmark®
http://www.sec.gov/rules/proposed/s72703/uspostal020204.htm
[3] Mutual Funds - the Softball Option
http://www.financialcryptography.com/mt/archives/000140.html
[4] E.g., DigiStamp, http://www.digistamp.com/
[5] Nesfield and Grigg, "Mutual Funds and Financial Flaws," testimony before U.S. Senate Finance Committee, 27th January 2004.
http://iang.org/papers/mutual_funds.html
May 18, 2004
EU seeks quantum cryptography response to Echelon
MAY 17, 2004 (IDG NEWS SERVICE) - The European Union plans to invest $13 million during the next four years to develop a secure communication system based on quantum cryptography, using physical laws governing the universe on the smallest scale to create and distribute unbreakable encryption keys, project coordinators said today.
The goal is to create unbreakable encryption keys
News Story by Philip Willan
If successful, the project will produce the cryptographer's Holy Grail -- absolutely unbreakable code -- and thwart the eavesdropping efforts of espionage systems such as Echelon, which intercepts electronic messages on behalf of the intelligence services of the U.S., Britain, Canada, New Zealand and Australia.
"The aim is to produce a communication system that cannot be intercepted by anyone, and that includes Echelon," said Sergio Cova, a professor from the electronics department of Milan Polytechnic and one of the project's coordinators. "We are talking about a system that requires significant technological innovations. We have to prove that it is workable, which is not the case at the moment."
Major improvements in geographic range and speed of data transmission will be required before the system becomes a commercial reality, Cova said.
"The report of the European Parliament on Echelon recommends using quantum cryptography as a solution to electronic eavesdropping. This is an effort to cope with Echelon," said Christian Monyk, the director of quantum technologies at Austrian company ARC Seibersdorf Research GmbH and overall coordinator of the project. Economic espionage has caused serious harm to European companies in the past, Monyk noted.
"With this project, we will be making an essential contribution to the economic independence of Europe," he said.
Quantum cryptography takes advantage of the physical properties of light particles, known as photons, to create and transmit binary messages. The angle of vibration of a photon as it travels through space -- its polarization -- can be used to represent a zero or a one under a system first devised by scientists Charles H. Bennett and Gilles Brassard in 1984. It has the advantage that any attempt to intercept the photons is liable to interfere with their polarization and can therefore be detected by those operating the system, the project coordinators said.
An intercepted key would therefore be discarded and a new one created for use in its place.
The new system, known as SECOQC (Secure Communication based on Quantum Cryptography), is intended for use by the secure generation and exchange of encryption keys, rather than for the actual exchange of data, Monyk said.
"The encrypted data would then be transmitted by normal methods," he said. Messages encrypted using quantum mechanics can currently be transmitted over optical fibers for tens of miles. The European project wants to extend that range by combining quantum physics with other technologies, Monyk said.
"The important thing about this project is that it is not based solely on quantum cryptography but on a combination with all the other components that are necessary to achieve an economic application," he said. "We are taking a really broad approach to quantum cryptography, which other countries haven't done."
Experts in quantum physics, cryptography, software and network development from universities, research institutes and private companies in Austria, Belgium, Britain, Canada, the Czech Republic, Denmark, France, Germany, Italy, Russia, Sweden and Switzerland will be contributing to the project, Monyk said.
In 18 months, project participants will assess progress on a number of alternative solutions and decide which technologies seem most promising and merit further development, project coordinators said. The goal is to have a workable technology ready in four years, but SECOQC will probably require three to four years of work beyond that before commercial use, Monyk said.
Cova was more cautious, noting, "This is the equivalent of the first flight of the Wright brothers, so it is too early to be talking already about supersonic transatlantic travel."
The technological challenges facing the project include the creation of sensors capable of recording the arrival of photons at high speed and photon generators that produce a single photon at a time, Cova said. "If two or three photons are released simultaneously, they become vulnerable to interception," he said.
Monyk believes there will be a global market of several million users once a workable solution has been developed. A political decision will have to be made regarding who those users will be in order to prevent terrorists and criminals from taking advantage of the completely secure communication network, he said.
"In my view, it should not be limited to senior government officials and the military, but made available to all users who need really secure communications," Monyk said, citing banks, insurance companies and law firms as potential clients. A decision will have to be made as to whether and how a key could be made available to law enforcement authorities under exceptional circumstances.
"It won't be up to us to decide who uses our results," said Cova.
Reprinted with permission from For more news from IDG visit IDG.net
Story copyright 2004 International Data Group. All rights reserved.
See QC - another hype cycle for commentary
May 16, 2004
US intelligence exposed as student decodes Iraq memo
Armed with little more than an electronic dictionary and text-analysis software, Claire Whelan, a graduate student in computer science at Dublin City University in Ireland, has managed to decrypt words that had been blotted out from declassified documents to protect intelligence sources.
13 May 2004 DECLAN BUTLER
[IMAGE]It took less then a week to decipher the blotted out words.
She and one of her PhD supervisors, David Naccache, a cryptographer with Gemplus, which manufactures banking and security cards, tackled two high-profile documents. One was a memo to US President George Bush that had been declassified in April for an inquiry into the 11 September 2001 terrorist attacks. The other was a US Department of Defense memo about who helped Iraq to 'militarize' civilian Hughes helicopters.
It all started when Naccache saw the Bush memo on television over Easter. "I was bored, and I was looking for challenges for Claire to solve. She's a wild problem solver, so I thought that with this one I'd get peace for a week," Naccache says. Whelan produced a solution in slightly less than that.
Demasking blotted out words was easy, Naccache told Nature. "Optical recognition easily identified the font type - in this case Arial - and its size," he says. "Knowing this, you can estimate the size of the word behind the blot. Then you just take every word in the dictionary and calculate whether or not, in that font, it is the right size to fit in the space, plus or minus 3 pixels.
"
A computerized dictionary search yielded 1,530 candidates for a blotted out word in this sentence of the Bush memo: "An Egyptian Islamic Jihad (EIJ) operative told an XXXXXXXX service at the same time that Bin Ladin was planning to exploit the operative's access to the US to mount a terrorist strike." A grammatical analyser yielded just 346 of these that would make sense in English.
A cursory human scan of the 346 removed unlikely contenders such as acetose, leaving just seven possibilities: Ugandan, Ukrainian, Egyptian, uninvited, incursive, indebted and unofficial. Egyptian seems most likely, says Naccache. A similar analysis of the defence department's memo identified South Korea as the most likely anonymous supplier of helicopter knowledge to Iraq.
Intelligence experts say the technique is cause for concern, and that they may think about changing procedures. One expert adds that rumour-mongering on probable fits might engender as much confusion and damage as just releasing the full, unadulterated text.
Naccache accepts the criticism that although the technique works reasonably well on single words, the number of candidates for more than two or three consecutively blotted out words would severely limit it. Many declassified documents contain whole paragraphs blotted out. "That's impossible to tackle," he says, adding that, "the most important conclusion of this work is that censoring text by blotting out words and re-scanning is not a secure practice".
Naccache and Whelan presented their results at Eurocrypt 2004, a meeting of security researchers held in Interlaken, Switzerland, in early May. They did not present at the formal sessions, but at a Tuesday evening informal 'rump session', where participants discuss work in progress. "We came away with the prize for the best rump-session talk - a huge cow-bell," says Naccache.
(c) Nature News Service / Macmillan Magazines Ltd 2004
SSL secure browsing - attack tree Mindmap
Here is a work in progress Mindmap on all threats to the secure browsing process. It purports to be an attack tree, which is a technique to include and categorise all possible threats to a process. It is one possible aid to constructing a threat model, which latter is a required step to constructing a security model. The mindmap supports another work in progress on threat modelling for secure browsing.
This work was inspired by the Mozilla project's new policy on new CAs, coordinated by Frank Hecker. Unpublished as yet, it forms part of the controversial security debate surrounding the CA model.
( To recap: the secure browsing security model uses SSL as a protocol and the Certificate Authority model as the public key authentication regime, all wrapped up in HTTPS within the browser. Technically, the protocol and key regime are separate, but in practice they are joined at the hip, so any security modelling needs to consider them both together. SSL - the protocol part - has been widely scrutinised and has evolved to what is considered a secure form. In contrast the CA model has been widely criticised, and has not really evolved since its inception. It remains the weak link in security.
As part of a debate on how to address the security issues in secure browsing and other applications that use SSL/CA such as S/MIME, the threat model is required before we can improve the security model. Unfortunately, the original one is not much use, as it was a theoretical prediction of the MITM that did not come to pass. )
May 10, 2004
Secret Ballot Receipts and Transparent Integrity
Professor David Chaum is working on the voting problem. On the face of it, this is an intractable problem given the requirement of voter secrecy. Yet David Chaum is one of the handful of cryptographers who have changed the game - his blinded tokens invention remains one of the half dozen seminal discoveries of the last half-century.
Of course, in financial voting, the requirement for ballot box privacy is not so stringent. Indeed votes are typically transferable as proxies, if not strictly saleable. For this reason, we can pretty much accomplish financial voting with what we know and have already (an addition of a nymous feature or a new issue would be two ways to do it).
But it is always worth following what is happening on the other side of the fence. Here's the abstract for David's paper, Secret Ballot Receipts and Transparent Integrity:
"Introduced here is a new kind of receipt. In the voting booth, it is as convincing as any receipt. And once the voter takes it out of the booth, it can readily be used to ensure that the votes it contains are included correctly in the final tally. But it cannot be used in improper influence schemes to show how the voter voted. The system incorporating the receipts can be proven mathematically to ensure integrity of the election against whatever incorrectly-behaving machines might do to surreptitiously change votes. Not only can receipts and this level of integrity enhance voter confidence, but they eliminate the need for trusted voting machines."
April 27, 2004
QC - another hype cycle
Cryptographers and software engineers are looking askance at the continued series of announcements in the Quantum Cryptography world. They are so ... vacuous, yet, so repititious. Surely nobody is buying this stuff?
'Fraid so. It's another hype cycle, in the making. Here's my analysis, as posted to the cryptography list.
Subject: Re: Bank transfer via quantum crypto
From: "Ian Grigg" <iang@...>
Date: Sun, April 25, 2004 14:47
To: "Ivan ..."
Cc: "Metzdowd Crypto" <cryptography@metzdowd.com>
Ivan Krstic wrote:
> I have to agree with Perry on this one: I simply can't see a compelling
> reason for the push currently being given to ridiculously overpriced
> implementations of what started off as a lab toy, and what offers - in
> all seriousness - almost no practical benefits over the proper use of
> conventional techniques.
You are looking at QC from a scientific perspective.
What is happening is not scientific, but business.
There are a few background issues that need to be
brought into focus.
1) The QC business is concentrated in the finance
industry, not national security. Most of the
fiber runs are within range. 10 miles not 100.
2) Within the finance industry, the security
of links is done majorly by using private lines.
Put in a private line, and call it secure because
only the operator can listen in to it.
3) This model has broken down somewhat due to the
arisal of open market net carriers, open colos, etc.
So, even though the mindset of "private telco line
is secure" is still prevalent, the access to those
lines is much wider than thought.
4) there is eavesdropping going on. This is clear,
although it is difficult to find confirmable
evidence on it or any stats:
"Security forces in the US discovered an illegally installed fiber
eavesdropping device in Verizon's optical network. It was placed at a
mutual fund company?..shortly before the release of their quarterly
numbers" Wolf Report March, 2003
(some PDF that google knows about.) These things
are known as vampire taps. Anecdotal evidence
suggests that it is widespread, if not exactly
rampant. That is, there are dozens or maybe hundreds
of people capable of setting up vampire taps. And,
this would suggest maybe dozens or hundreds of taps
in place. The vampires are not exactly cooperating
with hard information, of course.
5) What's in it for them? That part is all too
clear.
The vampire taps are placed on funds managers to
see what they are up to. When the vulnerabilities
are revealed over the fibre, the attacker can put
in trades that take advantage. In such a case,
the profit from each single trade might be in the
order of a million (plus or minus a wide range).
6) I have not as yet seen any suggestion that an
*active* attack is taking place on the fibres,
so far, this is simply a listening attack. The
use of the information happens elsewhere, some
batch of trades gets initiated over other means.
7) Finally, another thing to bear in mind is that
the mutual funds industry is going through what
is likely to be the biggest scandal ever. Fines
to date are at 1.7bn, and it's only just started.
This is bigger than S&L, and LTCM, but as the
press does not understand it, they have not
presented it as such. The suggested assumption
to draw from this is that the mutual funds are
*easy* to game, and are being gamed in very many
and various fashions. A vampire tap is just one
way amongst many that are going on.
So, in the presence of quite open use of open
lines, and in the presence of quite frequent
attacking on mutual funds and the like in order
to game their systems (endemic), the question
has arisen how to secure the lines.
Hence, quantum cryptogtaphy. Cryptographers and
engineers will recognise that this is a pure FUD
play. But, QC is cool, and only cool sells. The
business circumstances are ripe for a big cool
play that eases the fears of funds that their
info is being collected with impunity. It shows
them doing something.
Where we are now is the start of a new hype
cycle. This is to be expected, as the prior
hype cycle(s) have passed. PKI has flopped and
is now known in the customer base (finance
industry and government) as a disaster. But,
these same customers are desperate for solutions,
and as always are vulnerable to a sales pitch.
QC is a technology who's time has come. Expect
it to get bigger and bigger for several years,
before companies work it out, and it becomes the
same disputed, angry white elephant that PKI is
now.
If anyone is interested in a business idea, now
is the time to start building boxes that do "just
like QC but in software at half the price." And
wait for the bubble to burst.
iang
PS: Points 1-7 are correct AFAIK. Conclusions,
beyond those points, are just how I see it, IMHO.
April 20, 2004
DPA patents
Cryptography Research, the California company that announced the discovery of differential power analysis around late 1997, have picked up a swag of patents covering defences against DPA. One can't read too much into the event itself, as presumably they filed all these a long time ago, way back when, and once filed you just have to stay the distance. It's what companies do, over that side, and if you didn't predict it, you were naive (I didn't, and I was).
What is more significant is the changed market place for smart cards. The Europeans dominated this field due to their institutional structure. Big contracts from large telcos and banks lead to lots of support, all things that were lacking in the fragmented market in the US. Yet the Europeans kept their secrets too close to the chest, and now they are paying for the vulnerability.
CR managed to discover and publish a lot of the stuff that the Europeans thought they had secretly to themselves. Now CR has patented it. What a spectacular transfer of rights - even if the European labs can prove they invented it first (I've seen some confidential stuff on this from my smart card days) because they kept it secret, they lose it. Secrets don't enjoy any special protection.
Security by obscurity loses in more ways than one. What's more, royalties and damages may be due, just like in the Polaroid film case. When both sides had the secret, it didn't matter who invented it, it was who patented it first that won.
We will probably see the switch of a lot more smart card work across to CR's labs, and a commensurate rush by the European labs to patent everything they have left. Just a speculative guess, mind. With those patents in hand, CR's future looks bright, although whether this will prove to be drain or a boon to the smart card world remains to be seen.
Cryptography Research Granted Patents for Safer Smart Cards
Technology Prevents DPA Attacks to Combat Fraud and Piracy
SAN FRANCISCO, April 19 /PRNewswire/ -- Cryptography Research, Inc., a leader in advanced security research and engineering, today announced it has been granted several broad patents on technology that reduces fraud and piracy by protecting smart cards and other systems from Differential Power Analysis (DPA) attacks. The company developed the technology to help cryptographic device manufacturers, systems integrators, and smart card issuers develop secure, DPA-resistant implementations for use in financial, pay television, mass transit, secure identification and wireless industries.
Differential Power Analysis involves measuring the electrical power consumption of smart cards and other cryptographic devices. Statistical methods are then used to extract cryptographic keys and other secrets.
Vulnerable devices are at risk for compromises including fraud, cloning, impersonation, counterfeiting, and piracy. Although DPA attacks typically require technical skill to implement, they can be repeated with a few thousand dollars of standard equipment, and can often break a device in a few minutes. DPA and related attacks were originally discovered at Cryptography Research in the 1990s.
"We are proud to have our work recognized by the United State Patent and Trademark Office," said Paul Kocher, president of Cryptography Research. "As a research-focused company, we rely on patents to help us commercialize our results and make our ongoing R&D efforts possible."
The Cryptography Research DPA patents broadly cover countermeasures to DPA attacks, and include:
-- U.S. Patent #6,654,884: Hardware-level mitigation and DPA countermeasures for cryptographic devices;
-- U.S. Patent #6,539,092: Leak-resistant cryptographic indexed key update;
-- U.S. Patent #6,510,518: Balanced cryptographic computational method and apparatus for leak minimization in smartcards and other cryptosystems;
-- U.S. Patent #6,381,699: Leak-resistant cryptographic method and apparatus;
-- U.S. Patent #6,327,661: Using unpredictable information to minimize leakage from smartcards and other cryptosystems;
-- U.S. Patent #6,304,658: Leak-resistant cryptographic method and apparatus;
-- U.S. Patent #6,298,442: Secure modular exponentiation with leak minimization for smartcards and other cryptosystems; and
-- U.S. Patent #6,278,783: DES and other cryptographic, processes with leak minimization for smartcards and other cryptosystems.
Other Cryptography Research patents are issued and pending in the United States, Europe, Japan, Canada and other countries.
According to the Smart Card Alliance, an industry trade group, the United States became the third largest market for microprocessor smart cards in 2003, and more than 70 million smart cards shipped to the United States and Canada. The Card Industry Directory reported over 1.9 billion worldwide smart card shipments in 2003.
About Cryptography Research, Inc.
Cryptography Research, Inc. provides consulting services and technology to solve complex security problems. In addition to security evaluation and applied engineering work, CRI is actively involved in long-term research in areas including tamper resistance, content protection, network security, and financial services. The company also produces the DPA Workstation(TM) to help qualified organizations analyze DPA-related security vulnerabilities and improve their use of licensed DPA countermeasures. This year, security systems designed by Cryptography Research engineers will protect more than $60 billion of commerce for wireless, telecommunications, financial, digital
television, and Internet industries. For additional information or to arrange a consultation with a member of the technical staff, please contact Jennifer Craft at 415-397-0123 or visit http://www.cryptography.com.
April 19, 2004
El Qaeda substitution ciphers
The Smoking Gun has an alleged British translation of an El Qaeda training manual entitled _Military Studies in the Jihad Against the Tyrants_
Lesson 13, _Secret Writing And Ciphers And Codes_ shows the basic coding techniques that they use. In short, substitution ciphers, with some home-grown wrinkles to make it harder for the enemy.
If this were as good as it got, then claims that the terrorists use advanced cryptography would seem to be exaggerated. However, it's difficult to know for sure. How valid was the book? Who is given the book?
This is a basic soldier's manual, and thus includes a basic code that could be employed in the field, under stress. From my own military experience, working out simple encoded messages under battle conditions (in the dark, with freezing fingers, lying in a foxhole, and under fire, are all various impediments to careful coding) can be quite a fragile process, so not too much should be made of the lack of sophistication.
Also, bear in mind that your basic soldier has a lot of other things to worry about and one of the perennial problems is getting them to bother with letting the command structure know what they are up to. No soldier cares what happens at headquarters. Another factor that might shock the 90's generation of Internet cryptographers is that your basic soldiers' codes are often tactical, which means they are only secure for a day or so. They are not meant to hide information that would be stale and known by tomorrow, anyway.
How far this code is employed up the chain of command is the interesting question. My guess would be, not far, but, there is no reason for this being accurate. When I was a young soldier struggling with codes, the entire forces used a single basic code with key changes 4 times a day, presumably so that an army grunt could call in support from a ship off shore or a circling aircraft. If that grunt lost the codes, the whole forces structure was compromised, until the codes rotated outside the lost window (48 hours worth of codes might be carried at one time).
April 14, 2004
AES now rated to "Top Secret"
Of interest only to hard core cryptogaphers, it seems that the CNSS (a US intelligence/Defense security advisory body) has designated AES as suitable for "top secret." This is highly significant, as DES was only ever rated as suitable for "unclassified" material only, and the AES competition was specifically designed to create a replacement. I.e., the requirement was "good enough for the rest, not the big boys."
There is now no reason to ever prefer anything but AES as a secret key algorithm. Steve Bellovin reports:
-------- Original Message --------
Subject: AES suitable for protecting Top Secret information
Date: Wed, 14 Apr 2004 08:43:03 -0400
From: Steve Bellovin
To: cryptography@metzdowd.com
I haven't seen this mentioned on the list, so I thought I'd toss it
out. According to http://www.nstissc.gov/Assets/pdf/fact%20sheet.pdf ,
AES is acceptable for protecting Top Secret data. Here's the crucial
sentence:
The design and strength of all key lengths of the AES algorithm
(i.e., 128, 192 and 256) are sufficient to protect classified
information up to the SECRET level. TOP SECRET information will
require use of either the 192 or 256 key lengths.
--Steve Bellovin, http://www.research.att.com/~smb
---------------------------------------------------------------------
The Cryptography Mailing List
Unsubscribe by sending "unsubscribe cryptography" to majordomo@metzdowd.com
March 31, 2004
Dr. Self-signed or How CAs Learned to Stop Worrying and Love the Cert
Why is the market for certs so moribund? Well, one reason is that it lacks discrimination - a critical component as all marketeers know. This essential ingredient can be added easily with a dose of self-signed certificates and servers that help you to SSL protection. And, CAs stand to reap the benefits, as do users.
A new rant in the SSL series at: http://iang.org/ssl/dr_self_signed.html, or read on.
From: iang@systemics.com
Subject: Dr. Self-signed or How CAs Learned to Stop Worrying and Love the Cert
Date: Tue, March 30, 2004 12:59
To: mozilla-crypto@mozilla.org
Duane wrote:
> Nope I'm not proposing self-signed, that was Ian.
Guilty as charged!
In time, however, I fully expect all CAs to
promote self-signed certs, as aggressively I
do.
One day, Certificate Authorities ("CAs") will
defend our right to use self-signed certs, and
deny ever having said anything to the contrary.
It will be the thought crime of the age to think
in any other terms, a failure of your patriotic
duty, the denial of purity and essence of our
natural ... yadda yadda....
But, today, it's a different world. Most CAs,
today, think that a self-signed cert is bad, as,
in their minds, it reduces their possibilities
of selling another cert.
Which has gotta be bad, right?
Er, no!
Apologies in advance, but that couldn't be more
wrong.
Big CAs have as much understanding of marketing as
children do of the tooth fairy. That's why they
labelled the self-signed cert as "snake oil,"
they were thinking in terms of monsters in the
closet and other gremlins in the dark, bogeymen
their bigger badder siblings had told them about,
and stories of slippery slimy things they were
going to pass on to their smaller siblings.
But, that's not marketing, and not the market,
that's simply what they've been told to believe.
A story about selling: Two salesman went to
Africa in the 19th century to sell shoes.
The first one saw that everyone walked barefoot.
He booked passage back the next day, totally
despondent, muttering to himself, "I can't sell
shoes in Africa, nobody wears them." :-(
The second salesman saw all these unshod people,
and cabled back on the newfangled wire service
"hurry, send shoes, *nobody* wears them, the
market is wide open, it's HUGE..." :-)
The second guy knew what a market was.
My prediction is this: when the browsers stop
worrying and learn to love the increased security
of a self-signed cert, and when servers start
automagically bootstraping with self-signed
certs, then CAs will double their sales of certs.
If it's not double, it'll be triple. Or more.
It works this way. Currently, it is really
hard to sell certs, the problem being that
sales come to the CA, not the other way around.
One is stuck with pretty poor marketing tools
like banner ads and brand name (and even they
don't work because of the commoditisation of
the product that was created by the by the
"one size fits all" rule) and relying on rules
and regs and cartels.
However, if servers automatically installed
with SSL (up and running, self-signed cert
enabled, such that https://myfunsite.com/
worked immediataly) and, users could browse
(sans warnings, but with congratulations on
their choice of fine crypto), then, several
things would happen:
Firstly, CAs would now be able to see who was
using certs and thus who cared. I.e., what
sites care enough to actually promote and use
their easy crypto install, and what sites just
let it lie fallow.
That is, they would now be able to CONVERT sites
from self-signed over to CA-signed. Conversion
is an active selling process and is much more
successful than advertising.
Recall the phrase, "shares are sold, not bought!"
Secondly, the CA would be able to upgrade the
existing certificate - the self-signed one -
based on net-only DD (due diligence) in advance
of any sale.
That is, take the self-signed one and replace
its sig with the CA sig (sadly, x.509 doesn't
support multiple sigs like OpenPGP, it's pretty
useless rubbish, really, but it's the useless
rubbish that we have to deal with.)
Oh, and do some quick DD: check out the whois,
check out the web site, check out a few other
things (isn't competition wonderful...).
A lot of this could be automated, and thus done
for a very low price. A CA-signed cert written
at this lowest grade could then be presented and
sold to the site. $10 or so, who knows, maybe
even free under some circumstances. Digital
signatures are cheap, after all.
Thirdly, the act of upgrading to a CA-signed
cert would be immeasurably simpler - it would
become a drop-in replacement of a single file
and a restart, rather than having to set up all
this Apache SSL config blah blah and trying to
sort out all the whole cert DD and access and
so forth nonsense that drives people spare with
the number of little steps that can muck up.
Each of these factors has the capacity to DOUBLE
the market for CA-certs. Says I!
Why does this work? Simple. Right now and here,
there is a binary market. You either do or you
don't. To encrypt or share, to SSL or not.
There is no in between, no halfway house. No
compromise, no room to manouvre.
Marketeers know that this is the very model of a
primitive, undeveloped, near-worthless market,
with only a tiny number of "do's" because the
barrier is too high.
Check the stats. It's about 1% of the market,
less or more, depending on how you count them.
E.g., totally wide open, untapped, unless you
are like our first shoe salesman, already on
the boat heading home.
However, if we can turn the cliff of DON'T to
DO, into a number of smaller jumps, a climb
up a hill, as it were, this would enable people
to move up and down the slope more efficiently.
Which encourages more people to enter into the
market, and raises the size, and makes for more
security.
(A bit like selling thongs or flip flops to
people who've never worn shoes, this year, and
sandals next year, leather shoes the year after,
and high tech trainers with air cushions and
flashing leds the next year...)
A mature market doesn't overwhelm the customer,
it leads him or her along. We would be creating
a market for certificates that would travel like
this:
NONE -> self -> auto -> minimal -> MAXIMAL
The step from one gradation to the next is
much much smaller, and thus cheaper and easier
on the thought process of our currently unshod
masses. Five small steps replace one huge leap
(and any number of additional steps could be
added to smooth out the slope in future years).
More sites would find the first step easy, and
as they grow in size and value, they would be
encouraged to spend the little needed to go up
the next step. They could walk as high as they
wanted, at their own pace, instead of being
daunted by the size of the cliff.
There's no real reason why a premium CA
couldn't sell a real DD package that cost
tens of thousands, capped off by a solid
platinum grade cert - unless that reason
is a cliff that shrinks the size of the
market to next to nothing.
In marketing terms, this concept is known as
"discrimination" (nothing to do with other
uses of the word). The user is more finely
discriminated as to their needs and their
desires to pay. Consumer advocates would
call this "consumer choice." (If we were
to ask economists, they would refer to the
"consumer surplus," but I'd really advise
caution when letting any econowhatsits into
the market process.)
It's all well known stuff. Anyone who's done
marketing would know this, it's standard in
b-school and sales class. Question is, how
to tell the CAs this? And then stand out of
the way as the stampede to snap up all the
available self-signed certs...
iang
PS: so, what does all this do to security,
especially, of the users?
It increases it immensely. I'd say that this
could multiply by 10-fold the number of sites
doing crypto, using self-signed and auto-signed
certs. It could result in almost all sites
that need crypto using it, instead of the hit
and miss "merchant" approach we have now.
For the CIP (critical infrastructure protection)
people, this would be a godsend, as the one thing
that without a doubt helps net protection is
crypto (authenticated or not, and plenty of it)
and what's even more wonderful is that this could
be done at almost no cost!
PPS: this month's stats on just how wide open
the market is, are at:
http://www.securityspace.com/s_survey/sdata/200402/certca.html
_______________________________________________
mozilla-crypto mailing list
mozilla-crypto@mozilla.org
http://mail.mozilla.org/listinfo/mozilla-crypto
March 29, 2004
CA policy news
Mozilla Foundation (MF) has moved further forward in its debate on CA policy. In essence, the policy states that MF will distribute CA's root keys where the CA has implemented sufficient controls, in the view of MF, and doing so would serve the users of Mozilla. Point 4 of the policy pertains:
4. The Mozilla Foundation will consider adding certificates for additional CAs to the default Mozilla certificate set upon request. The Mozilla Foundation requires that all such CAs:
- provide some service relevant to typical Mozilla users;
- publish information about the CA and its policies and procedures; and
- provide CA certificate data in a form suitable for inclusion in Mozilla.
The process is still in draft, but is encouraging. They are leaving a way open for smaller, more focused CAs to get in to the game, without having to go through some committee idea of safety and security (such as an audit or other pure blooded means). Several CAs are champing at the bit to get in, presumably because they've already found out how hard it is to get accepted by other browser publishers.
Frank Hecker has writen a core policy proposal, supported by implementation details and a meta-policy:
http://www.hecker.org/mozilla/ca-certificate-policy
http://www.hecker.org/mozilla/ca-certificate-faq/policy-details/
http://www.hecker.org/mozilla/ca-certificate-metapolicy/
February 26, 2004
SSLBar + Fingerprints = GoogleCA
As a piece of cross-fertilisation from OpenPGP's fingerprint-based verification, Mister Lee has written a plugin called SSLBar that displays the fingerprint of a website certificate. I stumbled on this a while back, but didn't have a Mozilla browser. Now I have, and I've plugged it in!
After a few moment's thought as to who uses an SSL certificate (!) I went off to Verisign, and hey presto, their certificate has this fingerprint: 0f:a5:b0:52:7b:a9:8f:c6:62:76:ca:16:6b:a2:2e:44:a7:36:36:c9
One bug - I couldn't cut&paste the fingerprint, and had to type it in by hand.
Here's CACert's fingerprint: f6:20:2a:8d:ef:a4:e6:39:5d:b4:c5:fa:54:38:d6:04:6f:a0:74:e9
I'd encourage y'all to download and install the SSLBar, and check that these fingerprints are correct.
As the certs of CAs are by definition self-signed, then, according to their own doctrine, we need some trusted third party to check they are valid. We could wait until they start cross-signing, or we could just start a web of trust for them!
(As an aside, here is CACert's root certificate: 135C EC36 F49C B8E9 3B1A B270 CD80 8846 76CE 8F33 ... I managed to cut&paste that one from the website, after confirming it by eyeball.)
Now, it occurs to me that if we send enough copies of these cert fingerprints around, in the various posts to various lists, then one could use google to clarify the correct cert for each site. This is a trick I learnt from the gold community - it seems that banks don't know their ABA and SWIFT numbers, but their customers do, and google will tell you.
If, for example, Mozilla (SSLBar) were to take further the notion that customers know more, then it could automatically google for the www.verisign.com and then count up the number of occurrences of the fingerprint. This would give a confidence level as to the validity of the cert.
Hey presto, GoogleCA!
February 25, 2004
p2p crypto VoIP - Skype
This Slate article "Can They Hear You Now?" details how a Kazaa-style VoIP operator called Skype has emerged.
What type of encryption is used?
Skype uses AES (Advanced Encryption Standard) - also known as Rijndel - which is also used by U.S. Government organizations to protect sensitive, information. Skype uses 256-bit encryption, which has a total of 1.1 x 1077 possible keys, in order to actively encrypt the data in each Skype call or instant message. Skype uses 1536 to 2048 bit RSA to negotiate symmetric AES keys. User public keys are certified by Skype server at login.
(It's worth reading the entire article... click on!!!)
Can They Hear You Now?
How the FBI eavesdrops on Internet phone calls (and why it sometimes can't).
By David S. Bennahum
Posted Thursday, Feb. 19, 2004, at 2:49 PM PT
The Federal Communications Committee and the Justice Department are at loggerheads over a new problem in the war on terror: how to listen in on Internet phone calls. Thanks to the blistering growth of VoIP?Voice over Internet Protocol?services, which have been adopted by approximately 10 million people worldwide so far, law enforcement officials now worry that wiretapping may one day become technically obsolete. If traditional phone lines go the way of the horse and carriage, will the FBI still be able to listen in on Internet phone calls? How would it go about tapping one? Is it even possible?
I contacted three of the leading VoIP providers in the United States?Time Warner Cable, Vonage, and Skype?to ask them how they would comply with a court order to permit a wiretap. As it turns out, the Justice Department has good reason to worry. Depending on the provider, tapping a VoIP call can be either tricky or impossible.
For Jeffrey Citron, the CEO of Vonage, the critical problem is this: The 1994 law that dictates how telecoms must cooperate with the feds (it's known as CALEA) stipulates that government agents can listen in on phone calls only in real time. They are not permitted to record calls and play them back later to check for incriminating information. But as Citron explained it, on Vonage's system, it is technically impossible (for now) to listen in on a live phone call.
Here's why: A VoIP call transforms your voice into digital bits, then segments them into separate packets of data that are routed through the Internet and reassembled upon arrival at the other end. From an old-fashioned perspective, there is no actual "sound" passing through the Internet at any time?the PC or other device you use to place the VoIP call digitizes your voice in your home. Of course, a huge amount of regular phone traffic is also segmented into digital packets at some point, but such calls are digitized and then reconverted into sound waves far deeper into the telephone system, at points outside private homes. Law enforcement can therefore listen in on your line within the telephone system itself; the technology to do this is already embedded in the phone company's switches.
In theory, Vonage could comply with a tap request by making a copy of the call in real time and streaming that call to a law enforcement agent. But that tack would violate CALEA, since Vonage would still be making a copy of the original call. The alternative, Citron says, is for Vonage to modify its VoIP system so that its digital routers include analog-friendly wires capable of producing a real-time sound wave. These could then be linked to a law enforcement agency, permitting simultaneous listening-in. Citron says making the shift would cost Vonage a few million dollars?before taking any action, he's awaiting further regulatory instructions from the FCC. The company has already complied with between 10 and 100 requests from various government agencies for general information (including call records and billing history), but to date, he has yet to receive a single request for a live tap into a Vonage call.
Time Warner Cable, which has announced that it will make VoIP available to all its digital cable markets by the end of the year, would have a much easier time wiretapping live phone calls. That's because Time Warner owns the underlying infrastructure its VoIP service relies on. So while Vonage could offer government agents access only to the handful of routers it uses to direct its calls over the wider Internet, Time Warner can offer them direct access to the cables, routers, and switches over which its VoIP calls travel. It could, in theory, open a live channel for law enforcement at the place where Time Warner's cable modem signals are routed onto the wider, public Internet. This switch, known as the Cable Modem Termination System, is a natural junction where a company like Cisco, which already builds CMTS hardware, could easily and cheaply add in CALEA-compliant technology.
Why, then, couldn't the feds tap any VoIP call by listening in on the line at the CMTS? Because some VoIP calls are routed, digitized, or encrypted in ways that law enforcement can't decipher. Skype, which now boasts 7 million users, specializes in such encryption. The company's system is designed to thwart potential eavesdroppers, legal and otherwise. The difference begins with how the networks are designed: Both Time Warner and Vonage offer VoIP services that run through centralized networks. For instance, when I place a call through Vonage, it starts by going to a centralized Vonage computer, which in turn looks up the phone number I am dialing and routes the call over to the traditional phone system. This is a classic instance of a "hub and spoke" network. But Skype, built by the same people who brought us Kazaa, is a totally distributed peer-to-peer network, with no centralized routing computers. (That's possible in part because Skype calls can only be sent and received by computers?you can't call a friend with an analog phone.) As a result, the company's network looks more like a tangled spider web, and the packets that make up your voice in a Skype call are sent through myriad routes to their destination. Part of the brilliance of the Skype software is that it has learned to use desktop PCs as "supernodes," each sharing some of the load needed to route Skype calls quickly to their destination. From the caller's perspective, this is all invisible: The call just works.
Since it's exceedingly difficult to follow the path that a Skype call makes through the network, law enforcement agents would be hard-pressed to figure out where to place a tap. But even if they could, the company has built in such strong encryption that it's all but mathematically impossible with today's best computer technology to decode the scrambled bits into a conversation. Here's how Skype explained it: "Skype uses AES (Advanced Encryption Standard)?also known as Rijndel?which is also used by U.S. government organizations to protect sensitive information. Skype uses 256-bit encryption, which has a total of 1.1 x 1077 possible keys, in order to actively encrypt the data in each Skype call or instant message." The point of all this mumbo-jumbo is that Skype uses an encryption algorithm* known as 256-bit AES. The National Institute of Science and Technology states that it would take a computer using present-day technology "approximately 149 thousand-billion (149 trillion) years to crack a 128-bit AES key." And that's for the 128-bit version; Skype uses the more "secure" 256-bit standard. Since computers have a way of quickly getting more powerful, the institute forecasts that "AES has the potential to remain secure well beyond twenty years."
Moreover, Skype says, the company does not keep the encryption "keys" that are used to encode each Skype transmission?each one is generated and then discarded by the computer that initiates the call. So government agents couldn't force Skype to turn over the keys needed to decrypt a call either.
Last Thursday the FCC held an open hearing on the future of VoIP telecommunications. In a 4-1 decision, FCC commissioners, supported by Chairman Michael Powell, voted that a VoIP provider called Free World Dialup should not be subject to the same regulations as traditional phone companies?including the particulars of CALEA compliance. Instead, the FCC decided to put off the issue, stating that it would initiate a proceeding "to address the technical issues associated with law-enforcement access to Internet-enabled service" and "identify the wiretapping capabilities required." One commissioner, Michael J. Copps strongly dissented, calling the postponement "reckless."
But even if the FCC had ruled differently on Thursday, mandating specific rules for Internet phone calls and CALEA compliance, it couldn't have been the definitive word on the subject.
VoIP technology is gaining ground so fast that it may be impossible for any government agency to dictate what these networks should look like. Skype, for instance, isn't even an American company. It's legally based in Luxembourg. Increased regulation on American carriers, which could lead to higher costs for consumers, is likely to push people further toward carriers like Skype, rewarding companies that seek permissive legal jurisdictions and punishing those that try to comply with domestic regulations. It's this scenario that the Justice Department legitimately fears: Even though the Patriot Act has increased its ability to eavesdrop on Americans, companies like Skype are giving everyday people unprecedented freedom from government monitoring.
Correction, Feb. 20, 2004: This piece originally stated that Skype uses an encryption algorithm built by RSA known as 256-bit AES. In fact, RSA did not build this algorithm. (Return to corrected sentence.)
David S. Bennahum is a contributing writer with Wired and the author of Extra Life: Coming of Age in Cyberspace.
Illustration by Mark Alan Stamaty
February 10, 2004
CAcert debate leads rethink for SSL certs
A cert for a new CA, conveniently named CACert, is being proposed for addition to Mozilla, the big open source group pushing out a successful browser.
As CACert is not a commercial organisation, and doesn't sell its certs for any sort of real money, this has sparked quite a debate.
Mozilla Foundation has held firm to its non-commercial roots so far, by announcing and publishing a draft policy and faq that espouses no-cost CA Cert addition, and fairly perfunctory checks.
The groundswell for reworking browser approach to the crypto security layer is growing. In 2003, I pressed the debate forward with a series of rants attacking the SSL/HTTPS (in)security design.
I suggest the way is now open for cryptographers to adopt economic cryptography, rather than the no-risk cryptography approach used and since discredited in SSL.
In the specific case of SSL/HTTPS, we recommend moving to:
- opportunistic cryptography, as employed successfully by SSH system:
- acceptance of self-signed certs by browsers, and
- automatic generation of self-signed certs by servers;
- the switch of emphasis to browser presentation of security information and the branding of certs and CAs.
Copying the successful economic cryptography model of SSH would definitely lift the ugly duckling SSL crypto system up out of the doldrums (1st in above rants page, "How effective is open source crypto?" discusses the woeful statistics for SSL certificate usage).
February 08, 2004
FC 2004
FC 2004 starts this monday in Key West, Florida, USA. If you're not heading there by now, you're ... probably not going to make it!
http://fc04.ifca.ai/schedule.htm
January 16, 2004
Cheap Hardware Tokens
Hardware tokens from PicoDisk start at about 30 Euros for a 32Mb store that could fit on your keyring. These Italian stallions even have one that boasts AES encryption, and another with a biometric fingerprint sensor, for what it's worth...
Big enough to carry your secret keys, your transactions and your entire copy of WebFunds! You have to pay a bit more to get Java installed on them, but they do go up to a whopping 2Gb.
Of course, serious FCers know that the platform that runs your financial application also has to be secure, but nothing's perfect. These cheap tokens could go a long way to covering many of the sins found in "common windowing environments'" predeliction to being raided by viruses.
(I've since found out that these tokens are only accessible from Windows, and drivers are "closed". Whoops. My interest just hit the floor - it's hard enough to integrate these sorts of things into real apps without the supplier trying to stop you using them. Apologies for wasting your time!)
January 15, 2004
Adobe Helped Gov't Fight Counterfeiting
What fantastic news for the open source community ... This week's cryptogram reports that Adobe has added anti-money-counterfeiting technology to products.
What is not openly revealed is which products and how it works. My first knee-jerk obvious reactions are confirmed, almost paragraph by paragraph - this is going to backfire on Adobe. Read on for the full fascinating story...
Posted on Fri, Jan. 09, 2004
Adobe Helped Gov't Fight Counterfeiting
TED BRIDIS
Associated Press
WASHINGTON - Adobe Systems Inc. acknowledged on Friday it quietly added technology to the world's best-known graphics software at the request of government regulators and international bankers to prevent consumers from making copies of the world's major currencies.
The unusual concession has angered scores of customers.
Adobe, the world's leading vendor for graphics software, said the secretive technology "would have minimal impact on honest customers." It generates a warning message when someone tries to make digital copies of some currencies.
The U.S. Federal Reserve and other organizations that worked on the technology said they could not disclose how it works and wouldn't name which other software companies have it in their products. They cited concerns that counterfeiters would try to defeat it.
"We sort of knew this would come out eventually," Adobe spokesman Russell Brady said. "We can't really talk about the technology itself."
A Microsoft Corp. spokesman, Jim Desler, said the technology was not built into versions of its dominant Windows operating system.
A rival graphics program by Ulead Systems Inc. also blocks customers from copying currency.
Adobe revealed it added the technology after a customer complained in an online support forum about mysterious behavior by the new $649 "Photoshop CS" software when opening an image of a U.S. $20 bill.
Kevin Connor, Adobe's product management director, said the company did not disclose the technology in Photoshop's instructions at the request of international bankers. He said Adobe is looking at adding the detection mechanism to its other products.
"The average consumer is never going to encounter this in their daily use," Connor said. "It just didn't seem like something meaningful to communicate."
Angry customers have flooded Adobe's Internet message boards with complaints about censorship and concerns over future restrictions on other types of images, such as copyrighted or adult material.
"I don't believe this. This shocks me," said Stephen M. Burns, president of the Photoshop users group in San Diego. "Artists don't like to be limited in what they can do with their tools. Let the U.S. government or whoever is involved deal with this, but don't take the powers of the government and place them into a commercial software package."
Connor said the company's decision to use the technology was "not a step down the road towards Adobe becoming Big Brother."
Adobe said the technology slows its software's performance "just a fraction of a second" and urged customers to report unexpected glitches. It said the technology was new and there may be room for improvement.
The technology was designed recently by the Central Bank Counterfeit Deterrence Group, a consortium of 27 central banks in the United States, England, Japan, Canada and across the European Union, where there already is a formal proposal to require all software companies to include similar anti-counterfeit technology.
"The industry has been very open to understanding the nature of the problem," said Richard Wall, the Bank of Canada's representative to the counterfeit deterrence group. "We're very happy with the response."
He said nearly all counterfeit currency in Canada is now created with personal computers and ink-jet printers.
"We've seen a shift of what would normally be highly skilled counterfeiters using elaborate equipment to basically counterfeiters who need to know how to use a PC," Wall said.
Some policy experts were divided on the technology.
Bruce Schneier, an expert on security and privacy, called the anti-counterfeit technology a great system. "It doesn't affect privacy," he said. "It stops the casual counterfeiter. I can't think of any ill effects."
Another security expert, Gene Spafford of Purdue University, said Adobe should have notified its customers prominently. He wondered how closely Adobe was permitted to study the technology's inner-workings to ensure it was stable and performed as advertised.
"If I were the paranoid-conspiracy type, I would speculate that since it's not Adobe's software, what else is it doing?" Spafford said.
ON THE NET
Adobe Systems: www.adobe.com
Facts about banknote images: www.rulesforuse.org
Bureau of Engraving & Printing: www.moneyfactory.com
--
Additionally, stories on inevitable circumvention .
December 28, 2003
Repudiating non-repudiation
In a debate on the use of "non-repudiation" over on the cryptography list, Carl Ellison raises the point that only people can repudiate.
I have to agree with Carl and stress that the issue is not that the definition for "non-repudiation" is bad or whatever, but the word is simply out of place. Repudiation is an act of a human being. So is the denial of that or any other act, to take a word from one definition.
We can actually learn a lot more from the legal world here, in how they solve this dilemma. Apologies in advance, as what follows is my untrained understanding, derived from a legal case I was involved with in recent years [1]. It is an attempt to show why the use of the word "repudiation" will never help us and will always hinder us.
The (civil) courts resolve disputes. They do *not* make contracts right, or tell wrong-doers to do the right thing, as is commonly thought.
Dispute resolution by definition starts out with a dispute, of course. That dispute, for sake of argument, is generally grounded in a denial, or a repudiation.
One party - a person - repudiates a contract or a bill or a something.
So, one might think that it would be in the courts' interest to reduce the number of repudiations. Quite the reverse - the courts bend over backwards, sideways, and tie themselves in knots to permit and encourage repudiations. In general, the rule is that anyone can file *anything* into a court.
The notion of "non-repudiation" is thus anathema to the courts. From a legal point of view, we, the crypto community, will never make headway if we use this term [2]. What terms we should use, I suggest below, but to see that, we need to get the whole process of the courts in focus.
Courts encourage repudiations so as to encourage all the claims to get placed in front of the forum [3]. The full process that is then used to resolve the dispute is:
1. filing of claims, a.k.a. "pleadings",
2. presentation of evidence,
3. application of law to the evidence,
4. a reasoned ruling on 1 is delivered based on 2,3.
Now, here's where cryptographers have made the mistake that has led us astray. In the mind of a cryptographer, a statement is useless if it cannot be proven beyond a shred of doubt.
The courts don't operate that way - and neither does real life. In this, it is the cryptographers that are the outsiders [4].
What the courts do is to encourage the presentation of all evidence, even the "bad" stuff. (That's what hearings are, the presentation of evidence.)
Then, the law is applied - and this means that each piece of evidence is measured and filtered and rated. It is mulled over, tested, probed, and brought into relationship with all the other pieces of evidence.
Unlike no-risk cryptography, there isn't such a thing as bad evidence. There is, instead, strong evidence and weak evidence. There is stuff that is hard to ignore, and stuff that doesn't add much. But, even the stuff that adds little is not discriminated against, at least in the early phases.
And this is where the cryptography field can help: a digital signature, prima facie, is just another piece of evidence. In the initial presentation of evidence, it is neither weak nor strong.
It is certainly not "non-repudiable." What it is is another input to be processed. The digsig is as good as all the others, first off. Later on, it might become stronger or weaker, depending.
We cryptographers can help by assisting in the process of determining the strength of the evidence. We can do this in three ways, I think:
Firstly, the emphasis should switch from the notion of non-repudiation to the strength of evidence. A digital signature is evidence - our job as crypto guys is to improve the strength of that evidence, with an eye to the economic cost of that strength, of course.
Secondly, any piece of evidence will, we know, be scrutinised by the courts, and assessed for its strength. So, we can help the process of dispute resolution by clearly laying out the assumptions and tests that can be applied. In advance. In as accessible a form as we know how.
For example, a simple test might be that a receipt is signed validly if:
a. the receipt has a valid hash,
b. that hash is signed by a private key,
c. the signature is verified by a public key, paired with that private key.
Now, as cryptographers, we can see problems, which we can present as caveats, beyond the strict statement that the receipt has a valid signature from the signing key:
d. the public key has been presented by the signing party (person) as valid for the purpose of receipts,
e. the signing party has not lost the private key,
f. the signature was made based on best and honest intents...
That's where it gets murky. But, the proper place to deal with these murky issues is in the courts. We can't solve those issues in the code, and we shouldn't try. What we should do is instead surface all the assumptions we make, and list out the areas where further care is needed.
Thirdly, we can create protocols that bear in mind the concept of evidence. That means we use various techniques such as signed receipts, logs, sharing of records and chains of signatures to create pieces of evidence.
We use the careful techniques of protocol design to marshal sufficient evidence of strength to make it easy to resolve any questions; before they become disputes, and ideally, before they leave the protocol!
And, when these questions do become disputes, we try and make it easy (read: cheap) to present strong evidence to those resolving any dispute.
iang
[1] It was highly instructive, and I'd almost recommend all to get in trouble with the courts at least once in your lives, if only it wasn't so darn destructive of ones life!
[2] It's even worse than the signature. At least there is some resemblance between the process and result of a digital signature and a legal signature. With (non)-repudiation, however, cryptographers are saying that the entire meta-concept of the court is wrong.
[3] Courts actually have a rule, that, only claims made up front can be heard - so you had better get your repudiations up there in the beginning!
[4] This is a characteristic of the no-risk school of cryptography, but even economic cryptographers fall into this trap with regularity.
December 15, 2003
Keeping Secrets - Crypto gets a Demand-side Boost
http://www.usnews.com/usnews/issue/031222/usnews/22secrecy.htm
The above article talks a lot about how secrecy is the hallmark of the current USA administration. It includes this one snippet on page 8:
"Secret evidence of a different kind comes into play through a little-noticed effect of the U.S.A. Patriot Act. A key provision allows information from surveillance approved for intelligence gathering to be used to convict a defendant in criminal court."
Skipping past the rhetoric, and without examining the provisions of that act in detail, this signals a fairly significant shift in the threat models faced by ordinary civilians in the jurisdictions concerned. (By this, we include of course financial cryptography.)
In the past, it was possible to treat ones transmissions as protected from the average plausible attacks by the people similar to oneself. Encrypted email to your attorney was secure against, say, a bribed or nosy system administrator. An encrypted spreadsheet of ones hotel bills was secure against an ex-spouse's divorce attorney.
In addition to that, you took reasonable care of ones own machine, and hey presto, we had a security model for everyone. The closing statements of such a model said something like "secure against the threats we know about and expect. Does not include attacks by the intelligence services..."
In practical economic terms, this was grand. The common view amongst most practitioners was that if you were up against the spooks, then that was a whole different ballgame (and, we charged more...). We, as a society, relied on a shared understanding with the spooks that if they shared their product with civilians, it would weaken their effectiveness against real national security threats. In exchange for giving the spooks carte blanche with their activities, we also reduced society's costs in protecting against over-empowered public officials.
Now, we are seeing a progressive blurring of the lines of demarcation. This will make threat assessment much harder in the future. It will no longer be trivially possible to draw a line between civilian and military means, and say, for example, that "national technical means" are excluded from our threat model. It may now be necessary, for all sorts of civilian cryptography scenarios, to consider attacks by intelligence agencies operating under the direction of civilian agencies.
Take the office of the Leader of the Opposition. In the past, it was plausible to chortle and scoff at the notion that you needed to protect politically inspired attacks. We can no longer take for granted that a self respecting intelligence agent would protect their information and activities from politics. A rational analysis would now show there are just too many ways for spook material to be drafted into the re-election campaign.
Whether this means that cryptography practitioners should insist on very high standards in all crypto (as the no-risk cryptography school has it) or whether we should insist on lowering standards to increase adoption rates (as the economic cryptography school has it) is, I consider, an orthogonal issue.
What is clear is that the demand for crypto, and lots of it, will get stronger. More and more people will demand more and more cryptographic protection, as a routine feature in more and more applications. That's the inevitable consequence of more and more politicians pushing more and more power out to bureaucrats with private agendas.
iang
PS: in practice, this separation may have been illusory, as it appears to have only been maintained in "rich" countries, and only some of those. (Coincidentally, the ones that pioneered the Internet, it seems.) One of the threats that groups like cryptorights.org consider routine is that of the local security services working in concert with economic interests.
September 14, 2003
Say hello to success
How do we measure success in a cryptographic protocol?
Many talk as if it were ordained. This is a resort to religion. There are others that follow the words of their betters. Perhaps runes are cast, tea leaves remained, palms scanned.
All of this remains uninspiring. I mean, in a religious sense, where is the beauty in listening to someone telling you, "Believe, else yea be struck down!"
There has to be some science, some objectivity to this question. Why is it that one crypto protocol rises and another sinks? How can we measure this? How can we decide what is succesfull or not?
This is no mere sidelines question. No fodder for Tired Journalists. If we don't understand what makes a security protocol lead itself and ourselves to success, then how can we write the next one?
I propose these measures:
a. nunber of design "wins" - something that catches the eye. Press releases, deployments, applications that bought in to the secuity vision. They must have done so for a reason, their choice is tangibly measurable by us outsiders.
b. penetration into equivalent unprotected market. This is the easiest. If we have an alternate already in place, find some easy measure of comparison. How many people switch over?
c. number of actual attacks defeated. Now, this may seem like an imponderable, but it is possible to draw upper and lower bounds. It is possible and fruitful to estimate based on analogues.
d. subjective good, as at the application level. That is, a security protocol is naked without its application - what good has it delivered to its masters?
e. placebo effect - the inspiring of the user community to move forward and utilise the system, regardless of the real security so delivered. (This last one is subtle, but very important, as several people have commented).
These are all measures that can be applied externally, without need to worry ourselves over the goodness or otherwise of the cryptography.
From the list, we can exclude such worthless measures as
* deployed copies,
* amount of traffic protected,
* opinions of experts,
We need as professionals, objective, measurable metrics. Measure on!